






目录
13、将mq-2、mq-3作为内存节点加⼊mq-1节点集群中
15、 登录rabbitmq web管理控制台,创建新的队列
一、消息中间件
1、简介
消息中间件也可以称消息队列,是指用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息队列模型,可以在分布式环境下扩展进程的通信。
当下主流的消息中间件有RabbitMQ、Kafka、RocketMQ等。其能在不同平台之间进行通信,常用来屏蔽各种平台协议之间的特性,实现应用程序之间的协同。优点在于能够在客户端和服务器之间进行同步和异步的连接,并且在任何时刻都可以将消息进行传送和转发,是分布式系统中非常重要的组件,主要用来解决应用耦合、异步通信、流量削峰等问题。
2、消息中间件主要作用
-
解耦
-
冗余(存储)
-
扩展性
-
削峰
-
可恢复性
-
顺序保证
-
缓冲
-
异步通信
注意:
在软件工程中,降低耦合度即可以理解为解耦,模块间有依赖关系必然存在耦合,理论上的绝对零耦合是做不到的,但可以通过一些现有的方法将耦合度降至最低
3、消息中间件的两种模式
1、P2P模式
P2P模式包含三个角色:消息队列(Queue)、发送者(Sender)、接受者(Receiver)。每个消息都被发送到一个特定的队列,接受者从队列中获取消息。队列保留着消息,直到他们被消费或者过期。
P2P的特点
每个消息队列只有一个消费者Consumer),即一旦被消费,消息就不再在消息队列中
发送者和接收者之间在时间上没有依赖性,也就是说当发送者发送了消息之后,不管接收者有没有正在运行它不会影响到消息被发送到队列
接受者在成功接收消息之后需向队列应答成功
如果希望发送的每个消息都会被成功处理的话,那么需要P2P模式中的软件做相对的配置
2、Pub/Sub模式
Pub/Sub模式包含三个角色:主题(Topic)、发布者(Publisher)、订阅者(Subscriber) 。多个发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。
Pub/Sub的特点:
每个消息可以有多个消费者
发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅至之后,才能消费发布者的消息
为了消费信息,订阅者必须保持运行状态
如果希望发送的消息可以不被做任何处理、或者只被一个消费者处理、或者可以被多个消费者处理的话,那么可以采用Pub/Sub模型
4、常用中间件介绍与对比
1、kafka
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。
2、RabbitMQ
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
3、RocketMQ
RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
RabbitMQ比Kafka可靠,Kafka更适合IO高吞吐的处理,一般应用在大数据日志处理或对实时性(少量延迟),可靠性(少量丢数据)要求稍低的场景使用,比如ELK日志收集。
二、RabbitMQ详解
1、RabbitMQ介绍
RabbitMQ 是一个在 AMQP(Advanced Message Queuing Protocol 高级消息队列协议)基础上实现的,可复用的企业消息系统。它可以用于大型软件系统各个模块之间的高效通信,支持高并发,支持可扩展。它支持多种客户端如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX,持久化,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正是如此,使的它变的非常重量级,更适合于企业级的开发。它同时实现了一个Broker构架,这意味着消息在发送给客户端时先在中心队列排队,对路由(Routing)、负载均衡(Load balance)或者数据持久化都有很好的支持。
2、RabbitMQ 特点
-
可靠性
-
灵活的路由
-
扩展性
-
高可用性
-
多种协议
-
多语言客户端
-
管理界面
-
插件机制
3、AMQP 介绍
AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。
4、什么是消息队列
MQ 全称为Message Queue, 消息队列。是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。
