import java. util. UUID;
public enum PL0 {
IDENTIFIER ( "IDENTIFIER" , 1 ) ,
INTEGER ( "INTEGER" , 2 ) ,
ADD ( "+" , 3 ) ,
SUB ( "-" , 4 ) ,
MUL ( "*" , 5 ) ,
DIV ( "/" , 6 ) ,
EQL ( "=" , 7 ) ,
GT ( ">" , 8 ) ,
LT ( "<" , 9 ) ,
NE ( "<>" , 10 ) ,
LE ( "<=" , 11 ) ,
GE ( ">=" , 12 ) ,
LS ( "(" , 13 ) ,
RS ( ")" , 14 ) ,
LB ( "{" , 15 ) ,
RB ( "}" , 16 ) ,
SEM ( ";" , 17 ) ,
DOT ( "," , 18 ) ,
YY ( "\"" , 19 ) ,
SET ( ":=" , 20 ) ,
VAR ( "var" , 21 ) ,
IF ( "if" , 22 ) ,
THEN ( "then" , 23 ) ,
ELSE ( "else" , 24 ) ,
WHILE ( "while" , 25 ) ,
FOR ( "for" , 26 ) ,
BEGIN ( "begin" , 27 ) ,
WRITELN ( "writeln" , 28 ) ,
PROCEDURE ( "procedure" , 29 ) ,
END ( "end" , 30 ) ,
ERROR ( UUID. randomUUID ( ) . toString ( ) , 100 ) ;
private String word;
private Integer value;
PL0 ( String word, Integer value) {
this . word = word;
this . value = value;
}
public String getWord ( ) {
return word;
}
public void setWord ( String word) {
this . word = word;
}
public Integer getValue ( ) {
return value;
}
public void setValue ( Integer value) {
this . value = value;
}
}
import lombok. AllArgsConstructor ;
import lombok. Data ;
import lombok. Getter ;
import lombok. Setter ;
@Data
@Getter
@Setter
@AllArgsConstructor
public class Node {
String key;
Integer value;
@Override
public String toString ( ) {
return "(" + value + "," + key + ")" ;
}
}
import javax. swing. * ;
import java. io. * ;
import java. util. HashMap ;
import java. util. LinkedList ;
import java. util. List ;
import java. util. Map ;
public class Main {
private static Integer index = 0 ;
private static String progress;
public static List < Node > = new LinkedList < > ( ) ;
public static Map < String , Integer > = new HashMap < > ( ) ;
public static void main ( String [ ] args) throws IOException {
init ( ) ;
initPL0 ( ) ;
System . out. println ( progress) ;
analyzer ( ) ;
}
private static void analyzer ( ) {
while ( index < progress. length ( ) ) {
Node node = scanner ( ) ;
if ( node != null ) {
list. add ( node) ;
}
}
list. forEach ( System . out:: println ) ;
}
private static Node scanner ( ) {
StringBuilder tokenBuilder = new StringBuilder ( ) ;
while ( progress. charAt ( index) == ' ' || progress. charAt ( index) == '\n' || progress. charAt ( index) == '\t' || progress. charAt ( index) == '\r' ) {
index++ ;
if ( index >= progress. length ( ) ) {
return null ;
}
}
if ( Character . isLetter ( progress. charAt ( index) ) ) {
while ( Character . isLetter ( progress. charAt ( index) ) || Character . isDigit ( progress. charAt ( index) ) || progress. charAt ( index) == '_' ) {
tokenBuilder. append ( progress. charAt ( index) ) ;
index++ ;
}
String res = tokenBuilder. toString ( ) ;
if ( map. containsKey ( res) ) {
return new Node ( "\"" + res + "\"" , map. get ( res) ) ;
} else {
return new Node ( "\"" + res + "\"" , PL0. IDENTIFIER. getValue ( ) ) ;
