







本篇并没有介绍Zookeeper的本地与集群安装部署,相关操作都是基于本地或者集群已部署的条件下进行的。
目录
一. Zookeeper入门
1.1 概述
Zookeeper 是一个开源的分布式的,为分布式框架提供协调服务的 Apache 项目。
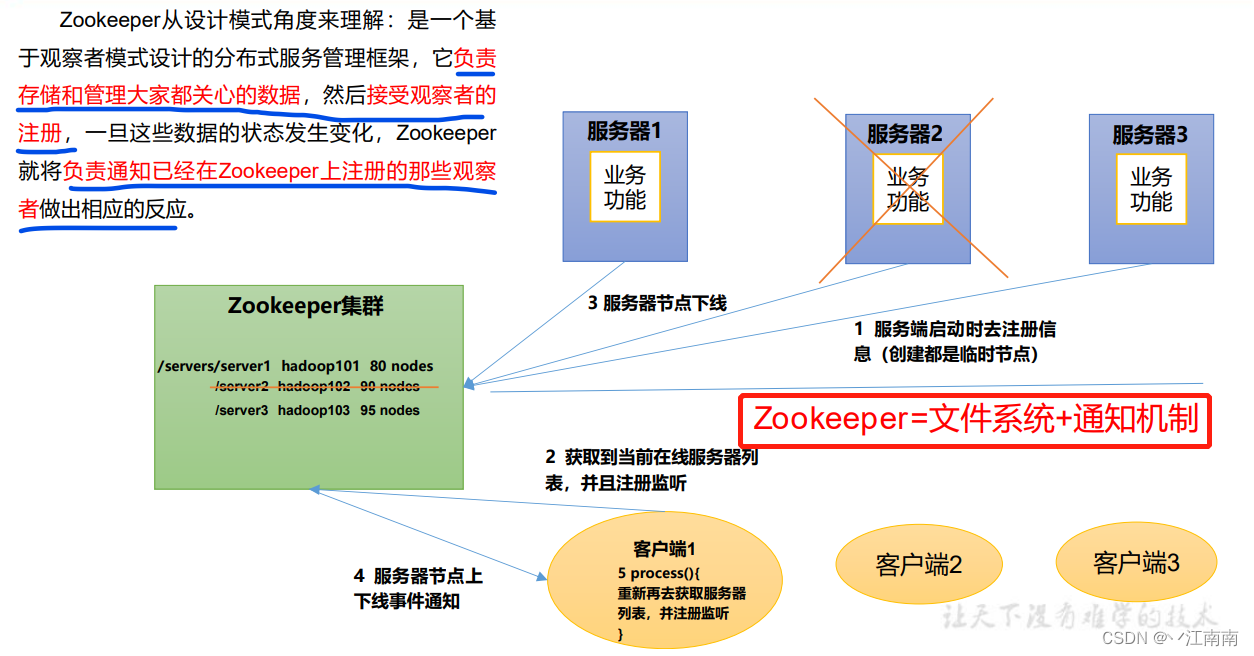
1.2 特点

