







python之公共基础
一、配置开发环境
目前我们使用的 Python 3.7.x 的版本是在 2018 年发布的,Python 的版本号分为三段,形如 A.B.C。其中 A 表示大版本号,一般当整体重写,或出现不向后兼容的改变时,增加 A;B 表示功能更新,出现新功能时增加 B;C 表示小的改动(如修复了某个 Bug),只要有修改就增加 C。
1.官网下载 Python
https://www.python.org/downloads/windows/
2.下载 Python 3.7.8
Download Windows x86-64 executable installer
3.安装过程中注意勾选添加 python 到 path

4.打开命令行
Python 3.7.8 (tags/v3.7.8:4b47a5b6ba, Jun 28 2020, 08:53:46) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
在 python 命令行输入如下即可打印字符串。
>>> print ("Hello, Python!")
二、hello world
计算机的硬件系统通常由五大部件构成,包括:运算器、控制器、存储器、输入设备和输出设备。其中,运算器和控制器放在一起就是我们通常所说的中央处理器,它的功能是执行各种运算和控制指令以及处理计算机软件中的数据。我们通常所说的程序实际上就是指令的集合,我们程序就是将一系列的指令按照某种方式组织到一起,然后通过这些指令去控制计算机做我们想让它做的事情。在记事本中编写如下指令,通过 python 命令执行里面的指令。
print('hello','哈哈','abc')
print(123)
print('bcd')
a = 20
print(a)
#如上就是hello world 的全部代码
在脚本的目录打开 cmd 命令行,输入 python test.py 命令执行,也可以简写为 py test.py 运行脚本。
注意:与 java 不同 python 是一种解释型语言,不会在执行前对代码进行编译,而是在执行的同时一边执行一边编译。
Python 中的注释以 # 开头。在 # 之后到行末的所有字符都是注释的一部分,Python 解释器会忽略它们。
三、变量和类型
在程序设计中,变量是一种存储数据的载体。计算机中的变量是实际存在的数据或者说是存储器中存储数据的一块内存空间,变量的值可以被读取和修改,这是所有计算和控制的基础。计算机能处理的数据有很多种类型,除了数值之外还可以处理文本、图形、音频、视频等各种各样的数据,那么不同的数据就需要定义不同的存储类型。Python 中的数据类型很多,而且也允许我们自定义新的数据类型(这一点在后面会讲到),我们先介绍几种常用的数据类型。
整型(int):Python 中可以处理任意大小的整数(Python 2.x 中有 int 和 long 两种类型的整数,但这种区分对 Python 来说意义不大,因此在 Python 3.x 中整数只有 int 这一种了),而且支持二进制(如 0b100,换算成十进制是4)、八进制(如 0o100,换算成十进制是64)、十进制(100)和十六进制(0x100,换算成十进制是 256)的表示法。
浮点型(float):浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,浮点数除了数学写法(如 123.456)之外还支持科学计数法(如 1.23456e2)。
字符串型(str):字符串是以单引号或双引号括起来的任意文本,比如’hello’和"hello",字符串还有原始字符串表示法、字节字符串表示法、Unicode 字符串表示法,而且可以书写成多行的形式(用三个单引号或三个双引号开头,三个单引号或三个双引号结尾)。
布尔型(bool):布尔值只有 True、False 两种值,要么是 True,要么是 False,在 Python中,可以直接用 True、False 表示布尔值(请注意大小写),也可以通过布尔运算计算出来(例如 3 < 5 会产生布尔值 True,而 2 == 1 会产生布尔值 False)。
复数型(complex):形如 3+5j,跟数学上的复数表示一样,唯一不同的是虚部的 i 换成了 j。
数学上:将数集拓展到实数范围内,仍有些运算无法进行。比如判别式小于 0 的一元二次方程仍无解,因此将数集再次扩充,达到复数范围, 并建立了与实数轴垂直的数轴来表示复数。 规定形如 z=a+bi(a,b 均为任意实数)的数称为复数,其中 a 称为实部,b 称为虚部,i 称为虚数单位,且 i^2=i×i=-1。 当虚部等于零时,这个复数可以视为实数;当 z 的虚部不等于零时,实部等于零时,常称 z 为纯虚数。
在 python 中使用 type© 获取变量的类型。
案例:
a = 321
b = 123
print(a + b)
print(a - b)
print(a * b)
print(a / b)
print(a // b)
#取商
print(a % b)
#取余
print(a ** b)
#a 的 b 次方
案例:
a = int(input('a = '))
b = int(input('b = '))
print('%d + %d = %d' % (a, b, a + b))
print('%d - %d = %d' % (a, b, a - b))
print('%d * %d = %d' % (a, b, a * b))
print('%d / %d = %f' % (a, b, a / b))
print('%d // %d = %d' % (a, b, a // b))
print('%d %% %d = %d' % (a, b, a % b))
print('%d ** %d = %d' % (a, b, a ** b))
案例:
a = 100
b = 12.345
c = 1 + 5j
d = 'hello, world'
e = True
print(type(a))
print(type(b))
print(type(c))
print(type(d))
print(type(e))
四、Python 标识符
Python 标识符是用来标识变量,函数,类,模块或其他对象的名称。标识符是以字母 A 到 Z 开始或 a〜z 或后跟零个或多个字母下划线(_),下划线和数字(0〜9)。
Python 标识符范围内的不容许有如:@, $ 和 % 符号。Python 是一种区分大小写的编程语言。因此,Manpower 和 manpower 在 Python 中是两种不同的标识符。
下面是 Python 标识符命名的约定
- 类名称使用大写字母。所有其它标识符开始使用小写字母。
- 开头使用一个下划线的标识符表示该标识符是私有的。
- 开始以两个前导下划线的标识符表示强烈私有的标识符。
- 如果标识符使用两个下划线作为结束时,所述标识符是语言定义的特殊的名字。
不能把它们作为常量或变量或任何其他标识符名称。 所有 Python 的关键字仅包含小写字母。
and exec not as finally or assert for pass break from print class global raise continue if return def import try del in while elif is with else lambda yield except
