







存储过程性能瓶颈分析–方法




存储过程性能瓶颈分析–案例
思路




具体过程
- 创建必要过程包:
[oracle@oracle11g ~]$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.4.0 Production on Tue Mar 30 04:56:42 2021
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> desc dbms_profiler
FUNCTION FLUSH_DATA RETURNS BINARY_INTEGER
PROCEDURE FLUSH_DATA
PROCEDURE GET_VERSION
Argument Name Type In/Out Default?
------------------------------ ----------------------- ------ --------
MAJOR BINARY_INTEGER OUT
MINOR BINARY_INTEGER OUT
FUNCTION INTERNAL_VERSION_CHECK RETURNS BINARY_INTEGER
FUNCTION PAUSE_PROFILER RETURNS BINARY_INTEGER
PROCEDURE PAUSE_PROFILER
FUNCTION RESUME_PROFILER RETURNS BINARY_INTEGER
PROCEDURE RESUME_PROFILER
PROCEDURE ROLLUP_RUN
Argument Name Type In/Out Default?
------------------------------ ----------------------- ------ --------
RUN_NUMBER NUMBER IN
PROCEDURE ROLLUP_UNIT
Argument Name Type In/Out Default?
------------------------------ ----------------------- ------ --------
RUN_NUMBER NUMBER IN
UNIT NUMBER IN
FUNCTION START_PROFILER RETURNS BINARY_INTEGER
Argument Name Type In/Out Default?
------------------------------ ----------------------- ------ --------
RUN_COMMENT VARCHAR2 IN DEFAULT
RUN_COMMENT1 VARCHAR2 IN DEFAULT
RUN_NUMBER BINARY_INTEGER OUT
PROCEDURE START_PROFILER
Argument Name Type In/Out Default?
------------------------------ ----------------------- ------ --------
RUN_COMMENT VARCHAR2 IN DEFAULT
RUN_COMMENT1 VARCHAR2 IN DEFAULT
RUN_NUMBER BINARY_INTEGER OUT
FUNCTION START_PROFILER RETURNS BINARY_INTEGER
Argument Name Type In/Out Default?
------------------------------ ----------------------- ------ --------
RUN_COMMENT VARCHAR2 IN DEFAULT
RUN_COMMENT1 VARCHAR2 IN DEFAULT
PROCEDURE START_PROFILER
Argument Name Type In/Out Default?
------------------------------ ----------------------- ------ --------
RUN_COMMENT VARCHAR2 IN DEFAULT
RUN_COMMENT1 VARCHAR2 IN DEFAULT
FUNCTION STOP_PROFILER RETURNS BINARY_INTEGER
PROCEDURE STOP_PROFILER
可见,oracle 11204默认自带dbms_profiler包,所以无需创建
创建跟踪表,运行账户创建,本例拿scott用户来执行,所以在scott用户下执行:
SQL> declare
2 v_run_number integer;
3 begin
4 sys.dbms_profiler.start_profiler(run_number => v_run_number);
5 dbms_output.put_line(‘run_number:’ || v_run_number);
6 sp_test2;
7 sys.dbms_profiler.stop_profiler;
8 end;
9 /
declare
*
ERROR at line 1:
ORA-06528: Error executing PL/SQL profiler
ORA-06512: at “SYS.DBMS_PROFILER”, line 123
ORA-06512: at line 4
SQL> @?/rdbms/admin/proftab.sql
drop table plsql_profiler_data cascade constraints
*
ERROR at line 1:
ORA-00942: table or view does not exist
drop table plsql_profiler_units cascade constraints
*
ERROR at line 1:
ORA-00942: table or view does not exist
drop table plsql_profiler_runs cascade constraints
*
ERROR at line 1:
ORA-00942: table or view does not exist
drop sequence plsql_profiler_runnumber
*
ERROR at line 1:
ORA-02289: sequence does not exist
Table created.
Comment created.
Table created.
Comment created.
Table created.
Comment created.
Sequence created.
- 创建测试存储过程
SQL> conn scott/tiger
Connected.
SQL> create table t1(id int);
Table created.
SQL> create or replace procedure scott.sp_test as
2 begin
3 for i in 1..618000 loop
4 insert into t1 values (i);
5 end loop;
6 commit;
7 end;
8 /
Procedure created.
SQL> create or replace procedure scott.sp_test2 as
2 begin
3 for i in 1..618000 loop
4 insert into t1 values (i);
5 commit;
6 end loop;
7 end;
8 /
Procedure created.
- dbms_profiler的运行
3.1以 dbms_profiler 方式运行 sp_test 和 sp_test2 (分别运行,合并运行,均可)
