







机器学习深版01:数据清洗
文章目录
1.极大似然估计

独立同分布:P(x1,x2,x3)= P(x1) P(x2) P(x3)
不是的话:P(x1,x2,x3)= P(x1|x2,x3) P(x2|x3) P(x3)
1. 二项分布:抛硬币的例子
理解最大似然估计:就是找出p可以让P得到最大值

一般会取对数再进行运算

2. 高斯分布
认为他们是独立的,所以进行乘积。

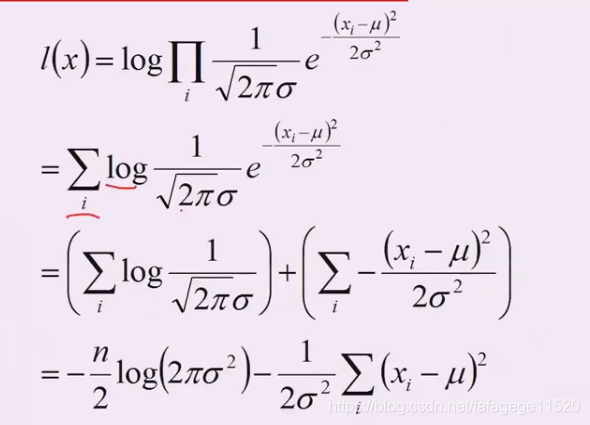

3. 最大似然估计与过拟合
案例中取值5实际是:拉普拉斯平滑

2.数据清洗与特征选择
1. 庄家与赔率

2. Nagel-Schreckenberg交通流模型

3. Pandas数据读取与处理
没有详细说
4. Fuzzywuzzy字符串模糊查找
Levenshtein 距离:两个字符串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。一般来说,编辑距离越小,两个串的相似度越大。
5. 数据清洗和校正
鸢尾花数据集:
- 有特征值过多,显示上不好画图:方法就是画图:主成分分析PCA
- 其他特征在其他维度上投影,投影之后计算方差使得最大
- 用x的转置 * 它本身,得到一个对称矩阵,得到它的特征值和特征向量,然后得到这四个是两两垂直的,取这里面的最大值做主成分。
- 理解事先做一些降维工作,不是丢失信息:

3.!!代码代码
1.Prime
#!/usr/bin/python
# -*- coding:utf-8 -*-
import operator
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from time import time
import math
def is_prime(x):
return 0 not in [x % i for i in range(2, int(math.sqrt(x)) + 1)]
def is_prime3(x):
flag = True
for p in p_list2:
if p > math.sqrt(x):
break
if x % p == 0:
flag = False
break
if flag:
p_list2.append(x)
return flag
if __name__ == "__main__":
a = 2
b = 100000
# 方法1:直接计算
t = time()
p = [p for p in range(a, b) if 0 not in [p % d for d in range(2, int(math.sqrt(p)) + 1)]]
print time() - t
print p
# 方法2:利用filter
t = time()
p = filter(is_prime, range(a, b))
print time() - t
print p
# 方法3:利用filter和lambda
t = time()
is_prime2 = (lambda x: 0 not in [x % i for i in range(2, int(math.sqrt(x)) + 1)])
p = filter(is_prime2, range(a, b))
print time() - t
print p
# 方法4:定义
t = time()
p_list = []
for i in range(2, b):
flag = True
for p in p_list:
if p > math.sqrt(i):
break
if i % p == 0:
flag = False
break
if flag:
p_list.append(i)
print time() - t
print p_list
# 方法5:定义和filter
p_list2 = []
t = time()
filter(is_prime3, range(2, b))
print time() - t
print p_list2
print '---------------------'
a = 1180
b = 1230
a = 1600
b = 1700
p_list2 = []
p = np.array(filter(is_prime3, range(2, b+1)))
p = p[p >= a]
print p
p_rate = float(len(p)) / float(b-a+1)
print '素数的概率:', p_rate, '\t',
print '公正赔率:', 1/p_rate
print '合数的概率:', 1-p_rate, '\t',
print '公正赔率:', 1 / (1-p_rate)
2.交通模型
#!/usr/bin/python
# -*- coding:utf-8 -*-
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
def clip(x, path):
for i in range(len(x)):
if x[i] >= path:
x[i] %= path
if __name__ == "__main__":
#这是绘图风格
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
path = 5000 # 环形公路的长度
n = 100 # 公路中的车辆数目
v0 = 50 # 车辆的初始速度
p = 0.3 # 随机减速概率
Times = 3000
np.random.seed(0) #当我们设置相同的seed,每次生成的随机数相同。
x = np.random.rand(n) * path #可以返回一个或一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。
x.sort() #排序
v = np.tile([v0], n).astype(np.float) # 扩大数组,见下面。扩大成了100个初速度为50的数组
plt.figure(figsize=(10, 8), facecolor='w')
for t in range(Times):
plt.scatter(x, [t]*n, s=1, c='k', alpha=0.05) #绘制散点图
# x是5000上服从正态分布 【t是时间】*n是车辆数目=1*n的数组(y是时间,x是位置)
for i in range(n):
if x[(i+1)%n] > x[i]:
d = x[(i+1) % n] - x[i] # 距离前车的距离
else:
d = path - x[i] + x[(i+1) % n]
if v[i] < d:
if np.random.rand() > p:
v[i] += 1
else:
v[i] -= 1
else:
v[i] = d - 1
v = v.clip(0, 150)
x += v
clip(x, path)
plt.xlim(0, path)
plt.ylim(0, Times)
plt.xlabel(u'车辆位置', fontsize=16)
plt.ylabel(u'模拟时间', fontsize=16)
plt.title(u'环形公路车辆堵车模拟', fontsize=20)
plt.tight_layout(pad=2)
plt.show()


