






目录
前言
首先,需要明确一点,爬虫的使用必须遵守法律法规和网站的使用协议,不可以随意抓取和使用网站内容。
Python 爬虫介绍 | 菜鸟教程 (runoob.com)
一.导包
再开始之前我们需要导入几个模块包,方便后续的操作。
import requests
from lxml import etree
import parsel
import csv这几个包如果系统库里面没有,我们可以在CMD里把它们下载: pip install requests ,
pip isatall lxml ,pip isatall parsel,这三个指令就可以把它们下载好了。
二.爬取网页
我这里爬取的是豆瓣影评里的《放牛班的春天》,首先要拿到它的网页链接:
https://movie.douban.com/subject/1291549/comments
这个就是它的网页链接。
把网页放进一个url里面
url='https://movie.douban.com/subject/1291549/comments'1、伪装头部
我们还需要一个伪装头部,以免被反爬
上面这个就是伪装头部,我们可以在网页中获取 按键盘的F12,我们进入这个页面获取头部

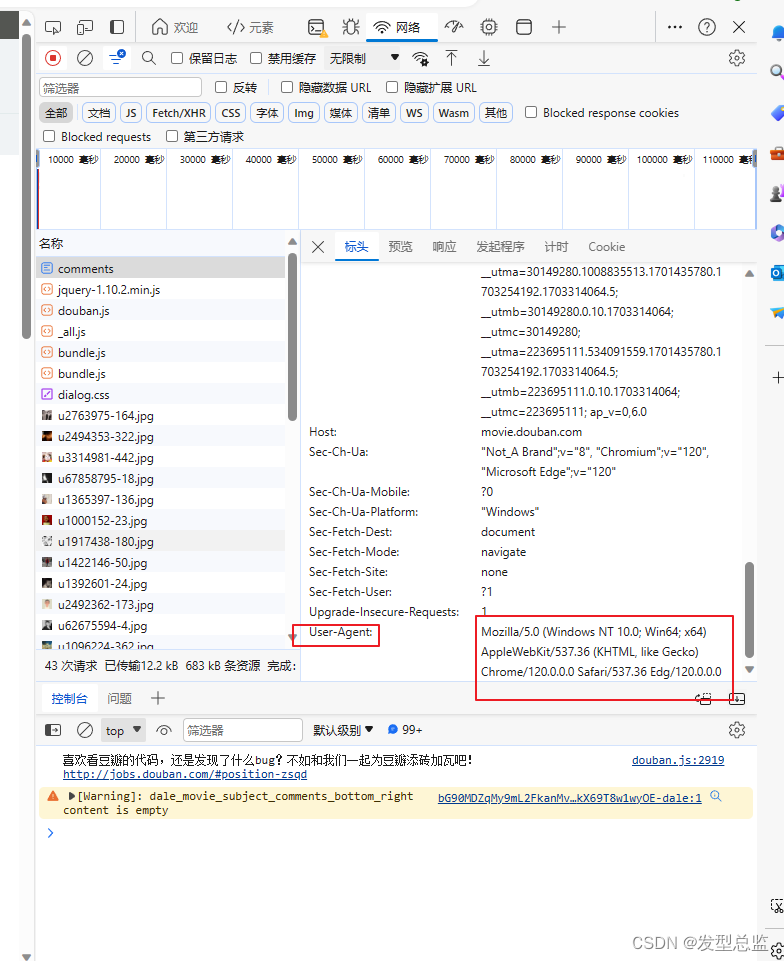
这两个头部我们直接复制过来就可以了
header={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0',
'Cookie':'SUB=_2AkMSGWslf8NxqwFRmfoUzWLhbYt2wwDEieKkRZr-JRMxHRl-yT8XqmUFtRB6OZlFys4qvlKx3Tvb2etnSP7fIwH3xZrs; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WF4C88xAdkTOamY1VEDYLcD; XSRF-TOKEN=UWgjjU1gpBd6U_RyNd9Xj5tl; WBPSESS=V0zdZ7jH8_6F0CA8c_ussf0MMoeKVtPabByLGblUomw7z-ZSmpLzjmq_g5HzCnAVut_Q_s9RcaOG-5n78dfP6Uf4mudJLC-Tvq1Ou_UBUQHR8A7ThRBx-FfG9gqPrdYW'
}2、头部封装
然后我们把头进行封装
res=requests.get(
url=url,
headers=header,
).text把网页进行输出,看一下它的代码,检验一下我们上面的步骤有没有错误
print(res)看一下它的输出结果
我们可以看到它的网页代码出来了说明我们的步骤没有出错。
3、评论内容的查找
我们进入《放牛班的春天》的评论网页按键盘F12功能键进入查找我们需要的内容

