







网络数据采集基础(一)
基础引入
1. 爬虫是什么?
2. HTTP/HTTPS请求与响应
**3. 抓包/抓包工具Fiddler、wireshark使用方式 **
4. urllib2(Python 2.x)/request.request(Python 3.x)
爬虫是什么?
爬虫(web crawler) ,也叫网络蜘蛛,字面意思一定不理解。他是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。[维基百科]
爬虫访问网站的过程会消耗目标系统资源。不少网络系统并不默许爬虫工作。因此在访问大量页面时,爬虫需要考虑到规划、负载,还需要讲“礼貌”。 不愿意被爬虫访问、被爬虫主人知晓的公开站点可以使用robots.txt文件之类的方法避免访问。这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理。
互联网上的页面极多,即使是最大的爬虫系统也无法做出完整的索引。因此在公元2000年之前的万维网出现初期,搜索引擎经常找不到多少相关结果。现在的搜索引擎在这方面已经进步很多,能够即刻给出高质量结果。
简单来说爬虫就是用来做网络数据采集的,什么是网络数据采集?
网络数据采集就是利用某种手段可以是人工可以是计算机从网络浏览器上抓取对你有用的数据进行本地化保存;无用的数据进行过滤操作。网络浏览器,抓取?我们日常生活中总会用到浏览器,我们可以用它来浏览各种各样的网页,比如说Google、百度等等。那么我们人眼所见到的画面又是如何制作而成的呢?
他一定不是杂乱无章的!! 无论是手机上还是电脑上,我们看到的都是经过浏览器内核渲染过的画面(后面我回去总结)我们拿事实情况去看去分析。
 百度浏览器页面
百度浏览器页面

文字摆放整齐,logo显示清晰,给人一种美感
上述的每一个东西,在爬虫界中都叫做元素,爬虫就是把上面你认为对你有帮助的元素給爬取下来。
爬虫最讲究的不是所见即所得,而是数据来源,这些文字,这些图片/音视频的来源(或是说地址)是哪儿? 这就是爬虫需要分析的地方.
通用爬虫和聚焦爬虫:
通用网络爬虫 是 捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
通用网络爬虫 从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。通用网络爬虫 从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。
第一步:抓取网页
搜索引擎网络爬虫的基本工作流程如下:
-
首先选取一部分的种子URL,将这些URL放入待抓取URL队列;
-
取出待抓取URL,解析DNS得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中,并且将这些URL放进已抓取URL队列。
-
分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环…

搜索引擎如何获取一个新网站的URL: -
新网站向搜索引擎主动提交网址:(如百度http://zhanzhang.baidu.com/linksubmit/url)
-
在其他网站上设置新网站外链(尽可能处于搜索引擎爬虫爬取范围)
-
搜索引擎和DNS解析服务商(如DNSPod等)合作,新网站域名将被迅速抓取。
但是搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件的内容,如标注为nofollow的链接,或者是Robots协议。
Robots协议(也叫爬虫协议、机器人协议等),全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,例如:
淘宝网:https://www.taobao.com/robots.txt
腾讯网: http://www.qq.com/robots.txt
第二步:数据存储
搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。
搜索引擎蜘蛛在抓取页面时,也做一定的重复内容检测,一旦遇到访问权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不再爬行。
第三步:预处理
搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理。
- 提取文字
- 中文分词
- 消除噪音(比如版权声明文字、导航条、广告等……)
- 索引处理
- 链接关系计算
- 特殊文件处理
- …
除了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型。
但搜索引擎还不能处理图片、视频、Flash 这类非文字内容,也不能执行脚本和程序。
第四步:提供检索服务,网站排名
搜索引擎在对信息进行组织和处理后,为用户提供关键字检索服务,将用户检索相关的信息展示给用户。
同时会根据页面的PageRank值(链接的访问量排名)来进行网站排名,这样Rank值高的网站在搜索结果中会排名较前,当然也可以直接使用 Money 购买搜索引擎网站排名,简单粗暴。

