







摘要:tcp就是乘性加,然后加性加接近最大码率。BIC优化了,变成折半加,不是加一个rtt,这样加的速度变快,同时进入下一周期做了图形对称。cubic完全根据bic的图形,将图形转成代数,带入3个关键点,得到参数,这样得到了曲线的代数式.
Cubic算法是基于丢包的拥塞控制协议.发展路线是Reno tcp->Ibc->Cubic.
在reno版本的拥塞控制下,进入拥塞避免状态或快速恢复状态后,每经过一个RTT才会将窗口大小加1,那么问题来了,假设我们链路状况好,但如果RTT很长的话,reno不就要很长时间才能达到最佳拥塞窗口了吗?
TCP reno:慢启动,3次拥塞避免(3个ack),RTO(快速重传即进入慢启动).ssthresh是丢包的位置.
BIC就是为了解决这个问题.因为BIC的核心思想就是通过二分搜索的思想来找到当前链路最合适的拥塞窗口,下面我们来详细阐述下BIC算法的主要流程。
BIC算法流程(BIC-TCP(Binary Increase Congestion control))
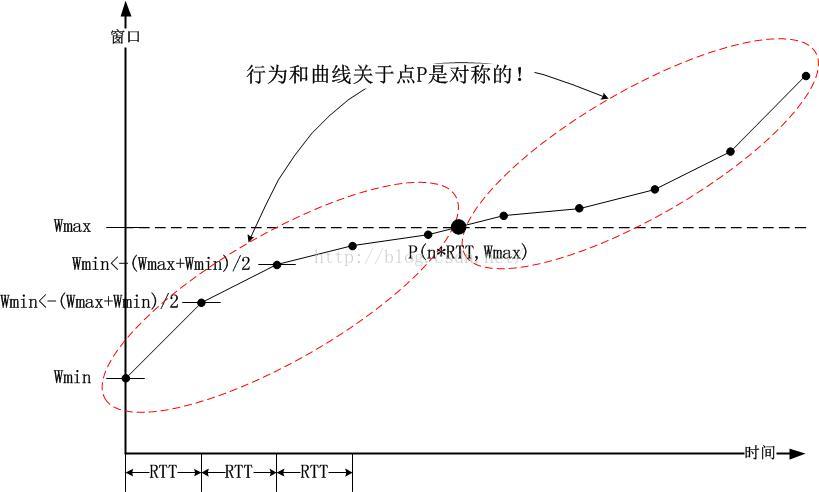
注意:Wmin=(Wmax+Wmin)/2,表示二分法查找
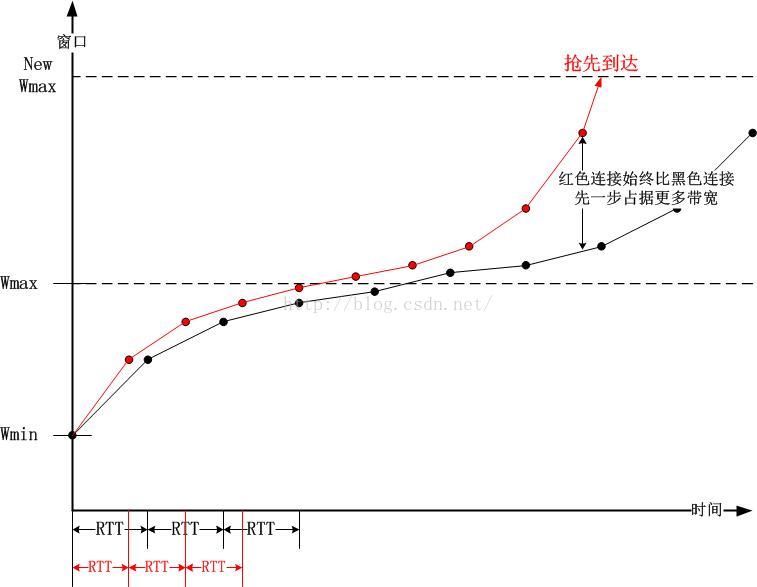
两个RTT不同的连接,其通过BIC算法搜索到Wmax的时间是不同,进而其进入Max-Probe阶段也是不同的,因此空闲的带宽会被RTT短的那个连接无情的占有:
显然,当前链路在网络上因为排队而发生丢包时,链路的当前最佳拥塞窗口肯定是小于丢包时的拥塞窗口的,我们称丢包时的拥塞窗口大小为Wmax,同样,BIC也采用乘法减小的方式减小窗口,我们称这个因子为,同时,我们称减小后的窗口为Wmin,则有Wmin=*Wmax,我们认为乘法减小后的窗口应该是小于最佳拥塞窗口的,因此,对于链路当前最佳拥塞窗口W来说,我们有Wmin<W<Wmax,reno采用加法去搜索W的方式实在是太慢了,因此BIC采用了二分搜索的方式去找到这个W,二分搜索的具体流程就不赘述了,我们来看看这么做的好处,首先我们来看下BIC的拥塞窗口图像:
我们看虚线左边的图像,也就是加法增窗(Additive Increase),二分搜索(Binary Search)的过程,整个增窗流程趋近一个凸函数的左半边,这样带来的好处是:越接近Wmax附近,窗口的增加速度越慢,这也就意味着,在一次经历了一次丢包后,窗口会更快的接近W,并在W附近停留更多的时间(对比reno的锯齿形图像可以有更明显的感觉)。当然你可能会觉得,W如果在Wmin附近呢?不是更快超过了吗?如果你产生了这样的疑问,你需要明确一个观点,对于整个网络来说,我们需要的是最终的收敛,而不是一次的收敛,网络拥塞丢包的大部分情况是,当前网络中所有的连接占满了带宽,此时有一个新链路加进来,那么新链路争抢资源过程则势必会引起丢包,合适的做法应当是,现有的各条链路让出部分资源,让新的链路可以和旧链路一样公平的拿到其应得的资源。所以,我们需要的是最终收敛,所有链路快速且公平的拿到带宽资源,因此,我们衡量一个拥塞控制算法的优劣时,会看他的收敛速度,公平性。回到刚才的问题上来,W如果在Wmin附近也并不影响,BIC会快速进入到下一次增窗过程中去,然后达到最终收敛。
再来看虚线右边的图像,这个过程被称作最大窗探测过程(Max Probing),顾名思义,这个过程就是在探测当前合适的最大窗口,为什么要设计成这样呢?BIC算法的设计者认为,当窗口Wmax超过以后,如果还未发生丢包,则说明网络变好了,或者有部分链接让出了资源,那么我们要尽可能的去抢占他,首先我们先慢慢的尝试,然后越来越快,以保证整个网络资源的利用率,因此Max Probing被设计为虚线左边的旋转对称的模样。当然,Max Probing的增窗过程真的合理吗?它确实保证了快速收敛,但对于其公平性(相对于tcp_reno,网络上会同时存在大量拥塞算法),可能要打一个问号。
关于BIC,这里再说一些细节上的东西,出于工程实现和现实应用的考虑,在窗口调整过程中设置了一个Smax及Smin的阈值,当窗口的增量大于时,增量则设为,当窗口增量为时,则将当前窗口设为Wmax,也就是说窗口已经通过二分搜索达到了最大值,可以开始Max Probing阶段了,具体原因很好理解,不赘述了。
Cubic:
通过用三次函数(包含凹和凸部分)代替BIC-TCP的凹凸窗口生长部分,大大简化了BIC-TCP的窗口调整算法
数学推导: 谁的导数是慢慢变小,变成0后再慢慢变大的呢?(由图形转为代数)
二次曲线:

然后画出其图形后发现它可以完美诠释BIC窗口探测曲线的斜率走势:

这条导数曲线对应的原始曲线就是一条3次曲线:(对二次函数取积分)
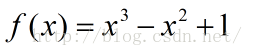
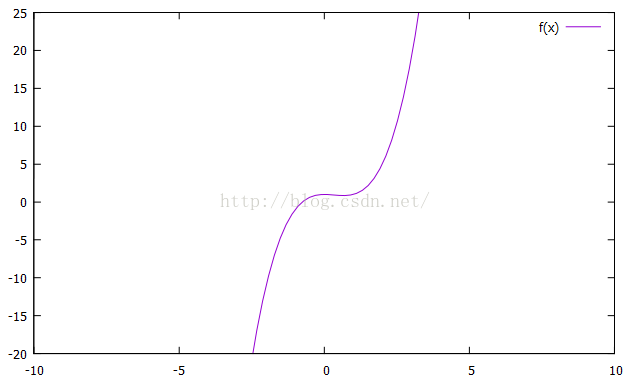
以上这个仅仅是个例子,我们的目的在于确定CUBIC的曲线形状,是的,最终的CUBIC曲线就是这样子的,是不是跟BIC的窗口探测曲线很像呢?
