






一:SQL 基础语言学习
1.1Select
(1) From:
准备表格(告诉SQL需要的数据在哪个数据库)
查询语句(不更改数据库原表格,复制完全一样表格用于查询处理),先执行from后执行select

(2)Select
在复制后的表格取出数据
书写顺序不等于运行顺序,查询注重的是结果(最终要查询的字段先写前面,后面是实现字段查询的方式)。先想好怎么查询,书写仍是先写select
![]()
1.2 Distinct
去重检索,SQL是单向执行语言,从头读到尾

1.3 where(自定义筛选)
(1)实例
(2) SQL的准备过程
先准备表格后查询字段:通过from和join准备表格后,先筛选后计算,在准备好的表格复制粘贴或计算字段(order是对准备好的表格进行排序,Limit是对准备好的表格进行限制)
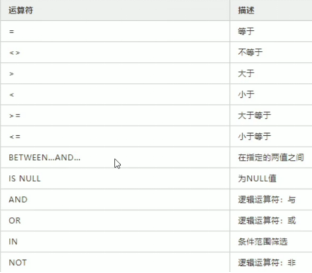
(3)运算符
between包含区间两端值,null:数据库某个数值为空
1.4 where in
in
(1)定义
(2)in可以实现多选,not in 可以反选
![]()
1.5 Like
like使用%通配符模糊匹配数据
(1) 语法

(2)定义
通配符用来匹配值的一部分,跟在Like关键字之后过滤数据
%代表任意字符出现的任意次数

1.6 order by
Order by指定字段做为表格排序依据
SQL默认升序,order by可以指定多个字段做为升序依据

1.7 Limit
(1)定义
限制查询的行数
留下指定行数据或指定位置的数据
(2)使用
筛选固定名次的数据
数据库中存在大量数据时不查看所有数据,只查看指定前几行的数据,不消耗过度资源

(3) limit n,b
表示从n开始后一行取b行数据

二:SQL 常用函数学习
2.1 聚合
对整个表计算
(1)不需要聚合运算时对原表格进行赋值后处理,需要时数据库在原有表格基础
上创建
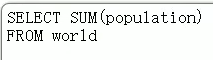
(2) 对word表进行引用,相当于将population放入值字段,做求和运算
2.2 group by
(1)作用:对字段进行去重合并
计算的功能放在select里,如果要进行聚合运算,sql会创建一个新的表格,选什么字段就会对什么字段进行去重合并
(2)select字段必须与group by字段相统一,因为select是基于group by的结果查询的,select字段是小于等于group by字段的
(3)语法

2.3 having
(1)定义
having类似于where,但只能基于group by非聚合字段和聚合字段进行搜寻筛选
(2)语法
where是对原表进行筛选

(3) sql 优化(一点点的效率优化对企业来说可以节省很大计算资源)
批评企业生成效率其中之一的方式就是每个业务价值对应花的it成本


三:子查询
没办法使用SQL一次性将现有数据查询的时候,需要子查询。基于先一步的结果再进行查询
好比不知道火车站转乘,不是不知道在哪个站换乘,而是不知道在哪个站转乘最好。所以如果感觉一次查询无法完成,就使用子查询
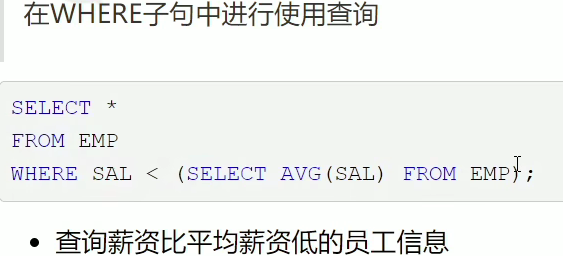
3.1 where子查询
3.2 Having子查询

3.3 From子查询
出现情况:
非聚合表与聚合表进行连接时,先做聚合运算查询,再跟非聚合运算表做连接
简化逻辑:字段计算逻辑特别复杂时
3.4 Select子查询

子查询复杂:对数据库和表格不熟悉,不知道每个数据库的字段有哪些,不知道从哪个表格里取哪个字段,对最后结果很模糊
四:SQL编程的10条建议
使用标准的SQL关键字:使用标准的SQL关键字,比如 SELECT, INSERT, UPDATE, DELETE, WHERE 等。
遵循语法规则:SQL语句需要遵循一定的语法规则,比如 SELECT 语句后面应该跟了表名和要查询的列名。
使用合适的数据类型:在创建表格或添加数据时,应选择正确和适合的数据类型。
注释的使用:注释可以帮助他人或者自己理解代码,包括在单行中使用 "--" 或者在多行中使用 "/* ... */" 。
使用适当的排序:使用 ORDER BY 语句以对结果进行适当的排序。
区分大小写:虽然大部分SQL平台都是不区分大小写的,但是要注意某些平台可能仍然做大小写区分。
合理使用索引:使用索引可以加快查询速度,但要注意不要过度使用,因为索引会占用磁盘空间,并且在插入、删除和更新操作时可能使性能下降。
防止SQL注入:在编写可执行参数的SQL语句时,确保参数已正确转义。
利用子查询:子查询可以在一个SQL语句中执行另一个SQL语句,帮助解决复杂的查询问题。
适当使用表别名:为表设置适当的表别名,不仅可以减少SQL语句的复杂度,也能尽量避免出错,让SQL语句更加的直观、易理解。
以上就是本次分享的内容,感谢大家支持。您的关注、点赞、收藏是我创作的动力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