SQL> set serveroutput on
SQL> declare
2 v_run_number integer;
3 begin
4 sys.dbms_profiler.start_profiler(run_number => v_run_number);
5 dbms_output.put_line('run_number:' || v_run_number);
6 sp_test2;
7 sys.dbms_profiler.stop_profiler;
8 end;
9 /
run_number:1
PL/SQL procedure successfully completed.
SQL> declare
2 v_run_number integer;
3 begin
4 sys.dbms_profiler.start_profiler(run_number => v_run_number);
5 dbms_output.put_line('run_number:' || v_run_number);
6 sp_test;
7 sys.dbms_profiler.stop_profiler;
8 end;
9 /
run_number:2
PL/SQL procedure successfully completed.
3.2 此处sp_test的run_number为2,sp_test2的run_number为1。
- DBMS_PROFILER的结果查询 SQL
set linesize 190
column text format a100 wrap
column total_time format 99999.9
column min_time format 99999.9
column max_time format 99999.9
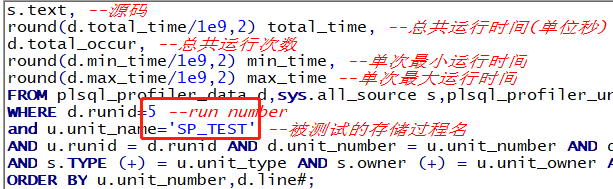
SELECT d.line#, --源码行号
s.text, --源码
round(d.total_time/1e9,2) total_time, --总共运行时间(单位秒)
d.total_occur, --总共运行次数
round(d.min_time/1e9,2) min_time, --单次最小运行时间
round(d.max_time/1e9,2) max_time --单次最大运行时间
FROM plsql_profiler_data d,sys.all_source s,plsql_profiler_units u
WHERE d.runid=&run_number --run number
and u.unit_name=’&spname’ --被测试的存储过程名
AND u.runid = d.runid AND d.unit_number = u.unit_number AND d.total_occur <> 0
AND s.TYPE (+) = u.unit_type AND s.owner (+) = u.unit_owner AND s.name(+) = u.unit_name AND d.line# = NVL(s.line,d.line#)
ORDER BY u.unit_number,d.line#;
- DBMS_PROFILER的查询结果:
SQL> set linesize 190
SQL> column text format a100 wrap
SQL> column total_time format 99999.9
SQL> column min_time format 99999.9
SQL> column max_time format 99999.9
SQL> SELECT d.line#, --源码行号
2 s.text, --源码
3 round(d.total_time/1e9,2) total_time, --总共运行时间(单位秒)
4 d.total_occur, --总共运行次数
5 round(d.min_time/1e9,2) min_time, --单次最小运行时间
6 round(d.max_time/1e9,2) max_time --单次最大运行时间
7 FROM plsql_profiler_data d,sys.all_source s,plsql_profiler_units u
8 WHERE d.runid=1 --run number
9 and u.unit_name='SP_TEST2' --被测试的存储过程名
10 AND u.runid = d.runid AND d.unit_number = u.unit_number AND d.total_occur <> 0
11 AND s.TYPE (+) = u.unit_type AND s.owner (+) = u.unit_owner AND s.name(+) = u.unit_name AND d.line# = NVL(s.line,d.line#)
12 ORDER BY u.unit_number,d.line#;
LINE# TEXT TOTAL_TIME TOTAL_OCCUR MIN_TIME MAX_TIME
---------- ---------------------------------------------------------------------------------------------------- ---------- ----------- -------- --------
3 for i in 1..618000 loop .1 618001 .0 .0
4 insert into t1 values (i); 18.2 618000 .0 .6
5 commit; 62.0 618000 .0 .0
7 end; .0 1 .0 .0
SQL> SELECT d.line#, --源码行号
2 s.text, --源码
3 round(d.total_time/1e9,2) total_time, --总共运行时间(单位秒)
4 d.total_occur, --总共运行次数
5 round(d.min_time/1e9,2) min_time, --单次最小运行时间
6 round(d.max_time/1e9,2) max_time --单次最大运行时间
7 FROM plsql_profiler_data d,sys.all_source s,plsql_profiler_units u
8 WHERE d.runid=2 --run number
9 and u.unit_name='SP_TEST' --被测试的存储过程名
10 AND u.runid = d.runid AND d.unit_number = u.unit_number AND d.total_occur <> 0
11 AND s.TYPE (+) = u.unit_type AND s.owner (+) = u.unit_owner AND s.name(+) = u.unit_name AND d.line# = NVL(s.line,d.line#)
12 ORDER BY u.unit_number,d.line#;
LINE# TEXT TOTAL_TIME TOTAL_OCCUR MIN_TIME MAX_TIME
---------- ---------------------------------------------------------------------------------------------------- ---------- ----------- -------- --------
3 for i in 1..618000 loop .0 618001 .0 .0
4 insert into t1 values (i); 7.3 618000 .0 1.7
6 commit; .0 1 .0 .0
7 end; .0 1 .0 .0


