







kafka 的重要概念
- Kafka 属于分布式的消息引擎系统,它的主要功能是提供一套完备的消息发布与订阅解决方案。
- 在 Kafka 中,发布订阅的对象是主题(Topic),可以为每个业务、每个应用甚至是每类数据都创建专属的主题。
- 向主题发布消息的客户端应用程序称为生产者(Producer),生产者程序通常持续不断地向一个或多个主题发送消息,而订阅这些主题消息的客户端应用程序就被称为消费者(Consumer)。和生产者类似,消费者也能够同时订阅多个主题的消息。
- 生产者和消费者统称为客户端(Clients)。可以同时运行多个生产者和消费者实例,这些实例会不断地向Kafka集群中的多个主题生产和消费消息。
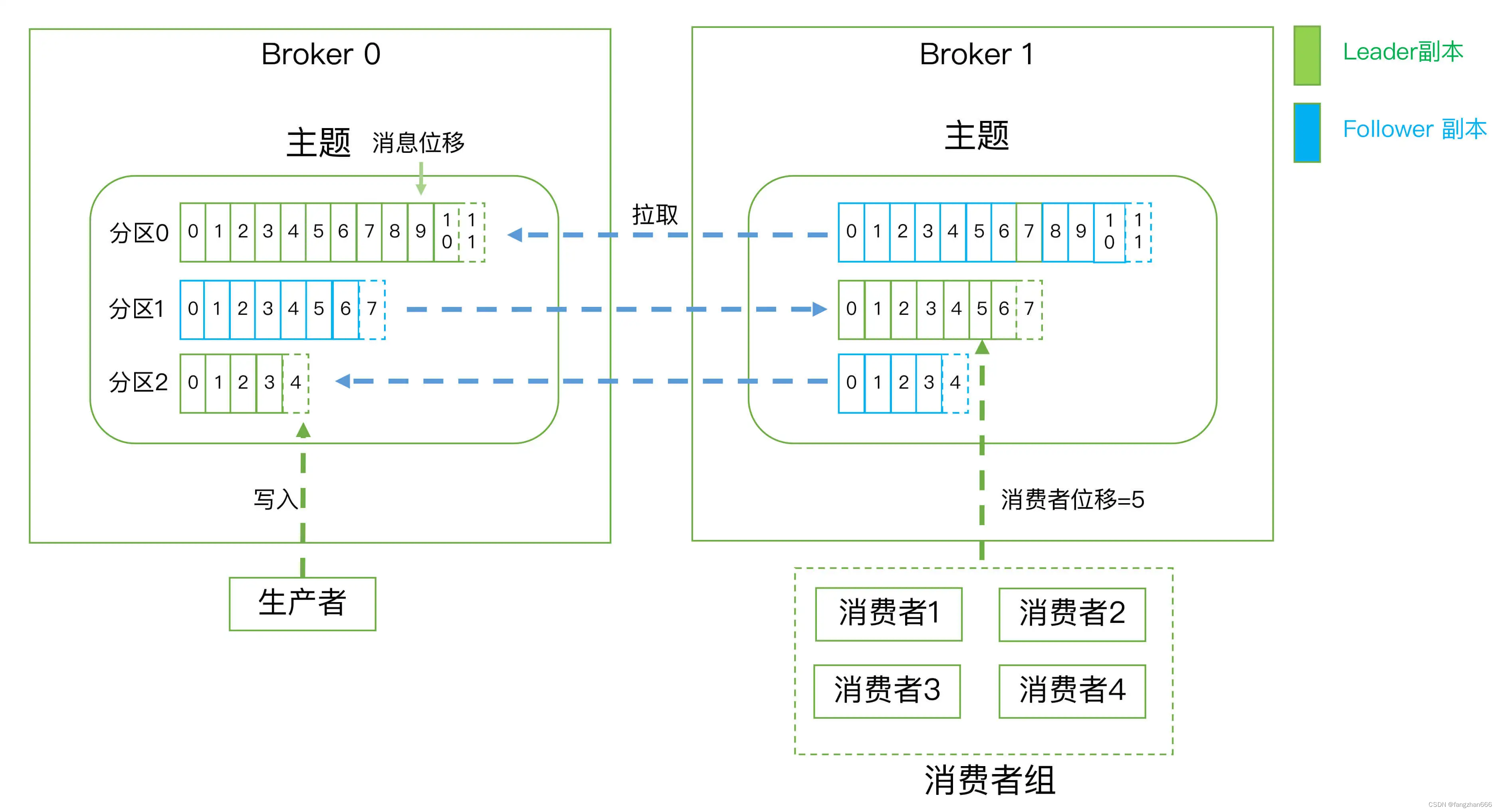
- Kafka 的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成,Broker 负责接收和处理客户端发送过来的请求,以及对消息进行持久化。
- 虽然多个 Broker 进程能够运行在同一台机器上,但更常见的做法是将不同的 Broker 分散运行在不同的机器上。
- 这样如果集群中某一台机器宕机,即使在它上面运行的所有 Broker 进程都挂掉了,其他机器上的 Broker 也依然能够对外提供服务。这其实就是 Kafka 提供高可用的手段之一。
- 实现高可用的另一个手段就是备份机制(Replication)。
- 备份就是把相同的数据拷贝到多台机器上,而这些相同的数据拷贝在 Kafka 中被称为副本(Replica)。
- Kafka 定义了两类副本:领导者副本(Leader Replica)和追随者副本(Follower Replica)。前者对外提供服务,这里的对外指的是与客户端程序进行交互;而后者只是被动地追随领导者副本而已,不能与外界进行交互。
- 副本的工作机制:生产者总是向领导者副本写消息;而消费者总是从领导者副本读消息。至于追随者副本,它只向领导者副本发送请求,请求领导者把最新生产的消息发给它,这样它能保持与领导者的同步。
- 分区机制(Partitioning)。
- Kafka 中的分区机制指的是将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。
- 生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区 0 中,要么在分区 1 中。
- 副本是在分区这个层级定义的。
- 每个分区下可以配置若干个副本,其中只能有1个领导者副本和 N-1 个追随者副本。
- 生产者向分区写入消息,每条消息在分区中的位置信息由一个叫位移(Offset)的数据来表征。分区位移总是从 0 开始,假设一个生产者向一个空分区写入了 10 条消息,那么这 10 条消息的位移依次是 0、1、2、…、9。