确定了曲线的形状之后,最终我们要确定曲线的参数,最终曲线的方程应该是:
完成确定待定系数这一步,我们就可以彻底理解CUBIC那看似复杂的方程式背后的所有了。
我们观察最终的曲线,发现横轴中点位置正好在纵轴到达Wmax,再看曲线的左界,当曲线在初始的时刻,W从快速恢复的结束位置开始增长,即ssthresh这个值的位置:这个位置,就是beta*Wmax
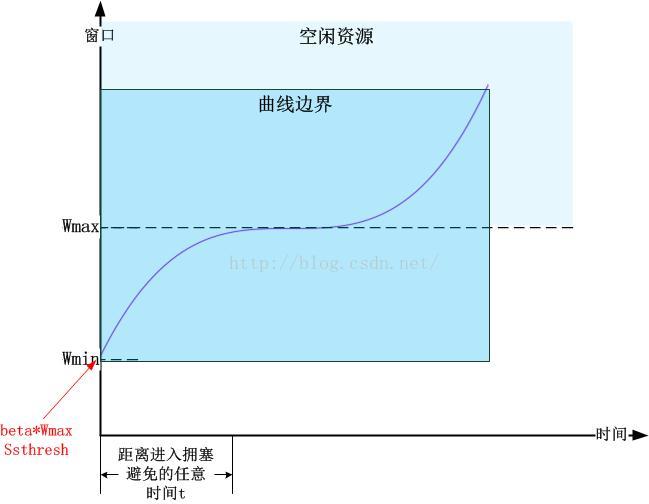
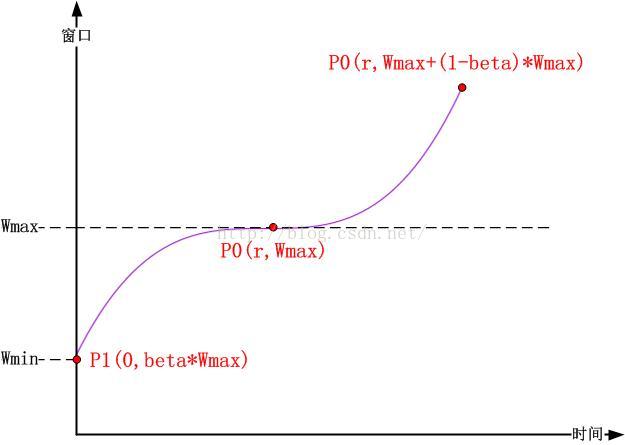
注意到曲线上有三个点是特殊的,如下图所示:
下面的推导,理解为向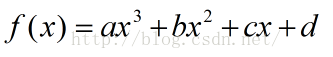
并且注意到曲线本身是关于P(x=r,y=Wmax)这个点对称的,我们确定曲线方程的常数因子就是Wmax。因此,我们可以简单的将曲线方程写成以下的形式:
现在的目标就是求h(x)。
注意到另外两个点对曲线的约束,从曲线关于点P(r,Wmax)对称,我们可以得知:


以及
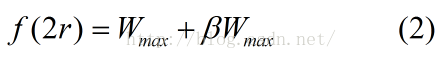
其中
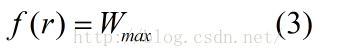
由以上三式(1),(2),(3)以及(0)得知:
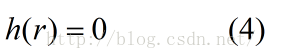
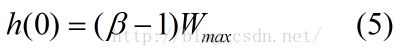
由(4),(5),我们可以构造出h(x)的一个合理形式:
根据上述的(4)和(5),我们得到r的表达式:
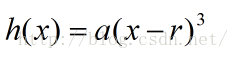
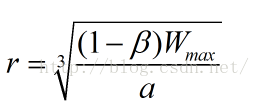
##不得不承认以上是一个很合理的解
到这里,你可能觉得这越来越复杂了,但事实上,这推导非常简单,而且,推导结束了,这就是CUBIC的最后结果!我们把上式中的系数a换成C(CUBIC的 Paper上写的就是C,另外,r也要换成K...),那么最终的式子就是:
OK!结束了。现在我们来看下这个式子里面的两个参数beta和C,分别代表什么,或者更加形象的,它们分别控制着什么。
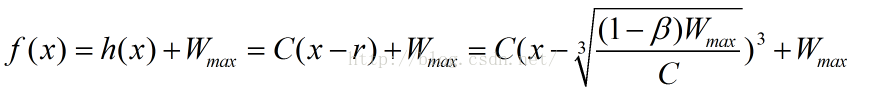