- 也可以合并执行:
SQL> declare
2 v_run_number integer;
3 begin
4 sys.dbms_profiler.start_profiler(run_number => v_run_number);
5 dbms_output.put_line('run_number:' || v_run_number);
6 sp_test;
7 sp_test2;
8 sys.dbms_profiler.stop_profiler;
9 end;
10 /
run_number:5
PL/SQL procedure successfully completed.

run_number相同,拿存储过程名区分而已。
- 结论
•通过 DBMS_PROFILER ,可以清晰了解到,每一行有效代码的运行所花费的时间及运行的次数
•通过对 total_time 的倒序排列,容易知晓哪些代码片段最耗时间,从而可以有的放矢的筛查出具体有哪些片段有优化空间,再进行相应的优化。
•在本案例中,我们可以很容易得出如下结论:
SP_TEST2将 commit 放在循环中,大大降低了数据入库速度
SP_TEST将 commit 放在循环外,有效提升了数据入库速度
•相比自己在存储过程代码中埋点的方式,通过 DBMS_PROFILER ,不仅可以减少无谓的代码,而且粒度非常细致,并且这种方式通用性很强
通过 awr 分析与存储过程有关的 Top SQL
- 每次commit




被session_id=11的会话所阻塞,查看sid=11的信息:

是个后台进程

等待事件是log file paralle write

是后台进程lgwr
具体见附件:每次commit.csv ,lgwr commit每次.csv
生成ash报告查看,如果现在知道了等待事件,现在想知道等待事件对应的具体sql是什么?那么就可以适用ASH报告。ASH报告是等待事件与SQL的完美结合。:
SQL> @?/rdbms/admin/ashrpt
。。。。。
Enter value for begin_time: 04/02/21 17:17:18
Report begin time specified: 04/02/21 17:17:18
Enter duration in minutes starting from begin time:
Defaults to SYSDATE - begin_time
Press Enter to analyze till current time
Enter value for duration: 2
Report duration specified: 2
。。。。。


具体见附件:ashrpt_1_0402_1719.html , awrrpt_1_4_5.html
执行的pl/sql存储过程名称,和具体的sql语句,都会出现在awr报告中。所以可以通过 awr 分析与存储过程有关的 Top SQL。
ASH查看顺序:

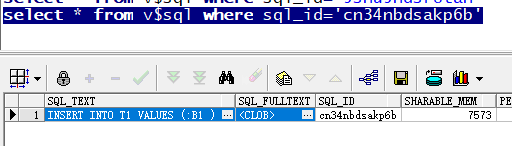
先看系统的等待事件,总体把控,那个等待事件占用的db time高。然后往下看,就可以看到,造成这些等待事件的具体SQL是什么?

明显的就可以看到系统里面这2条sql造成了等待。sqlid为cn34nbdsakp6b 的为存过里面包含的具体sql语句。5snu5hdsr8tah 为存储过程,但是sql text在这里没有显示出来。
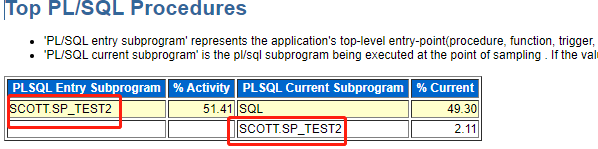
这里可以看出pl/sql块的具体等待。系统就是因为执行了scott.sp_test2而造成了等待,而sp_test2分为2部分,一部分是具体的SQL语句,占49.3%,另一部分就是pl/sql的控制代码部分,占比很小。

session部分,与前面的sid,serial#对应,都是33,35的会话最活跃,占比50%。11,1为lgwr后台进程,占比44%。
结论:可以通过 awr/ash 分析与存储过程有关的 Top SQL。
- 一次commit批处理





具体内容见附件:一次commit.csv
ashrpt_1_0403_2108.html awrrpt_1_35_36.html awrsqlrpt_1_35_36_2.html awrsqlrpt_1_35_36.html
结论:可以通过 awr/ash 分析与存储过程有关的 Top SQL。















 864
864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