消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
在项目中,将一些无需即时返回且耗时的操作提取出来,进行了异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量。
5、RabbitMQ 概念介绍
-
Broker:简单来说就是消息队列服务器实体。
-
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
-
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
-
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
-
Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
-
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
-
producer:消息生产者,就是投递消息的程序。
-
consumer:消息消费者,就是接受消息的程序。
-
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
-
RabbitMQ从整体上来看是一个典型的生产者消费者模型,主要负责接收、存储和转发消息
三、RabbitMQ 单机安装部署
1、安装erlang
[root@localhost ~]# wget --content-disposition https://packagecloud.io/rabbitmq/erlang/packages/el/7/erlang-23.3.4.11-1.el7.x86_64.rpm/download.rpm
[root@localhost ~]# yum install erlang-23.3.4.11-1.el7.x86_64 -y
2、安装RabbitMQ
[root@localhost ~]# wget --content-disposition https://packagecloud.io/rabbitmq/rabbitmq-server/packages/el/7/rabbitmq-server-3.10.0-1.el7.noarch.rpm/download.rpm
[root@localhost ~]# yum -y install rabbitmq-server-3.10.0-1.el7.noarch.rpm
3、启动服务
systemctl start rabbitmq-server
4、配置远程访问
老版本的配置文件是/usr/share/doc/rabbitmq-server-3.7.13/rabbitmq.config.example,把这个文件拷贝到/etc/rabbitmq,改为.config结尾,然后将loopback user.guest = false 的注释取消
新版本没有配置文件,我们可以网上搜一个上传到/etc/rabbitmq目录下,改为.conf结尾
vim /etc/rabbitmq/rabbitmq.conf
loopback_users.guest = false
5、开启web界面管理工具
[root@localhost ~]# rabbitmq-plugins enable rabbitmq_management
[root@localhost ~]# systemctl restart rabbitmq-server
注意:如果web界面插件不能启动
添加一个本地解析(ip 主机名)
再次启用插件
6、浏览器访问
浏览器访问192.168.242.144:15672
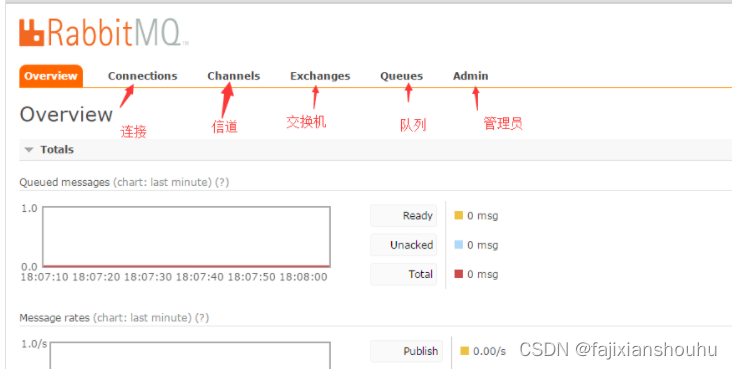
注意设置虚拟主机与添加用户这块
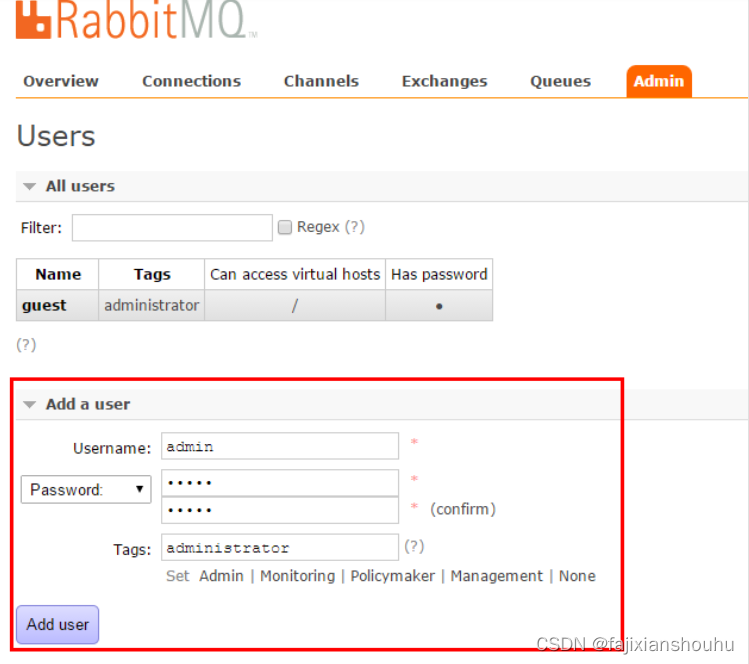
7、用户角色
1、超级管理员(administrator)
可登陆管理控制台,可查看所有的信息,并且可以对用户,策略(policy)进行操作。
2、监控者(monitoring)
可登陆管理控制台,同时可以查看rabbitmq节点的相关信息(进程数,内存使用情况,磁盘使用情况等)
3、策略制定者(policymaker)
可登陆管理控制台, 同时可以对policy进行管理。但无法查看节点的相关信息(上图红框标识的部分)。
4、普通管理者(management)
仅可登陆管理控制台,无法看到节点信息,也无法对策略进行管理。
5、其他
无法登陆管理控制台,通常就是普通的生产者和消费者。
