






一、个人任务
本周我的任务主要有以下两个
- 处理IU-XRay数据集
- 微调VisualGLM并记录结果
二、任务1——处理IU-XRay数据集
2.1 关于IU-XRay数据集
在该数据集中,作者收集了3996份报告,共8121张图像,实际公开:3955份报告,7470张图像。
印第安纳大学(IU)的研究人员从印第安纳州患者护理网络10数据库中的两个大型医院系统中提取了叙事性胸部X光检查报告及PA胸部X光片。并将图像和报告报告给NIH
2.2 预处理数据集
使用Mesh(医学主题词)将Finding和report编码(Manual annotation)。
- 第一个阶段,简单地将数据标为正常/不正常。
- 第二个阶段,细化不正常数据的标注(详见附录)
- 歧义词
- 同义词
- 确定会改变X射线外观的轻微,历史或偶然条件
此外,采用MTI自动编码(MTI annotation)。

2.3 将数据集转换成VisualGLM需要接受的形式
首先由团队成员刘馨瑶将数据集将英文转换成中文,
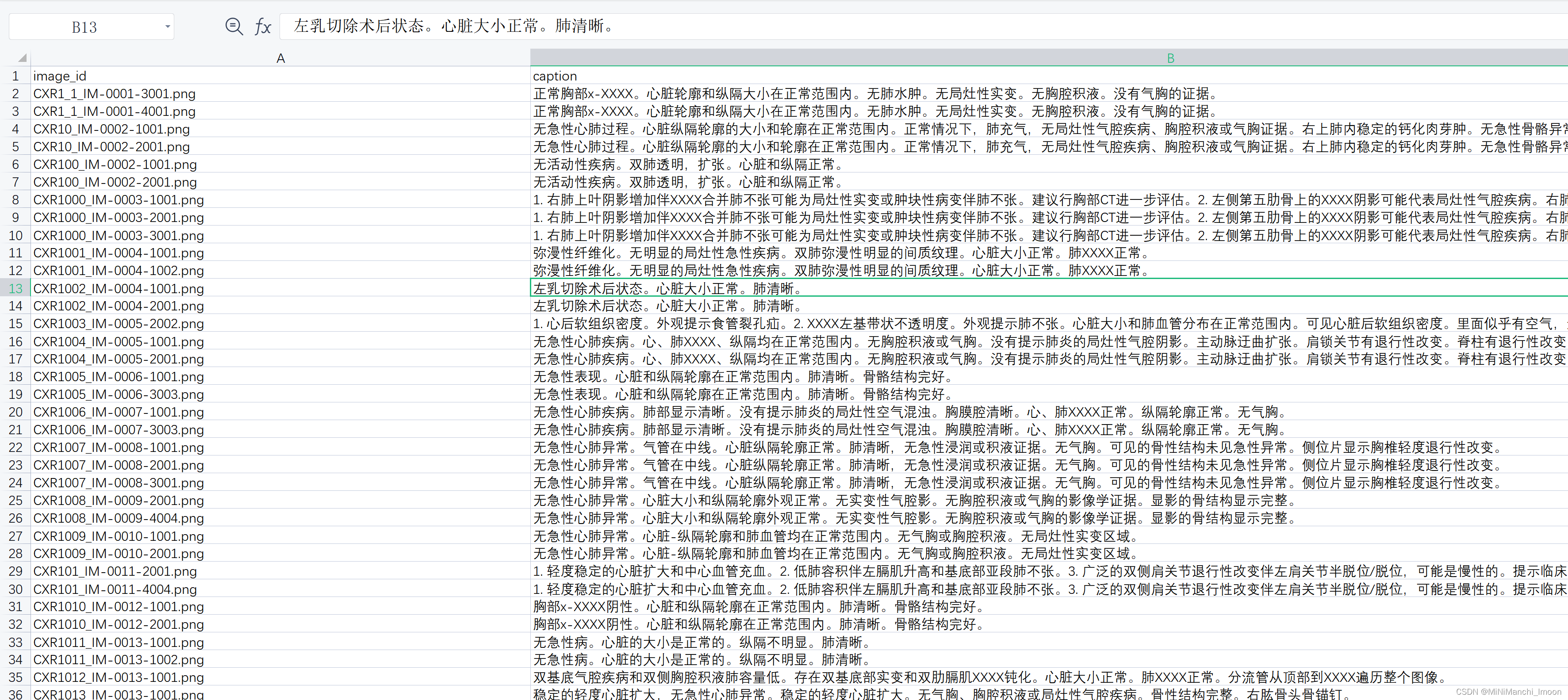
