









Classical Regularization: Parameter Norm Penalty
Most classical regularization approaches are based on limiting the capacity of models, by adding a parameter norm penalty
Ω
(
θ
)
\Omega(\theta)
Ω(θ) to the Objective function
J
J
J.
J ( θ ; X , y ) = J ( θ ; X , y ) + α Ω ( θ ) J(\theta;X,y)=J(\theta;X,y)+\alpha\Omega(\theta) J(θ;X,y)=J(θ;X,y)+αΩ(θ)
L 2 L^2 L2 Parameter Regularization, weight decay
Regularization term Ω ( θ ) = 1 2 ∥ w ∥ 2 2 \Omega(\theta)=\frac{1}{2}\left \|w \right \|^2_2 Ω(θ)=21∥w∥22
Gradient of the total objective function:
∇ w J ~ ( w ; X , y ) = α w + ∇ w J ( w ; X , y ) w : = w − ϵ ( α w + ∇ w J ( w ; X , y ) ) \nabla_w\tilde{J}(w;X,y)=\alpha w+ \nabla_wJ(w;X,y) \\ w := w -\epsilon (\alpha w + \nabla_w J(w;X,y)) ∇wJ~(w;X,y)=αw+∇wJ(w;X,y)w:=w−ϵ(αw+∇wJ(w;X,y))
插播一个公式,Taylor展开式: f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + f ′ ′ ( x 0 ) ( x − x 0 ) 2 + . . . f(x)=f(x_0)+f'(x_0)(x-x_0)+f''(x_0)(x-x_0)^2+... f(x)=f(x0)+f′(x0)(x−x0)+f′′(x0)(x−x0)2+...
assume w ⋆ w^\star w⋆ is the optimal solution of J J J, that is ∇ J ( w ⋆ ) = 0 \nabla J(w^{\star})=0 ∇J(w⋆)=0.
J ( w ) J(w) J(w)在 w ⋆ w^{\star} w⋆的Taylor展开式为: J ^ ( w ) = J ( w ⋆ ) + 1 2 ( w − w ⋆ ) T H ( w − w ⋆ ) \hat{J}(w)=J(w^{\star})+\frac{1}{2} (w-w^{\star})^TH(w-w^{\star}) J^(w)=J(w⋆)+21(w−w⋆)TH(w−w⋆).
substitue to pervious equation,
∇ w J ~ ( w ; X , y ) = α w + H ( w − w ⋆ ) \nabla_w \tilde{J}(w;X,y)=\alpha w+H(w-w^{\star}) ∇wJ~(w;X,y)=αw+H(w−w⋆), set it to 0 0 0.
α
w
+
H
(
w
−
w
⋆
)
=
=
0
w
~
=
(
H
+
α
I
)
−
1
H
w
⋆
\alpha w+H(w-w^{\star})==0 \\ \tilde{w}=(H+\alpha I)^{-1}H w^{\star}
αw+H(w−w⋆)==0w~=(H+αI)−1Hw⋆
w
~
\tilde{w}
w~ is new solution, that’s how my solution is going to change after weight decay.
If α → 0 , w ~ → w ⋆ \alpha \rightarrow 0, \tilde{w} \rightarrow w^{\star} α→0,w~→w⋆, what if α \alpha α is not 0.