四、RabbitMQ集群部署及配置
1、原理介绍
RabbitMQ是依据erlang的分布式特性(RabbitMQ底层是通过Erlang架构来实现的,所以rabbitmqctl会启动erlang节点,并基于erlang节点来使用erlang系统连接RabbitMQ节点,在连接过程中需要正确的erlang cookie和节点名称,erlang节点通过交换erlang cookie以获得认证)来实现的,所以部署rabbitmq分布式集群时要安装erlang,并把其中一个服务器的cookie复制到另外的节点。
RabbitMQ集群中,各个RabbitMQ为对等节点,即每个节点均提供给客户端连接,进行消息的接受和发送。节点分为内存节点和磁盘节点,一般的,均应建立为磁盘节点,为例防止机器重启后的消息消失;
RabbitMQ的cluster集群模式一般分为两种,普通模式和镜像模式。消息队列通过RabbitMQ HA镜像队列进行消息队列实体复制。
普通模式下,以两个节点(rabbit01、rabbit02)为例来进行说明。对于Queue来说,消息实体只存在于其中一个节点rabbit01(或者rabbit02)rabbit01和rabbit02两个节点仅有相同的元数据,即队列的结构。当消息进入rabbit01节点的Queue后,consumer从rabbit02节点消费时,RabbitMQ会临时在rabbit01、rabbit02间进行传输,把A中的消息实体取出并经过 B发送给consumer。所以consumer应尽量连接每一个节点从中取消息。即对于同一个逻辑队列,要建立多个节点建立物理Queue。否则无论consumer连rabbit01或rabbit02,出口总在rabbit01,会产生瓶颈。
镜像模式下,将需要消费的队列变成镜像队列,存在于多个节点中,这样就可以实现RabbitMQ高可用性。作用就是消息实体会主动在镜像节点之间实现同步,而不是像普通模式那样,在consumer消费数据时临时读取,缺点就是,集群内部的同步通讯会占用大量的网络宽带。
2、部署rabbitMQ cluter
1、rabbitmq有三种模式,但集群模式就两种
单一模式:即单机情况不做集群,就单独运行一个rabbitmq而已。
普通模式:即默认模式,以两个节点(rabbit01、rabbit02)为例来进行说明。对于Queue来说消息实体只存在于其中一个节点rabbit01或者 rabbit02),rabbit01 和 rabbit02 两个节点仅有相同的元数据,即队列的结构。当消息进入 rabbit01 节点的 Queue 后,consumer 从 rabbit02 节点消费时,RabbitMQ 会临时在 rabbit01、rabbit02 间进行消息传输,把 A 中的消息实体取出并经过 B 发送给 consumer。所以 consumer 应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理 Queue。否则无论 consumer 连 rabbit01 或 rabbit02,出口总在 rabbit01,会产生瓶颈。当rabbit01节点故障之后,rabbit02节点无法取到rabbit01节点中还未消费的消息实体。如果做了消息持久化,那么得等rabbit01节点恢复,然后才可以被消费;如果没有持久化的话,就会产生消息丢失的现象。
镜像模式:把需要的队列做成镜像队列,存在于多个节点中属于RabbitMQ的HA方案。该模式解决了普通模式中的问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在客户端取数据时临时拉取。该模式的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络宽带将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的长河中适用。
2、环境准备
192.168.242.144
192.168.242.145
192.168.242.146
3、三台机器都做域名解析
192.168.120.138 rabbitmq-1
192.168.120.139 rabbitmq-2
192.168.120.140 rabbitmq-3
注意:所有的服务器除了做本地解析外,本地的域名 是你的主机名 (所有服务器都要修改主机名)
4、保证三台都能ping通
[root@rabbitmq1 ~]# ping rabbitmq1
PING 192.168.31.154 (192.168.31.154) 56(84) bytes of data.