然后我将数据集分割为了训练集和测试集,并将格式转换成可处理的。
具体代码如下:
分割部分代码
import pandas as pd
import json
# 读取Excel文件
df = pd.read_excel('IU-Xray.xlsx')
# 假设第一列是图片名称,第二列是图片的描述
# 假设第一列是图片名称,第二列是图片的描述
image_names = df.iloc[:, 0] # 获取图片名称列
image_descriptions = df.iloc[:, 1] # 获取图片描述列
# 创建一个新的DataFrame,其中包含我们想要的键名
new_df = pd.DataFrame({
'image_id': image_names,
'caption': image_descriptions
})
# 分割数据集(这里只是简单地将数据分为两部分,你可以根据需求进行更复杂的分割)
# 例如,我们随机选择70%的数据作为训练集,剩下的30%作为测试集
train_size = int(0.7 * len(df))
test_size = len(df) - train_size
# 使用pandas的sample方法进行分割(如果需要随机性的话)
train_df = df.sample(n=train_size, random_state=42)
test_df = df.drop(train_df.index)
# 假设第一列是图片名称,第二列是图片的描述
image_names1 = train_df.iloc[:, 0] # 获取图片名称列
image_descriptions1 = train_df.iloc[:, 1] # 获取图片描述列
# 创建一个新的DataFrame,其中包含我们想要的键名
train_df = pd.DataFrame({
'image_id': image_names1,
'caption': image_descriptions1
})
# 假设第一列是图片名称,第二列是图片的描述
image_names2 = test_df.iloc[:, 0] # 获取图片名称列
image_descriptions2 = test_df.iloc[:, 1] # 获取图片描述列
# 创建一个新的DataFrame,其中包含我们想要的键名
test_df = pd.DataFrame({
