









 本文深入探讨了深度学习中神经网络的数据表示,包括在Numpy中操作张量,介绍如何进行张量切片。还讨论了数据批量的概念,以及在现实世界中如何表示向量、时间序列、图像和视频数据。了解这些基础知识对于算法工程师在深度学习实践中至关重要。
本文深入探讨了深度学习中神经网络的数据表示,包括在Numpy中操作张量,介绍如何进行张量切片。还讨论了数据批量的概念,以及在现实世界中如何表示向量、时间序列、图像和视频数据。了解这些基础知识对于算法工程师在深度学习实践中至关重要。
深度学习基础
神经网络的数学基础
神经网络的数据表示
在 Numpy 中操作张量
-
我们可以使用语法 train_images[i] 来选择沿着第一个轴的特定数字,选择张量的特定元素叫作张量切片(tensor slicing)。
-
我们来看一下 Numpy 数组上的张量切片运算:
选择第10~100个数字(不包括第100个),并将其放在形状为(90, 28, 28) 的数组中。 >>> my_slice = train_images[10:100] >>> print(my_slice.shape) (90, 28, 28) -
它等同于下面这个更复杂的写法,给出了切片沿着每个张量轴的起始索引和结束索引, : 等同于选择整个轴。
# 等同于前面的例子 >>> my_slice = train_images[10:100, :, :] >>> my_slice.shape (90, 28, 28) # 也等同于前面的例子 >>> my_slice = train_images[10:100, 0:28, 0:28] >>> my_slice.shape (90, 28, 28) -
一般来说,你可以沿着每个张量轴在任意两个索引之间进行选择。
-
例如,你可以在所有图像的右下角选出14像素×14像素的区域:
my_slice = train_images[:, 14:, 14:] -
也可以使用负数索引,与 Python 列表中的负数索引类似,它表示与当前轴终点的相对位置。你可以在图像中心裁剪出14像素×14像素的区域:
my_slice = train_images[:, 7:-7, 7:-7]
-
数据批量的概念
-
深度学习中所有数据张量的第一个轴(0 轴,因为索引从0开始)都是样本轴(samples axis,有时也叫样本维度)。 在 MNIST 的例子中,样本就是数字图像。
-
深度学习模型不会同时处理整个数据集,而是将数据拆分成小批量。
-
具体来看,下面是 MNIST 数据集的一个批量,批量大小为128:
batch = train_images[:128] -
然后是下一个批量:
batch = train_images[128:256] -
然后是第 n 个批量:
batch = train_images[128 * n:128 * (n + 1)] -
对于这种批量张量,第一个轴(0轴)叫作批量轴(batch axis)或批量维度(batch dimension)。
-
现实世界中的数据张量
-
向量数据:2D 张量,形状为 (samples, features)。
-
时间序列数据或序列数据:3D 张量,形状为 (samples, timesteps, features)。
-
图像:4D 张量,形状为 (samples, height, width, channels) 或 (samples, channels, height, width)。
-
视频:5D 张量,形状为 (samples, frames, height, width, channels) 或 (samples, frames, channels, height, width)。
向量数据
-
对于这种数据集,每个数据点都被编码为一个向量,因此一个数据批量就被编码为2D张量(即向量组成的数组),其中第一个轴是样本轴,第二个轴是特征轴。
