







bert模型的文章有许多,不过看了以后对整个模型的结构和数据流并没有太直观的理解,在看了源代码后有了自己的一些的理解写在下面,不一定全对,在学习中会不断更新,如果有不同意见欢迎评论提出。
首先bert的主体结构(base版),简单用一个图表示:

对应贴一下论文中的参数说明
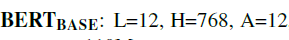
- 这里的L=12指的是网络层数(深度)为12层;
- A=12是transformer块中的多头自注意力的头数,需要注意的是bert中的transformer块并不是论文中的transformer结构,而是只用了encoder的部分;
- H指的是传输过程中的隐藏状态hidden_size,这里是768的向量,对应到输入就是一个单词给一个768维的向量来表示。
这边是transformer的结构图,我们只用了左边的encoder:
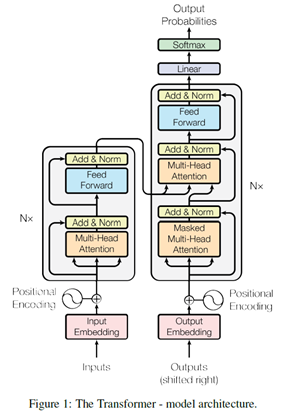
我看模型往往希望看到整个数据的流程,和网络的结构。我将整个数据流动画在下面的图中:

- 输入:这里的输入代表了最终的输入(这里以句子对的输入为例),最初的输入每次会取[batch_size,max_seq_length]的数据。batch_size代表了句子数目,论文中取的是256;max_seq_length代表了每个句子最大的单词数,论文中取的是512,单词少了会补齐多了会截断。所以embedding后最终的输入是[batch_size*max_seq_length,hidden_size] 格式。
- 多头自注意力的多头:这里的多头会将输入切分,最终的输入是[batch_size*max_seq_length,hidden_size] 格式,经过切分会将hidden_size切为12份,每个头得到的数据格式为[batch_size*max_seq_length,hidden_size/头数] 。之后每个头会经过不同的权重矩阵进行线性变换。
- Residual network:残差网络,主要为了能让模型建立的够深。
- Feed Forward:前馈神经网络,神经元数为hidden_size*4
这样连过12个transformer块之后,取[CLS]的输出作为整个句子的表示,得到句子对中两个句子的相似度。
















 1793
1793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









