









环境
虚拟主机:centos7两台
vmware 11.0
jdk-8u45-linux-x64
hadoop-2.7.0
* 一、单机模式的Hadoop分布式环境安装和运行*
所需环境:
两台centos7.0 64位虚拟机
hadoop-2.7.0
jdk-8u45-linux-x64通过ssh将Hadoop和javaJDK上传入虚拟机
分别进行解压并更改权限(代码序列如下)
tar –vxzf hadoop-2.7.0.tar.gztar -vxzf jdk-8u45-linux-x64.tar.gzchmod -R 777 hadoop-2.7.0/ jdk1.8.0_45/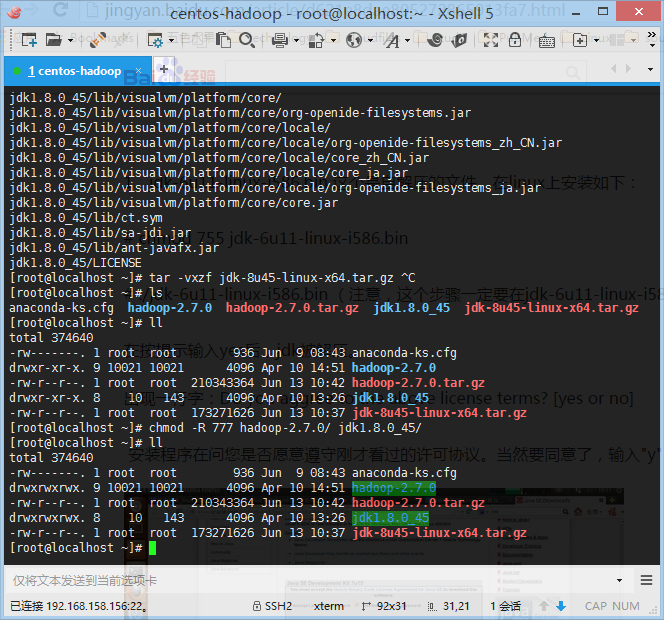
配置环境变量
jdk 和 Hadoop已经解压好的包路径为/root/编辑系统环境变量
vim /etc/profile并在文件最后添加:
export JAVA_HOME=/root/jdk1.8.0_45
export PATH=$JAVA_HOME/bin:$PATH
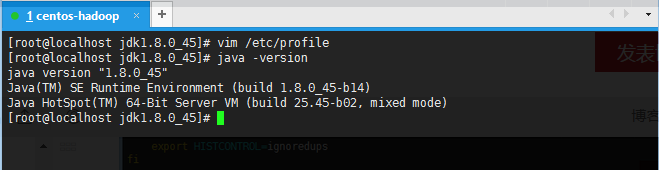
- 执行命令 . /etc/profile
注意:这里 . 与 / 之间存在一个空格
若在当前目录在/etc/,那么可以直接执行./profile,这里 . 与 /没有空格 - 输入java -version 进行测试
- - 修改hosts,将master ip地址编辑到hosts文件中
vim /etc/hosts
- 修改hostname