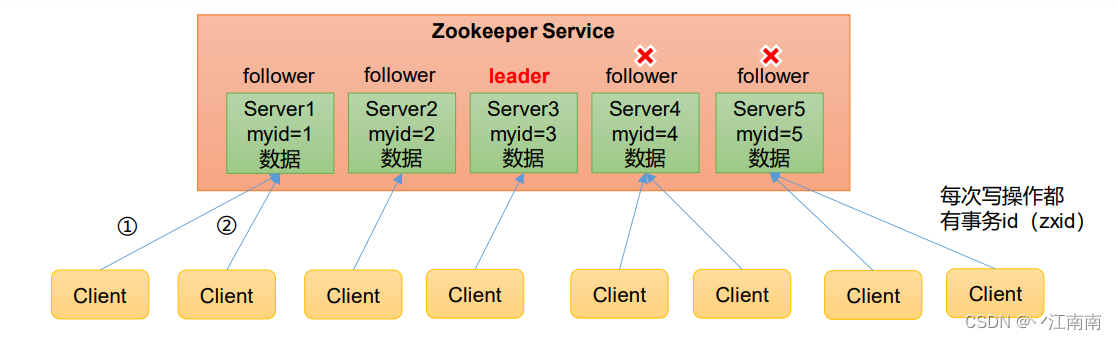
1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
2)集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所 以Zookeeper适合安装奇数台服务器。
3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
4)更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行。
5)数据更新原子性,一次数据更新要么成功,要么失败。
6)实时性,在一定时间范围内,Client能读到最新数据。
1.3 数据结构
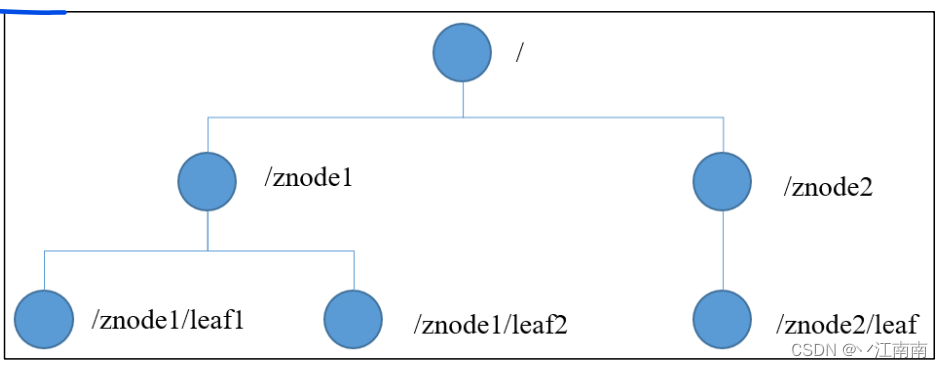
ZooKeeper 数据模型的结构与 Unix 文件系统很类似,整体上可以看作是一棵树,每个节点称做一个 ZNode。每一个ZNode默认能够存储1MB的数据,每个 ZNode 都可以通过其路径唯一标识。