练习:
1.编写一个程序根据华氏温度计算摄氏温度,已知 F = 1.8C + 32 其中 F 表示华氏温度,C 表示摄氏温度。
2.编写一个程序根据输入圆的半径计算计算周长和面积。
3.输入年份判断是不是闰年。
①、普通年能被4整除且不能被100整除的为闰年。(如2004年就是闰年,1901年不是闰年)
②、世纪年能被400整除的是闰年。(如2000年是闰年,1900年不是闰年) 运行时参数获取年份并判断是不是闰年。
参考代码:
题一:
f = float(input('请输入华氏温度: '))
c = (f - 32) / 1.8
print('%.1f华氏度 = %.1f摄氏度' % (f, c))
题二:
import math
radius = float(input('请输入圆的半径: '))
perimeter = 2 * math.pi * radius
area = math.pi * radius * radius
print('周长: %.2f' % perimeter)
print('面积: %.2f' % area)
题三:
year = int(input('请输入年份: '))
# 如果代码太长写成一行不便于阅读 可以使用\或()折行
is_leap = (year % 4 == 0 and year % 100 != 0 or
year % 400 == 0)
print(is_leap)
五、分支结构
迄今为止,我们写的 Python 代码都是一条一条语句顺序执行,这种代码结构通常称之为顺序结构。然而仅有顺序结构并不能解决所有的问题,比如我们设计一个游戏,游戏第一关的通关条件是玩家获得 1000 分,那么在完成本局游戏后,我们要根据玩家得到分数来决定究竟是进入第二关,还是告诉玩家“Game Over”,这里就会产生两个分支,而且这两个分支只有一个会被执行。类似的场景还有很多,我们将这种结构称之为“分支结构”或“选择结构”。
在 Python 中,要构造分支结构可以使用 if、elif 和 else 关键字。所谓关键字就是有特殊含义的单词,像 if 和 else 就是专门用于构造分支结构的关键字,很显然你不能够使用它作为变量名(事实上,用作其他的标识符也是不可以)。下面的例子中演示了如何构造一个分支结构。
案例:
username = input('请输入用户名: ')
password = input('请输入口令: ')
# 用户名是admin且密码是123456则身份验证成功否则身份验证失败
if username == 'admin' and password == '123456':
print('身份验证成功!')
else:
print('身份验证失败!')
需要说明的是和 C/C++、Java 等语言不同,Python 中没有用花括号来构造代码块而是使用了缩进的方式来表示代码的层次结构,如果if条件成立的情况下需要执行多条语句,只要保持多条语句具有相同的缩进就可以了。换句话说连续的代码如果又保持了相同的缩进那么它们属于同一个代码块,相当于是一个执行的整体。缩进可以使用任意数量的空格,但通常使用4个空格,建议大家不要使用制表键或者设置你的代码编辑工具自动将制表键变成4个空格。
当然如果要构造出更多的分支,可以使用if…elif…else…结构或者嵌套的if…else…结构,下面的代码演示了如何利用多分支结构实现分段函数求值。
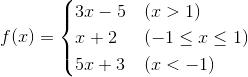
x = float(input('x = '))
if x > 1:
y = 3 * x - 5
elif x >= -1:
y = x + 2
else:
y = 5 * x + 3
print('f(%.2f) = %.2f' % (x, y))
当然根据实际开发的需要,分支结构是可以嵌套的,例如判断是否通关以后还要根据你获得的宝物或者道具的数量对你的表现给出等级(比如点亮两颗或三颗星星),那么我们就需要在if的内部构造出一个新的分支结构,同理elif和else中也可以再构造新的分支,我们称之为嵌套的分支结构,也就是说上面的代码也可以写成下面的样子。
x = float(input('x = '))
if x > 1:
y = 3 * x - 5
else:
if x >= -1:
y = x + 2
else:
y = 5 * x + 3
print('f(%.2f) = %.2f' % (x, y))
练习
1.编写一个程序完成英制单位英寸与公制单位厘米互换,已知 1 英寸等于 2.45 厘米。要求用户输入数值和转化后的单位并完成相应的转化输出。
2.编写一个程序完成百分制成绩转换为等级制成绩,如果输入的成绩在90分以上(含90分)输出A;80分-90分(不含90分)输出B;70分-80分(不含80分)输出C;60分-70分(不含70分)输出D;60分以下输出E。
3.编写一个程序要求输入三条边长并判断是否能构成三角形,如果能构成三角形就计算周长和面积。
海伦公式 公式描述:公式中 a,b,c 分别为三角形三边长,p 为半周长,S 为三角形的面积。
4.做一个加法,减法,乘法计算器方法,最后一个数字控制程序的算法。(1表示加法,2表示减法,3表示乘法,4表示除法,5表示次方)
参考代码:
题一:
value = float(input('请输入长度: '))
unit = input('请输入单位: ')
if unit == 'in' or unit == '英寸':
print('%f英寸 = %f厘米' % (value, value * 2.54))
elif unit == 'cm' or unit == '厘米':
print('%f厘米 = %f英寸' % (value, value / 2.54))
else:
print('请输入有效的单位')
题二:
score = float(input('请输入成绩: '))
if score >= 90:
grade = 'A'
elif score >= 80:
grade = 'B'
elif score >= 70:
grade = 'C'
elif score >= 60:
grade = 'D'
else:
grade = 'E'
print('对应的等级是:', grade)
题三:
a = float(input('a = '))
b = float(input('b = '))
c = float(input('c = '))
if a + b > c and a + c > b and b + c > a:
print('周长: %f' % (a + b + c))
p = (a + b + c) / 2
area = (p * (p - a) * (p - b) * (p - c)) ** 0.5
print('面积: %f' % (area))
else:
print('不能构成三角形')
题四:
a = int(input("请输入a:"))
b = int(input("请输入b:"))
order = int(input("请输入指令,1:加法,2:减法,3:乘法,4:除法,5:次方\n"))
if order == 1:
print('%d + %d =%d' % (a, b, a + b))
elif order == 2:
print('%d - %d =%d' % (a, b, a - b))
elif order == 3:
print('%d * %d =%d' % (a, b, a * b))