64 bytes from 192.168.31.154: icmp_seq=1 ttl=64 time=0.025 ms
....
[root@rabbitmq1 ~]# ping rabbitmq2
PING 192.168.31.155 (192.168.31.155) 56(84) bytes of data.
64 bytes from 192.168.31.155: icmp_seq=1 ttl=64 time=0.742 ms
...
[root@rabbitmq1 ~]# ping rabbitmq3
PING 192.168.31.156 (192.168.31.156) 56(84) bytes of data.
64 bytes from 192.168.31.156: icmp_seq=1 ttl=64 time=1.15 ms
...5、安装RabbitMQ
安装RabbitMQ的以来环境erlang,三台机器做同样的操作
wget --content-disposition https://packagecloud.io/rabbitmq/erlang/packages/el/7/erlang-23.3.4.11-1.el7.x86_64.rpm/download.rpm
yum install erlang-23.3.4.11-1.el7.x86_64 -y
安装socat,三台都做
yum install -y socat
安装RabbitMQ,三台都做
wget --content-disposition https://packagecloud.io/rabbitmq/rabbitmq-server/packages/el/7/rabbitmq
yum -y install rabbitmq-server-3.10.0-1.el7.noarch.rpm6、所有机器都开启用户远程登录
把上个实验用到的配置文件拿过来用
vim rabbitmq.conf
loopback_users.guest = false
7、开启web访问界面
三台都做
[root@rabbitmq1 ~]# systemctl start rabbitmq-server.service
每台都操作开启rabbitmq的web访问界面:
[root@rabbitmq-1 ~]# rabbitmq-plugins enable rabbitmq_management8、账号配置
安装启动后其实还不能在其他机器访问,RabbitMQ磨人的guest账号只能在本地机器访问,如果想在其他机器访问必须配置其他账号
创建用户:
注意:在一台机器操作
添加用户和密码
[root@rabbitmq-1 ~]# rabbitmqctl add_user zcg zcy
Creating user "zcg" ...
...done.
这是为管理员
[root@rabbitmq-1 ~]# rabbitmqctl set_user_tags soho administrator
Setting tags for user "zcg" to [administrator] ...
...done.
查看用户
[root@rabbitmq-1 ~]# rabbitmqctl list_users
Listing users ...
guest [administrator]
zcg [administrator]
9、设置权限
[root@rabbitmq-1 ~]# rabbitmqctl set_permissions -p "/" zcg ".*" ".*" ".*"
Setting permissions for user "soho" in vhost "/" ...
...done.
