







题目:
算法中需要打印消费前十老板的消费金额,解决保留两位小数,并发是 JAVA 中的常考题,

我这里简单模拟下了数据,关键数据是用户id和消费金额。
解题思路:
1. 最简单的思路是单线程,偷懒(dog),
public class Main {
public static void main(String[] args) throws FileNotFoundException {
Scanner scanner = new Scanner(new File("C:\\Users\\15031\\Desktop\\momo\\momo\\src\\data.txt"));
System.out.println(scanner.nextLine());
HashMap<Integer,Double>map = new HashMap<>();
String s = scanner.nextLine();
while (scanner.hasNextLine()) {
String line = scanner.nextLine();
String[] partLine = line.split(" ");
int userId = Integer.parseInt(partLine[1]);
double order = Double.parseDouble(partLine[2]);
map.put(userId,map.getOrDefault(userId,0d) + order);
}
Queue<Map.Entry<Integer,Double>>queue = new PriorityQueue<>((entry0,entry1)->
Double.compare(entry0.getValue(),entry1.getValue()));
for(Map.Entry<Integer,Double> e : map.entrySet()){
if(queue.size() < 10){
queue.offer(e);
}else {
queue.poll();
queue.offer(e);
}
}
for(Map.Entry<Integer,Double> e : queue){
System.out.println(e.getKey()+","+String.format("%.2f", e.getValue()));
}
}
}
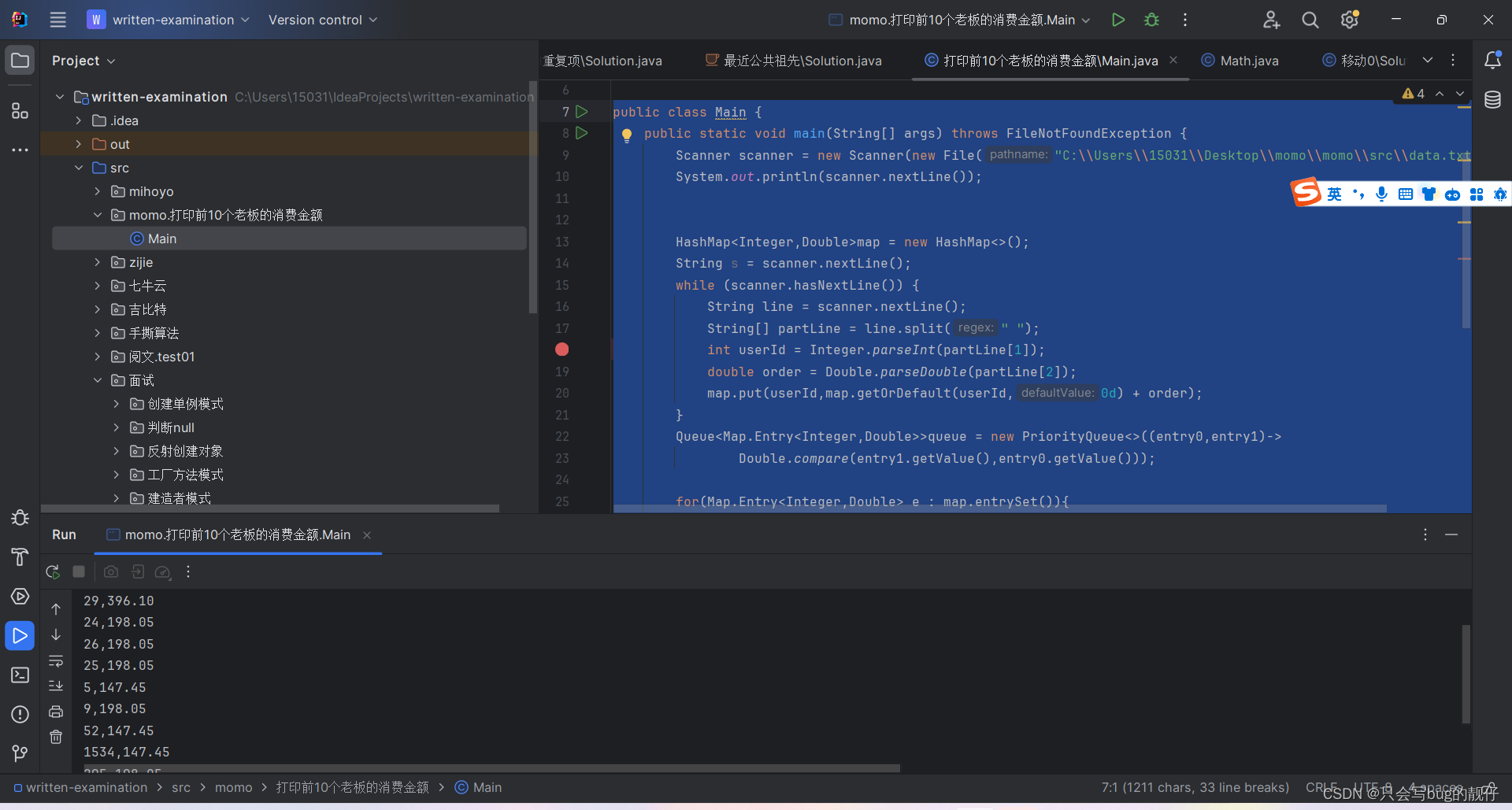
我们可以使用文件流读取数据偷懒,然后再使用
hashmap统计出现的次数,然后再使用优先队列统计前k个字符串,然后输出。
2. 多线程解决思路
多线程实际上要复杂的多,要考虑一个线程处理多少数据合适,当然,这是最笨的方法,甚至还要考虑是否要读入到内存里,如果数据较多,可能考虑内存占用问题。简单数据还好,可能几十万行也就占用几百兆内存。