1.4 应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
(1)统一命名服务
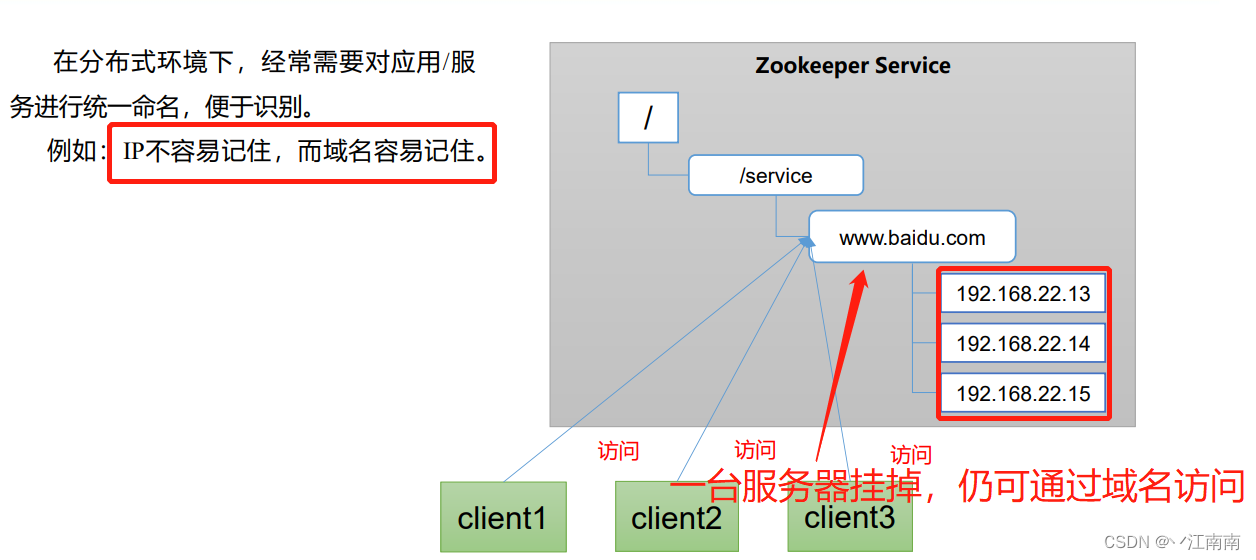
(2)统一配置管理
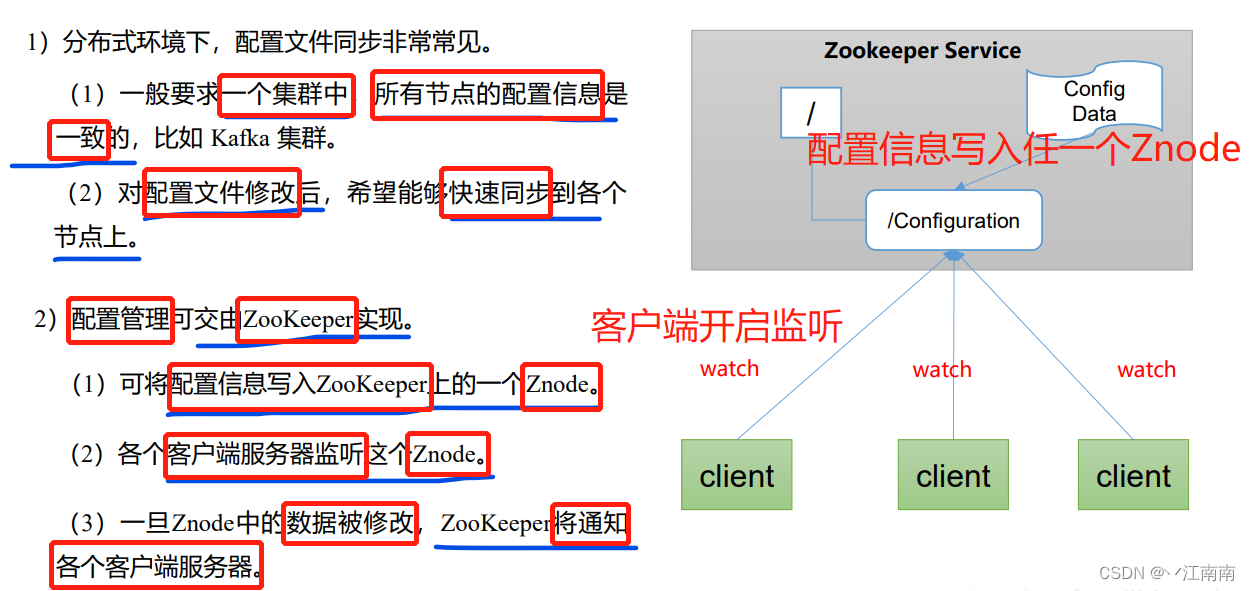
(3)统一集群管理
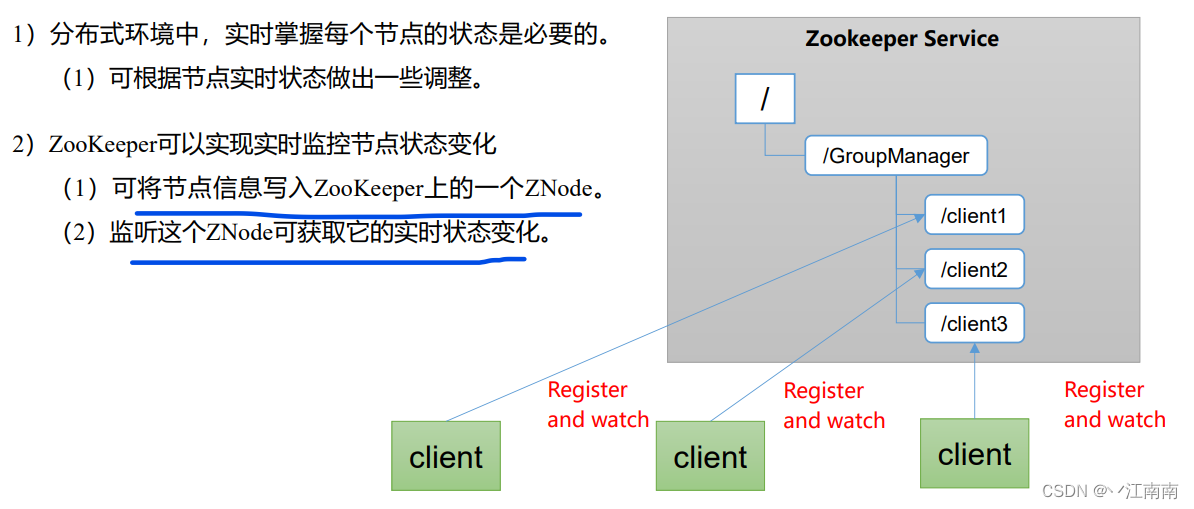
(4)服务器动态上下线
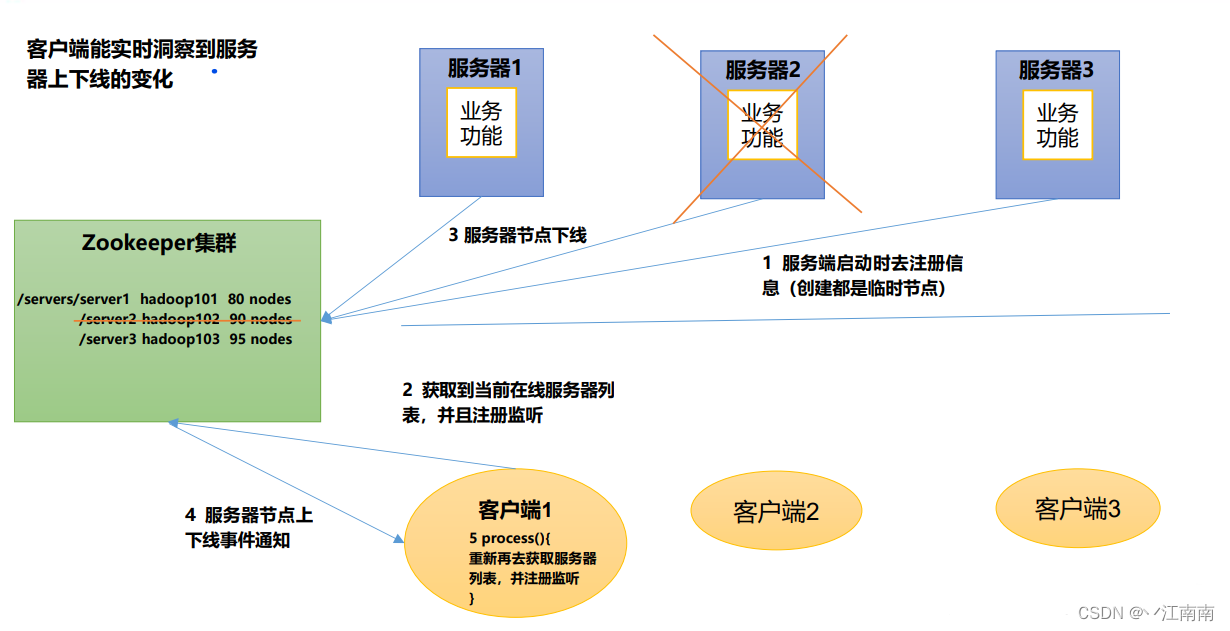
(5)转负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求:
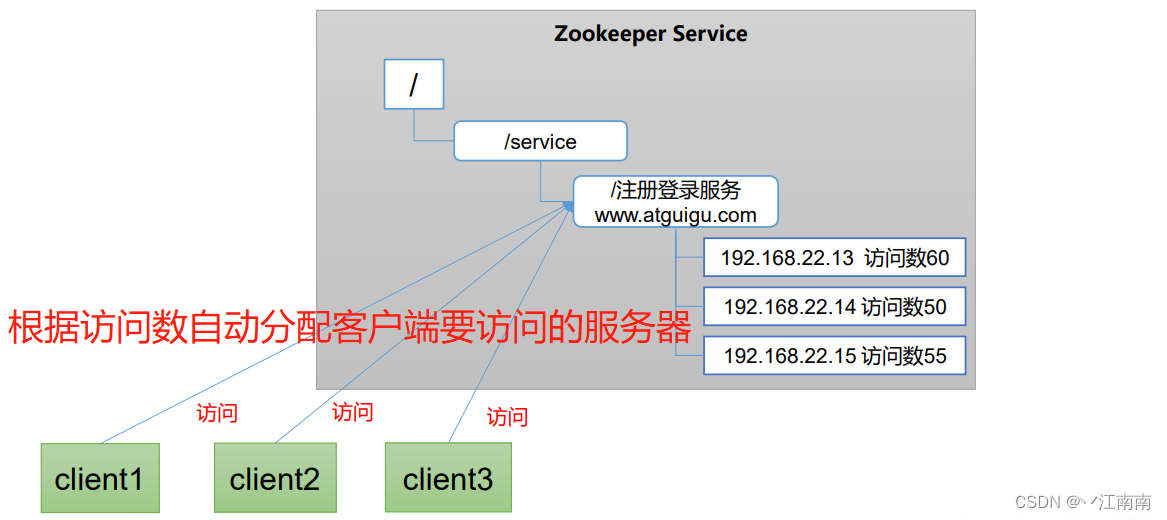
1.5 配置参数
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
1)tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒

2)initLimit = 10:LF初始通信时限
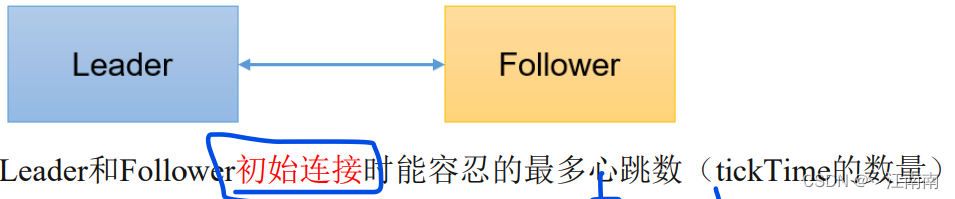
Leader服务器与Follower服务器第一次连接时,通信的最大时限为initLimit*tickTime,当超过时限意为连接失败。
3)syncLimit = 5:LF同步通信时限

Leader服务器与Follower服务器建立第一次连接以后,如果两服务器通信时间超过syncLimit*tickTime,那么Leader服务器认为Follower服务器已挂掉,自动删除Follower服务器。
4)dataDir:保存Zookeeper中的数据
注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录
5)clientPort = 2181:客户端连接端口,通常不做修改。
二. Zookeeper集群操作
2.1 选举机制
1)第一次启动
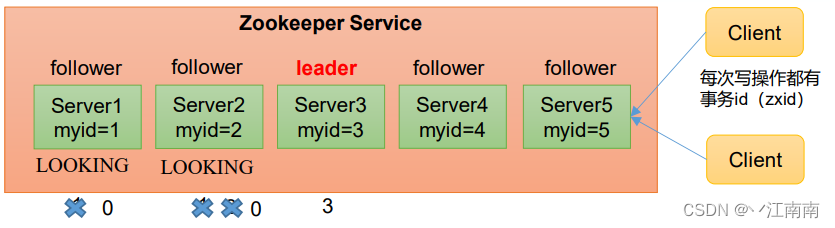
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
2)非第一次启动

(1)当ZooKeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
• 服务器初始化启动。
• 服务器运行期间无法和Leader保持连接。
(2)而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
• 集群中本来就已经存在一个Leader。
对于第一种已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连接,并进行状态同步即可。
• 集群中确实不存在Leader。

注:
(1)SID:服务器ID。用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致。
(2)ZXID:事务ID。ZXID是一个事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID值不一定完全一致,这和ZooKeeper服务器对于客户端“更新请求”的处理逻辑有关。
(3)Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加。
总结:
半数机制,超过半数的投票通过,即通过。
(1)第一次启动选举规则:
投票过半数时,SID大的胜出
(2)第二次启动选举规则:
①EPOCH 大的直接胜出
②EPOCH 相同,ZXID 大的胜出
③ZXID 相同,SID大的胜出
2.2 客户端命令行操作
2.2.1 命令行语法

1)启动客户端
客户端进入显示:

2)显示所有操作命令
2.2.2 znode节点数据信息
1)查看当前znode中所包含的内容

2)查看当前节点详细数据
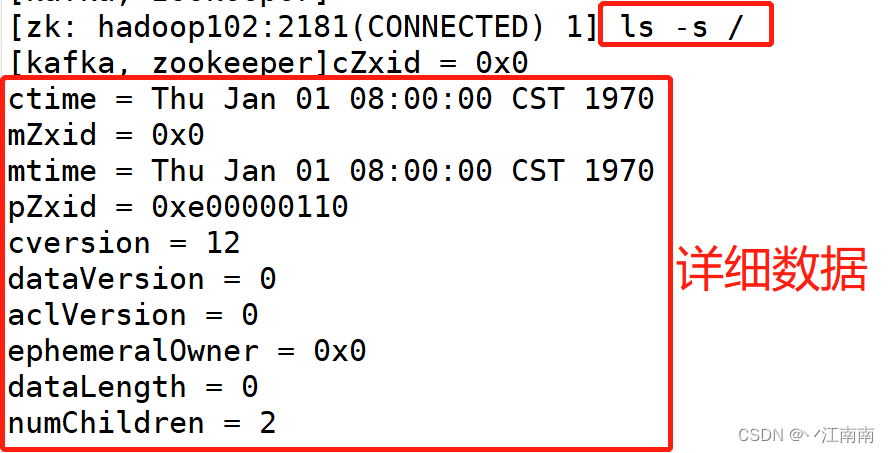
(1)czxid:创建节点的事务 zxid
每次修改 ZooKeeper 状态都会产生一个 ZooKeeper 事务 ID。事务 ID 是 ZooKeeper 中所有修改总的次序。每次修改都有唯一的 zxid,如果 zxid1 小于 zxid2,那么 zxid1 在 zxid2 之前发生。
(2)ctime:znode 被创建的毫秒数(从 1970 年开始)
(3)mzxid:znode 最后更新的事务 zxid
(4)mtime:znode 最后修改的毫秒数(从 1970 年开始)
(5)pZxid:znode 最后更新的子节点 zxid
(6)cversion:znode 子节点变化号,znode 子节点修改次数
(7)dataversion:znode 数据变化号
(8)aclVersion:znode 访问控制列表的变化号
(9)ephemeralOwner:如果是临时节点,这个是 znode 拥有者的 session id。如果不是临时节点则是 0。
(10)dataLength:znode 的数据长度
(11)numChildren:znode 子节点数量
2.2.3 节点类型(持久/短暂/有序号/无序号)
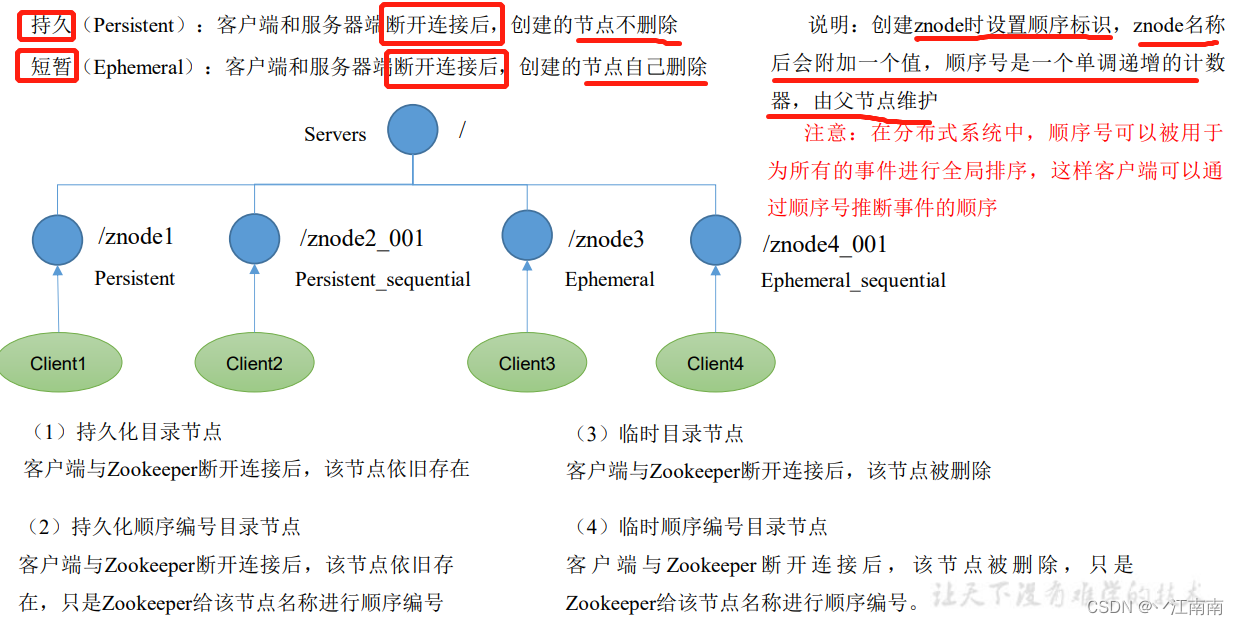
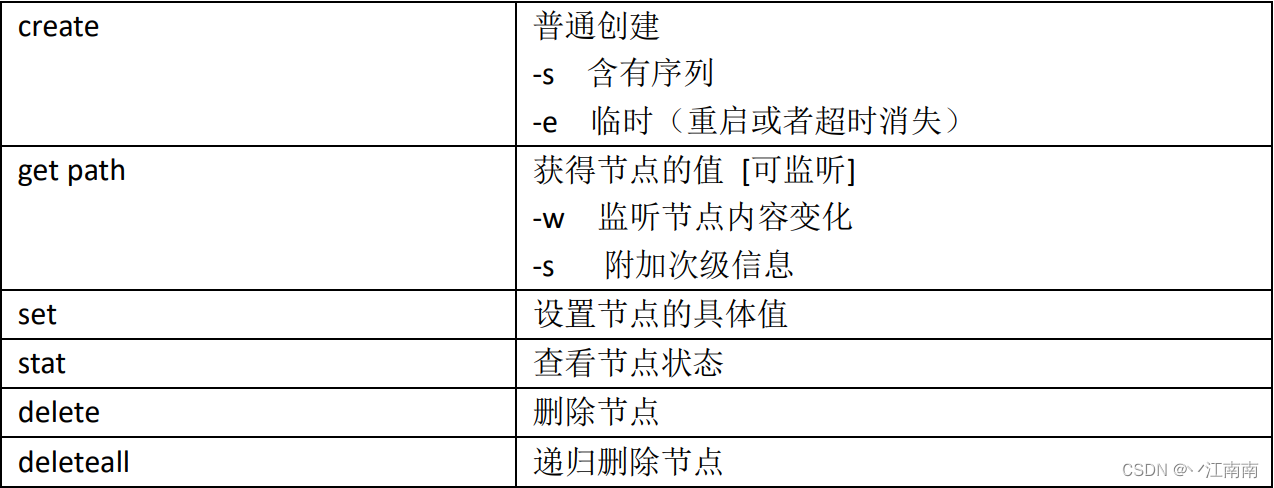
1)分别创建2个普通节点(永久节点 + 不带序号)