此处设置权限时注意'.*'之间需要有空格 三个'.*'分别代表了conf权限,read权限与write权限 例如:当没有给zcg设置这三个权限前是没有权限查询队列,在ui界面也看不见
10、端口
4369 -- erlang发现口
5672 --程序连接端口
15672 -- 管理界面ui端口
25672 -- server间内部通信口
rabbitmq默认管理员用户:guest 密码:guest
11、集群部署
首先创建好数据存放目录和日志存放目录:
[root@rabbitmq-1 ~]# mkdir -p /data/rabbitmq/data
[root@rabbitmq-1 ~]# mkdir -p /data/rabbitmq/logs
[root@rabbitmq-1 ~]# chmod 777 -R /data/rabbitmq
[root@rabbitmq-1 ~]# chown rabbitmq.rabbitmq /data/ -R
创建配置文件:
[root@rabbitmq-1 ~]# vim /etc/rabbitmq/rabbitmq-env.conf
[root@rabbitmq-1 ~]# cat /etc/rabbitmq/rabbitmq-env.conf
RABBITMQ_MNESIA_BASE=/data/rabbitmq/data
RABBITMQ_LOG_BASE=/data/rabbitmq/logs
重启服务
[root@rabbitmq-1 ~]# systemctl restart rabbitmq-server
注意在其他两台机器上也做同样的操作12、拷贝erlang.cookie
Rabbitmq的集群是依附于erlang的集群来⼯作的,所以必须先构建起erlang的集群景象。Erlang的集群中各节点是经由⼀个cookie来实现的,这个cookie存放在/var/lib/rabbitmq/.erlang.cookie中,⽂件是400的权限。所以必须保证各节点cookie⼀致,不然节点之间就⽆法通信。
在部署集群时,要先把功能停用,不是停用RabbitMQ服务
#如果执行# rabbitmqctl stop_app 这条命令报错:需要执行
#chmod 400 .erlang.cookie
#chown rabbitmq.rabbitmq .erlang.cookie
(官方在介绍集群的文档中提到过.erlang.cookie 一般会存在这两个地址:第一个是home/.erlang.cookie;第二个地方就是/var/lib/rabbitmq/.erlang.cookie。如果我们使用解压缩方式安装部署的rabbitmq,那么这个文件会在{home}目录下,也就是$home/.erlang.cookie。如果我们使用rpm等安装包方式进行安装的,那么这个文件会在/var/lib/rabbitmq目录下。)
[root@rabbitmq-1 ~]# cat /var/lib/rabbitmq/.erlang.cookie
HOUCUGJDZYTFZDSWXTHJ
⽤scp的⽅式将rabbitmq-1节点的.erlang.cookie的值复制到其他两个节点中。
[root@rabbitmq-1 ~]# scp /var/lib/rabbitmq/.erlang.cookie root@192.168.242.145:/var/lib/rabbitmq/
[root@rabbitmq-1 ~]# scp /var/lib/rabbitmq/.erlang.cookie root@192.168.242.146:/var/lib/rabbitmq/13、将mq-2、mq-3作为内存节点加⼊mq-1节点集群中
[root@rabbitmq-2 ~]# systemctl restart rabbitmq-server
[root@rabbitmq-2 ~]# rabbitmqctl stop_app #停止节点,切记不是停止服务
[root@rabbitmq-2 ~]# rabbitmqctl reset #如果有数据需要重置,没有则不用
[root@rabbitmq-2 ~]# rabbitmqctl join_cluster --ram rabbit@rabbitmq-1
Clustering node 'rabbit@rabbitmq-2' with 'rabbit@rabbitmq-1' ...
[root@rabbitmq-2 ~]# rabbitmqctl start_app #启动节点
Starting node 'rabbit@rabbitmq-2' ...
