







压缩就是位域的操作,假设A对应0000,B对应1111,则AB压缩后为00001111即为0x0F,AB原本为2个字节,压缩后变为1个字节。其它数据类似一样的压缩操作即可。
解压缩就是取出每一个位,如果是0,则走到哈夫曼编码树的左孩子,如果是1,则走到哈夫曼编码树的右孩子,接着判断是否走到了叶子节点,如果是,输出叶子节点对应的编码值即可。依次类推,解压出全部数据。
如下的代码只是为了更好的演示压缩和解压过程,基本没有太多考虑效率等问题。
#ifndef _HANFUMAN_H_
#define _HANFUMAN_H_
typedef struct _t_HANFUMAN_TREE
{
unsigned char data; //编码的数据值,0-255之间,如果不是叶子节点,设置为0
unsigned short weight; //编码数字的权重,可以是出现的概率,这里使用data出现的次数
_t_HANFUMAN_TREE* parent;
_t_HANFUMAN_TREE* left;
_t_HANFUMAN_TREE* right;
}HANFUMAN_TREE,*PHANFUMAN_TREE;
#define MAX_CODE_BYTES 16
#define INDEX_TYPE_TREE 0x00
#define INDEX_TYPE_INFO 0x01
typedef struct _t_HANFUMAN_SELECT_HELPER
{
_t_HANFUMAN_SELECT_HELPER()
{
Init();
}
void Init()
{
firstMinIndex = -1;
secondMinIndex = -1;
firstMinType = INDEX_TYPE_TREE; //默认值为子树类型
secondMinType = INDEX_TYPE_TREE; //默认值为子树类型
}
int firstMinIndex;
int secondMinIndex;
unsigned char firstMinType;
unsigned char secondMinType;
}HANFUMAN_SELECT_HELPER,*PHANFUMAN_SELECT_HELPER;
typedef struct _t_DATA_INFO
{
unsigned char data;
unsigned short times; //data出现的次数
}DATA_INFO,*PDATA_INFO;
typedef struct _t_HANFUMAN_CODE_ITEM
{
unsigned char data[MAX_CODE_BYTES]; //最长表示MAX_CODE_BYTES*8长度的编码位域
unsigned short codeLen;//编码的位域长度
}HANFUMAN_CODE_ITEM,*PHANFUMAN_CODE_ITEM;
BOOL TestHanfuMan();
//创建哈夫曼编码树
PHANFUMAN_TREE CreateHanfuManTree(PDATA_INFO pDataInfo,int len);
void EnumHanfuManCode(PHANFUMAN_TREE tree);
void DestroyTree(PHANFUMAN_TREE tree);
#endif#include <Windows.h>
#include <iostream>
#include <stdlib.h>
#include <time.h>
#include "HanfuMan.h"
#define TEST_DATA_LEN 16
void InsertSort(PDATA_INFO pDataInfo,int len,unsigned char data,unsigned short dataTimes);
//哈夫曼编码,返回值为编码后的数据位数 一个字节有8位
int HanfuManEncode(unsigned char* data,int dataLen,unsigned char **encodeData);
//哈夫曼解压缩,返回值为解压缩后的数据字节数
int HanfuManDecode(PHANFUMAN_TREE tree,unsigned char* data,int dataBitLen,unsigned char **decodeData);
//编码表,用于0-255之间
static HANFUMAN_CODE_ITEM g_HanfuManCodeTable[256] = {0};
BOOL TestHanfuMan()
{
BOOL bRet = FALSE;
unsigned char *p = (unsigned char*)new unsigned char[TEST_DATA_LEN];
if(!p)
{
return FALSE;
}
memset(p,0,TEST_DATA_LEN);
srand(time(NULL));
for(int i=0;i<TEST_DATA_LEN;i++)
{
p[i] = rand()%256; //随机生成数据内容
}
//统计0-255之间每个数字出现的次数
unsigned short times[256] = {0};
for(int i=0;i<TEST_DATA_LEN;i++)
{
times[p[i]]++;
}
int count = 0;//统计有出现的数字个数
for(int i=0;i<256;i++)
{
if(times[i])
{
count++;
}
}
PDATA_INFO pDataInfo = (PDATA_INFO)new DATA_INFO[count];
if(!pDataInfo)
{
goto RET;
}
memset(pDataInfo,0,count*sizeof(DATA_INFO));
int len = 0;