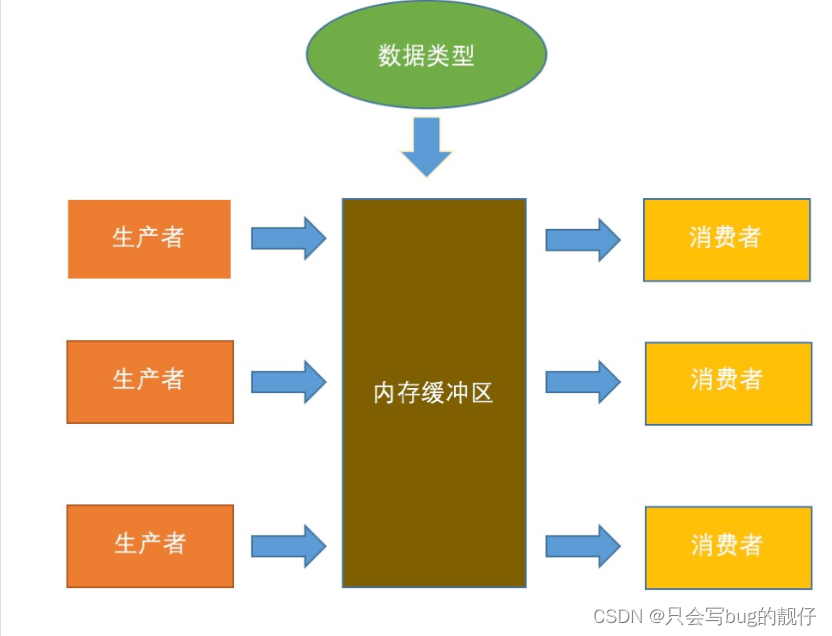
- 内存缓冲器区
我们使用BlockingQueue,该队列是生产者消费者模型中常用的类
BlockingQueue<String> queue = new LinkedBlockingQueue<>();
- 这里我们使用一个线程做生产者,多线程不知道怎么生产(dog),
BlockingQueue做缓冲区。
生产者,生产者文件流如果使用多线程读取会比较复杂,故我们使用单线程,还有一个问题是读一行感觉消费处理起来也并不太高。(当然这里就先偷懒了)
producerExecutor.submit(() -> {
try (Scanner scanner = new Scanner(new File("C:\\Users\\15031\\Desktop\\momo\\momo\\src\\data.txt"))) {
while (scanner.hasNextLine()) {
queue.put(scanner.nextLine());
}
for (int j = 0; j < CONSUMER_COUNT; j++) {
queue.put("EOF"); // End-of-file markers for consumer threads
}
} catch (FileNotFoundException | InterruptedException e) {
e.printStackTrace();
}
});
- 消费者处理
消费者这里我们直接使用线程池处理了,需要注意的是线程数并非越多越好,最好和计算机 cpu 核心数有相关性,同时这里一行数据切换一个线程也并不能提升效率(dog)
for (int i = 0; i < CONSUMER_COUNT; i++) {
consumerExecutor.submit(() -> {
try {
while (true) {
List<String> batch = queue.take();
if (batch.contains("EOF")) {
queue.put(Collections.singletonList("EOF")); // Pass the marker to other consumers
break;
}
for (String line : batch) {
String[] partLine = line.split(" ");
int userId = Integer.parseInt(partLine[1]);
double order = Double.parseDouble(partLine[2]);
map.merge(userId, order, Double::sum);
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
为什么要添加消费者数量的EOF 而不是先peek判断,然后再取出呢?