H is symmetric, so it can be decomposed by H = Q Λ Q T H=Q\Lambda Q^T H=QΛQT, substitue to the previous equation, we get, w ~ = ( Q Λ Q T + α I ) − 1 H w ⋆ = ( Q ( Λ + α I ) Q T ) − 1 Q Λ Q T w ⋆ = ( Q ( Λ + α I ) − 1 Q T ) Q Λ Q T w ⋆ = Q ( Λ + α I ) − 1 Λ Q T w ⋆ \tilde{w}=(Q\Lambda Q^T+\alpha I)^{-1}Hw^{\star} \\= (Q(\Lambda+\alpha I)Q^T)^{-1}Q\Lambda Q^T w^{\star} \\= (Q(\Lambda+\alpha I)^{-1}Q^T)Q\Lambda Q^T w^{\star} \\=Q(\Lambda+\alpha I)^{-1}\Lambda Q^T w^{\star} w~=(QΛQT+αI)−1Hw⋆=(Q(Λ+αI)QT)−1QΛQTw⋆=(Q(Λ+αI)−1QT)QΛQTw⋆=Q(Λ+αI)−1ΛQTw⋆
中间项展开式如下图所示,也是一个对角矩阵。 Q , Q T Q,Q^T Q,QT都可以看作旋转矩阵,并且它们两个是向相反的方向旋转。上面的等式可以这么理解:经过weight decay后的解是将原来的解,换到不同的基上,并且在每个方向都乘上一个系数。如果 λ i > > α \lambda_i >> \alpha λi>>α,系数趋近于1,反之,趋近于0。这样就会去掉一些项。
Hessian matrix of J J J,代表 J J J在某些方向上的变化快慢。 H = Q Λ Q T H=Q \Lambda Q^T H=QΛQT
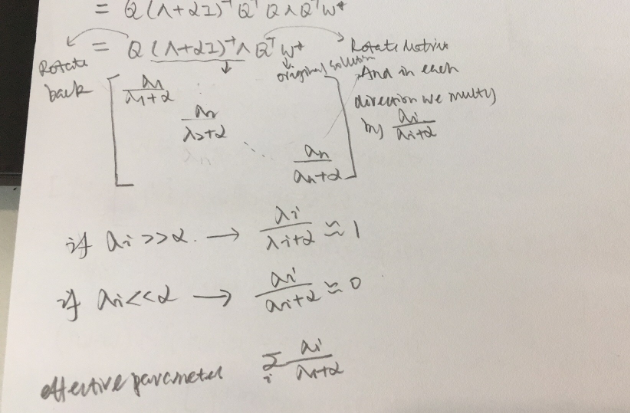
Directions along which the parameters contribute significantly to reducing the objective function are presented a small eigenvalue of the Hessian tell us that movement in this direction will not significantly increase the gradient
effective number of parameters defined to be
γ = ∑ i λ i λ i + α \gamma=\sum\limits_i \frac{\lambda_i}{\lambda_i+\alpha} γ=i∑λi+αλi.
As α \alpha α is increased, the effective number of parameters decreases.
Dataset Augmentation
The best way to make a machine learning model generalize better is to train it on more data.
The amount of data we have is limited.
Create fake data and add it to the training set.
Not applicable to all tasks.
For example, it is difficult to generate new fake data for a density estimation task unless we have already solved the density estimation problem.
Operations like translating the training images a few pixels in each direction can often greatly improve generalization.
One way to improve the robustness of neural networks is simply to train them with random noise applied to their inputs.
This same approach also works when the noise is applied to the hidden units, which can be seen as doing dataset augmentation at multiple levels of abstraction.
Noise injection
Two ways that noise can be used as part of a regularization strategy.
Adding noise to the input.
This can be interpreted simply as form of dataset augmentation.
Can also interpret it as being equivalent to more traditional forms of regularization.
Adding it to the weights.
This technique has been used primarily in the context of recurrent neural networks(Jim et al., 1996, Graves, 2011a).
This can be interpreted as a stochastic implementation of a Bayesian interpretation over the weights.
Manifold Tangent Classifier
It is assumed that we are trying to classify examples and that examples on the same manifold share the same category.
The classifier should be invariant to the local factors of variation that correspond to movement on the manifold.
Use an nearest-neighbor distance between points x 1 x_1 x1 and x 2 x_2 x2 the distance between the manifolds M 1 M_1 M1 and M 2 M_2 M2 to which they respectively belong.
Approximate M 1 M_1 M1 by its tangent plane at x i x_i xi and measure the distance between the two tangent.
Train a neural net classifier with an extra penalty to make the output f ( x ) f(x) f(x) of the neural net locally invariant to known factors of variation(Tangent Prop algorithm, Simard et al. 1992)















 1267
1267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