对于一次从快速恢复结束的时刻到丢包的拥塞避免过程,我们假设发生丢包时的窗口大小为Wmax,并且假设网络中没有别的连接,那么窗口探测曲线在每一轮拥塞探测过程都是相同的,因此,我们认为Wmax是常数。(Wmax理解为丢包开始的时刻)
非常显然,beta决定了整个曲线对称范围围成区域的高度,而r则控制了从起始窗口到达丢包窗口的时间,由于r与C成反比,那么C越大,则探测到最大窗口的时间越短,反之则越久。(参见上面红黑两个RTT比较图)
由此,我们只要控制beta和C两个参数,就能控制CUBIC算法的行为了。
现在知道CUBIC曲线的细节了吗?好吧,我们一直在数学公式里徘徊,现在终于要回到TCP了!我们看一下曲线中的beta和a(也就是C)分别影响了TCP的什么特性,正如CUBIC的 Paper上所述:
beta控制了TCP Friendliness;Can控制了TCP的收敛速度
小结:引自网络:Cubic比Bic强在不用rtt探测
CUBIC 使用一个三次函数代替了BIC 中的窗口探测曲线,在CUBIC 中窗口的增长依赖于发生两次拥塞事件之间的时间t ,达到独立于RTT 来避免BIC 算法出现的问题,并且当RTT 较小的情况下CUBIC 能够使其与标准的TCP 协议很好兼容。
疑问:由于CUBIC曲线在稳定拥塞避免阶段(Steady State)和空闲资源探测阶段(Max Probing)是对称的(凸曲线的后一半和凹曲线的前一半),因此我们把收敛速度理解成两个方面:
一方面,它决定了在稳定的拥塞避免阶段TCP的拥塞窗口到达最大窗口的时间.
另一方面,它在空闲资源的探测阶段又决定了探测到新的最大窗口所需的时间。这种对称的行为,它真的合理吗??
notes:之前我也有这个疑问,加性增加接近最大值可以理解。之后,更应该小心探测了哈,很可能增大不了多少,Wmax都是加性增加的哈。
引用自网络:"对于整个网络来说,我们需要的是最终的收敛,而不是一次的收敛,网络拥塞丢包的大部分情况是,当前网络中所有的连接占满了带宽,此时有一个新链路加进来,那么新链路争抢资源过程则势必会引起丢包,合适的做法应当是,现有的各条链路让出部分资源,让新的链路可以和旧链路一样公平的拿到其应得的资源.
CUBIC将BIC的二分搜索过程和Max Probing以公式的形式独立出来,剥离了其对RTT的依赖,同时这也大量减轻了代码负担,一个公式就全部搞定了"
个人理解:实际设计的意思是,这个周期的码率需要凸函数尝试到Wmax,但是过了Wmax说明是新码率,新码率需要快速探测,快速探测之后。
Tcp网络最常用的场景就是,新用户加入,所有用户网速折半,全都重新探测,这样具有公平性.