elif order == 4:
print('%d ** %d =%d' % (a, b, a ** b))
else:
print("参数错误")
六、循环结构
如果在程序中我们需要重复的执行某条或某些指令,比如在我们的程序中要实现每隔 1 秒中在屏幕上打印一个"hello, world"这样的字符串并持续一个小时,我们肯定不能够将打印输出这句代码写上 3600 遍,如果真的需要这样做那么编程的工作就太无聊了。因此,我们需要了解一下循环结构,有了循环结构我们就可以轻松的控制某件事或者某些事重复、重复、再重复的发生。
在 Python 中构造循环结构有两种做法,一种是 for-in 循环,一种是 while 循环。
for-in 循环
如果明确的知道循环执行的次数或者是要对一个容器进行迭代(后面会讲到),那么我们推荐使用 for-in 循环,例如下面代码中计算 1~100的和。
sum = 0
for x in range(101):
sum += x
print(sum)
需要说明的是上面代码中的 range 类型,range 可以用来产生一个不变的数值序列,而且这个序列通常都是用在循环中的,例如:
- range(101)可以产生一个 0 到 100 的整数序列。
- range(1, 100)可以产生一个 1 到 99 的整数序列。
- range(1, 100, 2)可以产生一个 1 到 99 的奇数序列,其中的 2 是步长,即数值序列的增量。
知道了这一点,我们可以用下面的代码来实现 1~100 之间的偶数求和。
sum = 0
for x in range(2, 101, 2):
sum += x
print(sum)
while循环
如果要构造不知道具体循环次数的循环结构,我们推荐使用 while 循环,while 循环通过一个能够产生或转换出 bool 值的表达式来控制循环,表达式的值为 True 循环继续,表达式的值为 False 循环结束。下面我们通过一个“猜数字”的小游戏(计算机出一个 1~100 之间的随机数,人输入自己猜的数字,计算机给出对应的提示信息,直到人猜出计算机出的数字)来看看如何使用 while 循环。
import random
#生成一个[1,100]之间的随机数
answer = random.randint(1, 100)
counter = 0
while True:
counter += 1
number = int(input('请输入: '))
if number < answer:
print('大一点')
elif number > answer:
print('小一点')
else:
print('恭喜你猜对了!')
break
print('你总共猜了%d次' % counter)
if counter > 7:
print('你的智商余额明显不足')
注意:
上面的代码中使用了 break 关键字来提前终止循环,需要注意的是 break 只能终止它所在的那个循环,这一点在使用嵌套的循环结构(下面会讲到)需要引起注意。除了 break 之外,还有另一个关键字是 continue,它可以用来放弃本次循环后续的代码直接让循环进入下一轮。
和分支结构一样,循环结构也是可以嵌套的,也就是说在循环中还可以构造循环结构。下面的例子演示了如何通过嵌套的循环来输出一个九九乘法表。
for i in range(1, 10):
for j in range(1, i + 1):
print('%d*%d=%d' % (i, j, i * j), end='\t')
print()
练习:
1.输入一个数,并判断这个数是不是素数(一个只能被 1 和本身整除的数)。
2.输入两个正整数,计算最大公约数和最小公倍数。
3.打印如下各种三角形图案。
*
* *
* * *
* * * *
* * * * *
* * * * * *
*
* *
* * *
* * * *
* * * * *
* * * * * *
*
* * *
* * * * *
* * * * * * *
* * * * * * * * *
* * * * * * * * * * *
参考代码:
题一:
from math import sqrt
num = int(input('请输入一个正整数: '))
end = int(sqrt(num))
is_prime = True
for x in range(2, end + 1):
if num % x == 0:
is_prime = False
break
if is_prime and num != 1:
print('%d是素数' % num)
else:
print('%d不是素数' % num)
题二:
x = int(input('x = '))
y = int(input('y = '))
if x > y:
x, y = y, x
for factor in range(x, 0, -1):
if x % factor == 0 and y % factor == 0:
print('%d和%d的最大公约数是%d' % (x, y, factor))
print('%d和%d的最小公倍数是%d' % (x, y, x * y // factor))
break
题三:
row = int(input('请输入行数: '))
for i in range(row):
for _ in range(i + 1):
print(' *', end='')
print()
for i in range(row):
for j in range(row):
if j < row - i - 1:
print(' ', end='')
else:
print(' *', end='')
print()
for i in range(row):
for _ in range(row - i - 1):
print(' ', end='')
for _ in range(2 * i + 1):
print(' *', end='')
print()
七、函数和模块的使用
编程大师 Martin Fowler 先生曾经说过:“代码有很多种坏味道,重复是最坏的一种!”,要写出高质量的代码首先要解决的就是重复代码的问题。对于大量重复的代码来说,我们可以将它的功能封装到一个称之为函数的功能模块中,在需要使用的地方,我们只需要调用这个函数就可以了。
在 Python 中可以使用 def 关键字来定义函数,和变量一样每个函数也有一个响亮的名字,而且命名规则跟变量的命名规则是一致的。在函数名后面的圆括号中可以放置传递给函数的参数,这一点和数学上的函数非常相似,程序中函数的参数就相当于是数学上说的函数的自变量,而函数执行完成后我们可以通过 return 关键字来返回一个值,这相当于数学上说的函数的因变量。
函数是绝大多数编程语言中都支持的一个代码的"构建块",但是 Python 中的函数与其他语言中的函数还是有很多不太相同的地方,其中一个显著的区别就是 Python 对函数参数的处理。在 Python 中,函数的参数可以有默认值,也支持使用可变参数,所以 Python 并不需要像其他语言一样支持函数的重载,因为我们在定义一个函数的时候可以让它有多种不同的使用方式,下面是两个小例子。
from random import randint
def roll_dice(n=2):
"""摇色子"""
total = 0
for _ in range(n):