3. Pandas
#!/usr/bin/python
# -*- encoding: utf-8
import numpy as np
import pandas as pd
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
def enum_row(row):
print( row['state'])
def find_state_code(row):
if row['state'] != 0:
print (process.extractOne(row['state'], states, score_cutoff=80))
def capital(str):
return str.capitalize()
def correct_state(row):
if row['state'] != 0:
state = process.extractOne(row['state'], states, score_cutoff=80)
if state:
state_name = state[0]
return ' '.join(map(capital, state_name.split(' ')))
return row['state']
def fill_state_code(row):
if row['state'] != 0:
state = process.extractOne(row['state'], states, score_cutoff=80)
if state:
state_name = state[0]
return state_to_code[state_name]
return ''
if __name__ == "__main__":
pd.set_option('display.width', 200)
# 解决pandas.read_excel() 列数多时会省略
data = pd.read_excel('sales.xlsx', sheetname='sheet1', header=0)
# 读取excel文件
print ('data.head() = \n', data.head())
print ('data.tail() = \n', data.tail())
print ('data.dtypes = \n', data.dtypes)
print( 'data.columns = \n', data.columns)
for c in data.columns:
print (c,)
data['total'] = data['Jan'] + data['Feb'] + data['Mar']
print(data['total'])
print(data.head())
print(data['Jan'].sum())
print (data['Jan'].min())
print( data['Jan'].max())
print (data['Jan'].mean())
print( '=============')
# 添加一行
s1 = data[['Jan', 'Feb', 'Mar', 'total']].sum()
print (s1)
s2 = pd.DataFrame(data=s1)
print( s2)
print (s2.T)
print (s2.T.reindex(columns=data.columns))
# 即:
s = pd.DataFrame(data=data[['Jan', 'Feb', 'Mar', 'total']].sum()).T
s = s.reindex(columns=data.columns, fill_value=0)
print (s)
data = data.append(s, ignore_index=True)
data = data.rename(index={15:'Total'})
print( data.tail())
# apply的使用
print( '==============apply的使用==========')
# 对DataFrame对象中的某些行或列,或者对DataFrame对象中的所有元素进行某种运算或操作
#我们无需利用低效笨拙的循环,DataFrame给我们分别提供了相应的直接而简单的方法
#apply()和applymap()。
data.apply(enum_row, axis=1)
state_to_code = {"VERMONT": "VT", "GEORGIA": "GA", "IOWA": "IA", "Armed Forces Pacific": "AP", "GUAM": "GU",
"KANSAS": "KS", "FLORIDA": "FL", "AMERICAN SAMOA": "AS", "NORTH CAROLINA": "NC", "HAWAII": "HI",
"NEW YORK": "NY", "CALIFORNIA": "CA", "ALABAMA": "AL", "IDAHO": "ID",
"FEDERATED STATES OF MICRONESIA": "FM",
"Armed Forces Americas": "AA", "DELAWARE": "DE", "ALASKA": "AK", "ILLINOIS": "IL",
"Armed Forces Africa": "AE", "SOUTH DAKOTA": "SD", "CONNECTICUT": "CT", "MONTANA": "MT",
"MASSACHUSETTS": "MA",
"PUERTO RICO": "PR", "Armed Forces Canada": "AE", "NEW HAMPSHIRE": "NH", "MARYLAND": "MD",
"NEW MEXICO": "NM",
"MISSISSIPPI": "MS", "TENNESSEE": "TN", "PALAU": "PW", "COLORADO": "CO",
"Armed Forces Middle East": "AE",
"NEW JERSEY": "NJ", "UTAH": "UT", "MICHIGAN": "MI", "WEST VIRGINIA": "WV", "WASHINGTON": "WA",
"MINNESOTA": "MN", "OREGON": "OR", "VIRGINIA": "VA", "VIRGIN ISLANDS": "VI",
"MARSHALL ISLANDS": "MH",
"WYOMING": "WY", "OHIO": "OH", "SOUTH CAROLINA": "SC", "INDIANA": "IN", "NEVADA": "NV",
"LOUISIANA": "LA",
"NORTHERN MARIANA ISLANDS": "MP", "NEBRASKA": "NE", "ARIZONA": "AZ", "WISCONSIN": "WI",
"NORTH DAKOTA": "ND",
"Armed Forces Europe": "AE", "PENNSYLVANIA": "PA", "OKLAHOMA": "OK", "KENTUCKY": "KY",
"RHODE ISLAND": "RI",
"DISTRICT OF COLUMBIA": "DC", "ARKANSAS": "AR", "MISSOURI": "MO", "TEXAS": "TX", "MAINE": "ME"}
states = state_to_code.keys()
print (fuzz.ratio('Python Package', 'PythonPackage'))# 计算二者的相似度
print (process.extract('Mississippi', states))
print (process.extract('Mississipi', states, limit=1))
print (process.extractOne('Mississipi', states))
data.apply(find_state_code, axis=1)
print( 'Before Correct State:\n', data['state'])
data['state'] = data.apply(correct_state, axis=1)
print ('After Correct State:\n', data['state'])
data.insert(5, 'State Code', np.nan)
data['State Code'] = data.apply(fill_state_code, axis=1)
print( data)
# group by
print ('==============group by================')
print (data.groupby('State Code'))
print ('All Columns:\n')
print (data.groupby('State Code').sum())
print ('Short Columns:\n')
print (data[['State Code', 'Jan', 'Feb', 'Mar', 'total']].groupby('State Code').sum())
# 写入文件
data.to_excel('sales_result.xls', sheet_name='Sheet1', index=False)