for(int i=0;i<256;i++)
{
if(times[i])
{
//使用插入排序,把0-255之间出现的数字的次数进行从小到大排序
InsertSort(pDataInfo,len,i,times[i]);
len++;
}
}
PHANFUMAN_TREE tree = CreateHanfuManTree(pDataInfo,len);
EnumHanfuManCode(tree);
unsigned char *pEncode = NULL;
int encodeBitLen = HanfuManEncode(p,TEST_DATA_LEN,&pEncode); //编码数据
printf("Bytes Before encode = %d Bytes Arter encode = %d\r\n",TEST_DATA_LEN,(encodeBitLen+7)/8);
unsigned char *pDecode = NULL;
int decodeByteLen = HanfuManDecode(tree,pEncode,encodeBitLen,&pDecode);
if(decodeByteLen != TEST_DATA_LEN)
{
printf("Decode Fail...Len is not match\r\n");
}
else
{
if(memcmp(p,pDecode,TEST_DATA_LEN))
{
printf("Decode Fail... Decode data fail\r\n");
}
else
{
printf("Decode Success\r\n");
}
}
if(!pEncode)
{
delete []pEncode;
pEncode = NULL;
}
if(!pDecode)
{
delete []pDecode;
pDecode = NULL;
}
DestroyTree(tree);
RET:
if(pDataInfo)
{
delete [] pDataInfo;
}
if(p)
{
delete [] p;
}
return bRet;
}
//哈夫曼编码,返回值为编码后的数据位数 一个字节有8位
int HanfuManEncode(unsigned char* data,int dataLen,unsigned char **encodeData)
{
if(!data || dataLen<=0)
{
return 0;
}
//存储编码后的数据
*encodeData = (unsigned char *)new unsigned char[dataLen*8];
if(!*encodeData)
{
return 0;
}
memset(*encodeData,0,(dataLen*8)*sizeof(unsigned char));
int byteIndex = 0;
int bitIndexOfByte = 7;
unsigned char bitHelper[8] = {0x01,0x02,0x04,0x08,0x10,0x20,0x40,0x80};
for(int i=0;i<dataLen;i++)
{
for(int j=0;j<(g_HanfuManCodeTable[data[i]]).codeLen;j++)
{
int codeByteIndex = j/8;
int codeBitIndexOfByte = j%8;
if((g_HanfuManCodeTable[data[i]]).data[codeByteIndex] & bitHelper[codeBitIndexOfByte])
{
(*encodeData)[byteIndex] |= bitHelper[bitIndexOfByte];
}
//达到了一个字节,则需要设置下一个字节当中的位域
if(-1 == --bitIndexOfByte)
{
byteIndex++;
bitIndexOfByte = 7;
}
}
}
return byteIndex*8 + (7 - bitIndexOfByte);
}
//哈夫曼解压缩,返回值为解压缩后的数据字节数
int HanfuManDecode(PHANFUMAN_TREE tree,unsigned char* data,int dataBitLen,unsigned char **decodeData)
{
if(!data || dataBitLen<=0)
{
return 0;
}
//存储解码后的数据
*decodeData = (unsigned char *)new unsigned char[dataBitLen];
if(!*decodeData)
{
return 0;
}
memset(*decodeData,0,(dataBitLen)*sizeof(unsigned char));
int decodeIndex = 0;
unsigned char bitHelper[8] = {0x01,0x02,0x04,0x08,0x10,0x20,0x40,0x80};
PHANFUMAN_TREE pTree = tree;
for(int i=0;i<dataBitLen;i++)
{
int codeByteIndex = i/8;
int codeBitIndexOfByte = i%8;
if(data[codeByteIndex] & bitHelper[7-codeBitIndexOfByte])
{
pTree = pTree->right; //如果是1,走到右子树
}
else
{
pTree = pTree->left; //如果是0,走到左子树
}
//叶子节点,则输出解码数据
if(!pTree->left && !pTree->right)
{
(*decodeData)[decodeIndex++] = pTree->data;
pTree = tree;