因为我们要爬取它的评论内容点击量等内容,所以我们要知道它的代码在哪里,我们找寻它的规律将它们爬取下来。
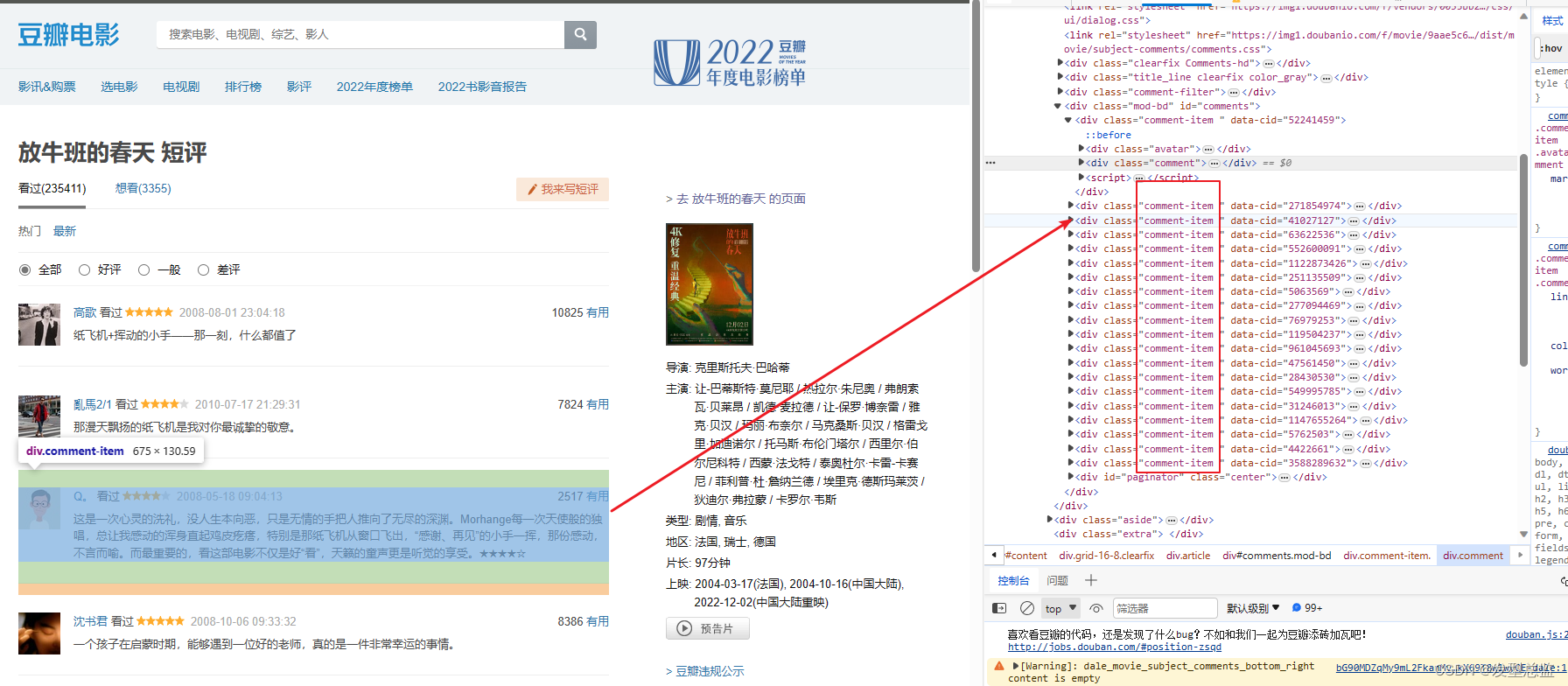
我们鼠标放在右边的代码上发现它们的评论内容等,都在 div的class里面这样我们就找到它们的规律了。
4、评论内容的爬取
我们使用上面导入的parsel里的一个Selector功能,将一整个框架爬取下来。
selector=parsel.Selector(res)
comment_list=selector.css('.comment-item')然后因为是一整个框架我们需要把姓名评论和点赞分别爬取,这时候我们需要一个for循环把它们分开。
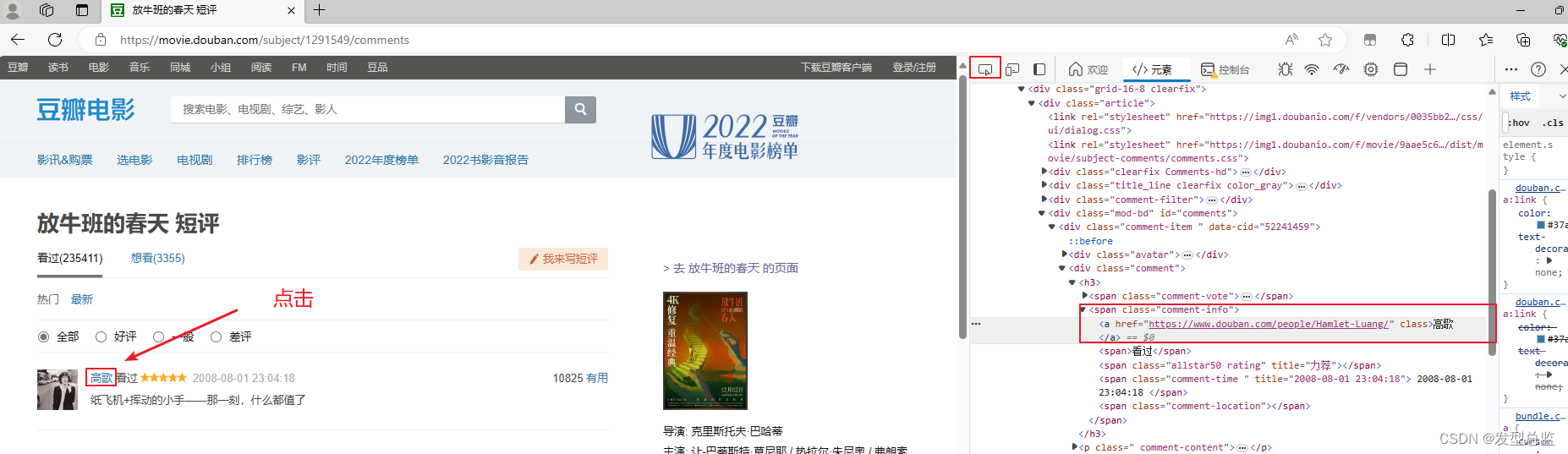
我们可以使用上面讲到的方法点击我们需要获取的东西然后看到他的代码块在哪我们可以清楚的看到,姓名在 span模块里的的a模块中。