课外阅读:Google搜索引擎的工作原理
但是,这些通用性搜索引擎也存在着一定的局限性:
- 通用搜索引擎所返回的结果都是网页,而大多情况下,网页里90%的内容对用户来说都是无用的。
- 不同领域、不同背景的用户往往具有不同的检索目的和需求,搜索引擎无法提供针对具体某个用户的搜索结果。
- 万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎对这些文件无能为力,不能很好地发现和获取。
- 通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询,无法准确理解用户的具体需求。
针对这些情况,聚焦爬虫技术得以广泛使用。
聚焦爬虫
聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
而我们今后要学习的,就是聚焦爬虫。
HTTP/HTTPS请求与响应
浏览器浏览网页需要下载网页,需要缓存数据,数据不是杂乱无章。学过计算机基础的都知道,网页是有静态网页(HTML)和动态网页(JSP)等等组成的。 HTML文件经过浏览器渲染,形成人们想要见到的样子。
网页源代码
 使用开发者工具(在浏览器中右击)即可查看网页源代码(html代码)
使用开发者工具(在浏览器中右击)即可查看网页源代码(html代码)
这里要回顾下基础
URL、HTML、HTTP、TCP四层模型
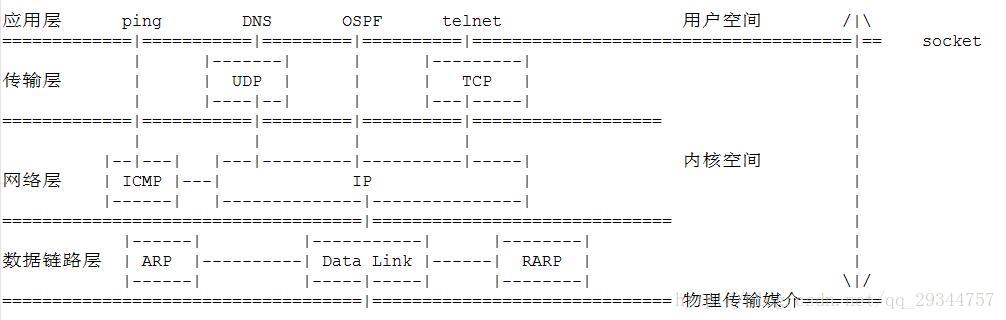
HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法。
HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,在HTTP下加入SSL层。
SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
HTTP的端口号为80,HTTPS的端口号为443
HTTP工作原理
网络爬虫抓取过程可以理解为模拟浏览器操作的过程。
浏览器的主要功能是向服务器发出请求,在浏览器窗口中展示您选择的网络资源,HTTP是一套计算机通过网络进行通信的规则。
当浏览器收到一个URL的时候,会执行哪些相应的步骤?
a. 浏览器通过DNS域名解析器,解析出主机名(url—>ip/ip—>url);
b. 浏览器获得主机名的ip地址后,并获得其端口号,端口号决定了应用层隶属于什么应用(HTTP?还是FTP?还是 SMTP?还是POP3) 那我们浏览器不需要关心这些,他把URL交给了底层,底层回去帮其分析:👀 比如: HTTP S://www.baidu.com 这个就是URL ,前面的HTTPS表示的就是使用HTTPS服务 底层解析器端口为443端口,HTTP 解析为80端口,告诉对方我正要请求的服务是HTTP网络请求服务。
c. 那么浏览器法从一条HTTP 请求报文 (HTTP请求报文由:请求行、请求头、空行、请求数据构成) 通过GET或POST方法向服务器端发送请求request。
d. 服务器收到请求报文,并给予浏览器端一个响应报文response。
e. 浏览器关闭链接
URL只是标识服务器资源的位置,而HTTP是用来提交和获取资源的一簇协议
HTTP :**HTTP今后写爬虫程序最主要的两个方法 **①GET方法 从服务器上获取资源 ②POST是向服务器传递数据
常用浏览器请求头:
Host: 主机和端口号
Connection:链接类型
Upgrade-Insecure-Request: 升级为HTTPS请求
User-Agent: 浏览器名称(今后写爬虫程序必须要经历的一步)
Accept: 传输文件类型
Accept: */*:表示什么都可以接收。
Accept:image/gif:表明客户端希望接受GIF图像格式的资源;
Accept:text/html:表明客户端希望接受html文本。
Accept: text/html, application/xhtml+xml;q=0.9, image/*;q=0.8:表示浏览器支持的 MIME 类型分别是 html文本、xhtml和xml文档、所有的图像格式资源。
Referer: 页面跳转处
Accept-Encoding: 文件编码格式
Accept-Language: 语言种类
cookie: 浏览器用这个属性向服务器发送Cookie。Cookie是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息,也可以用来实现会话功能,以后会详细讲。
浏览器响应头(了解)