vim /etc/hostname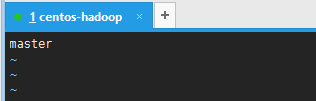
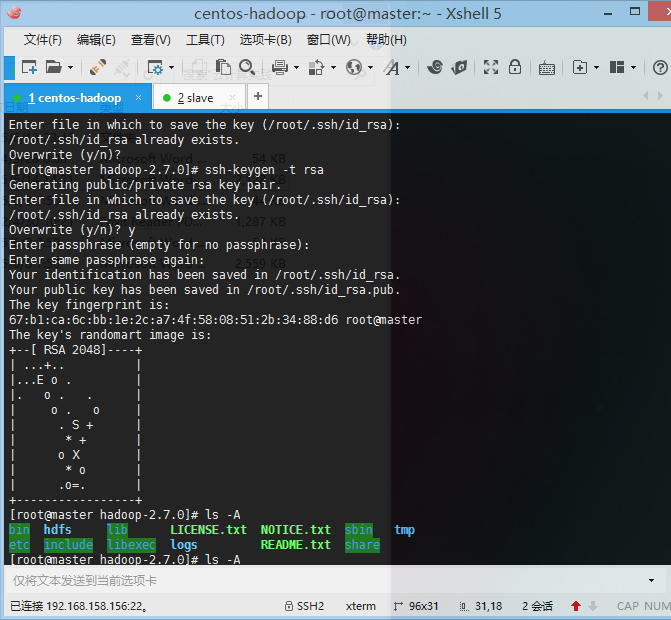
- 创建ssh公钥和私钥
ssh-keygen –t rsa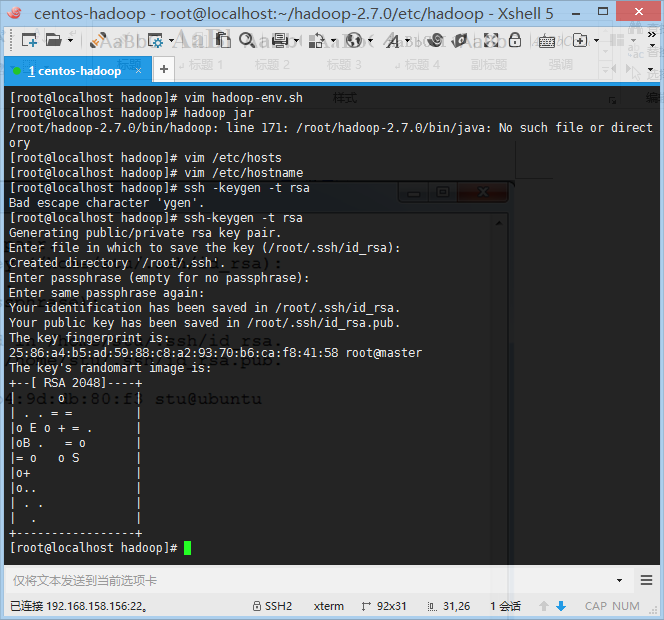
- 将公钥导入认证文件
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys- 将以下两句添加进/etc/profile文件中
export HADOOP_HOME=/root/hadoop-2.7.0
export PATH=$HADOOP_HOME/bin:$PATH
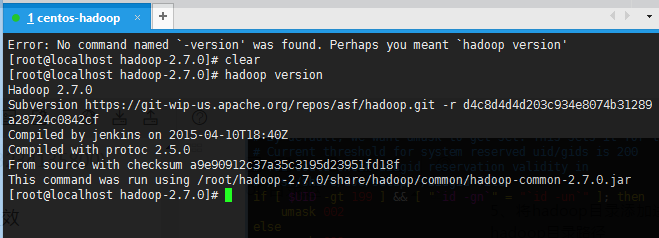
执行命令 . /etc/profile 使得hadoop环境变量生效
执行 hadoop version 测试环境是否已经成功搭建
- 测试运行情况
hadoop jar /root/hadoop-2.7.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar pi 4 1000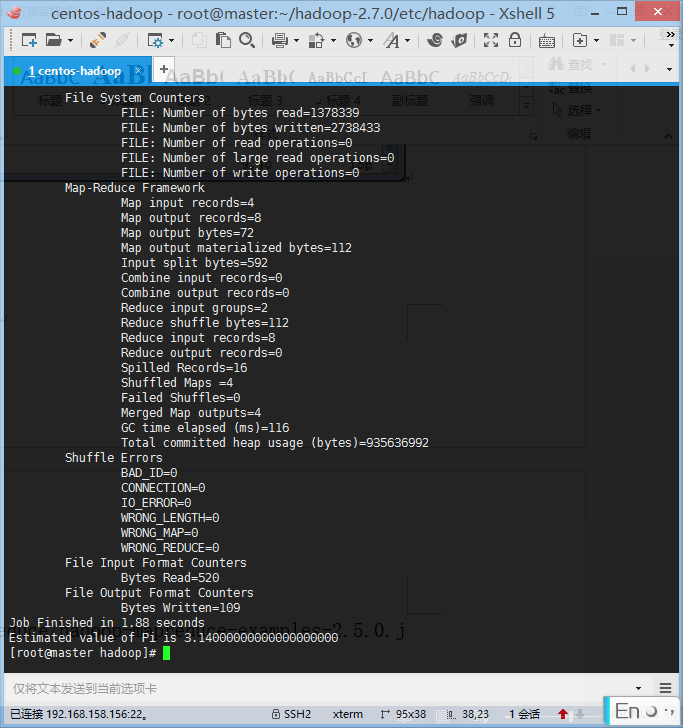
二 、完全分布模式的Hadoop分布式环境安装和运行
两台虚拟机地址:
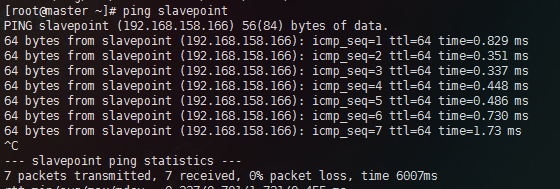
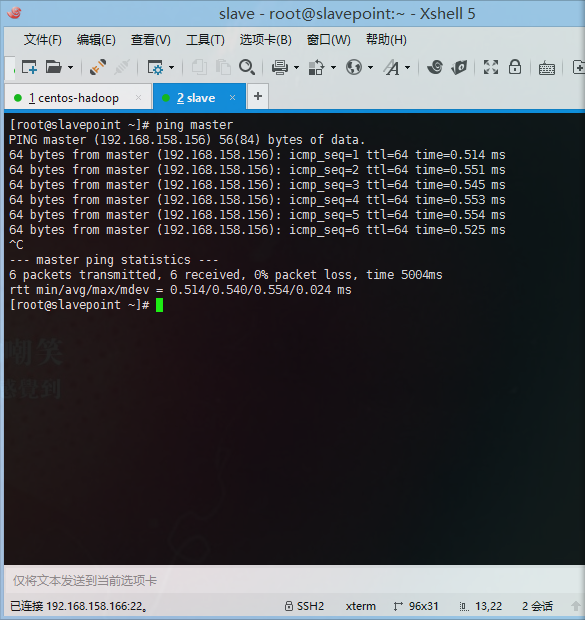