这里我们使用的是用css语法来获取我们需要的内容。
for comment in comment_list:
name = comment.css('.comment-info a::text').get().strip()#姓名
print(name)我们可以输出一下看看有没有找对

查看输出我们发现没什么错误接下来就可以把剩下的内容爬取下来了

结尾的srtip()是取消它的空格让爬取出来的内容更加好看。到这一步我们就基本能爬取我们需要的内容了。
5、多页爬取
有些同学需要爬取的数据可能对数量有需求这样我们可以进行多页爬取,回到我们的网页点击后页观察它的网页地址变化。

 然后我们把网页链接拿下来
然后我们把网页链接拿下来

发现它们的start有变化我们就用一个for循环把他后面的也爬取下来
for page in range(0,10):
url=f'https://movie.douban.com/subject/1291549/comments?start={page}&limit=20&status=P&sort=new_score'6、保存爬取内容到电脑
然后我们把它的内容保存到电脑,就完成了。
with open('放牛班的春天.csv',mode='a',encoding='utf-8',newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow([name,short,time,vote_count])
print("下载完成")7、完整的代码
#导包
import requests
from lxml import etree
import parsel
import csv
#豆瓣链接
#https://movie.douban.com/subject/1291549/comments?start=20&limit=20&status=P&sort=new_score
#第一页链接 https://movie.douban.com/subject/1291549/comments?limit=20&status=P&sort=new_score
#第二页链接 https://movie.douban.com/subject/1291549/comments?start=20&limit=20&status=P&sort=new_score
#第三页链接 https://movie.douban.com/subject/1291549/comments?start=40&limit=20&status=P&sort=new_score
# url='https://movie.douban.com/subject/1291549/comments'
#头
header={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0',
'Cookie':'SUB=_2AkMSGWslf8NxqwFRmfoUzWLhbYt2wwDEieKkRZr-JRMxHRl-yT8XqmUFtRB6OZlFys4qvlKx3Tvb2etnSP7fIwH3xZrs; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WF4C88xAdkTOamY1VEDYLcD; XSRF-TOKEN=UWgjjU1gpBd6U_RyNd9Xj5tl; WBPSESS=V0zdZ7jH8_6F0CA8c_ussf0MMoeKVtPabByLGblUomw7z-ZSmpLzjmq_g5HzCnAVut_Q_s9RcaOG-5n78dfP6Uf4mudJLC-Tvq1Ou_UBUQHR8A7ThRBx-FfG9gqPrdYW'
}
#通过循环爬取后面10页
for page in range(0,10):
url=f'https://movie.douban.com/subject/1291549/comments?start={page}&limit=20&status=P&sort=new_score'
res=requests.get(
url=url,
headers=header,
).text
selector=parsel.Selector(res)
comment_list=selector.css('.comment-item')#使用css语法获取所有评论
# 利用循环爬取整个页面
for comment in comment_list:
name = comment.css('.comment-info a::text').get().strip()#姓名
short = comment.css('.short::text').get().strip()#评论
time = comment.css('.comment-time::text').get().strip()#时间
vote_count = comment.css('.votes.vote-count::text').get().strip()#点赞数量
print(name,short,time,vote_count)
#保存到文件中
with open('放牛班的春天.csv',mode='a',encoding='utf-8',newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow([name,short,time,vote_count])
print("下载完成")三、总结
我们需要对网页的代码有一定的了解,方便我们寻找需要的代码块,请使用在正当途径上。
希望这篇博文能对你有所帮助!















 3861
3861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