total += randint(1, 6)
return total
def add(a=0, b=0, c=0):
"""三个数相加"""
return a + b + c
# 如果没有指定参数那么使用默认值摇两颗色子
print(roll_dice())
# 摇三颗色子
print(roll_dice(3))
print(add())
print(add(1))
print(add(1, 2))
print(add(1, 2, 3))
# 传递参数时可以不按照设定的顺序进行传递
print(add(c=50, a=100, b=200))
我们给上面两个函数的参数都设定了默认值,这也就意味着如果在调用函数的时候如果没有传入对应参数的值时将使用该参数的默认值,所以在上面的代码中我们可以用各种不同的方式去调用 add 函数,这跟其他很多语言中函数重载的效果是一致的。
其实上面的 add 函数还有更好的实现方案,因为我们可能会对 0 个或多个参数进行加法运算,而具体有多少个参数是由调用者来决定,我们作为函数的设计者对这一点是一无所知的,因此在不确定参数个数的时候,我们可以使用可变参数,代码如下所示。
# 在参数名前面的*表示args是一个可变参数
def add(*args):
total = 0
for val in args:
total += val
return total
# 在调用add函数时可以传入0个或多个参数
print(add())
print(add(1))
print(add(1, 2))
print(add(1, 2, 3))
print(add(1, 3, 5, 7, 9))
用模块管理函数
对于任何一种编程语言来说,给变量、函数这样的标识符起名字都是一个让人头疼的问题,因为我们会遇到命名冲突这种尴尬的情况。最简单的场景就是在同一个文件中定义了两个同名函数,由于 Python 没有函数重载的概念,那么后面的定义会覆盖之前的定义,也就意味着两个函数同名函数实际上只有一个是存在的。
def foo():
print('hello, world!')
def foo():
print('goodbye, world!')
# 下面的代码会输出什么呢?
foo()
当然上面的这种情况我们很容易就能避免,但是如果项目是由多人协作进行团队开发的时候,团队中可能有多个程序员都定义了名为 foo 的函数,那么怎么解决这种命名冲突呢?答案其实很简单,Python 中每个文件就代表了一个模块(module),我们在不同的模块中可以有同名的函数,在使用函数的时候我们通过 import 关键字导入指定的模块就可以区分到底要使用的是哪个模块中的 foo 函数,代码如下所示。
module1.py
def foo():
print('hello, world!')
module2.py
def foo():
print('goodbye, world!')
test.py
from module1 import foo
# 输出hello, world!
foo()
from module2 import foo
# 输出goodbye, world!
foo()
也可以按照如下所示的方式来区分到底要使用哪一个foo函数。
import module1 as m1
import module2 as m2
m1.foo()
m2.foo()
需要说明的是,如果我们导入的模块除了定义函数之外还中有可以执行代码,那么 Python 解释器在导入这个模块时就会执行这些代码,事实上我们可能并不希望如此,因此如果我们在模块中编写了执行代码,最好是将这些执行代码放入如下所示的条件中,这样的话除非直接运行该模块,if 条件下的这些代码是不会执行的,因为只有直接执行的模块的名字才是"main"。
module3.py
def foo():
pass
def bar():
pass
# __name__是Python中一个隐含的变量它代表了模块的名字
# 只有被Python解释器直接执行的模块的名字才是__main__
if __name__ == '__main__':
print('call foo()')
foo()
print('call bar()')
bar()
test.py
import module3
# 导入module3时 不会执行模块中if条件成立时的代码 因为模块的名字是module3而不是__main__
注意:Python 还提供了 pass 语句(C 中没有提供对应的语句)。Python 没有使用传统的大括号来标记代码块,有时,有些地方在语法上要求要有代码,而 Python 中没有对应的空大括号或是分号(;)来表示 C 语言中的“不做任何事”,如果你在需要在有语句块的地方不写任何语句,解释器会提示你语法错误。因此,Python 提供了 pass 语句,它不做任何事情——即 NOP,(No OPeration,无操作)我们从汇编语言中借用这个概念。
练习:
1.实现计算求最大公约数和最小公倍数的函数。
2.实现判断一个数是不是回文数的函数。
"回文"是指正读反读都能读通的句子,它是古今中外都有的一种修辞方式和文字游戏,如"我为人人,人人为我"等。在数学中也有这样一类数字有这样的特征,成为回文数(palindrome number)。 设 n 是一任意自然数。若将 n 的各位数字反向排列所得自然数 n1 与 n 相等,则称 n 为一回文数。例如,若n=1234321,则称 n 为一回文数;但若 n=1234567,则 n 不是回文数。
3.实现判断一个数是不是素数的函数。
参考代码:
题一
def gcd(x, y):
"""求最大公约数"""
(x, y) = (y, x) if x > y else (x, y)
for factor in range(x, 0, -1):
if x % factor == 0 and y % factor == 0:
return factor
def lcm(x, y):
"""求最小公倍数"""
return x * y // gcd(x, y)
题二:
def is_palindrome(num):
"""判断一个数是不是回文数"""
temp = num
total = 0
while temp > 0:
total = total * 10 + temp % 10
temp //= 10
return total == num
题三:
def is_prime(num):
"""判断一个数是不是素数"""
for factor in range(2, int(num ** 0.5) + 1):
if num % factor == 0:
return False
return True if num != 1 else False
注意:通过上面的程序可以看出,当我们将代码中重复出现的和相对独立的功能抽取成函数后,我们可以组合使用这些函数来解决更为复杂的问题,这也是我们为什么要定义和使用函数的一个非常重要的原因。
八、变量的作用域
最后,我们来讨论一下 Python 中有关变量作用域的问题。
def foo():
b = 'hello'
# Python中可以在函数内部再定义函数
def bar():
c = True
print(a)
print(b)
print(c)
bar()
# print(c) # NameError: name 'c' is not defined
if __name__ == '__main__':
a = 100