4. 鸢尾花
# -*- coding:utf-8 -*-
%matplotlib inline
import pandas as pd
import numpy as np
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegressionCV
from sklearn import metrics
from sklearn.model_selection import train_test_split
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
def extend(a, b):
return 1.05*a-0.05*b, 1.05*b-0.05*a
if __name__ == '__main__':
pd.set_option('display.width', 200)
data = pd.read_csv('iris.data', header=None) #读取数据
columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'type']
data.rename(columns=dict(zip(np.arange(5), columns)), inplace=True)
# {0: 'sepal_length', 1: 'sepal_width', 2: 'petal_length', 3: 'petal_width', 4: 'type'}
# zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
'''
>>>a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
[(1, 2, 3), (4, 5, 6)]
'''
data['type'] = pd.Categorical(data['type']).codes
# 把类别用012代替了
# d.Categorical( list ).codes 这样就可以直接得到原始数据的对应的序号列表,通过这样的处理可以将类别信息转化成数值信息
print( data.head(5))
x = data.loc[:, columns[:-1]]
y = data['type']
'''
PCA可以把具有相关性的高维变量合成线性无关的低维变量。
新的低维数据集尽可能保留原始数据的变量。
当数据集不同维度上的方差分布不均匀的时候,PCA最有用。
(如果是一个球壳型数据集,PCA不能有效的发挥作用,因为各个方向上的方差基本相等。
若一个维度没有丢失大量的信息的话,该维度一定不能忽略。)
'''
pca = PCA(n_components=2, whiten=True, random_state=0)
#whiten 白化. 每个特征的标准偏差是否一致。默认default,一般改成whiten=True
x = pca.fit_transform(x)
print( '各方向方差:', pca.explained_variance_)
print( '方差所占比例:', pca.explained_variance_ratio_)
print( x[:5])
# 设置颜色
cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
# 设置模板颜色
mpl.rcParams['font.sans-serif'] = u'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
plt.figure(facecolor='w')
plt.scatter(x[:, 0], x[:, 1], s=30, c=y, marker='o', cmap=cm_dark)
plt.grid(b=True, ls=':')
plt.xlabel(u'组份1', fontsize=14)
plt.ylabel(u'组份2', fontsize=14)
plt.title(u'鸢尾花数据PCA降维', fontsize=18)
# plt.savefig('1.png')
plt.show()
x, x_test, y, y_test = train_test_split(x, y, train_size=0.7)
model = Pipeline([
('poly', PolynomialFeatures(degree=2, include_bias=True)),
('lr', LogisticRegressionCV(Cs=np.logspace(-3, 4, 8), cv=5, fit_intercept=False))
])
model.fit(x, y)
print ('最优参数:', model.get_params('lr')['lr'].C_)
y_hat = model.predict(x)
print( '训练集精确度:', metrics.accuracy_score(y, y_hat))
y_test_hat = model.predict(x_test)
print ('测试集精确度:', metrics.accuracy_score(y_test, y_test_hat))
N, M = 500, 500 # 横纵各采样多少个值
x1_min, x1_max = extend(x[:, 0].min(), x[:, 0].max()) # 第0列的范围
x2_min, x2_max = extend(x[:, 1].min(), x[:, 1].max()) # 第1列的范围
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_show = np.stack((x1.flat, x2.flat), axis=1) # 测试点
y_hat = model.predict(x_show) # 预测值
y_hat = y_hat.reshape(x1.shape) # 使之与输入的形状相同
plt.figure(facecolor='w')
plt.pcolormesh(x1, x2, y_hat, cmap=cm_light) # 预测值的显示
plt.scatter(x[:, 0], x[:, 1], s=30, c=y, edgecolors='k', cmap=cm_dark) # 样本的显示
plt.xlabel(u'组份1', fontsize=14)
plt.ylabel(u'组份2', fontsize=14)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid(b=True, ls=':')
patchs = [mpatches.Patch(color='#77E0A0', label='Iris-setosa'),
mpatches.Patch(color='#FF8080', label='Iris-versicolor'),
mpatches.Patch(color='#A0A0FF', label='Iris-virginica')]
plt.legend(handles=patchs, fancybox=True, framealpha=0.8, loc='lower right')
plt.title(u'鸢尾花Logistic回归分类效果', fontsize=17)
# plt.savefig('2.png')
plt.show()