}
}
return decodeIndex;
}
void InsertSort(PDATA_INFO pDataInfo,int len,unsigned char data,unsigned short dataTimes)
{
if(0 == len)
{
pDataInfo[0].data = data;
pDataInfo[0].times = dataTimes;
return;
}
int inserIndex = 0;
//使用插入排序
for(inserIndex=0;inserIndex<len;inserIndex++)
{
if(dataTimes >= pDataInfo[inserIndex].times)
{
continue;
}
break;
}
for(int i=len-1;i>=inserIndex;i--)
{
memcpy(&pDataInfo[i+1],&pDataInfo[i],sizeof(DATA_INFO));
}
//插入新数据
pDataInfo[inserIndex].data = data;
pDataInfo[inserIndex].times = dataTimes;
}
void InsertSortTree(PHANFUMAN_TREE *pSubTree,int subTreeCount,PHANFUMAN_TREE insertTree)
{
if(0 == subTreeCount)
{
pSubTree[0] = insertTree;
return;
}
int inserIndex = 0;
//使用插入排序
for(inserIndex=0;inserIndex<subTreeCount;inserIndex++)
{
if(insertTree->weight >= (pSubTree[inserIndex])->weight)
{
continue;
}
break;
}
for(int i=subTreeCount-1;i>=inserIndex;i--)
{
pSubTree[i+1] = pSubTree[i];
}
//插入新数据
pSubTree[inserIndex] = insertTree;
}
void RefreshSubTrees(PHANFUMAN_TREE *pSubTree,int subTreeCount,PHANFUMAN_TREE mergeTree)
{
for(int i=2;i<subTreeCount;i++)
{
pSubTree[i-2] = pSubTree[i];
}
//插入排序,按照权重的从小到大顺序排序
InsertSortTree(pSubTree,subTreeCount-2,mergeTree);
}
//合并2棵子树,pSubTree1的权重默认比pSubTree2的小
PHANFUMAN_TREE MergeTree(PHANFUMAN_TREE pLeftSubTree,PHANFUMAN_TREE pRightSubTree)
{
PHANFUMAN_TREE mergeRoot = new HANFUMAN_TREE;
if(!mergeRoot)
{
return NULL;
}
mergeRoot->data = 0;
pLeftSubTree->parent = mergeRoot;
mergeRoot->weight = pLeftSubTree->weight;
//pLeftSubTree 默认不为空
if(pRightSubTree)
{
mergeRoot->weight += pRightSubTree->weight;
pRightSubTree->parent = mergeRoot;
}
mergeRoot->parent = NULL;
mergeRoot->left = pLeftSubTree;
mergeRoot->right = pRightSubTree;
return mergeRoot;
}
//创建新树,用于创建叶子节点
PHANFUMAN_TREE CreateLeaf(PDATA_INFO pDataInfo)
{
PHANFUMAN_TREE leafTree = new HANFUMAN_TREE;
if(!leafTree)
{
return NULL;
}
leafTree->data = pDataInfo->data;
leafTree->weight = pDataInfo->times;
leafTree->parent = NULL;
leafTree->left = NULL;
leafTree->right = NULL;
return leafTree;
}
//创建哈夫曼编码树
PHANFUMAN_TREE CreateHanfuManTree(PDATA_INFO pDataInfo,int len)
{
if(len<=0)
{
return NULL;
}
int dataIndex = 0;
//最多只可能出现len+1/2个子树,用于保存编码过程可能出现的全部子树的根节点指针
PHANFUMAN_TREE *pSubTree = (PHANFUMAN_TREE*) new PHANFUMAN_TREE[(len+1)/2];
PHANFUMAN_TREE root = NULL;
int subTreeCount = 0; //子树的个数
HANFUMAN_SELECT_HELPER selectHelper;
memset(pSubTree,0,sizeof(PHANFUMAN_TREE)*((len+1)/2));
while(dataIndex<len)
{
//对比数组中剩余未编码的数据和各个子树选择2个权重最小的,如果权重相同,优先选择子树中的
//由于数组和子树都已经按照从小到大的顺序,因此直接选取对比即可
if(subTreeCount>=2)
{