# print(b) # NameError: name 'b' is not defined
foo()
上面的代码能够顺利的执行并且打印出 100、hello 和 True,但我们注意到了,在 bar 函数的内部并没有定义 a 和 b 两个变量,那么 a 和 b 是从哪里来的。我们在上面代码的 if 分支中定义了一个变量 a,这是一个全局变量(global variable),属于全局作用域,因为它没有定义在任何一个函数中。在上面的 foo 函数中我们定义了变量 b,这是一个定义在函数中的局部变量(local variable),属于局部作用域,在 foo 函数的外部并不能访问到它;但对于 foo 函数内部的 bar 函数来说,变量 b 属于嵌套作用域,在 bar 函数中我们是可以访问到它的。bar 函数中的变量c属于局部作用域,在bar函数之外是无法访问的。事实上,Python查找一个变量时会按照“局部作用域”、“嵌套作用域”、“全局作用域”和“内置作用域”的顺序进行搜索,前三者我们在上面的代码中已经看到了,所谓的“内置作用域”就是 Python 内置的那些标识符,我们之前用过的 input、print、int 等都属于内置作用域。
再看看下面这段代码,我们希望通过函数调用修改全局变量 a 的值,但实际上下面的代码是做不到的。
def foo():
a = 200
print(a) # 200
if __name__ == '__main__':
a = 100
foo()
print(a) # 100
在调用 foo 函数后,我们发现 a 的值仍然是 100,这是因为当我们在函数 foo 中写 a = 200 的时候,是重新定义了一个名字为 a 的局部变量,它跟全局作用域的 a 并不是同一个变量,因为局部作用域中有了自己的变量 a,因此 foo 函数不再搜索全局作用域中的 a。如果我们希望在 foo 函数中修改全局作用域中的 a,代码如下所示。
def foo():
global a
a = 200
print(a) # 200
if __name__ == '__main__':
a = 100
foo()
print(a) # 200
我们可以使用 global 关键字来指示 foo 函数中的变量 a 来自于全局作用域,如果全局作用域中没有 a,那么下面一行的代码就会定义变量 a 并将其置于全局作用域。
在实际开发中,我们应该尽量减少对全局变量的使用,因为全局变量的作用域和影响过于广泛,可能会发生意料之外的修改和使用,除此之外全局变量比局部变量拥有更长的生命周期,可能导致对象占用的内存长时间无法被垃圾回收。
九、字符串及基本操作
第二次世界大战促使了现代电子计算机的诞生,最初计算机被应用于导弹弹道的计算,而在计算机诞生后的很多年时间里,计算机处理的信息基本上都是数值型的信息。世界上的第一台电子计算机叫 ENIAC(电子数值积分计算机),诞生于美国的宾夕法尼亚大学,每秒钟能够完成约 5000 次浮点运算。随着时间的推移,虽然数值运算仍然是计算机日常工作中最为重要的事情之一,但是今天的计算机处理得更多的数据可能都是以文本的方式存在的,如果我们希望通过 Python 程序操作本这些文本信息,就必须要先了解字符串类型以及与它相关的知识。
所谓字符串,就是由零个或多个字符组成的有限序列。在 Python 程序中,如果我们把单个或多个字符用单引号或者双引号包围起来,就可以表示一个字符串。
s1 = 'hello, world!'
s2 = "hello, world!"
# 以三个双引号或单引号开头的字符串可以折行
s3 = """
hello,
world!
"""
print(s1, s2, s3, end='')
可以在字符串中使用 \(反斜杠)来表示转义,也就是说 \ 后面的字符不再是它原来的意义,例如:\n 不是代表反斜杠和字符 n,而是表示换行;而 \t 也不是代表反斜杠和字符 t,而是表示制表符。所以如果想在字符串中表示 ’ 要写成 ',同理想表示 \要写成 \ \。可以运行下面的代码看看会输出什么。
s1 = '\'hello, world!\''
s2 = '\n\\hello, world!\\\n'
print(s1, s2, end='')
在 \ 后面还可以跟一个八进制或者十六进制数来表示字符,例如 \141 和 \x61 都代表小写字母 a,前者是八进制的表示法,后者是十六进制的表示法。也可以在 \ 后面跟 Unicode 字符编码来表示字符,例如 \u9a86\u660a 代表的是中文“张三”。运行下面的代码,看看输出了什么。
s1 = '\141\142\143\x61\x62\x63'
s2 = '\u5f20\u4e09'
print(s1, s2)
如果不希望字符串中的 \ 表示转义,我们可以通过在字符串的最前面加上字母 r 来加以说明,再看看下面的代码又会输出什么。
s1 = r'\'hello, world!\''
s2 = r'\n\\hello, world!\\\n'
print(s1, s2, end='')
Python 为字符串类型提供了非常丰富的运算符,我们可以使用 + 运算符来实现字符串的拼接,可以使用 * 运算符来重复一个字符串的内容,可以使用 in 和 not in 来判断一个字符串是否包含另外一个字符串。
s1 = 'hello ' * 3
print(s1) # hello hello hello
s2 = 'world'
s1 += s2
print(s1) # hello hello hello world
print('ll' in s1) # True
print('good' in s1) # False
十、字符串切片
切片操作(slice)可以从一个字符串中获取子字符串(字符串的一部分)。我们使用一对方括号、起始偏移量 start、终止偏移量 end 以及可选的步长 step 来定义一个分片。
语法如下:
[start:end:step]
1.[:] 提取从开头(默认位置0)到结尾(默认位置-1)的整个字符串
案例:
letter = 'abcdefghijklmnopqrstuvwxyz'
print(letter[:])
2.[start:] 从 start 提取到结尾
案例:
letter = 'abcdefghijklmnopqrstuvwxyz'
print(letter[3:])
3.[:end] 从开头提取到 end - 1
案例:
letter = 'abcdefghijklmnopqrstuvwxyz'
print(letter.__len__())
print(letter[:25])
4.[start:end] 从start 提取到 end - 1
案例:
letter = 'abcdefghijklmnopqrstuvwxyz'
print(letter.__len__())
print(letter[3:25])
5.[start: end:step] 从 start 提取到 end - 1,每 step 个字符提取一个
letter = 'abcdefghijklmnopqrstuvwxyz'
print(letter.__len__())
print(letter[3:25:2])
注意:左侧第一个字符的位置 / 偏移量为 0,右侧最后一个字符的位置 / 偏移量为 -1。几个特别的 examples 如下:
- 提取最后 N 个字符:
letter = 'abcdefghijklmnopqrstuvwxyz'
letter[-3:] 'xyz'
- 从开头到结尾,step 为 N:
letter[::5] 'afkpuz'
- 将字符串倒转(reverse), 通过设置步长为负数:
letter[::-1] 'zyxwvutsrqponmlkjihgfedcba'
在 Python 中,我们还可以通过一系列的方法来完成对字符串的处理,代码如下所示。
str1 = 'hello, world!'
# 通过内置函数len计算字符串的长度
print(len(str1)) # 13
# 获得字符串首字母大写的拷贝
print(str1.capitalize()) # Hello, world!
# 获得字符串每个单词首字母大写的拷贝
print(str1.title()) # Hello, World!
# 获得字符串变大写后的拷贝
print(str1.upper()) # HELLO, WORLD!
# 从字符串中查找子串所在位置
print(str1.find('or')) # 8
print(str1.find('shit')) # -1
# 与find类似但找不到子串时会引发异常
# print(str1.index('or'))
# print(str1.index('shit'))
# 检查字符串是否以指定的字符串开头
print(str1.startswith('He')) # False
print(str1.startswith('hel')) # True
# 检查字符串是否以指定的字符串结尾
print(str1.endswith('!')) # True
# 将字符串以指定的宽度居中并在两侧填充指定的字符
print(str1.center(50, '*'))
# 将字符串以指定的宽度靠右放置左侧填充指定的字符
print(str1.rjust(50, ' '))
str2 = 'abc123456'
# 检查字符串是否由数字构成
print(str2.isdigit()) # False
# 检查字符串是否以字母构成
print(str2.isalpha()) # False
# 检查字符串是否以数字和字母构成
print(str2.isalnum()) # True
str3 = ' jackfrued@126.com '
print(str3)
# 获得字符串修剪左右两侧空格之后的拷贝
print(str3.strip())
我们之前讲过,可以用下面的方式来格式化输出字符串。
a, b = 5, 10
print('%d * %d = %d' % (a, b, a * b))
当然,我们也可以用字符串提供的方法来完成字符串的格式,代码如下所示。
a, b = 5, 10
print('{0} * {1} = {2}'.format(a, b, a * b))
Python 3.6 以后,格式化字符串还有更为简洁的书写方式,就是在字符串前加上字母 f,我们可以使用下面的语法糖来简化上面的代码。
a, b = 5, 10
print(f'{a} * {b} = {a * b}')
十一、列表
不知道大家是否注意到,刚才我们讲到的字符串类型(str)和之前我们讲到的数值类型(int 和 float)有一些区别。数值类型是标量类型,也就是说这种类型的对象没有可以访问的内部结构;而字符串类型是一种结构化的、非标量类型,所以才会有一系列的属性和方法。接下来我们要介绍的列表(list),也是一种结构化的、非标量类型,它是值的有序序列,每个值都可以通过索引进行标识,定义列表可以将列表的元素放在 [] 中,多个元素用逗号进行分隔,可以使用 for 循环对列表元素进行遍历,也可以使用 [] 或 [:] 运算符取出列表中的一个或多个元素。 下面的代码演示了如何定义列表、如何遍历列表以及列表的下标运算。
list1 = [1, 3, 5, 7, 100]
print(list1) # [1, 3, 5, 7, 100]
# 乘号表示列表元素的重复
list2 = ['hello'] * 3
print(list2) # ['hello', 'hello', 'hello']
# 计算列表长度(元素个数)
print(len(list1)) # 5
# 下标(索引)运算
print(list1[0]) # 1
print(list1[4]) # 100
# print(list1[5]) # IndexError: list index out of range
print(list1[-1]) # 100
print(list1[-3]) # 5
list1[2] = 300
print(list1) # [1, 3, 300, 7, 100]
# 通过循环用下标遍历列表元素
for index in range(len(list1)):
print(list1[index])
# 通过for循环遍历列表元素
for elem in list1:
print(elem)
# 通过enumerate函数处理列表之后再遍历可以同时获得元素索引和值
for index, elem in enumerate(list1):
print(index, elem)
下面的代码演示了如何向列表中添加元素以及如何从列表中移除元素。
list1 = [1, 3, 5, 7, 100]
# 添加元素
list1.append(200)
list1.insert(1, 400)
# 合并两个列表
# list1.extend([1000, 2000])
list1 += [1000, 2000]
print(list1) # [1, 400, 3, 5, 7, 100, 200, 1000, 2000]
print(len(list1)) # 9
# 先通过成员运算判断元素是否在列表中,如果存在就删除该元素
if 3 in list1:
list1.remove(3)
if 1234 in list1:
list1.remove(1234)
print(list1) # [1, 400, 5, 7, 100, 200, 1000, 2000]
# 从指定的位置删除元素
list1.pop(0)
list1.pop(len(list1) - 1)
print(list1) # [400, 5, 7, 100, 200, 1000]
# 清空列表元素
list1.clear()
print(list1) # []
和字符串一样,列表也可以做切片操作,通过切片操作我们可以实现对列表的复制或者将列表中的一部分取出来创建出新的列表,代码如下所示。
fruits = ['grape', 'apple', 'strawberry', 'waxberry']
fruits += ['pitaya', 'pear', 'mango']
# 列表切片
fruits2 = fruits[1:4]
print(fruits2) # apple strawberry waxberry
# 可以通过完整切片操作来复制列表
fruits3 = fruits[:]
print(fruits3) # ['grape', 'apple', 'strawberry', 'waxberry', 'pitaya', 'pear', 'mango']
fruits4 = fruits[-3:-1]
print(fruits4) # ['pitaya', 'pear']
# 可以通过反向切片操作来获得倒转后的列表的拷贝
fruits5 = fruits[::-1]
print(fruits5) # ['mango', 'pear', 'pitaya', 'waxberry', 'strawberry', 'apple', 'grape']