rabbitmq-3也做同样的操作(1)默认rabbitmq启动后是磁盘节点,在这个cluster命令下,mq-2和mq-3是内存节点,mq-1是磁盘节点。
(2)如果要使mq-2、mq-3都是磁盘节点,去掉--ram参数即可。
(3)如果想要更改节点类型,可以使⽤命令rabbitmqctl change_cluster_node_type,disc(ram),前提是必须停掉rabbit应⽤
需要使用磁盘节点加入集群的话执行下面的命令
[root@rabbitmq-2 ~]# rabbitmqctl join_cluster rabbit@rabbitmq-1
[root@rabbitmq-3 ~]# rabbitmqctl join_cluster rabbit@rabbitmq-1
14、查看集群状态
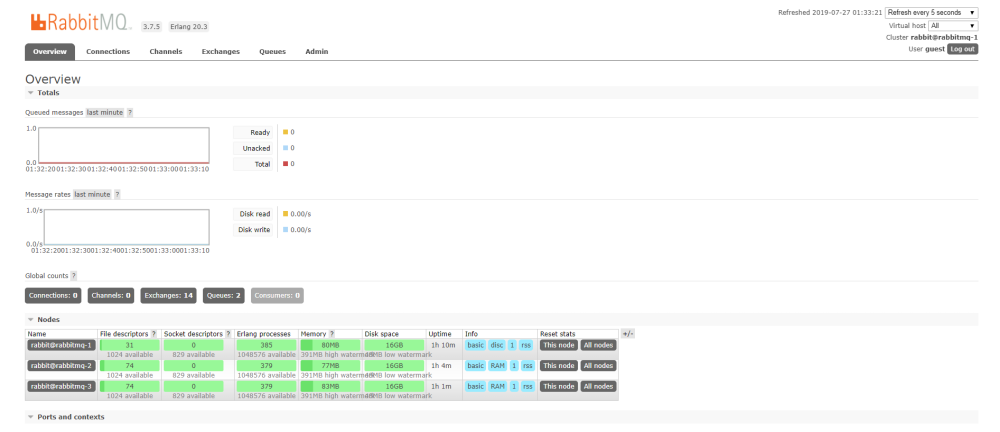
在 RabbitMQ 集群任意节点上执行 rabbitmqctl cluster_status来查看是否集群配置成功。
在mq-1磁盘节点上面查看

15、 登录rabbitmq web管理控制台,创建新的队列
打开浏览器输⼊http://192.168.242.144:15672
输⼊默认的Username:guest
输⼊默认的Password:guest
可以看到节点状态
16、 根据界⾯提示创建⼀条队列
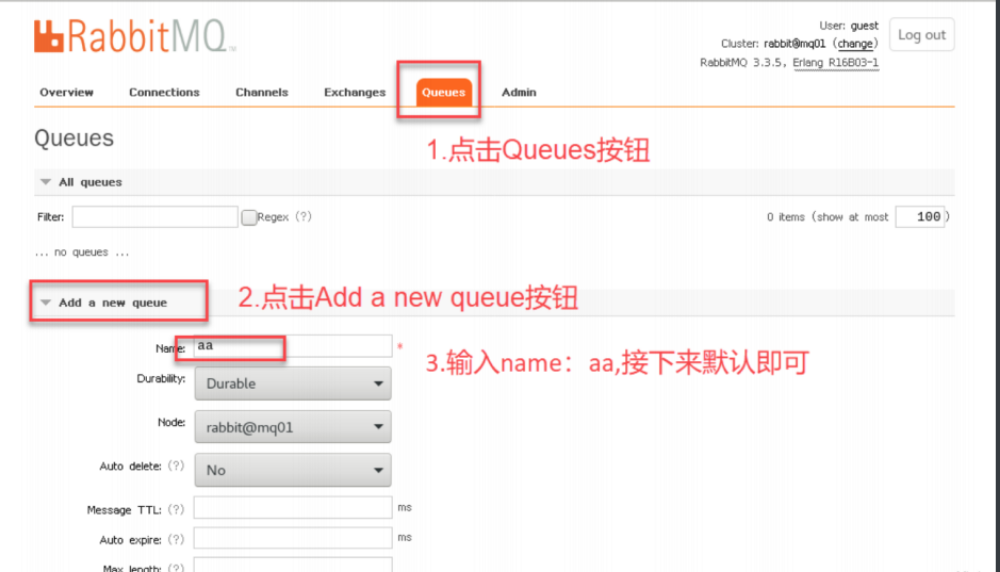
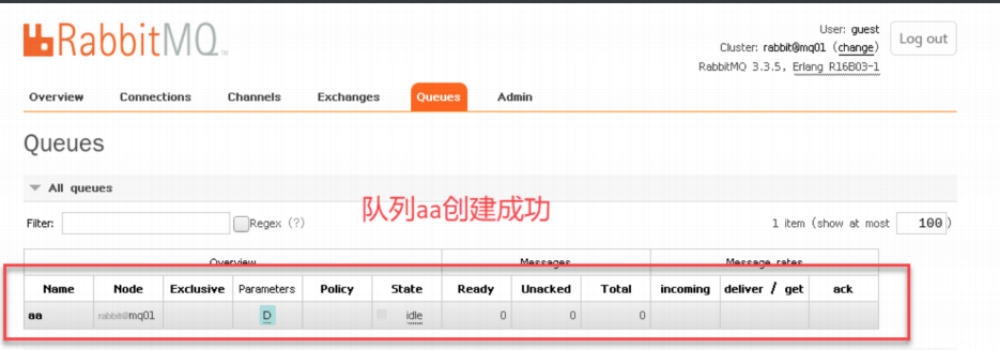
在RabbitMQ集群中,必须⾄少有⼀个磁盘节点,否则队列元数据⽆法写⼊到集群中,当磁盘节点宕掉时,集群将⽆法写⼊新的队列元数据信息。
3、部署RabbitMQ镜像配置
上面已经完成RabbitMQ默认集群模式,但并不保证队列的高可用性,队列内容不会复制。如果队列节点宕机直接导致该队列无法应用,只能等待重启,所以要想在队列节点宕机或故障也能正常应用,就要复制队列内容到集群里的每个节点,必须要创建镜像队列。
镜像队列是基于普通的集群模式的。
1、创建镜像集群:三台机器相同操作
rabbitmq set_policy :设置策略
[root@rabbitmq-1 ~]#rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
Setting policy "ha-all" for pattern "^" to "{"ha-mode":"all"}" with priority "0" for vhost "/" ...
[root@rabbitmq-2 ~]# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