5. 异常值
#!/usr/bin/python
# -*- encoding: utf-8
%matplotlib inline
import numpy as np
import matplotlib as mpl
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import BaggingRegressor
# 这个东西在后面根本没用上呀!!
def read_data():
plt.figure(figsize=(13, 7), facecolor='w')
plt.subplot(121) # 一个figure对象包含了多个子图,可以使用subplot()函数来绘制子图
data = pd.read_csv('C0904.csv', header=0)
x = data['H2O'].values
plt.plot(x, 'r-', lw=1, label=u'C0904')
plt.title(u'实际排放数据0904', fontsize=18)
plt.legend(loc='upper right')
plt.grid(b=True)
plt.subplot(122)
data = pd.read_csv('C0911.csv', header=0)
x = data['H2O'].values
plt.plot(x, 'r-', lw=1, label=u'C0911')
plt.title(u'实际排放数据0911', fontsize=18)
plt.legend(loc='upper right')
plt.grid(b=True)
plt.tight_layout(2, rect=(0, 0, 1, 0.95))
plt.suptitle(u'如何找到下图中的异常值', fontsize=20)
plt.show()
if __name__ == "__main__":
# 设置基本格式
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
# read_data()
data = pd.read_csv('C0904.csv', header=0) # C0911.csv, C0904.csv
x = data['H2O'].values
print( x)
width = 500
delta = 10
eps = 0.15
N = len(x)
p = []
abnormal = []
for i in np.arange(0, N-width, delta):
s = x[i:i+width]
p.append(np.ptp(s)) # np.ptp(a)或者a.ptp()是最大值与最小值的差
if np.ptp(s) > eps:
abnormal.append(range(i, i+width))
abnormal = np.array(abnormal).flatten()
abnormal = np.unique(abnormal)
# plt.plot(p, lw=1)
# plt.grid(b=True)
# plt.show()
plt.figure(figsize=(18, 7), facecolor='w')
plt.subplot(131)
plt.plot(x, 'r-', lw=1, label=u'原始数据')
plt.title(u'实际排放数据', fontsize=18)
plt.legend(loc='upper right')
plt.grid(b=True)
plt.subplot(132)
t = np.arange(N)
plt.plot(t, x, 'r-', lw=1, label=u'原始数据')
plt.plot(abnormal, x[abnormal], 'go', markeredgecolor='g', ms=3, label=u'异常值')
plt.legend(loc='upper right')
plt.title(u'异常检测', fontsize=18)
plt.grid(b=True)
# 预测
plt.subplot(133)
select = np.ones(N, dtype=np.bool)
select[abnormal] = False
t = np.arange(N)
dtr = DecisionTreeRegressor(criterion='mse', max_depth=10)
br = BaggingRegressor(dtr, n_estimators=10, max_samples=0.3)
br.fit(t[select].reshape(-1, 1), x[select])
y = br.predict(np.arange(N).reshape(-1, 1))
y[select] = x[select]
plt.plot(x, 'g--', lw=1, label=u'原始值') # 原始值
plt.plot(y, 'r-', lw=1, label=u'校正值') # 校正值
plt.legend(loc='upper right')
plt.title(u'异常值校正', fontsize=18)
plt.grid(b=True)
plt.tight_layout(1.5, rect=(0, 0, 1, 0.95))
plt.suptitle(u'排污数据的异常值检测与校正', fontsize=22)
plt.show()
6.LR