下面的代码实现了对列表的排序操作。
list1 = ['orange', 'apple', 'zoo', 'internationalization', 'blueberry']
list2 = sorted(list1)
# sorted函数返回列表排序后的拷贝不会修改传入的列表
# 函数的设计就应该像sorted函数一样尽可能不产生副作用
list3 = sorted(list1, reverse=True)
# 通过key关键字参数指定根据字符串长度进行排序而不是默认的字母表顺序
list4 = sorted(list1, key=len)
print(list1)
print(list2)
print(list3)
print(list4)
# 给列表对象发出排序消息直接在列表对象上进行排序
list1.sort(reverse=True)
print(list1)
练习:
1.在不排序的情况下使用 for 循环找出数组中最大的那个数。
2.首先创建一个长度是 5 的数组,并填充 0-100 之间的随机数。使用 for 循环或者 while 循环,对这个数组实现反转效果。
参考代码:
list1 = [1, 3, 5, 7, 100]
max_value = list1[0]
for i in range(1, len(list1)):
if list1[i] > max_value:
max_value = list1[i]
print(max_value)
参考代码:
import random
list1 = [0] * 5
for i in range(len(list1)):
list1[i] = random.randint(0, 100)
print(list1)
for i in range(len(list1) // 2):
list1[i], list1[4 - i] = list1[4 - i], list1[i]
print(list1)
十二、元组
Python 中的元组与列表类似也是一种容器数据类型,可以用一个变量(对象)来存储多个数据,不同之处在于元组的元素不能修改,在前面的代码中我们已经不止一次使用过元组了。顾名思义,我们把多个元素组合到一起就形成了一个元组,所以它和列表一样可以保存多条数据。下面的代码演示了如何定义和使用元组。
# 定义元组
t = ('张三', 38, True, '四川成都')
print(t)
# 获取元组中的元素
print(t[0])
print(t[3])
# 遍历元组中的值
for member in t:
print(member)
# 重新给元组赋值
# t[0] = '王大锤' # TypeError
# 变量t重新引用了新的元组原来的元组将被垃圾回收
t = ('王大锤', 20, True, '云南昆明')
print(t)
# 将元组转换成列表
person = list(t)
print(person)
# 列表是可以修改它的元素的
person[0] = '李小龙'
person[1] = 25
print(person)
# 将列表转换成元组
fruits_list = ['apple', 'banana', 'orange']
fruits_tuple = tuple(fruits_list)
print(fruits_tuple)
这里有一个非常值得探讨的问题,我们已经有了列表这种数据结构,为什么还需要元组这样的类型呢?
1.元组中的元素是无法修改的,事实上我们在项目中尤其是多线程环境(后面会讲到)中可能更喜欢使用的是那些不变对象(一方面因为对象状态不能修改,所以可以避免由此引起的不必要的程序错误,简单的说就是一个不变的对象要比可变的对象更加容易维护;另一方面因为没有任何一个线程能够修改不变对象的内部状态,一个不变对象自动就是线程安全的,这样就可以省掉处理同步化的开销。一个不变对象可以方便的被共享访问)。所以结论就是:如果不需要对元素进行添加、删除、修改的时候,可以考虑使用元组,当然如果一个方法要返回多个值,使用元组也是不错的选择。
2.元组在创建时间和占用的空间上面都优于列表。我们可以使用 sys 模块的 getsizeof 函数来检查存储同样的元素的元组和列表各自占用了多少内存空间,这个很容易做到。
from sys import getsizeof
list1 = [0, 1, 2, 3, 4, 5]
list2 = (0, 1, 2, 3, 4, 5)
print(getsizeof(list1))
# 112
print(getsizeof(list2))
# 96
十三、集合
Python 中的集合跟数学上的集合是一致的,不允许有重复元素,而且可以进行交集、并集、差集等运算。可以按照下面代码所示的方式来创建和使用集合。
# 创建集合的字面量语法
set1 = {1, 2, 3, 3, 3, 2}
print(set1)
print('Length =', len(set1))
# 创建集合的构造器语法(面向对象部分会进行详细讲解)
set2 = set(range(1, 10))
set3 = set((1, 2, 3, 3, 2, 1))
print(set2, set3)
# 创建集合的推导式语法(推导式也可以用于推导集合)
set4 = {num for num in range(1, 100) if num % 3 == 0 or num % 5 == 0}
print(set4)
向集合添加元素和从集合删除元素。
set1.add(4)
set1.add(5)
set2.update([11, 12])
set2.discard(5)
if 4 in set2:
set2.remove(4)
print(set1, set2)
print(set3.pop())
print(set3)
集合的成员、交集、并集、差集等运算。
# 集合的交集、并集、差集、对称差运算
print(set1 & set2)
# print(set1.intersection(set2))
print(set1 | set2)
# print(set1.union(set2))
print(set1 - set2)
# print(set1.difference(set2))
print(set1 ^ set2)
# print(set1.symmetric_difference(set2))
# 判断子集和超集
print(set2 <= set1)
# print(set2.issubset(set1))
print(set3 <= set1)
# print(set3.issubset(set1))
print(set1 >= set2)
# print(set1.issuperset(set2))
print(set1 >= set3)
# print(set1.issuperset(set3))
十四、字典
字典是另一种可变容器模型,Python 中的字典跟我们生活中使用的字典是一样一样的,它可以存储任意类型对象,与列表、集合不同的是,字典的每个元素都是由一个键和一个值组成的“键值对”,键和值通过冒号分开。下面的代码演示了如何定义和使用字典。
# 创建字典的字面量语法
scores = {'张三': 95, '白元芳': 78, '狄仁杰': 82}
print(scores)
# 创建字典的构造器语法
items1 = dict(one=1, two=2, three=3, four=4)