Master:192.168.158.156
Slavepoint:192.168.158.166实验环境
两台centos7.0 64位虚拟机
hadoop-2.7.0
jdk-8u45-linux-x64实验步骤
重新安装一台虚拟机slavepoint配置slavepoint的ip以及hosts文件,hostname文件
vim /etc/hostname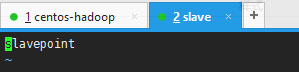
vim /etc/hosts
- 配置master主机hostname,hosts文件
vim /etc/hostname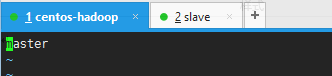
vim /etc/hosts
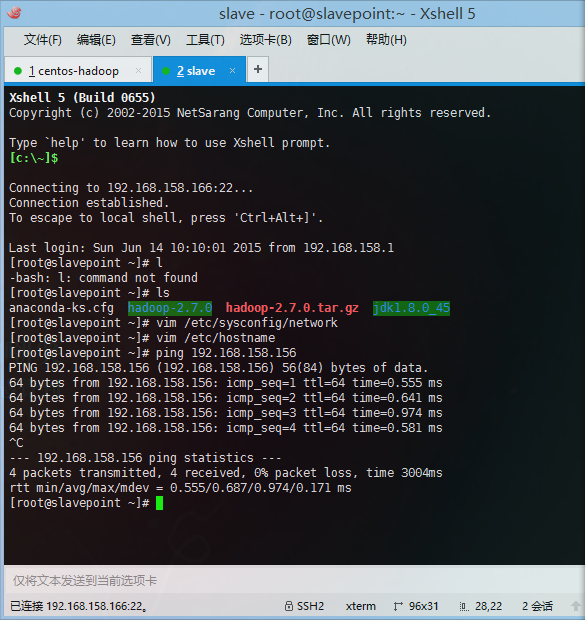
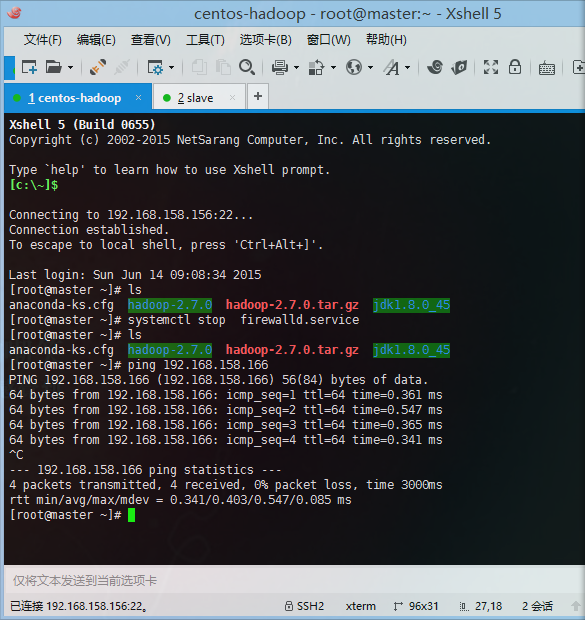
- 两台主机进行主机名ping操作
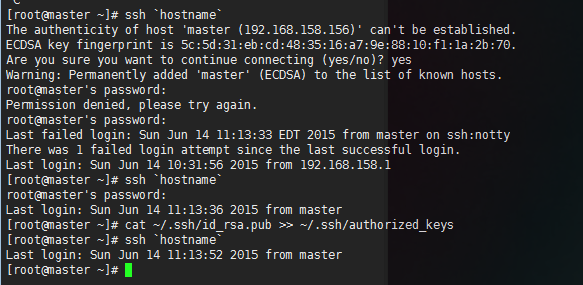
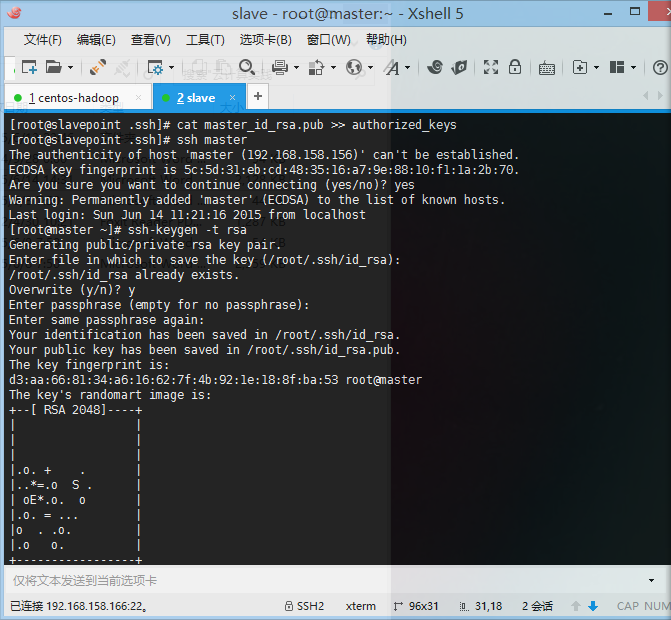
- 4、 配置无密码登录:ssh-keygen –t rsa
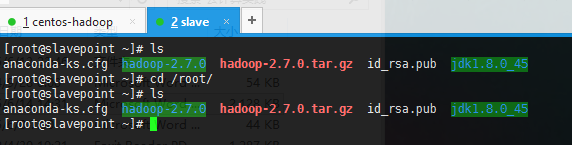
将秘钥导入到slave主机
scp ~/.ssh/id_rsa.pub root@192.168.158.166:~/Slave主机:
将秘钥导入到认证文件

进行ssh master登录