注:创建节点时,一定要赋值!!!
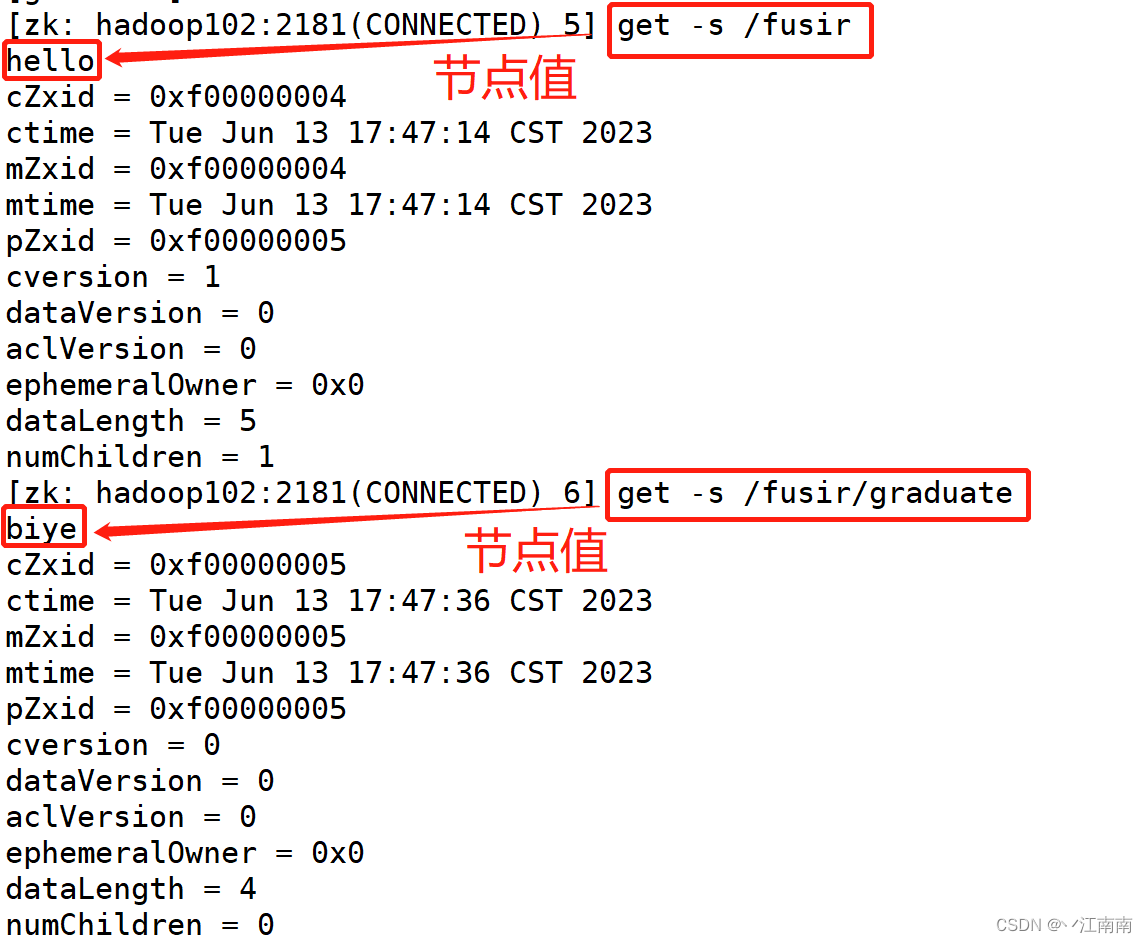
2)获得节点的值
3)创建带序号的节点(永久节点 + 带序号)
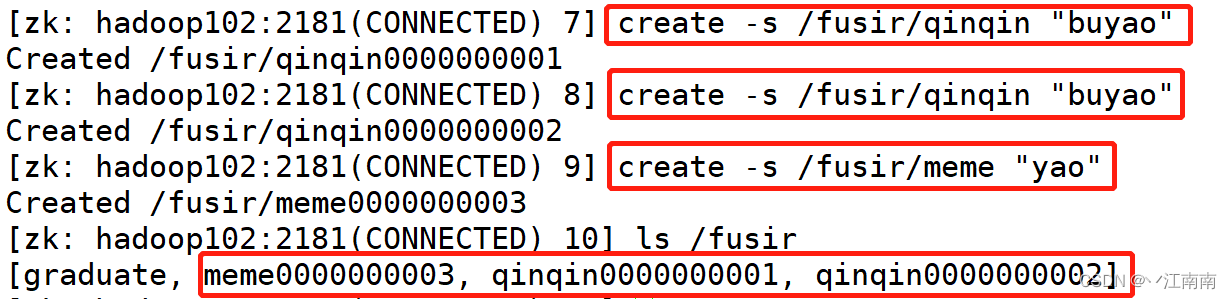
4)创建短暂节点(短暂节点 + 不带序号 or 带序号)
(1)创建短暂的不带序号的节点

