







1.前言
下拉刷新和上拉加载这两种交互方式通常出现在移动端中,本质上等同于PC网页中的分页,只是交互形式不同。
开源社区也有很多优秀的解决方案,如iscroll、better-scroll、pulltorefresh.js库等等。
下面通过原生的方式实现上拉加载,下拉刷新,有助于对第三方库有更好的理解与使用。
2.上拉加载
如下看一张图:
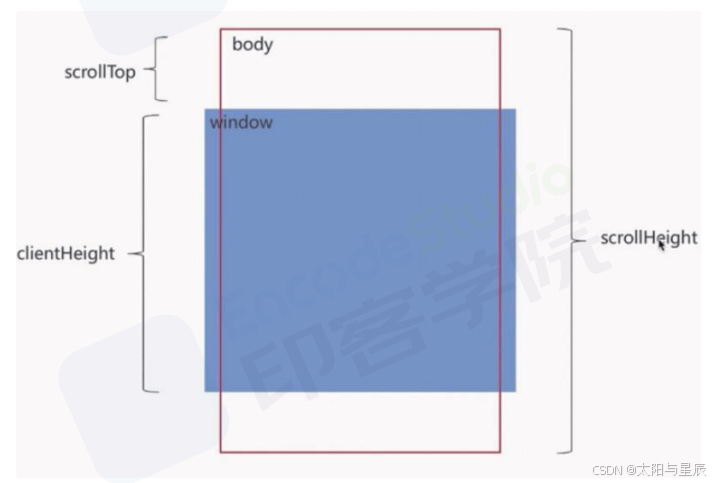
我们可以知道:实现上拉加载的关键点是判断页面触底,或者判断是否快要触底。即scrollTop+clientHeight>= scrollHeight。
这几个属性我在之前三大家族文章https://blog.csdn.net/fageaaa/article/details/145728760里面详细讲解过。下面来回忆一下:
scrollTop:滚动视窗的高度距离window顶部的距离,它会随着往上滚动而不断增加,初始值是0,它是一个变化的值clientHeight:它是一个定值,表示屏幕可视区域的高度;scrollHeight:页面不能滚动时也是存在的,此时scrollHeight等于clientHeight。scrollHeight表示body所有元素的总长度(包括body元素自身的padding)。
简单实现:
let clientHeight = document.documentElement.clientHeight; //浏览器高度
let scrollHeight = document.body.scrollHeight;
let scrollTop = document.documentElement.scrollTop;
let distance = 50; //距离视窗还用50的时候,开始触发;
if ((scrollTop + clientHeight) >= (scrollHeight - distance)) {
console.log("开始加载数据");
}
下面再看一个详细的例子:

如上图,我们需要实现的是:页面总共要加载1000条数据,但不可能一开始直接一次性加载在页面上。如图,一次性只加载20条数据,所以一开始页面加载了20条数据,会有一个滚动条,但这个滚动条距离底部很近(大概两个多条目高度的距离,因为最底部条目是item18,总共有20个条目)。当我们向下移动滚动条时候,当发现快要触底时候,我们会自动再加载20条数据,向上滚动时候不加载,因为向上滚动时的条目都是已经加载在页面上的条目了,不用再加载。依次类似诸如此类。
如下我们实现一下代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Title</title>
<style>
body,
html {
padding: 0px;
margin: 0px;
width: 100%;
height: 100%;
overflow: hidden;
}
ul {
margin: 0;
width: 90%;
height: 100%;
overflow-y: auto;
list-style: none;
}
ul > li {
width: 100%;
height: 40px;
}
ul > li:nth-of-type(2n + 1) {
background-color: aqua;
}
ul > li:nth-of-type(2n) {
background-color: antiquewhite;
}
</style>
</head>
<body>
<ul></ul>
<script>
//初始化一个1000大小的数组-->
// 真实开发中 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









