







本文是《图解Spark核心技术与案例实战》一书的读书笔记,将简单介绍一下几种Spark运行架构。
总体介绍
三种角色
Spark有本地运行模式,stand alone模式,集群模式,yarn模式,mesos模式等多种模式。这些模式的主要组成部分都可以看成SparkContext,Cluster Manager,Executor三个部分,其中SparkContext负责管理Application的执行,与ClusterManager通信,进行资源的申请,任务的调度,监控。Cluster Manager负责管理集群资源,Executor负责执行task。
在不同的模式下,ClusterManager由不同的组件担任,在本地,stand alone和集群模式下,cluster manager是master,在Yarn 模式中由Resource Manager担任,在Mesos模式中由Application Master担任。
重要的类
TaskScheduler.
taskScheduler负责将DAGScheduler解析出来的stage转换成task set,然后通过submitTasks()提交给SchedulerBackend,SchedulerBackend收到任务之后使用reviveOffers()方法分配运行资源并启动任务。TaskScheduler负责沟通DAGScheduler和SchedulerBackend,由于DAGScheduler抽象层次较高,而SchedulerBackend负责与底层接口交互,因此TaskScheduler可以起到屏蔽底层不同的资源分配方式的作用。TaskScheduler的主要实现类是TaskSchedulerImpl,Yarn模式下提供了两个类继承TaskSchedulerImpl,分别是YarnScheduler和YarnCluseterScheduler.
SchedulerBackend
SchedulerBackend根据不同的运行模式分为本地的LocalBackend,粗粒度模式下的CoarseGrainedSchedulerBackend,细粒度模式下的MesosSchedulerBackend,粗粒度模式下又分为stand alone模式下的SparkDeploySchedulerBackend,Yarn运行模式下的YarnSchedulerBackend,mesos粗粒度模式的CoarseMesosShedulerBackend.其中Yarn又根据client模式和cluster模式分为了YarnClientSchedulerBackend,YarnClusterSchedulerBackend.

本地模式
本地模式一般用于测试,在这种模式下所有的Spark进程都运行在同一个JVM里面,比如在IDEA里面直接启动一个程序,那么这种情况下就是在本地模式。在运行中,默认不加配置的情况下使用的是本地模式,还可以在参数里或者程序中显式指定使用本地模式:
参数:--master local[4]
代码:SparkConf conf = new SparkConf().setAppName("Simple Application").setMaster("local[*]");
local模式首先启动了SparkContext,在启动SparkContext的过程中会初始化DAGScheduler,启动TaskSchedulerImpl,初始化TaskSchedulerImpl的时候会启动LocalBackend。启动LocalBackend的时候会实例化LocalEndpoint,实例化LocalEndpoint的时候会实例化Executor。
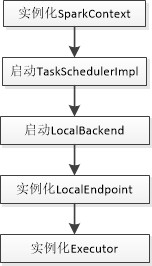
本地模式的job执行调用图:

上面省略了一些细节,只突出了在调用过程中比较重要的一些组件,大体流程如下:
main方法执行,创建了SparkContext,DAGScheduler,TaskSchedulerImpl等组件,程序执行到Action操作,开始执行job
- SparkContext 中的runJob方法层层调用最终通过messageLoop的方法提交给了DAGScheduler
- DAGScheduler对RDD进行解析,通过宽依赖划分为不同的stage,然后通过submitStage方法提交调度阶段,注意在这之后还是DAGScheduler做了将stage解析为task的任务,最后是在DAGScheduler的submitMissingTasks()方法里面调用了taskSchedulerImpl的submitTasks方法
- taskSchedulerImpl的submitTasks方法里面调用了LocalBackend的reviveOffers方法,开始分配资源。
- LocalBackend的reviveOffers使用locaEndpoint发送了消息,注意这里的localEndpoint虽然是一个RpcEndpointRef的类,但是底层操作的是LocalEndpoint,所以发送的reviveOffer消息被LocalEndpoint收到,然后调用LocalEndpoint的reviveOffers,在里面调用Executor的launchTasks开始执行任务,首先是使用Runnable的实现类TaskRunner包装了task.runTask,然后通过线程池调度运行任务。
独立运行模式(Standalone)
独立运行模式是使用Spark自己实现的资源管理组件,而没有使用Yarn或者Mesos的运行模式。独立运行模式由客户端,Master节点,Worker节点组成,而SparkContext可能运行在本地客户端,也可能运行在Master节点,当使用run-example来运行spark程序的时候,SparkContext运行在Master节点上,如果使用spark submit工具运行作业时,spark context 运行在提交作业的客户端上。
在worker节点上通过ExecutorRunner运行了若干个CoarseGrainedExecutorBackend进程,每个进程包含一个executor,executor里面包含了一个线程池,用来调度执行任务。