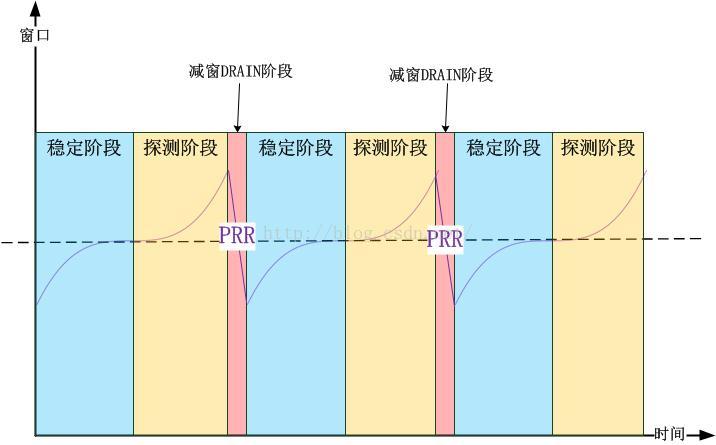
最后,我将CUBIC的算法运行和通用的TCP拥塞控制算法进行映射,我发现它毫不特殊,运行CUBIC算法的TCP连接,也分别会将运行阶段映射为三个阶段中的一个.
- 稳定阶段(Steady State),即不丢包的阶段.
- 新空闲资源探测阶段,即探测新最大窗口的阶段(Max Probing).
- 以及公平收敛阶段,即减少数据发送量的阶段(类似PRR降窗过程).
和bbr不同的是,CUBIC的公平收敛阶段不是自己算法控制的(PRR),而bbr则是自己控制的(默认运行1个周期,其后持续运行6个恒稳周期,bbr的周期是一个伺服循环:1个Max Probing-1个Drain-6个Steady State-...)。CUBIC的总体运行如下图所示:
后记
BIC算法呢?收到ACK包后执行二分查找驱动的一个过程而已。
bbr算法就是其行为本身的描述,而CUBIC算法则是借用了一条数学上很优美的曲线方程,这条3次曲线并不关联任何TCP的行为,换句话说,如果有更好的选择,也可以不使用这条曲线。这一点与ECC算法(椭圆曲线加密算法)的背景十分不一样,ECC算法脱离不了椭圆曲线,正是在该曲线上的群,环,域的计算定义了整个算法过程。区别这两点,对于优化CUBIC是十分重要的。
附1:优化和灵活性
优化,根据丢包预判网速可能高还是低一些,以决定是加性还是乘性增加
既然TCP拥塞算法是借用了一条3次曲线,那么这条曲线就不是必须的!仔细观察本文最后的那幅图,和BIC算法一样,CUBIC算法在稳定阶段和探测阶段是对称的,但是非得这样吗?
如果我明明知道在探测到Wmax的时候已经近乎拥塞,那CUBIC曲线还傻傻的去猛往上探测直到丢包,这样还合适吗?显然是不合适的。因此我们可能需要一条不对称的CUBIC曲线!比如在稳定阶段陡一点,在探测阶段缓一点,这可能最终会进化到bbr算法类似的效果!
但是,我真的需要另外一条曲线吗??完美主义者或者数学洁癖者可能特别希望用一个方程式描述这种不对称的曲线,但如果仅仅想在工程上实现这个理念,完全没有必要去寻找什么曲线,直接使用不对称的曲线即可。
我不再深入阐述这个话题,我只展示一下Linux CUBIC的代码之修改.对bictcp_update进行修改:
curr_C = cube_rtt_scale;
// base_mdev的含义是,刚进入拥塞避免稳定状态时的mdev,而curr_mdev则是当前的mdev
if (ca->base_mdev && ca->curr_mdev && t > ca->dragon_K) {
if (ca->curr_mdev > ca->base_mdev) // 如果RTT变得比较更加抖动,说明丢包可能性比较大
curr_C >>= 1; // 仅为一例,旨在伸展曲线宽度
if (ca->base_mdev < ca->curr_mdev)
curr_C <<= 1; // 旨在压缩曲线宽度
}
delta = (cube_rtt_scale * offs * offs * offs) >> (10+3*BICTCP_HZ);小结:
CUBIC曲线由参数确定。(用数学公式替换BIC设计结果)
BIC曲线由行为确定。(根据tcp网络乘性加和加性加画图)
BIC/CUBIC的收敛靠事件触发,bbr收敛靠自身伺服机制触发(基于丢包,基于延时)
CUBIC源码在linux内核














 6231
6231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