- 线程安全:在使用 peek() 和 poll() 时,需要确保操作的原子性。使用两步操作会强行把原子操作变成不原子的,在操作之间peek()的数据可能被修改,造成线程安全问题。
- 简化实现:尽可能简化并发模型可以减少复杂性和错误的可能性。直接使用 take() 可以确保每个元素只被处理一次,逻辑更为简单。
- 总体代码
```java
public class Main {
private static final int PRODUCER_COUNT = 1; // 生产者threads
private static final int CONSUMER_COUNT = 4; // 消费者threads
private static final int TOP_N = 10; // Top N users by order amount
public static void main(String[] args) throws FileNotFoundException {
BlockingQueue<String> queue = new LinkedBlockingQueue<>();
ConcurrentHashMap<Integer, Double> map = new ConcurrentHashMap<>();
ExecutorService producerExecutor = Executors.newFixedThreadPool(PRODUCER_COUNT);
ExecutorService consumerExecutor = Executors.newFixedThreadPool(CONSUMER_COUNT);
// Producer threads
for (int i = 0; i < PRODUCER_COUNT; i++) {
producerExecutor.submit(() -> {
try (Scanner scanner = new Scanner(new File("C:\\Users\\15031\\Desktop\\momo\\momo\\src\\data.txt"))) {
while (scanner.hasNextLine()) {
queue.put(scanner.nextLine());
}
for (int j = 0; j < CONSUMER_COUNT; j++) {
queue.put("EOF"); // End-of-file markers for consumer threads
}
} catch (FileNotFoundException | InterruptedException e) {
e.printStackTrace();
}
});
}
// Consumer threads
for (int i = 0; i < CONSUMER_COUNT; i++) {
consumerExecutor.submit(() -> {
try {
while (true) {
String line = queue.take();
if ("EOF".equals(line)) {
queue.put("EOF"); // Pass the marker to other consumers
break;
}
String[] partLine = line.split(" ");
int userId = Integer.parseInt(partLine[1]);
double order = Double.parseDouble(partLine[2]);
map.merge(userId, order, Double::sum);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
producerExecutor.shutdown();
consumerExecutor.shutdown();
try {
producerExecutor.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
consumerExecutor.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
// Process the map to find top N users
PriorityQueue<Map.Entry<Integer, Double>> queueTopN = new PriorityQueue<>(Map.Entry.comparingByValue());
for (Map.Entry<Integer, Double> entry : map.entrySet()) {
if (queueTopN.size() < TOP_N) {
queueTopN.offer(entry);
} else if (entry.getValue() > queueTopN.peek().getValue()) {
queueTopN.poll();
queueTopN.offer(entry);
}
}
List<Map.Entry<Integer, Double>> topNList = new ArrayList<>(queueTopN);
topNList.sort((e0,e1)-> (int) (e0.getValue()-e1.getValue()));
for (Map.Entry<Integer, Double> entry : topNList) {
System.out.println(entry.getKey() + "," + String.format("%.2f", entry.getValue()));
}
}
}
思考:
😄 这里主要是对生产者和消费者模式的一个总结和复习,这些处理模式可能平时没感觉怎么用,但是一结合实际,我们就立马可以感受到这些处理的模式的优异之处了。
















 2375
2375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