Slave主机生成秘钥
cat id_rsa.pub >> authorized_keys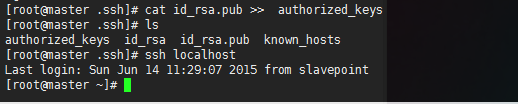
将秘钥导入值master主机
scp id_rsa.pub root@master:~/
进入master主机将密钥导入认证文件
mv id_rsa.pub salve_id_rsa.pub
cp salve_id_rsa.pub .ssh/
cd .ssh/
cat salve_id_rsa.pub >> authorized_keys
在slavepint主机执行命令 ssh master

- 在hadoop根下建立hadoop工作临时文件夹
mkdir tmp hdfs
mkdir hdfs/name hdfs/data
- 配置namenode,修改core-site.xml文件 vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/hadoop-2.7.0/tmp</value>
</property>
</configuration>
- 修改hdfs-site.xml vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:/root/hadoop-2.7.0/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:/root/hadoop-2.7.0/hdfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
- 修改yarn-site.xml 文件 vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
- 将配置好的hadoop和jdk以及/etc/profile导入到salvepoint主机中,并在slavepoint主机中执行. /etc/profile使得环境变量生效
scp /root/Hadoop-2.7.0 root@slavepoint:/root/
scp /root/jdk1.8.0_45 root@slavepoint:/root/
scp /etc/profile root@slavepoint:/etc/
. /etc/profile (在slavepoint主机中执行)
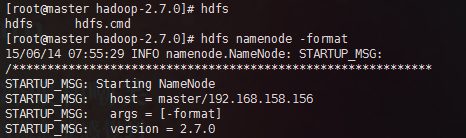
- 文件系统格式化:hdfs namenode –format,并开启hadoop
. /root/Hadoop-2.7.0/sbin/start-all.sh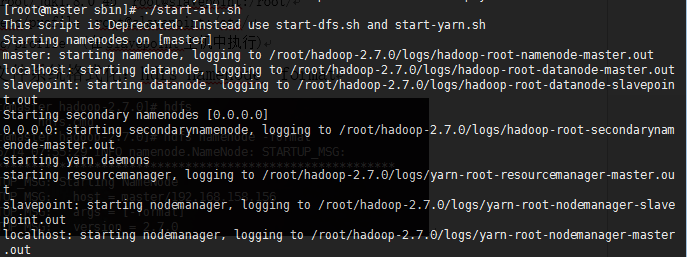
- 在windows浏览器中输入http://192.168.158.156:50070/进行测试
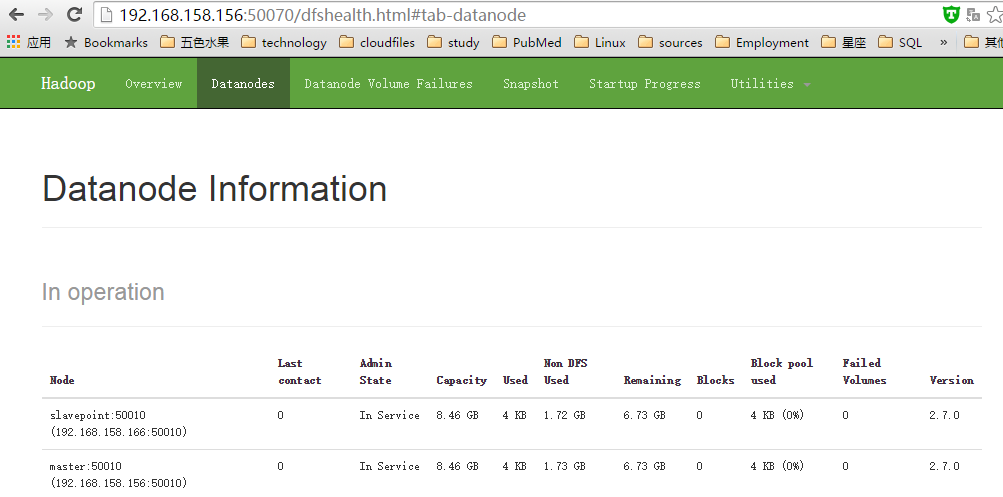















 493
493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