# 通过zip函数将两个序列压成字典
items2 = dict(zip(['a', 'b', 'c'], '123'))
# 创建字典的推导式语法
items3 = {num: num ** 2 for num in range(1, 10)}
print(items1, items2, items3)
# 通过键可以获取字典中对应的值
print(scores['张三'])
print(scores['狄仁杰'])
# 对字典中所有键值对进行遍历
for key in scores:
print(f'{key}: {scores[key]}')
# 更新字典中的元素
scores['白元芳'] = 65
scores['诸葛王朗'] = 71
scores.update(冷面=67, 方启鹤=85)
print(scores)
if '武则天' in scores:
print(scores['武则天'])
print(scores.get('武则天'))
# get方法也是通过键获取对应的值但是可以设置默认值
print(scores.get('武则天', 60))
# 删除字典中的元素
print(scores.popitem())
print(scores.popitem())
print(scores.pop('张三', 100))
# 清空字典
scores.clear()
print(scores)
章节练习
1.设计一个函数产生指定长度的验证码,验证码由大小写字母和数字构成,默认长度为 4。
2.设计一个函数返回给定文件名的后缀名,增加一个参数判断是否需要带点。
3.设计一个函数返回传入的列表中最大和第二大的元素的值。
4.计算指定的年月日是这一年的第几天。
5.打印杨辉三角。
6.有 15 个基督徒和 15 个非基督徒在海上遇险,为了能让一部分人活下来不得不将其中 15 个人扔到海里面去,有个人想了个办法就是大家围成一个圈,由某个人开始从 1 报数,报到 9 的人就扔到海里面,他后面的人接着从 1 开始报数,报到 9 的人继续扔到海里面,直到扔掉 15 个人。由于上帝的保佑,15 个基督徒都幸免于难,问这些人最开始是怎么站的,哪些位置是基督徒哪些位置是非基督徒。
参考代码:
1.验证码生成。
import random
def generate_code(code_len=4):
all_chars = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
last_pos = len(all_chars) - 1
code = ''
for _ in range(code_len):
index = random.randint(0, last_pos)
code += all_chars[index]
return code
if __name__ == '__main__':
print(generate_code(4))
2.返回文件后缀名。
def get_suffix(filename, has_dot=False):
pos = filename.rfind('.')
if 0 < pos < len(filename) - 1:
index = pos if has_dot else pos + 1
return filename[index:]
else:
return ''
if __name__ == '__main__':
print(get_suffix('aa.txt',True))
3.设计一个函数返回传入的列表中最大和第二大的元素的值。
def max2(x):
m1, m2 = (x[0], x[1]) if x[0] > x[1] else (x[1], x[0])
for index in range(2, len(x)):
if x[index] > m1:
m2 = m1
m1 = x[index]
elif x[index] > m2:
m2 = x[index]
return m1, m2
if __name__ == '__main__':
print(max2([1,2,5,4,8,45,6]))
4.判断天数
def is_leap_year(year):
"""
判断指定的年份是不是闰年
:param year: 年份
:return: 闰年返回True平年返回False
"""
return year % 4 == 0 and year % 100 != 0 or year % 400 == 0
def which_day(year, month, date):
"""
计算传入的日期是这一年的第几天
:param year: 年
:param month: 月
:param date: 日
:return: 第几天
"""
days_of_month = [
[31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31],
[31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
][is_leap_year(year)]
total = 0
for index in range(month - 1):
total += days_of_month[index]
return total + date
def main():
print(which_day(1980, 11, 28))
print(which_day(1981, 12, 31))
print(which_day(2018, 1, 1))
print(which_day(2016, 3, 1))
if __name__ == '__main__':
main()
5.杨辉三角
def main():
num = int(input('Number of rows: '))
yh = [[]] * num
for row in range(len(yh)):
yh[row] = [None] * (row + 1)
for col in range(len(yh[row])):
if col == 0 or col == row:
yh[row][col] = 1
else:
yh[row][col] = yh[row - 1][col] + yh[row - 1][col - 1]
print(yh[row][col], end='\t')
print()
if __name__ == '__main__':
main()
6.基督教徒
def main():
persons = [True] * 30
counter, index, number = 0, 0, 0
while counter < 15:
if persons[index]:
number += 1
if number == 9:
persons[index] = False
counter += 1
number = 0
index += 1
index %= 30
for person in persons:
print('基' if person else '非', end='')
if __name__ == '__main__':
main()















 411
411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