- 启动过程中会实例化DriverEndpint,这个实际上是在SparkDeploySchedulerBackend里面调用了CoarseGrainedSchedulerBackend的start,然后SparkDeploySchedulerBackend自身的start方法实例化了一个AppClient
override def start() {
super.start()
……
client = new AppClient(sc.env.actorSystem, masters, appDesc, this, conf)
client.start()
waitForRegistration()
}
// CoarseGrainedExecutorBackend的start
override def start() {
val properties = new ArrayBuffer[(String, String)]
for ((key, value) <- scheduler.sc.conf.getAll) {
if (key.startsWith("spark.")) {
properties += ((key, value))
}
}
// TODO (prashant) send conf instead of properties
// 创建driverEndpoint
driverEndpoint = rpcEnv.setupEndpoint(
CoarseGrainedSchedulerBackend.ENDPOINT_NAME, new DriverEndpoint(rpcEnv, properties))
}
在AppClient里面有个内部类,ClientActor,在AppClient的start方法里面初始化了这个ClientActor,触发了它的生命周期方法,registerWithMaster,然后就向Master发送了注册请求。
def tryRegisterAllMasters() {
for (masterAkkaUrl <- masterAkkaUrls) {
logInfo("Connecting to master " + masterAkkaUrl + "...")
val actor = context.actorSelection(masterAkkaUrl)
// !是运算符重载,发送了RegisterApplication消息
actor ! RegisterApplication(appDescription)
}
}
- master 收到信息之后回复了RegisterApplication消息,并调用了schedule启动Executor
override def receiveWithLogging: PartialFunction[Any, Unit] = {
case RegisterApplication(description) => {
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else {
logInfo("Registering app " + description.name)
// 创建App
val app = createApplication(description, sender)
// 注册App
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
persistenceEngine.addApplication(app)
// 回复消息
sender ! RegisteredApplication(app.id, masterUrl)
// 启动Executor
schedule()
}
}
/**
* Schedule the currently available resources among waiting apps. This method will be called
* every time a new app joins or resource availability changes.
*/
private def schedule(): Unit = {
if (state != RecoveryState.ALIVE) {
return }
// Drivers take strict precedence over executors
val shuffledWorkers = Random.shuffle(workers) // Randomization helps balance drivers
// 遍历所有活着的worker
for (worker <- shuffledWorkers if worker.state == WorkerState.ALIVE) {
// 遍历所有等待的driver
for (driver <- waitingDrivers) {
// 如果worker的空闲资源可以满足driver的需求
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
// 在worker上面启动driver程序
launchDriver(worker, driver)
waitingDrivers -= driver
}
}
}
// 在worker 上启动executor
startExecutorsOnWorkers()
}
上面给的launchDriver给worker发送了launchDriver的消息,worker收到了消息之后会尝试启动driver,而startExecutorOnWorkers会向选中的worker发送launchExecutor的消息,worker收到消息之后会启动Executor。
override def receiveWithLogging: PartialFunction[Any, Unit] = {
// 启动executor
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>
if (masterUrl != activeMasterUrl) {
logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.")
} else {
try {
logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name))
// Create the executor's working directory
val executorDir = new File(workDir, appId + "/" + execId)
if (!executorDir.mkdirs()) {
throw new IOException("Failed to create directory " + executorDir)
}
// Create local dirs for the executor. These are passed to the executor via the
// SPARK_EXECUTOR_DIRS environment variable, and deleted by the Worker when the
// application finishes.
val appLocalDirs = appDirectories.get(appId).getOrElse {
Utils.getOrCreateLocalRootDirs(conf).map {
dir =>
Utils.createDirectory(dir, namePrefix = "executor").getAbsolutePath()
}.toSeq
}
appDirectories(appId) = appLocalDirs
// 创建executor runner
val manager = new ExecutorRunner(
appId,
execId,
appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)),
cores_,
memory_,
self,
workerId,
host,
webUi.boundPort,
publicAddress,
sparkHome,
executorDir,
akkaUrl,
conf,
appLocalDirs, ExecutorState.LOADING)
executors(appId + "/" + execId) = manager
manager.start()
coresUsed += cores_
memoryUsed += memory_
master ! ExecutorStateChanged(appId, execId, manager.state, None, None)
} catch {
……
}
// 启动driver
case LaunchDriver(driverId, driverDesc) => {
logInfo(s"Asked to launch driver $driverId")
val driver = new DriverRunner(
conf,
driverId,
workDir,
sparkHome,
driverDesc.copy(command = Worker 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3024
3024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