Cache-Control: must-revalidate, no-cache, private
这个值告诉客户端,服务端不希望客户端缓存资源,在下次请求资源时,必须要从新请求服务器,不能从缓存副本中获取资源。
Connection:keep-alive 告诉客户端服务器的tcp连接也是一个长连接,客户端可以继续使用这个tcp连接发送http请求。
Content-Encoding:告诉客户端,服务端发送的资源是采用gzip编码的,客户端看到这个信息后,应该采用gzip对资源进行解码。一般爬虫不用这个请求
Content-Type:告诉客户端,资源文件的类型,还有字符编码,客户端通过utf-8对资源进行解码,然后对资源进行html解析。通常我们会看到有些网站是乱码的,往往就是服务器端没有返回正确的编码。
Date: 这个是服务端发送资源时的服务器时间,GMT是格林尼治所在地的标准时间。http协议中发送的时间都是GMT的,这主要是解决在互联网上,不同时区在相互请求资源的时候,时间混乱问题。
Expires:这个响应头也是跟缓存有关的,告诉客户端在这个时间前,可以直接访问缓存副本,很显然这个值会存在问题,因为客户端和服务器的时间不一定会都是相同的,如果时间不同就会导致问题。所以这个响应头是没有Cache-Control :max-age=*这个响应头准确的,因为max-age=date中的date是个相对时间,不仅更好理解,也更准确
Praagma: no-cache 这个含义与Cache-Control等同。
Server: 这个是服务器和相对应的版本,只是告诉客户端服务器的信息。
Transfer: 这个响应头告诉客户端,服务器发送的资源的方式是分块发送的。一般分块发送的资源都是服务器动态生成的,在发送时还不知道发送资源的大小,所以采用分块发送,每一块都是独立的,独立的块都能标示自己的长度,最后一块是0长度的,当客户端读到这个0长度的块时,就可以确定资源已经传输完了。
Vary: 告诉缓存服务器,缓存压缩文件和非压缩文件两个版本,现在这个字段用处并不大,因为现在的浏览器都是支持压缩的。
相应状态码:
100~199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。200~299:表示服务器成功接收请求并已完成整个处理过程。常用200(OK 请求成功)。300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用302(所请求的页面已经临时转移至新的url)、307和304(使用缓存资源)。400~499:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服务器拒绝访问,权限不够)。500~599:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)。
Cookie和Session:
服务器和客户端的交互仅限于请求/响应过程,结束之后便断开,在下一次请求时,服务器会认为新的客户端。
为了维护他们之间的链接,让服务器知道这是前一个用户发送的请求,必须在一个地方保存客户端的信息。
Cookie:通过在 客户端 记录的信息确定用户的身份。
Session:通过在 服务器端 记录的信息确定用户的身份。
抓包/抓包工具Fiddler、wireshark
什么是抓包,为什么要抓包?
一般地,我们分析一个网页URL编写爬虫程序的前提就是要看网页源代码,要看网页的HTTP请求头部信息,从而总结出静态网页URL内部的规律 ,已经观察它的响应数据属于什么类型,比如JSON文件JSP还是直接是HTML,一般地HTML一些重要的地方还需要动态处理(今后会总结到),那些一般的静态处理网页的方法就不够完成任务了。
查看网页源代码的方式:
- 浏览器中直接进行审查元素 h或者一般按
F12快捷键直接进入开发者模式 观察 这也是通用技巧 - 使用更为强大的抓包工具,一般使用简单的Fiddler就已经够用了; wireshark比Fiddler更为强大,适用场景在底层网络开发上面占优势。
Fiddler是一个本地代理工具,所有流经浏览器的数据都会流经它,浏览器设置本地代理即可通过Fiddler抓取数据包,操作如下所示:
-
先打开浏览器(我这里以FireFox火狐浏览器为试验对象)---->
点击选项进行设置 2. 点击设置:
2. 点击设置:进行手动代理配置即自定义配置; 这么做的原因是:告诉浏览器我即将使用的是本地代理Proxy Fiddler抓包工具。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传