(2)创建短暂的带序号的节点

(3)在当前客户端是能查看到的

(4)退出当前客户端然后再重启客户端,再次查看根目录下短暂节点已经删除

5)修改节点数据值
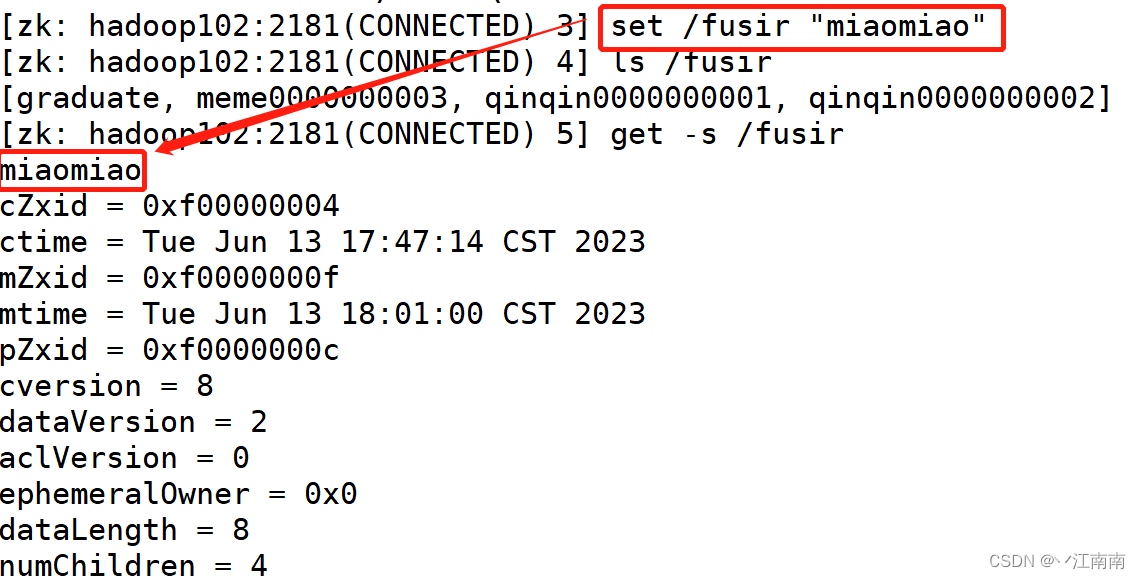
2.2.4 监听器原理
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、节点删除、子目录节点增加删除)时,ZooKeeper 会通知客户端。监听机制保证 ZooKeeper 保存的任何的数据的任何改变都能快速的响应到监听了该节点的应用程序。
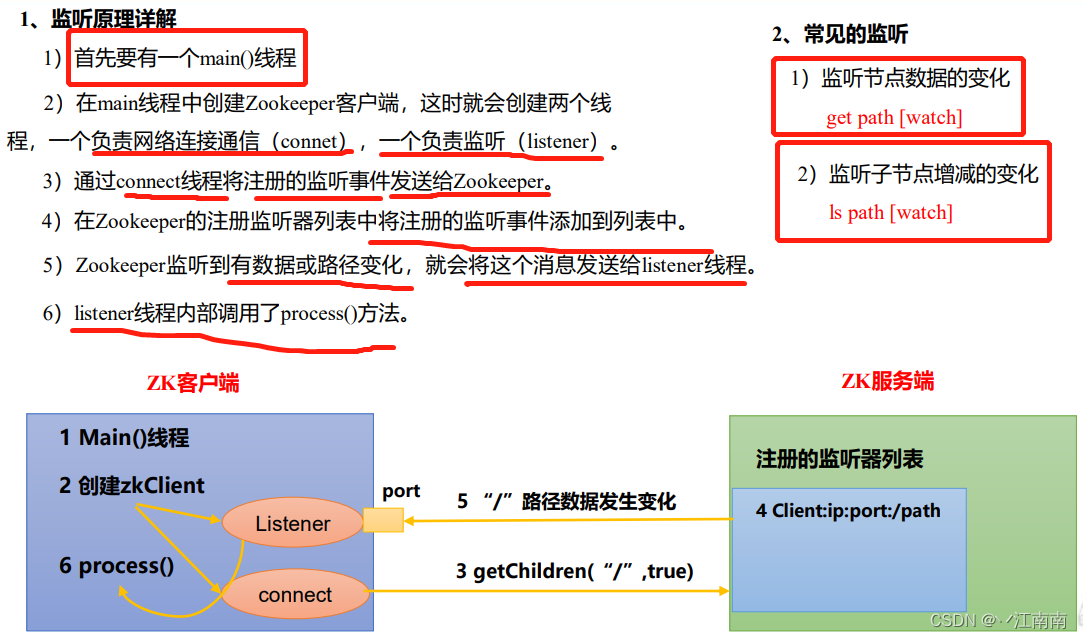
1)节点的值变化监听
在 hadoop102主机上修改/fusir 节点的数据,在 hadoop104 主机上注册监听/fusir 节点数据变化,并观察 hadoop104 主机收到数据变化的监听:

注意:在hadoop102再多次修改/fusir的值,hadoop104上不会再收到监听。因为注册一次,只能监听一次。想再次监听,需要再次注册。
2)节点的子节点变化监听(路径变化)
在 hadoop102主机/fusir节点上创建子节点,在 hadoop104 主机上注册监听/fusir 节点的子节点变化,并观察 hadoop104 主机收到子节点变化的监听:


注意:节点的路径变化,也是注册一次,生效一次。想多次生效,就需要多次注册.
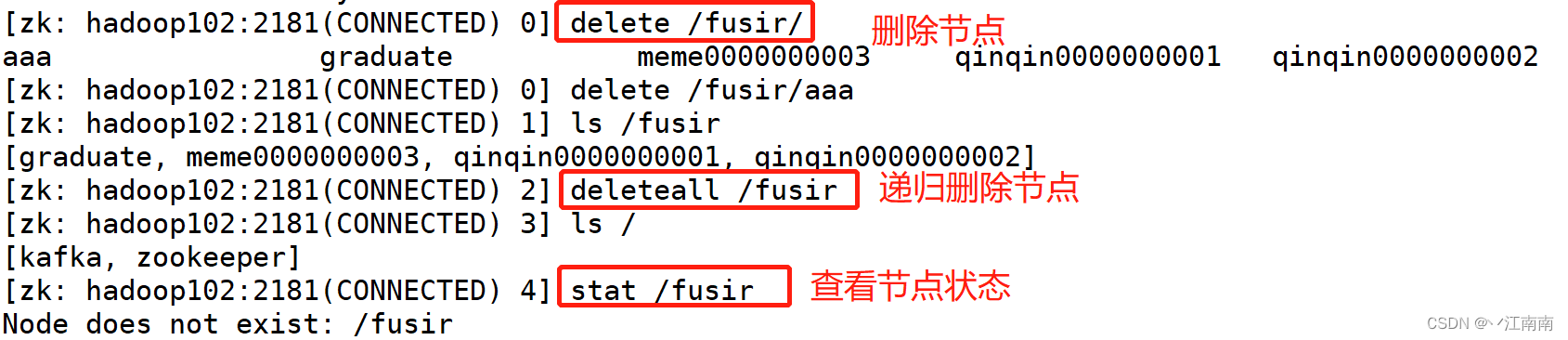
2.2.5 节点删除与查看
删除节点,递归删除节点,查看节点状态:
2.3 客户端API操作
前提:保证 hadoop102、hadoop103、hadoop104 服务器上Zookeeper 集群服务端启动。
2.3.1 IDEA环境搭建
1)创建一个工程:zookeeper
2)添加pom文件
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.7</version>
</dependency>
</dependencies>
3)拷贝log4j.properties文件到项目根目录
需要在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c]- %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c]- %m%n
4)创建包名com.atguigu.zk
5)创建类名称zkClient
2.3.2 创建ZooKeeper客户端
private static String connectString ="hadoop102:2181,hadoop103:2181,hadoop104:2181";
private static int sessionTimeout = 2000;
private ZooKeeper zkClient = null;
@Before
public void init() throws Exception {
zkClient = new ZooKeeper(connectString, sessionTimeout, new
Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
// 收到事件通知后的回调函数(用户的业务逻辑)
System.out.println(watchedEvent.getType() + "--"
+ watchedEvent.getPath());
// 再次启动监听
try {
List<String> children = zkClient.getChildren("/",
true);
for (String child : children) {
System.out.println(child);
}
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
2.3.3 创建子节点
// 创建子节点
@Test
public void create() throws Exception {
// 参数 1:要创建的节点的路径; 参数 2:节点数据 ; 参数 3:节点权限 ;
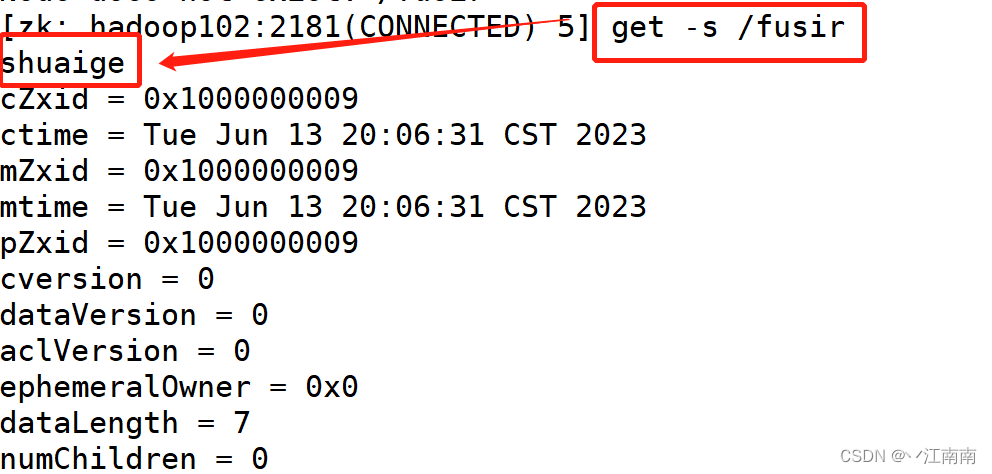
String nodeCreated = zkClient.create("/fusir",
"shuaige".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
测试:在 hadoop102 的 zk 客户端上查看创建节点情况:
2.3.4 获取子节点并监听节点变化
// 获取子节点
@Test
public void getChildren() throws Exception {
List<String> children = zkClient.getChildren("/", true);
for (String child : children) {
System.out.println(child);
}
// 延时阻塞
Thread.sleep(Long.MAX_VALUE);
}
(1)在 IDEA 控制台上看到如下节点:

(2)在 hadoop102 的客户端上创建再创建一个节点/fusir1,观察 IDEA 控制台:


(3)在 hadoop102 的客户端上删除节点/atguigu1,观察 IDEA 控制台:

2.3.5 判断Znode是否存在
// 判断 znode 是否存在
@Test
public void exist() throws Exception {
Stat stat = zkClient.exists("/fusir", false);
System.out.println(stat == null ? "not exist" : "exist");
}
















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