selectHelper.firstMinIndex = 0;
selectHelper.secondMinIndex = 1;
}
else
{
if(subTreeCount>=1)
{
selectHelper.firstMinIndex = 0;
}
}
if(-1 == selectHelper.firstMinIndex)
{
selectHelper.firstMinIndex = dataIndex;
selectHelper.firstMinType = INDEX_TYPE_INFO;
if(++dataIndex<len)
{
selectHelper.secondMinIndex = dataIndex++;
selectHelper.secondMinType = INDEX_TYPE_INFO;
}
}
else
{
if(pDataInfo[dataIndex].times < (pSubTree[selectHelper.firstMinIndex])->weight)
{
selectHelper.secondMinIndex = selectHelper.firstMinIndex;
selectHelper.firstMinIndex = dataIndex;
selectHelper.firstMinType = INDEX_TYPE_INFO;
if( (++dataIndex<len) && ( pDataInfo[dataIndex].times < (pSubTree[selectHelper.secondMinIndex])->weight ) )
{
selectHelper.secondMinIndex = dataIndex++;
selectHelper.secondMinType = INDEX_TYPE_INFO;
}
}
else
{
if( (-1==selectHelper.secondMinIndex) || (pDataInfo[dataIndex].times < (pSubTree[selectHelper.secondMinIndex])->weight))
{
selectHelper.secondMinIndex = dataIndex++;
selectHelper.secondMinType = INDEX_TYPE_INFO;
}
}
}//至此,已经选择出了2个最小权重的
if(INDEX_TYPE_TREE == selectHelper.firstMinType && INDEX_TYPE_TREE == selectHelper.secondMinType)
{
//合并2棵子树
PHANFUMAN_TREE mergeTree = MergeTree(pSubTree[0],pSubTree[1]);
if(!mergeTree)
{
exit(0);
}
RefreshSubTrees(pSubTree,subTreeCount,mergeTree);
subTreeCount--;
}
if(INDEX_TYPE_TREE == selectHelper.firstMinType && INDEX_TYPE_INFO == selectHelper.secondMinType)
{
PHANFUMAN_TREE newLeaf = CreateLeaf(&pDataInfo[selectHelper.secondMinIndex]);
if(!newLeaf)
{
exit(0);
}
PHANFUMAN_TREE mergeTree = MergeTree(pSubTree[0],newLeaf);
if(!mergeTree)
{
exit(0);
}
for(int i=1;i<subTreeCount;i++)
{
pSubTree[i-1] = pSubTree[i];
}
InsertSortTree(pSubTree,subTreeCount-1,mergeTree);//插入子树后,子树的数量不变
}
if(INDEX_TYPE_INFO == selectHelper.firstMinType && INDEX_TYPE_INFO == selectHelper.secondMinType)
{
PHANFUMAN_TREE leftLeaf = CreateLeaf(&pDataInfo[selectHelper.firstMinIndex]);
if(!leftLeaf)
{
exit(0);
}
PHANFUMAN_TREE rightLeaf = CreateLeaf(&pDataInfo[selectHelper.secondMinIndex]);
if(!leftLeaf)
{
exit(0);
}
PHANFUMAN_TREE mergeTree = MergeTree(leftLeaf,rightLeaf);
if(!mergeTree)
{
exit(0);
}
InsertSortTree(pSubTree,subTreeCount,mergeTree);
subTreeCount++; //插入子树后,子树的数量+1
}
if(INDEX_TYPE_INFO == selectHelper.firstMinType && INDEX_TYPE_TREE == selectHelper.secondMinType)
{
if(-1 == selectHelper.secondMinIndex)
{
PHANFUMAN_TREE leftLeaf = CreateLeaf(&pDataInfo[selectHelper.firstMinIndex]);
if(!leftLeaf)
{
exit(0);
}
PHANFUMAN_TREE mergeTree = MergeTree(leftLeaf,NULL);
if(!mergeTree)
{
exit(0);
}
InsertSortTree(pSubTree,subTreeCount,mergeTree);