SOCKS代理与其他类型的代理不同,它只是简单地传递数据包,而并不关心是何种应用协议,既可以是HTTP请求,所以SOCKS代理服务器比其他类型的代理服务器速度要快得多。
SOCKS代理又分为SOCKS4和SOCKS5
二者不同的是SOCKS4代理只支持TCP协议(即传输控制协议),而SOCKS5代理则既支持TCP协议又支持UDP协议(即用户数据包协议),还支持各种身份验证机制、服务器端域名解析等。
SOCK4能做到的SOCKS5都可得到,但SOCKS5能够做到的SOCK4则不一定能做到,比如我们常用的聊天工具QQ在使用代理时就要求用SOCKS5代理,因为它需要使用UDP协议来传输数据。
- 这样浏览器这边基本设置完毕了
- Fiddler设置 进入Fiddler软件:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
和普通软件一样: 菜单栏 + 工具栏 + 显示栏 + 状态栏 **首先需要设置的是: **点击Tools 再点击 Options进行设置, 依次设置 即可, 后期有需求再更改。。。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传

进入HTTPS设置 , 最后一步 点击Actions 选择 Trust Root certifications ,跳转出界面—>选择是

设置Connections 设置端口号 这里和上述浏览器设置对应, port: 8888

其他按照默认设置 ,点击OK。
请求 (Request) 部分详解
- Headers —— 显示客户端发送到服务器的 HTTP 请求的 header,显示为一个分级视图,包含了 Web 客户端信息、Cookie、传输状态等。
- Textview —— 显示 POST 请求的 body 部分为文本。
- WebForms —— 显示请求的 GET 参数 和 POST body 内容。
- HexView —— 用十六进制数据显示请求。
- Auth —— 显示响应 header 中的 Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息.
- Raw —— 将整个请求显示为纯文本。
- JSON - 显示JSON格式文件。
- XML —— 如果请求的 body 是 XML 格式,就是用分级的 XML 树来显示它。
响应 (Response) 部分详解
- Transformer —— 显示响应的编码信息。
- Headers —— 用分级视图显示响应的 header。
- TextView —— 使用文本显示相应的 body。
- ImageVies —— 如果请求是图片资源,显示响应的图片。
- HexView —— 用十六进制数据显示响应。
- WebView —— 响应在 Web 浏览器中的预览效果。
- Auth —— 显示响应 header 中的 Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息。
- Caching —— 显示此请求的缓存信息。
- Privacy —— 显示此请求的私密 (P3P) 信息。
- Raw —— 将整个响应显示为纯文本。
- JSON - 显示JSON格式文件。
- XML —— 如果响应的 body 是 XML 格式,就是用分级的 XML 树来显示它 。
抓包小测试
-
现在就跟可以测试抓包了 , 测试之前 先清空列表中无用数据。