# -*- coding:utf-8 -*-
%matplotlib inline
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegressionCV
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
import matplotlib as mpl
import matplotlib.pyplot as plt
if __name__ == '__main__':
# 设置打印时候的宽度啥的,让他不要因为行数或列数太多
pd.set_option('display.width', 300)
pd.set_option('display.max_columns', 300)
data = pd.read_csv('car.data', header=None) #读取数据
# 设置数据的标题头
n_columns = len(data.columns)
columns = ['buy', 'maintain', 'doors', 'persons', 'boot', 'safety', 'accept']
new_columns = dict(zip(np.arange(n_columns), columns))
data.rename(columns=new_columns, inplace=True)
print( data.head(10))
# one-hot编码
x = pd.DataFrame()
for col in columns[:-1]:
t = pd.get_dummies(data[col]) # get_dummies 是利用pandas实现one hot encode的方式
t = t.rename(columns=lambda x: col+'_'+str(x))
x = pd.concat((x, t), axis=1) # 见下文
print (x.head(10))
# print x.columns
y = pd.Categorical(data['accept']).codes
# 把类别用01234等等代替了
# d.Categorical( list ).codes 这样就可以直接得到原始数据的对应的序号列表,通过这样的处理可以将类别信息转化成数值信息
x, x_test, y, y_test = train_test_split(x, y, train_size=0.7)
clf = LogisticRegressionCV(Cs=np.logspace(-3, 4, 8), cv=5)
clf.fit(x, y)
print( clf.C_)
y_hat = clf.predict(x)
print( '训练集精确度:', metrics.accuracy_score(y, y_hat))
y_test_hat = clf.predict(x_test)
print( '测试集精确度:', metrics.accuracy_score(y_test, y_test_hat))
n_class = len(data['accept'].unique())
y_test_one_hot = label_binarize(y_test, classes=np.arange(n_class))
y_test_one_hot_hat = clf.predict_proba(x_test)
fpr, tpr, _ = metrics.roc_curve(y_test_one_hot.ravel(), y_test_one_hot_hat.ravel())
print ('Micro AUC:\t', metrics.auc(fpr, tpr))
print( 'Micro AUC(System):\t', metrics.roc_auc_score(y_test_one_hot, y_test_one_hot_hat, average='micro'))
auc = metrics.roc_auc_score(y_test_one_hot, y_test_one_hot_hat, average='macro')
print ('Macro AUC:\t', auc)
mpl.rcParams['font.sans-serif'] = u'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(8, 7), dpi=80, facecolor='w')
plt.plot(fpr, tpr, 'r-', lw=2, label='AUC=%.4f' % auc)
plt.legend(loc='lower right')
plt.xlim((-0.01, 1.02))
plt.ylim((-0.01, 1.02))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate', fontsize=14)
plt.ylabel('True Positive Rate', fontsize=14)
plt.grid(b=True, ls=':')
plt.title(u'ROC曲线和AUC', fontsize=18)
plt.show()





















 597
597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