-
人口统计数据集
- 其中包括每个人的年龄、邮编和收入。
- 每个人可以表示为包含3个值的向量,而整个数据集包含100000个人,因此可以存储在形状为 (100000, 3) 的 2D 张量中。
-
文本文档数据集
- 我们将每个文档表示为每个单词在其中出现的次数(字典中包含20000个常见单词)。
- 每个文档可以被编码为包含20000个值的向量(每个值对应于字典中每个单词的出现次数),整个数据集包含500个文档,因此可以存储在形状为(500, 20000)的张量中。
时间序列数据或序列数据
-
当时间(或序列顺序)对于数据很重要时,应该将数据存储在带有时间轴的 3D 张量中。每个样本可以被编码为一个向量序列(即 2D 张量),因此一个数据批量就被编码为一个 3D 张量。根据惯例,时间轴始终是第2个轴(索引为1的轴)。
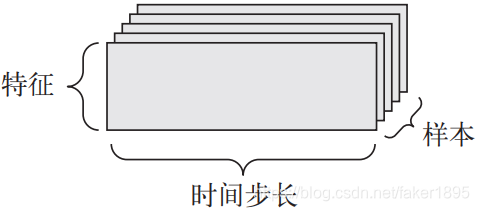
-
股票价格数据集
- 每一分钟,我们将股票的当前价格、前一分钟的最高价格和前一分钟的最低价格保存下来。
- 因此每分钟被编码为一个 3D 向量,整个交易日被编码为一个形状为(390, 3)的 2D 张量(一个交易日有390分钟),而250天的数据则可以保存在一个形状为(250, 390, 3)的 3D 张量中。
- 这里每个样本是一天的股票数据。
-
推文数据集
- 我们将每条推文编码为280个字符组成的序列,而每个字符又来自于128个字符组成的字母表。
- 在这种情况下,每个字符可以被编码为大小为128的二进制向量(只有在该字符对应的索引位置取值为1,其他元素都为0)。
- 那么每条推文可以被编码为一个形状为 (280, 128) 的 2D 张量,而包含100万条推文的数据集则可以存储在一个形状为(1000000, 280, 128)的张量中。
图像数据
-
图像通常具有三个维度:高度、宽度和颜色深度。
-
虽然灰度图像(比如 MNIST 数字图像)只有一个颜色通道,因此可以保存在 2D 张量中,但按照惯例,图像张量始终都是 3D 张量,灰度图像的彩色通道只有一维。因此,如果图像大小为256×256,那么128张灰度图像组成的批量可以保存在一个形状为(128, 256, 256, 1)的张量中,而128张彩色图像组成的批量则可以保存在一个形状为(128, 256, 256, 3) 的张量中。
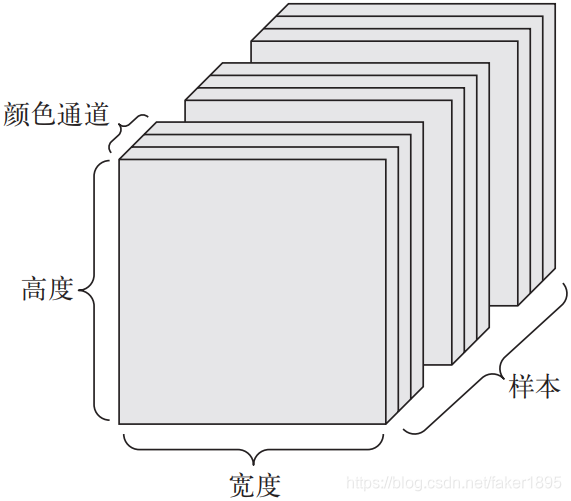
-
图像张量的形状有两种约定:通道在后(channels-last)的约定(在 TensorFlow 中使用)和通道在前(channels-first)的约定(在 Theano 中使用)。
-
Google 的 TensorFlow 机器学习框架将颜色深度轴放在最后:(samples, height, width, color_depth)。与此相反,Theano 将图像深度轴放在批量轴之后:(samples, color_depth, height, width)。Keras 框架同时支持这两种格式。
视频数据
-
视频数据是现实生活中需要用到 5D 张量的少数数据类型之一。
-
视频可以看作一系列帧,每一帧都是一张彩色图像。由于每一帧都可以保存在一个形状为 (height, width, color_depth) 的 3D 张量中,因此一系列帧可以保存在一个形状为(frames, height, width, color_depth) 的 4D 张量中,而不同视频组成的批量则可以保存在一个 5D 张量中,其形状为(samples, frames, height, width, color_depth)。

















 4705
4705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