subTreeCount++;
}
else
{
PHANFUMAN_TREE leftLeaf = CreateLeaf(&pDataInfo[selectHelper.firstMinIndex]);
if(!leftLeaf)
{
exit(0);
}
PHANFUMAN_TREE mergeTree = MergeTree(leftLeaf,pSubTree[selectHelper.secondMinIndex]);
if(!mergeTree)
{
exit(0);
}
for(int i=1;i<subTreeCount;i++)
{
pSubTree[i-1] = pSubTree[i];
}
InsertSortTree(pSubTree,subTreeCount-1,mergeTree);
}
}
selectHelper.Init();
}
//合并sub trees
while(subTreeCount>1)
{
//合并2棵子树
PHANFUMAN_TREE mergeTree = MergeTree(pSubTree[0],pSubTree[1]);
if(!mergeTree)
{
exit(0);
}
RefreshSubTrees(pSubTree,subTreeCount,mergeTree);
subTreeCount--;
}
//最后子树中只剩下一课,这棵树即为编码树
PHANFUMAN_TREE tree = pSubTree[0];
delete [] pSubTree;
return tree;
}
//释放树
void DestroyTree(PHANFUMAN_TREE tree)
{
if(!tree)
{
return;
}
DestroyTree(tree->left); //刪除左子树
DestroyTree(tree->right);//删除右子树
delete tree; //删除根节点
tree = NULL;
}
//通过叶子的父节点向上
void PrintHanfuManCode(PHANFUMAN_TREE tree,int *codeLen,unsigned char data)
{
if(!tree)
{
return;
}
PHANFUMAN_TREE parent = tree->parent;
if(!parent)
{
return;
}
PrintHanfuManCode(parent,codeLen,data);
if(parent->left == tree)
{
(*codeLen)++;
printf("0");
//默认值就是为0,因此编码表元素不需要设置数据,长度增加1个位域即可
g_HanfuManCodeTable[data].codeLen++;
}
else
{
(*codeLen)++;
printf("1");
//需要设置编码表元素的第g_HanfuManCodeTable[data].codeLen位为1
int byteIndex = g_HanfuManCodeTable[data].codeLen/8;
int bitIndexOfByte = g_HanfuManCodeTable[data].codeLen%8;
unsigned char bitHelper[8] = {0x01,0x02,0x04,0x08,0x10,0x20,0x40,0x80};
g_HanfuManCodeTable[data].data[byteIndex] |= bitHelper[bitIndexOfByte];
g_HanfuManCodeTable[data].codeLen++;
//如果某个字段的编码位域为1101,则设置后,g_HanfuManCodeTable[data].data[0]第1位为1,第二位为1,第三位为0,第四为为1,即1011
//如果某个字段的编码位域为1011 1111 1101,则设置后,g_HanfuManCodeTable[data].data[0] = 1111 1101
//g_HanfuManCodeTable[data].data[1] = 0000 1011 即保存的顺序和我们阅读的顺序刚好相反了
}
}
//通过二次遍历编码树,枚举得到每个data的哈夫曼编码
void EnumHanfuManCode(PHANFUMAN_TREE tree)
{
if(!tree)
{
return;
}
//叶子节点
if(!tree->left && !tree->right)
{
int codeLen = 0;
printf("data value = 0x%2x HanfuMan Code = ",tree->data);
PrintHanfuManCode(tree,&codeLen,tree->data);
printf(" CodeLen = %d\r\n",codeLen);
return;
}
if(tree->left)
{
EnumHanfuManCode(tree->left);
}
if(tree->right)
{
EnumHanfuManCode(tree->right);
}
}#include <Windows.h>
#include <stdio.h>
#include "HanfuMan.h"
int main(int agrc,char* argv[])
{
TestHanfuMan();
getchar();
return 0;
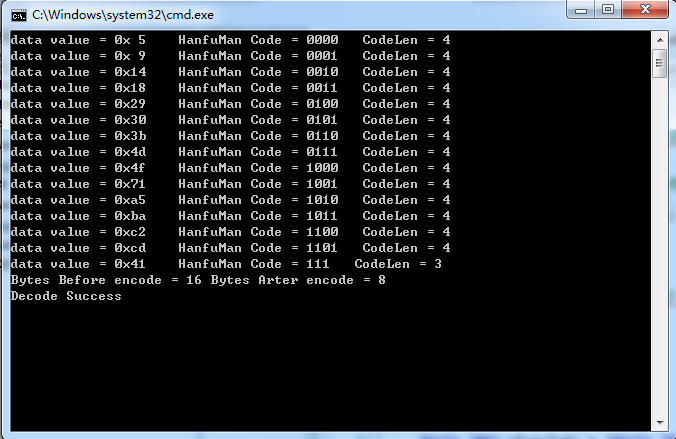
}这里,是通过随机生成的压缩数据,测试数据大小 #define TEST_DATA_LEN 16。测试结果如下:















 2916
2916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