'image_id': image_names2,
'caption': image_descriptions2
})
# 将数据集保存为JSON格式
# 如果你的DataFrame中不包含复杂的数据类型(如日期或自定义对象),可以直接使用to_json方法
train_json = train_df.to_json(orient='records')
test_json = test_df.to_json(orient='records')
# 将JSON字符串写入文件
with open('train_dataset.json', 'w', encoding='utf-8') as f:
json.dump(json.loads(train_json), f, ensure_ascii=True, indent=4)
with open('test_dataset.json', 'w', encoding='utf-8') as f:
json.dump(json.loads(test_json), f, ensure_ascii=True, indent=4)
格式转换部分代码
import json
from tqdm import tqdm
with open('test_dataset.json') as f:
data = json.load(f)
data_info = []
for i in tqdm(range(len(data['annotations']))):
img = data['annotations'][i]['image_id']
prompt = '通过这张胸部X光影像可以诊断出什么?'
label = data['annotations'][i]['caption']
json_data = {
'img': './data/Xray/'+str(img),
'prompt': prompt,
'label': str(label)
}
data_info.append(json_data)
with open('test-ui-prompt.json', 'w+') as f1:
json.dump(data_info, f1)
最后成功获得可训练数据集
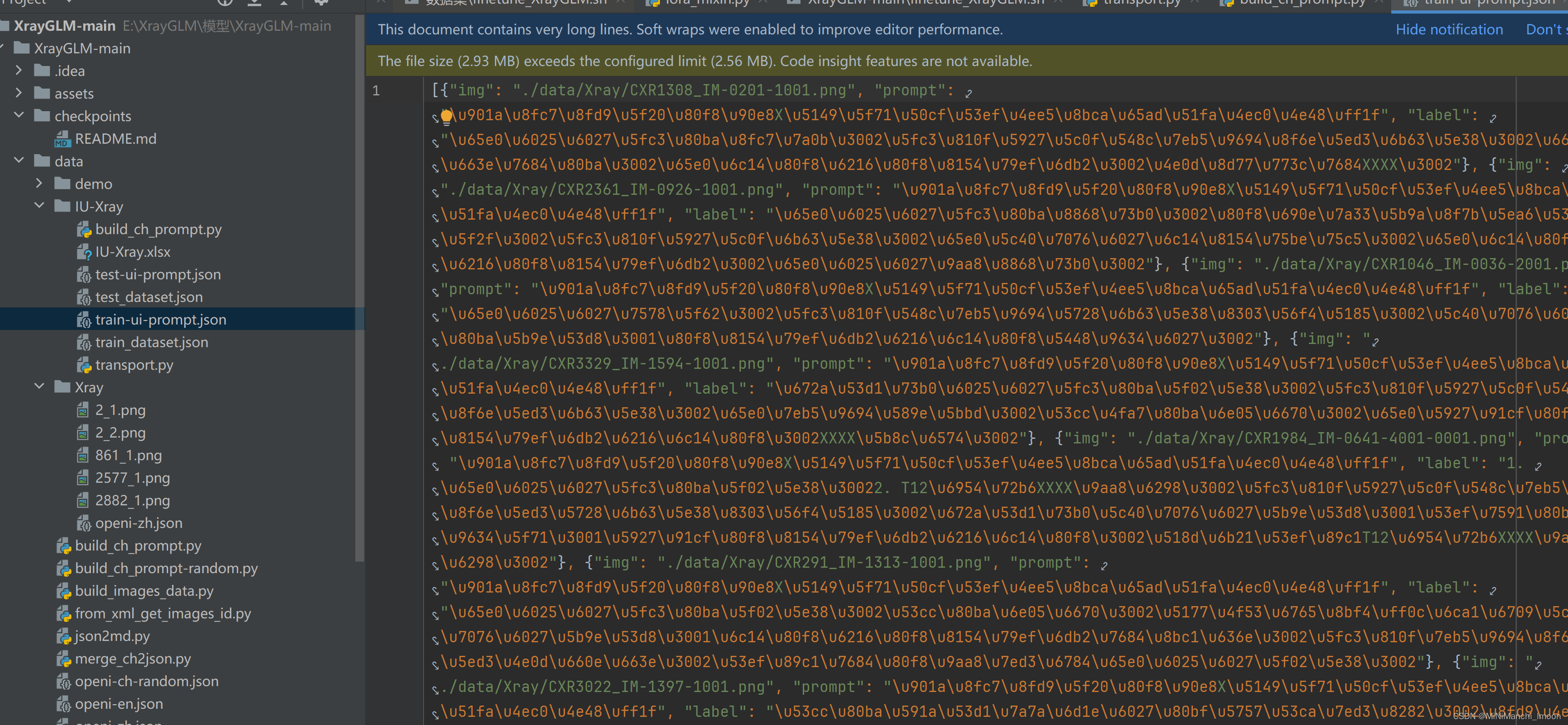