Setting policy "ha-all" for pattern "^" to "{"ha-mode":"all"}" with priority "0" for vhost "/" ...
[root@rabbitmq-3 ~]# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
Setting policy "ha-all" for pattern "^" to "{"ha-mode":"all"}" with priority "0" for vhost "/" ...
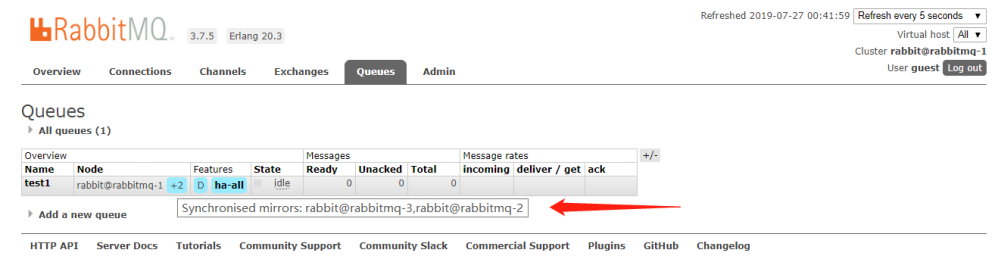
"^"匹配所有的队列, ha-all 策略名称为ha-all, '{"ha-mode":"all"}' 策略模式为 all 即复制到所有节点,包含新增节点。
2、设置节点策略介绍
rabbitmqctl set_policy [-p Vhost] Name Pattern Definition
-p Vhost: 可选参数,针对指定vhost下的queue进行设置
Name: policy(策略)的名称
Pattern: queue的匹配模式(正则表达式),也就是说会匹配一组。
Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
all:表示在集群中所有的节点上进行镜像
exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-params:ha-mode模式需要用到的参数
ha-sync-mode:进行队列中消息的同步方式,有效值为automatic(自动)和manual(手动)
案例:
例如,对队列名称以hello开头的所有队列进行镜像,并在集群的两个节点上完成镜像,policy的设置命令为:
rabbitmqctl set_policy hello-ha "^hello" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
rabbitmqctl set_policy hello-ha "^hello" '{"ha-mode":"nodes","ha-params":["rabbit@rabbitmq-2"],"ha-sync-mode":"automatic"}'
则此时镜像队列设置成功。
已经部署完成
将所有队列设置为镜像队列,即队列会被复制到各个节点,各个节点状态保持一致。
扩展
官方手册:https://www.rabbitmq.com/documentation.html
任何参数或者命令都可以在这个手册中找到使用方法,学会使用官方手册很重要。















 1085
1085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