}
}
if ( Character . isDigit ( progress. charAt ( index) ) ) {
boolean floatFlag = false ;
while ( Character . isDigit ( progress. charAt ( index) ) || progress. charAt ( index) == '.' ) {
if ( ! floatFlag && progress. charAt ( index) == '.' ) {
floatFlag = true ;
}
if ( floatFlag && progress. charAt ( index) == '.' ) {
throw new IllegalArgumentException ( "语法不正确" ) ;
}
tokenBuilder. append ( progress. charAt ( index) ) ;
index++ ;
}
return new Node ( tokenBuilder. toString ( ) , PL0. INTEGER. getValue ( ) ) ;
}
switch ( progress. charAt ( index) ) {
case ':' :
if ( progress. charAt ( index + 1 ) == '=' ) {
index += 2 ;
return new Node ( "\"" + PL0. SET. getWord ( ) + "\"" , PL0. SET. getValue ( ) ) ;
} else {
index++ ;
throw new IllegalArgumentException ( "语法不正确,:的意思是:=嘛?" ) ;
}
case '<' :
if ( progress. charAt ( index + 1 ) == '>' ) {
index += 2 ;
return new Node ( "\"" + PL0. NE. getWord ( ) + "\"" , PL0. NE. getValue ( ) ) ;
}
if ( progress. charAt ( index + 1 ) == '=' ) {
index += 2 ;
return new Node ( "\"" + PL0. LE. getWord ( ) + "\"" , PL0. LE. getValue ( ) ) ;
}
index++ ;
return new Node ( "\"" + PL0. LT + "\"" , PL0. LT. getValue ( ) ) ;
case '>' :
if ( progress. charAt ( index + 1 ) == '=' ) {
index += 2 ;
return new Node ( "\"" + PL0. GE. getWord ( ) + "\"" , PL0. GE. getValue ( ) ) ;
}
index++ ;
return new Node ( "\"" + PL0. GT. getWord ( ) + "\"" , PL0. GT. getValue ( ) ) ;
case '+' :
case '-' :
case '*' :
case '/' :
case '=' :
case ';' :
case ',' :
case '"' :
String res = String . valueOf ( progress. charAt ( index++ ) ) ;
return new Node ( "\"" + res + "\"" , map. get ( res) ) ;
default :
index++ ;
return null ;
}
}
private static void init ( ) {
for ( PL0 v : PL0. values ( ) ) {
map. put ( v. getWord ( ) , v. getValue ( ) ) ;
}
}
private static void initPL0 ( ) throws IOException {
String path = "D:\\HJC\\Desktop\\编译原理\\pl01.txt" ;
BufferedReader reader = null ;
try {
System . out. println ( path) ;
reader = new BufferedReader ( new InputStreamReader ( new FileInputStream ( path) ) ) ;
String str;
StringBuilder stringBuilder = new StringBuilder ( ) ;
while ( ( str = reader. readLine ( ) ) != null ) {
stringBuilder. append ( str) . append ( '\n' ) ;
}
progress = stringBuilder. toString ( ) ;
} catch ( Exception e) {
e. printStackTrace ( ) ;
} finally {
if ( reader != null ) {
reader. close ( ) ;
}
}
}
}
procedure divide;
var w;
begin
r := x; q := 0 ; w := y;
end
( 29 ,"procedure" )
( 1 ,"divide" )
( 17 ,";" )
( 21 ,"var" )
( 1 ,"w" )
( 17 ,";" )
( 27 ,"begin" )
( 1 ,"r" )
( 20 ,":=" )
( 1 ,"x" )
( 17 ,";" )
( 1 ,"q" )
( 20 ,":=" )
( 2,0 )
( 17 ,";" )
( 1 ,"w" )
( 20 ,":=" )
( 1 ,"y" )
( 17 ,";" )
( 30 ,"end" )
进程已结束,退出代码为 0










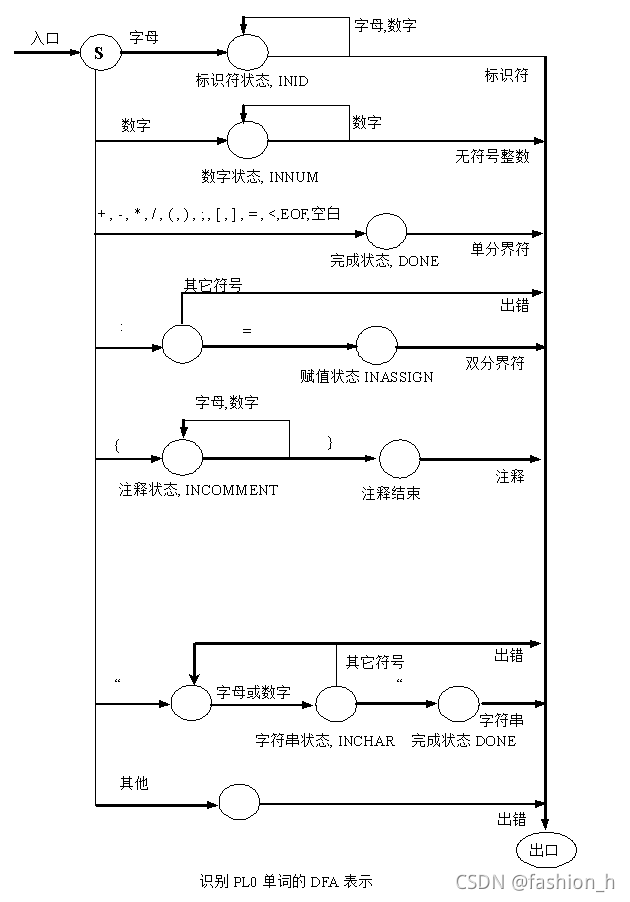
















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