三、任务2——微调VisualGLM并记录结果
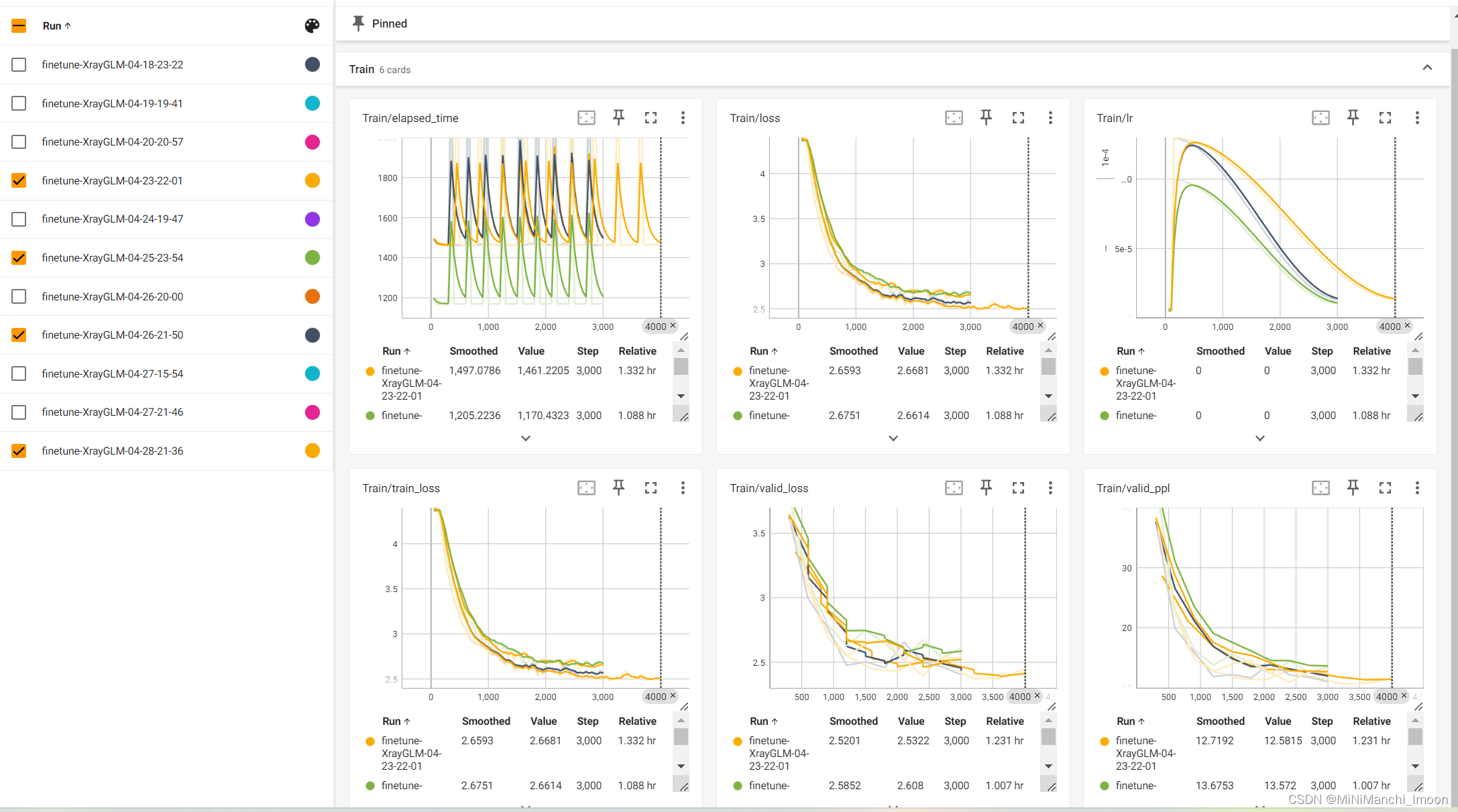
这部分工作由我和团队成员宗亚静共同完成,具体的微调结果如下:
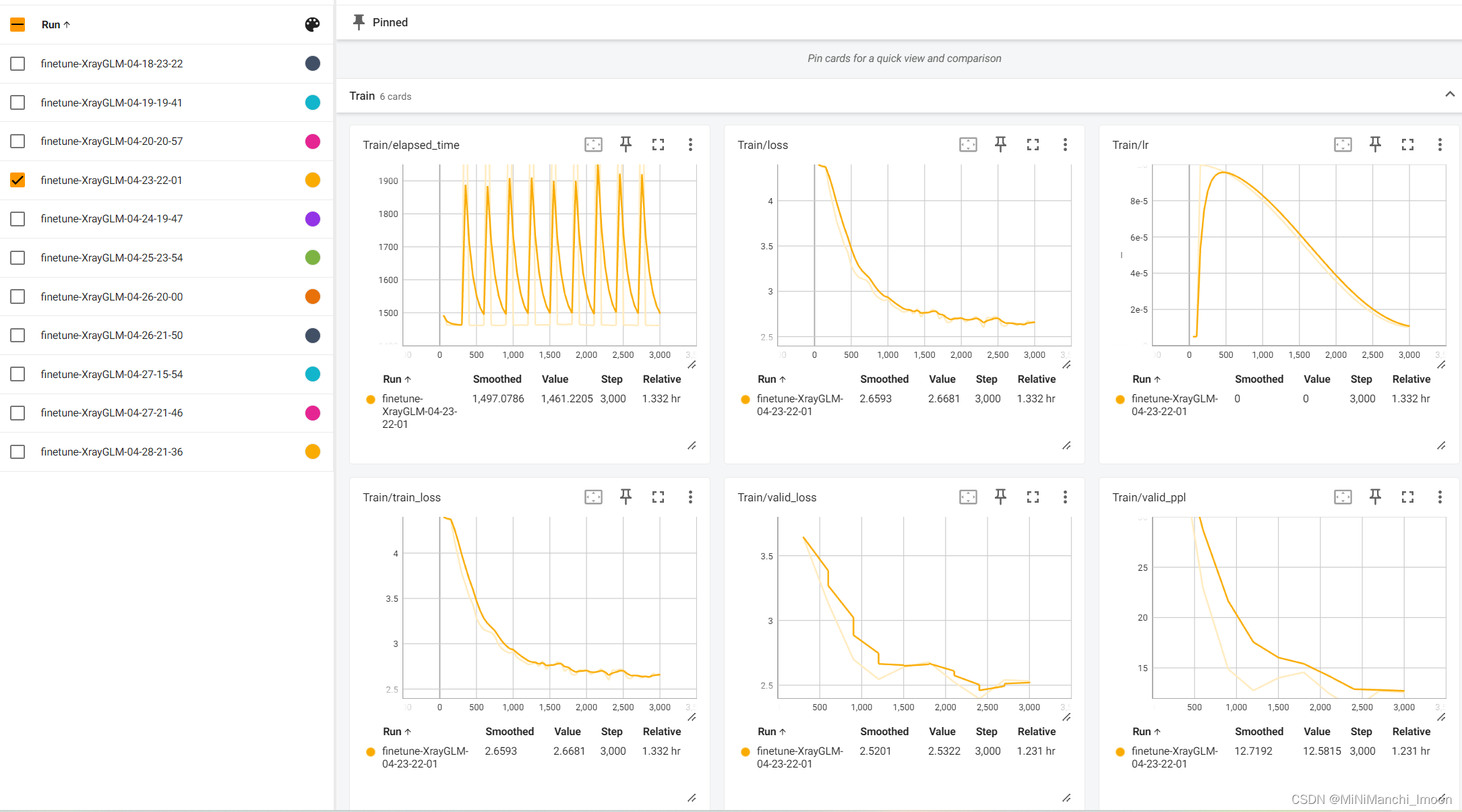
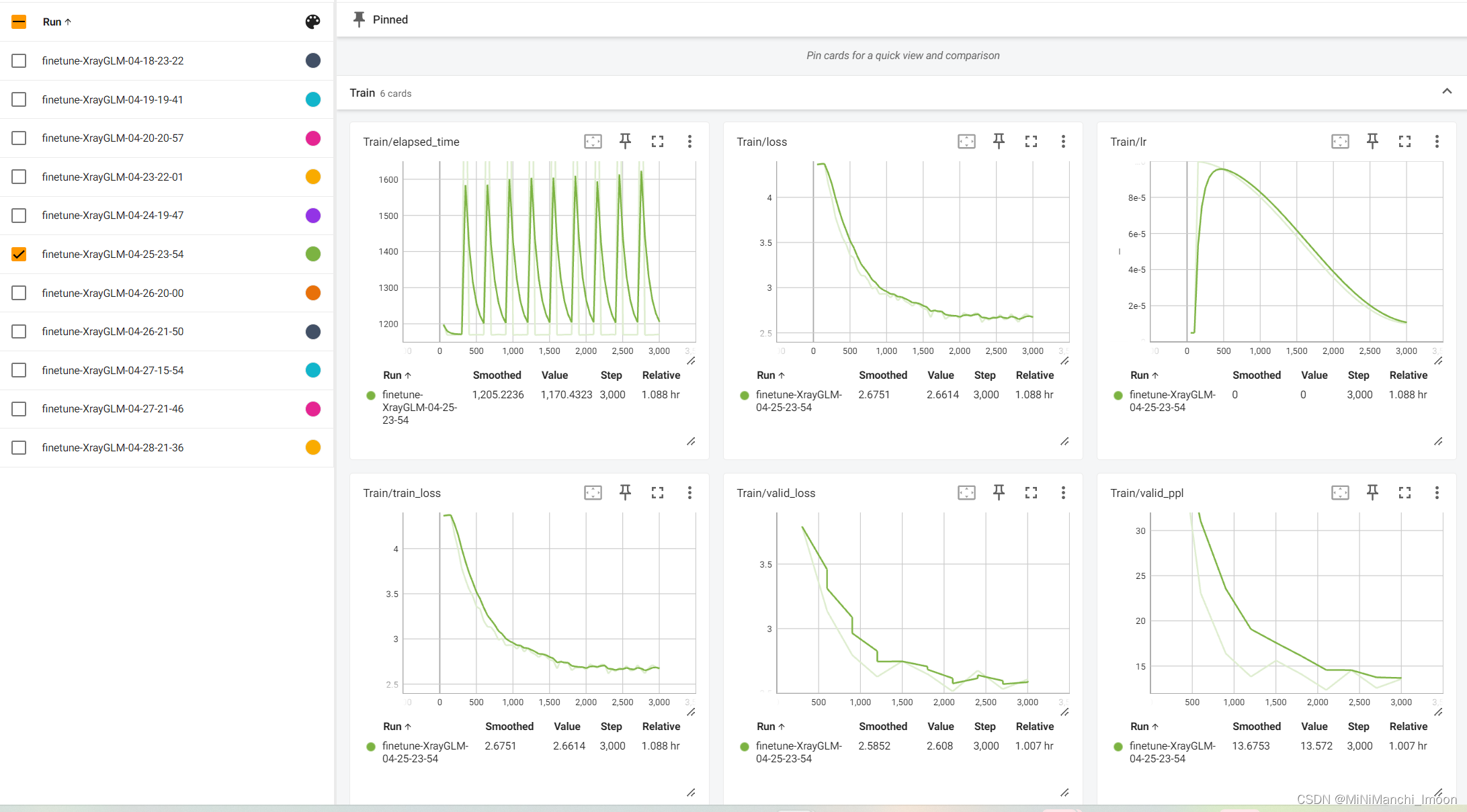
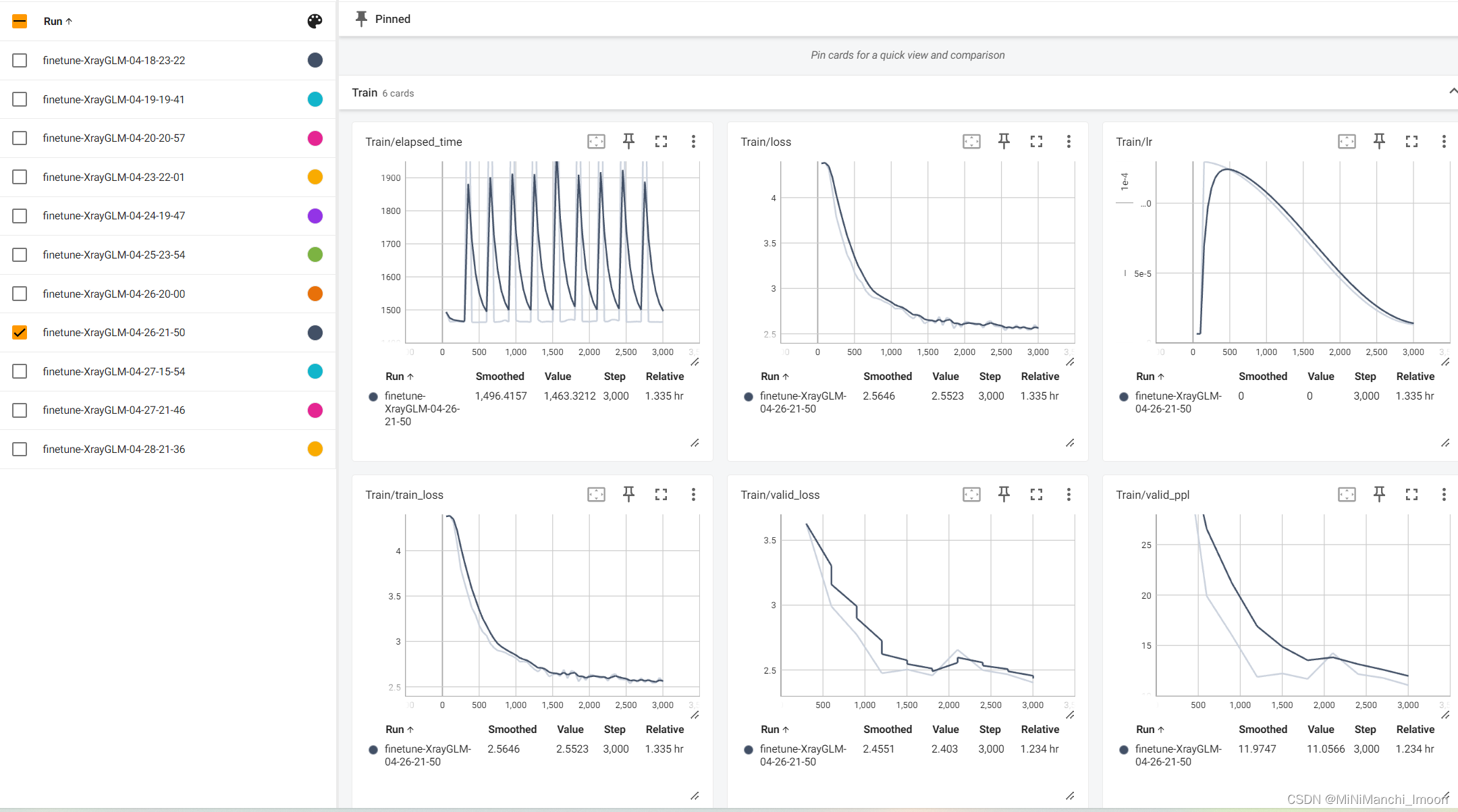
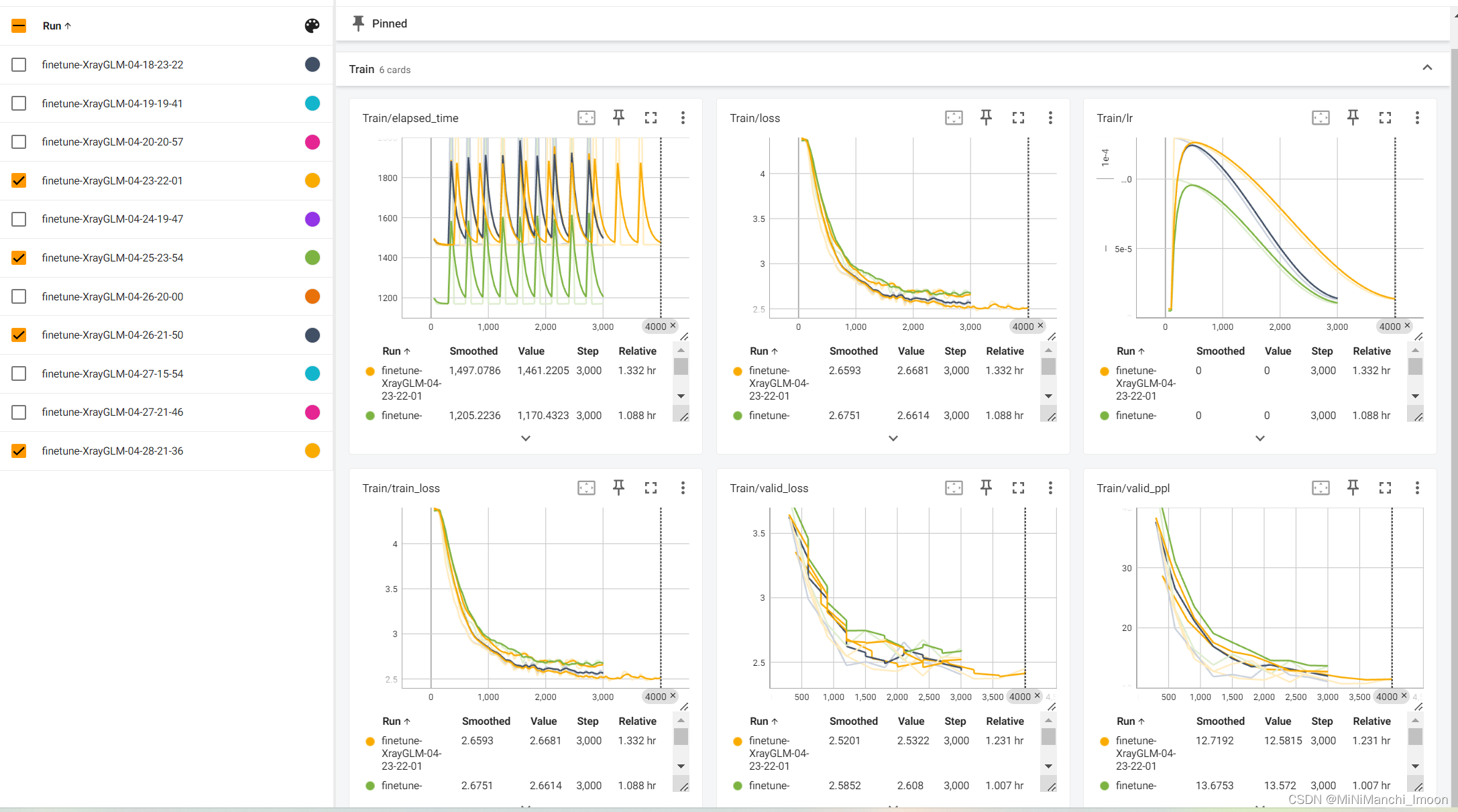
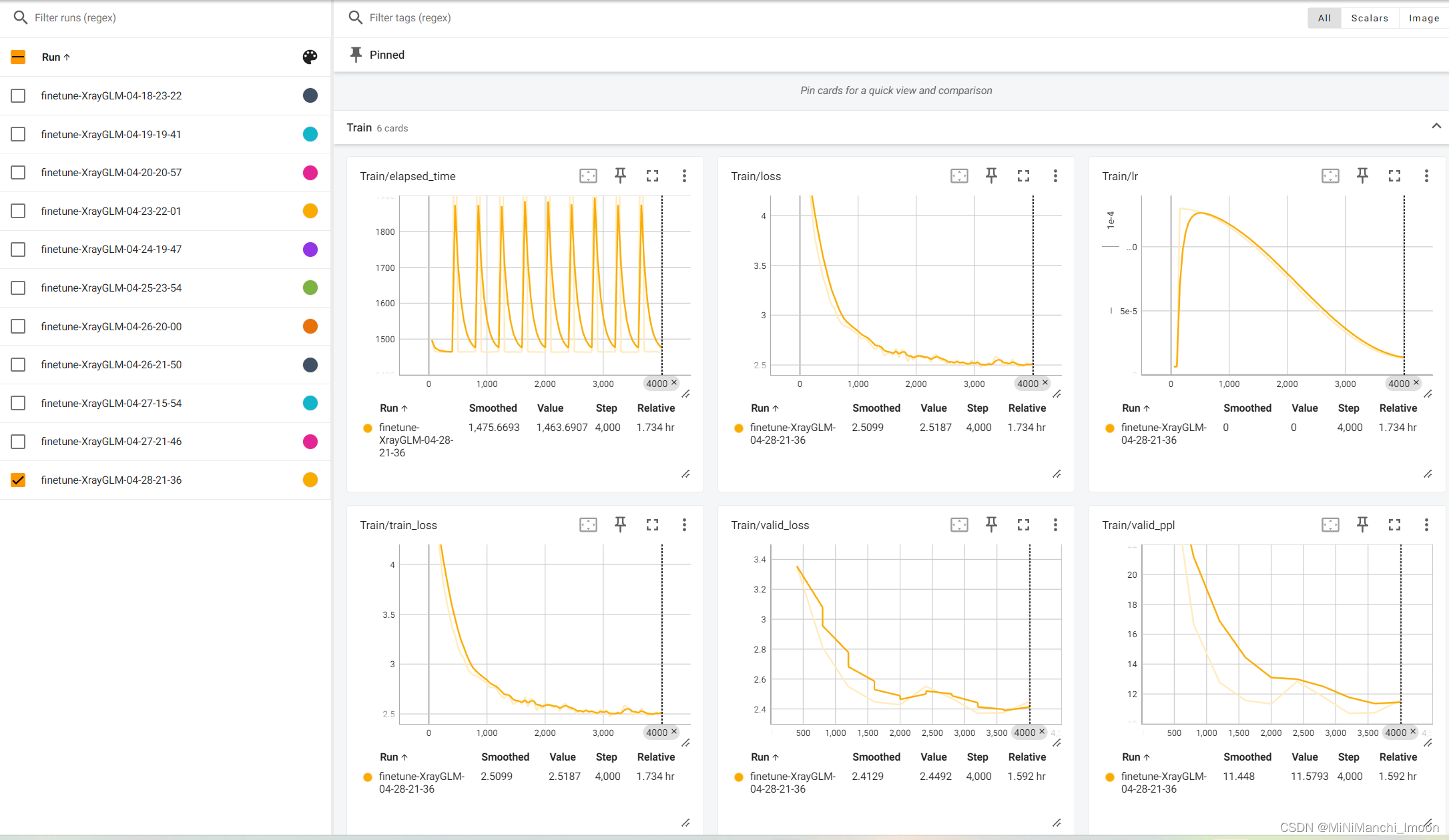
训练结果对比
四、总结
4.1 处理IU-XRay数据集
本周的首要任务是处理IU-XRay数据集。IU-XRay数据集是一个针对胸部X射线图像的医学数据集,常用于胸部疾病如肺炎、肺结核等的计算机视觉和机器学习研究。在处理该数据集的过程中,我主要完成了以下几个步骤:
-
数据下载与验证:首先,我从官方或可靠来源下载了IU-XRay数据集,并验证了数据的完整性和准确性。
-