-
那我以 豆瓣网为例,抓取相关热门影视信息 url: https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
上面的URL就可以作为爬虫分析的依据之一
进入到Fiddler 进行分析看看:
我们已经看到Fiddler中有很多数据包了

随便点击一个进行分析:看右方显示包体结果

上方是请求头, 下方是响应头。
在此往下点击分析查找:
 我们已经看到熟悉的画面了😏😏😏 这就是我们要找的
我们已经看到熟悉的画面了😏😏😏 这就是我们要找的


这个响应的是json文件 是不是和浏览器中出现的一样呢?!!😆 可以对比一下

那么这样,我们的爬虫工作就可以开始了。
这是一个带有url参数的HTTP GET请求:(如下图所示) QueryString

当然, 并不是所有 的网站都向豆瓣这样好找,还有很多网站是专门隐藏了吊爬虫来爬的陷阱, 有时你还要注意,别到时候 爬虫太过分把自己的ip给封掉了(以后你可能一段时间访问不了这个网站了,这就是常见的封号 就跟游戏作弊封号一样) 得不偿失。。
我想一般 不是特别值钱的数据 就不爬了 只爬合法的数据和娱乐性的数据一般没危险… :写爬虫还是得讲道德的
urllib2(Python 2.x)/request.request(Python 3.x)的基本使用
说到这里,网络爬虫可以理解为:模拟浏览器操作的过程
浏览器的主要功能就是向服务器发出请求,在浏览器窗口中展示选择的网络资源 HTTP是一套计算机通过网络进行通信的规则。
urllib2是作为早期Python模拟浏览器的重要手段,随着时间的推移,目前最好用且简单的是requests库
Python 3.x中 urllib2 被直接合并到urllib中 并且分为三个子模块: request类、parse类、error类
request类中提供了Request()方法,用于提供请求操作。
函数原型:
request.Request(url[, data][, headers][, origin_req_host][, unverifible]) # []代表参数可省略
# 用于模拟浏览器发送请求的方法
# url: 包含有效的url字符串
# data: 指定了附加发送给服务器数据的字符串, 默认是None(不发),即不需要提交数据,此时HTTP请求为"GET"方式
# 有这个参数时, HTTP请求将从“GET”转变为“POST”
# headers:这个参数默认为空,是一个字典,表示的是向url请求中发送头部信息,后期写爬虫程序时都需要使用到它
# 最后两个参数一般不去关心,仅仅是为了校正处理感兴趣的第三方HTTP cookies数据
# 该函数返回一个request对象
# 这个对象含有添加头部信息的方法: 即.add_header("key", "value") 的方式为HTTP头部添加信息
request.urlopen(url[, data][, timeout][, cafile][, capath][, cadefault], [context]) # 即模拟浏览器发送一个HTTP/HTTPS请求
# urlopen() 可以直接接受一个reqeust对象 作为发送请求的参数
# url: 同上 有了request对象这个就可以省略
# data: 同上 有了request对象这个就可以省略
# timeou 超时设置 默认全局超时
# cafile capath ca证书 和路径 一般可爬的不设
# cadefault 默认
# context 描述不同ssl选项的实例 一般不设
# 该方法返回一个response对象,它类似于文件句柄,可以对他进行read()操作
# 还有其他方法: 1. geturl() 返回请求服务器地址
# 2. getcode() 返回HTTP的状态响应码
# 3. info() 返回实例格式页面的元数据(一般用不到)
仪式感
from urllib import reqeust
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0"
}
url = "http://www.baidu.com/"
req = request.Request(url, headers=headers) # 构造一个reqeust请求对象
response = reqeust.urlopen(req) # 向指定的url地址发送HTTP请求返回response对象
# 得到一个html等类型的文件 decode()表示用人可以识别的方式显示
html = response.read().decode()
print(html)
一般用不到)















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









