







一. Flume群起群停服务配置
本篇中
编写Flume群起群停的脚本主要是学习当某个服务没有相应的命令停止时,如何通过灵活的杀死进程ID号来实现停止,不仅限于本篇的Flume服务
(1)创建shell脚本
首先需要在根目录下的~/bin/目录下创建一个fl.sh的脚本文件,文件功能是:实现在多个服务器上同时启动flume服务和同时停止flume服务。

(2)编写脚本
在编写此部分脚本时,我们注意到Flume对于启动有相应的nohup命令,但并没有有关服务停止的命令,那么针对于没有相关服务停止命令的脚本又该如何编写呢?

首先我们先把start部分的脚本编写保存后,在控制台先调用启动命令,之后jps查看当前进程状况:
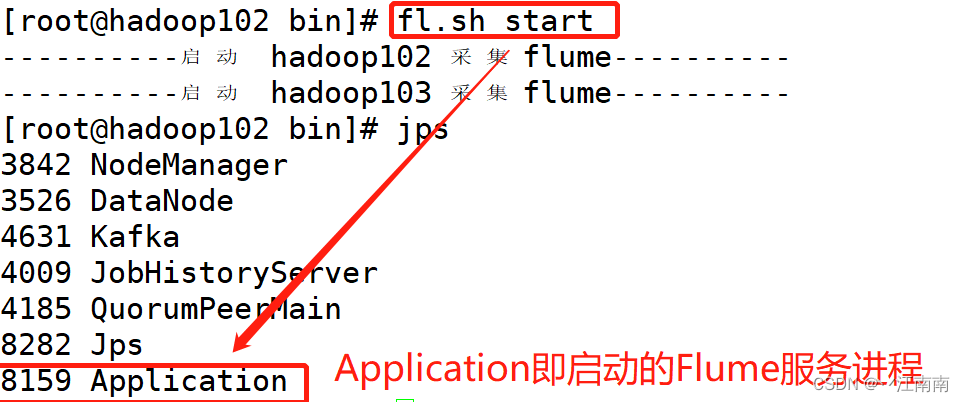
我们想到可以通过kill -9 进程ID号杀死进程的方式来停止服务,但是随时间改变,进程号也会改变,也就是说进程ID是变量,在此时刻通过kill -9 8159 确实杀死了该进程:
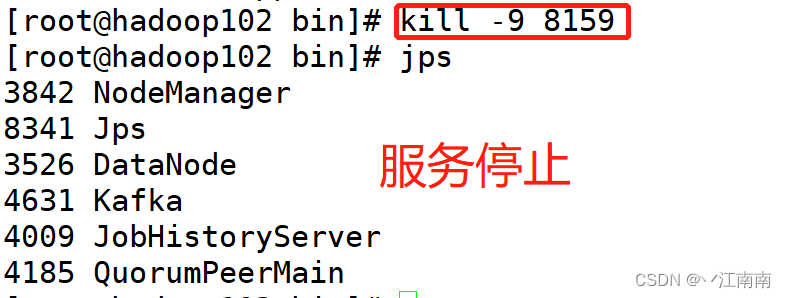
但是并不是每次的ID都是8159,显然这种方式满足不了我们的要求,因此我们想通过另外一种方式来解决这个问题:
通过ps -ef 外加grep管道过滤的方式找到我们想停止的进程状态信息,可以看到我们想要得到的是Application进程对应的ID:8436,因此我们想通过一定的linux指令实现我们的要求
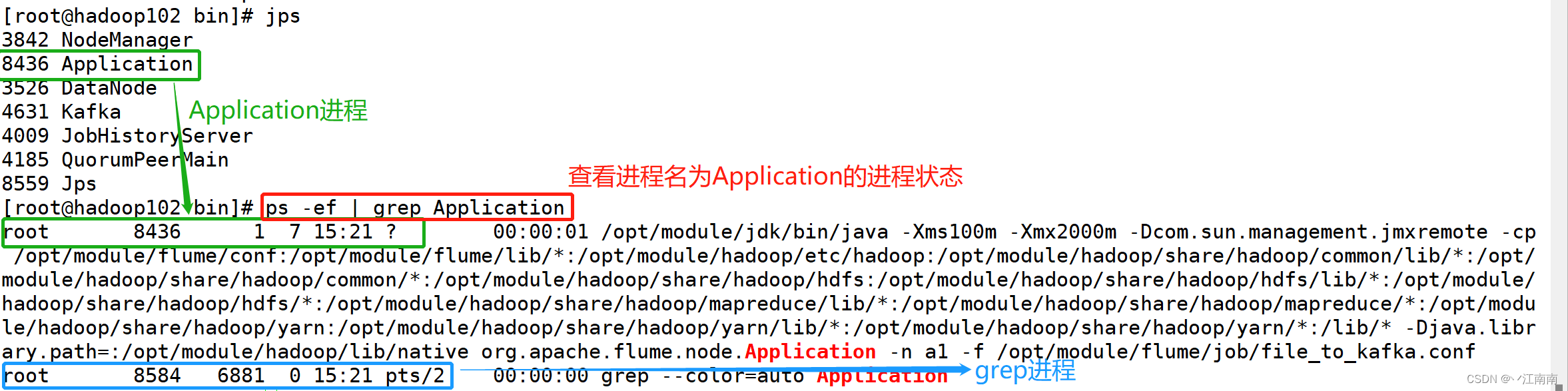
注: 这里我们一旦调用了grep管道命令来查看进程状态信息时,也会同时产生一个grep进程,所以显示在控制台的状态信息中有两条(后面有关grep进程的信息需要过滤除去)。
在原命令的base上,需要继续过滤:

到此我们把grep进程的有关信息过滤除去了,现在如何得到8436这个ID号呢?
我们想到借助之前学到的强大文本分析工具—awk命令
它把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。
这里我们仅介绍其基本用法:
awk [选项参数] 'pattern1{action1} pattern2{action2}...' filename
pattern:表示AWK在数据中查找的内容,就是匹配模式。
action:在找到匹配内容时所执行的一系列命令。
常用的选项参数:
-F:指定输入文件分隔符(不指定默认为空格分隔)
-v:赋值一个用户定义变量
-f:引入awk执行脚本
举个例子,假如我们有这样一个test.txt文本文件,文件内容如下,我们想以其中的,分隔符作分割,查找以 wangsir 开头的行数据的第二个参数(年龄)数据:
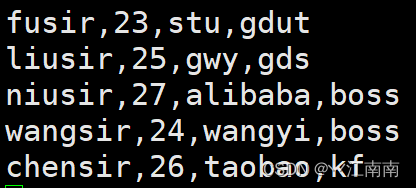
此时的命令应为:

其中,-F后跟的,表示以,为分隔符,单引号''中/^wangsir/表示以wangsir开头,{print $2}表示在查找到的以wangsir开头的行数据中输出其第二个参数,test.txt表示要操作的文本文件。
当然,回到我们想查找的进程ID号,再两次grep过滤后,同样可以通过相应的awk命令实现ID号过滤:

这里我们的进程信息由于都是空格分隔开的,所以不用指定awk的选项参数,awk '{print $2}'表示:通过空格把之前管道二次过滤后的信息分割开,分割开的数据取其中的第二个数据,也就是进程ID号:8436 ,得到这个ID号后,我们是不是可以在命令前直接加kill -9 来杀死进程呢?
通过操作我们发现出了错,原因是kill -9 后面跟的参数必须是进程ID号,而我们这样写命令,会把 ps -ef | grep Application | grep -v grep | awk '{print $2}'这个整体当作参数,这显然不是ID号,需要借助其他命令协作:

通过xargs -n1 kill -9 命令,我们把前面的输出作为后面kill -9 命令参数的输入,这样就不会产生之前的问题了,这里-n1表示每次只传递一个参数,在Application服务启动的状况下再次调用jps查看进程状态,发现该服务已经停止,到此为止我们是否完成了呢?事实上还有一种情况我们尚未考虑:

当我们另外再开一个远程连接hadoop102服务器,并开启flume服务,此时跳回原来的hadoop102查看进程发现有2个Application进程(一个job1任务,一个job2任务),此时通过群停stop指令后再次查看进程发现两个Application都被杀死了。
实际生产中,我们可能有时需要仅kill掉其中一个,事实上,命令ps -ef | grep Application并不只是单单过滤进程名,下图中被圈住部分的内容都可以作为grep后面的参数,即只要grep后面的参数出现在了被圈的部分当中就可以被过滤出来,那么我们就需要找一个能唯一标识的子字符串,由于file_to_kafka.conf文件在同一台机器上只会启动一次,因此可以拿它作为唯一标识符:

因此我们最终是用ps -ef | grep file_to_kafka命令
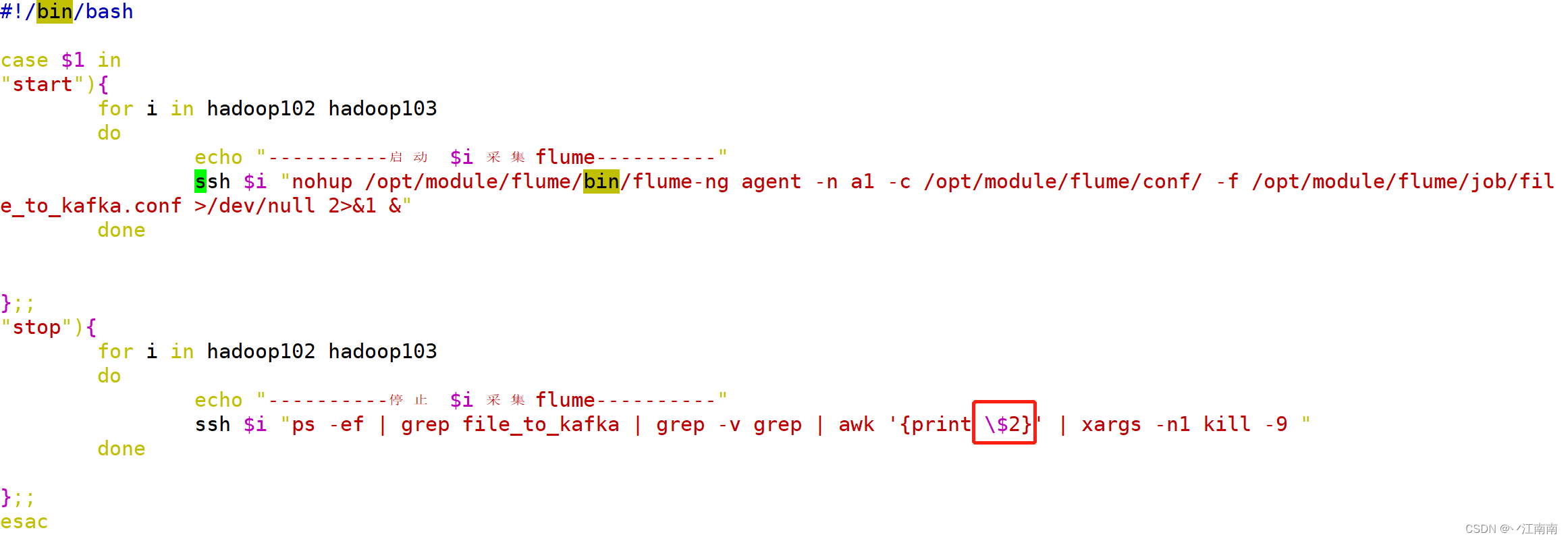
由此我们便最终完成了Flume群起群停的脚本编写,完整的shell脚本如下:
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo "----------启动 $i 采集flume----------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/job/file_to_kafka.conf >/dev/null 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo "----------停止 $i 采集flume----------"
ssh $i "ps -ef | grep file_to_kafka | grep -v grep | awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac
注:这里我们发现一个小细节,
awk命令后{}内使用了\$2而不是$2,是因为在该shell脚本中,开头我们使用了case判断,其中用到了$1参数,这里的$1代表的是未来在控制台控制群起群停的参数(start/stop),为了避免混淆,在后面stop部分的脚本代码中的$2是awk命令的参数,并不是未来在控制台我们输入的参数,因此需要加一个反斜杠\表示该$2是awk命令中的参数。

















 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