数据清洗:对下载的数据进行了初步清洗,包括删除损坏或格式不正确的图像文件,以及去除标签中可能的错误或不一致之处。
-
数据预处理:为了适配后续的模型训练,我对图像进行了必要的预处理操作,如尺寸调整、归一化、对比度增强等。同时,对标签数据进行了编码,以便于模型理解和使用。
-
数据划分:将清洗和预处理后的数据集划分为训练集、验证集和测试集,以确保模型训练的有效性和泛化能力。
-
数据增强:为了增加模型的鲁棒性,我应用了一系列数据增强技术,如随机旋转、翻转、缩放等,以扩充训练样本的数量和多样性。
-
数据保存:将处理好的数据集保存为易于加载和使用的格式,以便后续模型训练和评估。
4.2 微调VisualGLM并记录结果
在处理好IU-XRay数据集后,我开始了对VisualGLM模型的微调工作。VisualGLM是一种结合了视觉信息和语言信息的深度学习模型,常用于跨模态任务。在微调过程中,我遵循了以下步骤:
-
模型加载:首先,我加载了预训练的VisualGLM模型,并查看了其结构和参数设置。
-
修改模型配置:根据IU-XRay数据集的特点和任务需求,我对VisualGLM模型的配置进行了必要的修改,如调整输出层的神经元数量、修改损失函数等。
-
模型训练:使用划分好的训练集对VisualGLM模型进行微调训练。在训练过程中,我监控了模型的损失函数和准确率等指标,以确保训练的有效性。
-
模型验证:在验证集上评估微调后的模型性能。通过对比训练集和验证集上的性能指标,我分析了模型的泛化能力和可能存在的过拟合问题。
-
模型测试:在测试集上测试微调后的模型性能,并记录了详细的测试结果。这些结果将用于评估模型的实用性和性能。
-
结果分析与记录:我详细分析了微调过程中的训练日志、验证结果和测试结果,并记录了关键信息如损失函数值、PPL等。同时,我也对模型的表现进行了深入分析和讨论,提出了可能的改进方向和建议。
总结
本周我成功完成了IU-XRay数据集的处理和VisualGLM模型的微调工作。通过精心处理数据集和微调模型配置,我得到了一个性能良好的模型,并在测试集上取得了满意的结果。这些工作为后续的研究和应用奠定了坚实的基础。同时,我也从中学到了很多宝贵的经验和知识,这将对我未来的工作产生积极的影响。


















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