- Kafka 的三层消息架构:
- 第一层是主题层,每个主题可以配置 M 个分区,而每个分区又可以配置 N 个副本。
- 第二层是分区层,每个分区的 N 个副本中只能有一个充当领导者角色,对外提供服务;其他 N-1 个副本是追随者副本,只是提供数据冗余之用。
- 第三层是消息层,分区中包含若干条消息,每条消息的位移从 0 开始,依次递增。
- 最后,客户端程序只能与分区的领导者副本进行交互。
- Kafka Broker 持久化数据:
- Kafka 使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件。
- 因为只能追加写入,故避免了缓慢的随机 I/O 操作,改为性能较好的顺序 I/O 写操作,这也是实现 Kafka 高吞吐量特性的一个重要手段。
- 不过如果不停地向一个日志写入消息,最终也会耗尽所有的磁盘空间,因此 Kafka 必然要定期地删除消息以回收磁盘。
- 简单来说就是通过日志段(Log Segment)机制。
- 在Kafka底层,一个日志又近一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,Kafka 会自动切分出一个新的日志段,并将老的日志段封存起来。
- Kafka 在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的。
- 消费者
- 点对点模型(Peer to Peer,P2P)的点对点指的是同一条消息只能被下游的一个消费者消费,其他消费者则不能染指。
- 在 Kafka 中实现这种 P2P 模型的方法就是引入了消费者组(Consumer Group)。
- 所谓的消费者组,指的是多个消费者实例共同组成一个组来消费一组主题。
- 这组主题中的每个分区都只会被组内的一个消费者实例消费,其他消费者实例不能消费它。
- 引入消费者组主要是为了提升消费者端的吞吐量。
- 多个消费者实例同时消费,加速整个消费端的吞吐量(TPS)。
- 消费者实例可以是运行消费者应用的进程,也可以是一个线程,它们都称为一个消费者实例(Consumer Instance)。
- 消费者组里面的所有消费者实例不仅“瓜分”订阅主题的数据,而且更酷的是它们还能彼此协助。
- 假设组内某个实例挂掉了,Kafka 能够自动检测到,然后把这个 Failed 实例之前负责的分区转移给其他活着的消费者。
- 这个过程就是 Kafka 中大名鼎鼎的“重平衡”(Rebalance)。
- 每个消费者在消费消息的过程中必然需要有个字段记录它当前消费到了分区的哪个位置上,这个字段就是消费者位移(Consumer Offset)。消费者位移可能是随时变化的,它是消费者消费进度的指示器。















 199
199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









