






基础资料
书生浦语整个系列做得非常棒,从数据(书生万卷)、训练(xtuner)、部署(LMDeploy)、评测(OpenCompass)、应用(Lagent),为用户提供了一整套完整的开源开放生态系统。
IntermLM是由上海人工智能实验室与商汤科技共同开发的大语言模型。从模型微调到部署,官方提供了详尽的文档,我结合官方提供的tutorial,在此分享我的经验。
InternLM: A Multilingual Language Model with Progressively Enhanced Capabilities
Paper URL: https://github.com/InternLM/InternLM-techreport/blob/main/InternLM.pdf
Project URL: https://internlm.org/
Code URL: https://github.com/InternLM/
Tutorial: https://github.com/InternLM/tutorial/
huggingface:https://huggingface.co/internlm
前置知识
Chat Format(对话模板/对话格式)
要训练出大语言对话模型,模型的数据输入需要遵循一定的格式,这样模型才能够区分出哪些是用户说的话,哪些是模型回复的话。
首先从openai的对话模板开始说起。ChatGPT的训练可以大致划分为下图所示的若干个阶段。在预训练(Pretraining)阶段,模型使用的训练数据仅为纯文本,其核心任务是基于上下文预测接下来的token。随后的阶段,为了赋予模型对话的能力,便需借助对话类型的数据集进行进一步训练。这类对话数据通常涵盖了多个角色的文本交互。OpenAI创建了Chat Markup Language(简称ChatML),就是为了将不同角色的内容有效地拼接起来。

这是openai官方提供的一种chat格式示例:

可以看到有三种角色:system、user、assistant
system prompt是系统级提示词,该内容会在整个会话过程中持久地影响模型的回复,且相比于普通 Prompt 具有更高的重要性。我们一般设置 System Prompt 来对模型进行一些初始化设定,例如,我们可以在 System Prompt 中给模型设定我们希望它具备的人设如一个个人知识库助手等。System Prompt 一般在一个会话中仅有一个。在通过 System Prompt 设定好模型的人设或是初始设置后,我们可以通过 User Prompt 给出模型需要遵循的指令。
user代表的是用户输入的内容,即用户与模型交互时所输入的对话文本。
assistant则是代表模型本身的回应,它根据用户的输入和系统的前置设定,进行相应的回复和互动。
在深度学习的对话系统中,<|im_start|>和<|im_end|>扮演着特殊标记(special tokens)的角色。在模型的分词器(tokenizer)执行编码过程中,这些特殊标记会被转换为相应的独立的token标识符(token id),它们具体用于指示一个角色发言的开始(start)和结束(end)。
然而,假设这些特殊标记<|im_end|>出现在实际的对话文本中,的确可能会引起模型的混淆。为了避免这种情况,可能成为注入攻击的一部分,OpenAI的处理机制很可能会在输入文本中剔除这些<|im_start|>和<|im_end|>特殊标记,从而保护模型不受到意外的干扰。
以下是我尝试的一些例子:

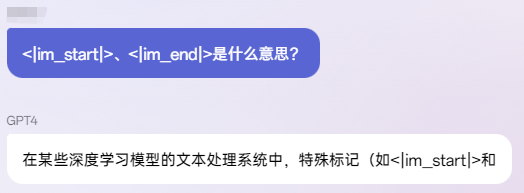
模型似乎想继续回答<|im_end|>,但是当它试图输出<|im_end|>时,会将<|im_end|>判定成回答结束的标志,因此回答戛然而止。
llama2的对话模板和openai的不同。其对话格式如下:
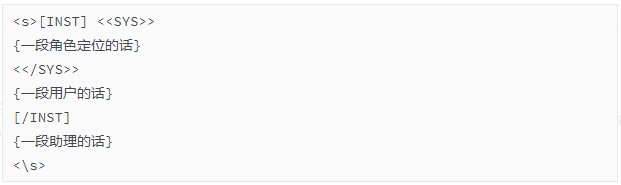
说明:
<> System上下文开始
<> System上下文结束
[INST] user指令开始
[INST] user指令结束
参考资料:
openai提出的chatML(Chat Markup Language):
https://github.com/openai/openai-python/blob/release-v0.28.0/chatml.md
聊聊ChatGPT是如何组织对话的 - CompHub的文章 - 知乎
https://zhuanlan.zhihu.com/p/640503292
不得不说的Chat Format(聊天格式)——大模型CPU部署系列03 - 引线小白的文章 - 知乎
https://zhuanlan.zhihu.com/p/666461139
从奶奶漏洞到 Prompt injection:指令注入攻击 - 段小草的文章 - 知乎
https://zhuanlan.zhihu.com/p/647162002
书生浦语提出的format
官方说明:https://github.com/InternLM/InternLM/blob/main/chat/chat_format_zh-CN.md
InternLM2-Chat 采用的对话格式和openai的ChatML类似:

在InternLM稍旧的版本中,采用如下的格式:
<|System|> :System上下文的开始
<|User|> :user指令的开始
<|eoh|> :user指定的结束(end of human)
<|Bot|> :assistant开始回答
<|eoa|> :assistant回答结束(end of assistant)
由于我在稍旧的版本中跑InternLM模型,因此下文中的格式以稍旧的版本为准。
快速上手推理流程
加载InternLM并对话
包导入:

加载intern模型(从hf下载,下载下来的模型需要从cache导入):
tokenizer = AutoTokenizer.from_pretrained("internlm/internlm-chat-7b", trust_remote_code=True, cache_dir='.../Intern-models-dirs')
model = AutoModelForCausalLM.from_pretrained("internlm/internlm-chat-7b", trust_remote_code=True, cache_dir='.../Intern-models-dirs').cuda()
或者加载intern2模型(从ms下载,下载下来的模型,直接传入下载路径即可):
tokenizer = AutoTokenizer.from_pretrained('.../Intern-models-dirs/Shanghai_AI_Laboratory/internlm2-chat-7b', device_map="auto", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained('.../Intern-models-dirs/Shanghai_AI_Laboratory/internlm2-chat-7b', device_map="auto", trust_remote_code=True)
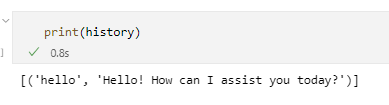
推理(多轮对话):
response, history = model.chat(tokenizer, "hello", history=[])
response, history = model.chat(tokenizer, "please provide three suggestions about time management", history=history)
注:
internlm/internlm-chat-7b的参数量是7321948160
internlm/internlm2-chat-7b的参数量是7737708544
通过lmdeploy来实现对话
下面的代码需要通过python文件来跑,在ipynb(jupyter)下不行:

intern多模态模型

torch.set_grad_enabled(False)
model = AutoModel.from_pretrained('internlm/internlm-xcomposer-7b', trust_remote_code=True, cache_dir='.../Intern-models-dirs').cuda().eval()
tokenizer = AutoTokenizer.from_pretrained('internlm/internlm-xcomposer-7b', trust_remote_code=True, cache_dir='.../Intern-models-dirs')
model.tokenizer = tokenizer
纯文本推理:
text = 'Please introduce Einstein.'
response = model.generate(text)
print(response)
图文生成:
text = '解释这张图片.'
image = '.../aigc/intern/test_img/1.jpg'
response, history = model.chat(text, image, history=None)
print(response)
XTuner实战——通过内置配置来微调
参考资料
github的readme:https://github.com/InternLM/InternLM/blob/main/finetune/README_zh-CN.md
tutorial:https://github.com/InternLM/tutorial/blob/main/xtuner/README.md
视频:https://www.bilibili.com/video/BV1yK4y1B75J/?vd_source=00adbfc66f6b0ae40a7ad4e7bfad9525
前置准备——安装xtuner包
方法一(我的方法):
pip install -U 'xtuner[deepspeed]>=0.1.13' -i https://mirrors.aliyun.com/pypi/simple/
我下载下来的版本是0.1.13
方法二:
把xtuner的github仓库down下来,然后通过pip install -e的方法来安装。
训练流程——第一步:确定配置文件
第一步,确定好本次微调的模型、方法、数据集等基本信息,从intern官方提供的配置文件列表中,选定对应的配置文件(如果没有官方的配置,则需要自定义。后面会说到这个问题)。
下面的命令可以查看所有内置的官方配置:

可以看到支持很多主流的开源模型,包括qwen/baichuan/chatglm/llama/llava等
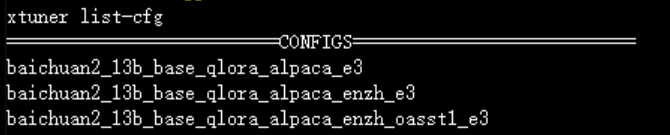
base:base模型
qlora:使用Qlora微调方法
alpaca:微调数据集
e3:3个epoch
假如我现在想要微调internlm_chat_7b,那么需要把对应的配置文件copy到当前的数据集的路径(.../aigc/intern/xtuner-main/ft-oasst1)中
配置的命令是:

这个文件名表示,我们对internlm_chat_7b模型来微调,微调方法是qlora,微调数据集的格式是oasstl数据集的格式,微调的epoch是3。
下面对该文件进行分析:
该文件包括五个部分
PART 1 Settings
参数的定义:包括模型、数据集路径、Scheduler & Optimizer
PART 2 Model & Tokenizer
配置Model和Tokenizer的参数
PART 3 Dataset & Dataloader
配置train_dataset和train_dataloader的参数
PART 4 Scheduler & Optimizer
配置Scheduler和Optimizer的参数
PART 5 Runtime
其他配置,比如hook
对此本任务,主要是修改模型和数据集的路径。
训练流程——第二步:准备数据集并修改配置文件
官方的tutorial使用的是timdettmers/openassistant-guanaco数据集。
数据集下载路径:
https://huggingface.co/datasets/timdettmers/openassistant-guanaco?row=0
这个数据集是Open Assistant数据集的子集。Open Assistant数据集是一个人工生成的、人工注释的辅助风格对话语料库,由35种不同语言的161443条消息组成,注释了461292个质量评级,产生了超过10000个完全注释的对话树。该语料库是涉及13500多名志愿者的全球众包活动的产物。
本次使用的数据集是一个子集,train部分一共有9846条数据,test部分一共由518条数据。
但是我对这个数据集存在疑问,以下两个截图是我从huggingface官网截取的图片。第一个截图选中的数据是恶意的脏数据,第二个截图的数据看起来不完整。

数据集下载到openassistant-guanaco文件夹里。如下图所示,work_dirs是训练过程中生成的文件夹。py文件是刚刚复制的配置文件(internlm_chat_7b_qlora_oasst1_e3_copy.py),我们需要修改这个文件,主要是修改数据集和模型的路径。
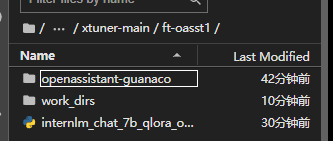
在这个配置文件里,还定义了两个问题:evaluation_inputs = ['请给我介绍五个上海的景点', 'Please tell me five scenic spots in Shanghai']
在经过了自定义的迭代步数后,模型会针对这两个问题输出一个回答,以供研究人员直观地感受到模型的训练效果。
训练流程——第三步:启动训练
在命令行启动命令:

每隔一段时间会输出两个test数据的预测结果。
下图是第一次的输出,这是在模型开始训练之前输出的,可以看到针对中文的回答不完整:
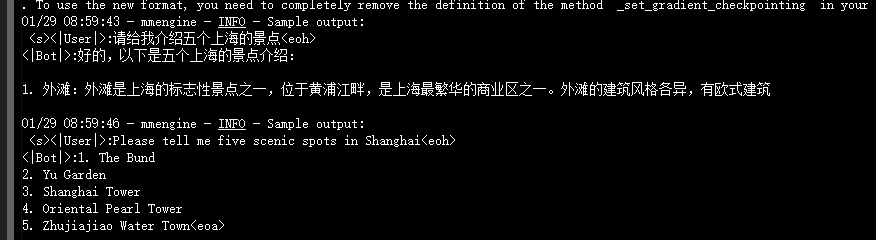
这是经过了一定的训练后,第二次的输出:

启动训练后显存占用的结果:
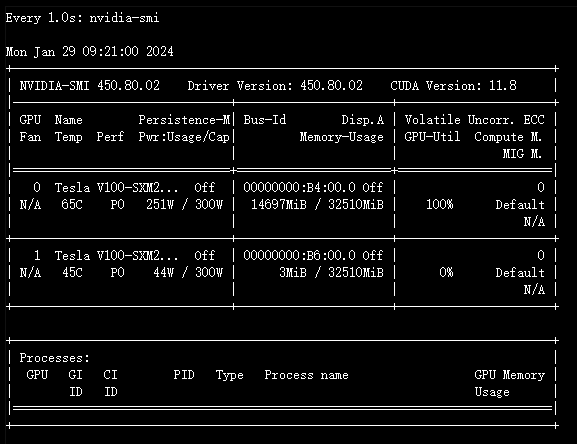
我使用的是internlm-chat-7b模型,是用QLoRA来训练的,load_in_4bit=True。一个参数占用了4bit的内存,那么整个模型应该占用了大约3.5G显存。总占用的显存是14.6G左右,这些显存包括LoRA分支、梯度、优化器状态、中间激活层的输出。
这是每一个iter之后的输出日志:
01/29 09:38:41 - mmengine - INFO - Epoch(train) [1][ 10/2165] lr: 2.8573e-05 eta: 1:40:37 time: 2.8018 data_time: 0.0050 memory: 12273 grad_norm: 0.0717 loss: 1.2244
其中,Epoch(train) [1][ 10/2165] 表示当前在第一轮,一共有2165个批次,当前处于第10个批次
注意,训练数据集一共有9843条,然后我设置的batchsize=1。为什么这里是2165呢?因为在配置文件里我设置了pack_to_max_length = True,这个参数的意思是允许多条数据拼凑在一起(在允许的最大的训练长度下)
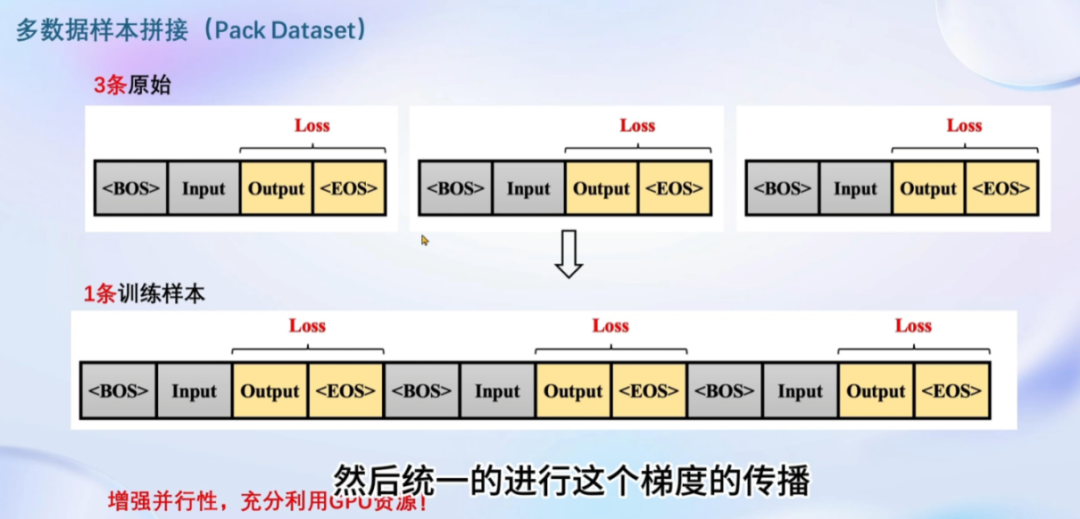
如果设置为False,那么一轮的总迭代步数就变成9843了,而且训练时间也变长了。我猜测的原因是:首先batchsize变小了,一般来说,batchsize越小,训练时间越长。因为每次iter启动训练需要耗时间,batchsize减小,iter数量将会增多。而且较大的batchsize可以充分利用GPU并行运算的优势。除了batchsize变小的原因,第二个原因是多条数据拼凑在一起,数据几乎统一到相同的长度,可以让数据量“减小”,有助于更进一步充分地利用资源。
如何结合deepspeed来训练?
启动命令:
xtuner train internlm_chat_7b_qlora_oasst1_e3_copy.py --deepspeed deepspeed_zero2
启动后,显存占用稍微变小了(12G)
控制台输出:
01/29 09:48:33 - mmengine - INFO - Epoch(train) [1][ 10/2167] lr: 2.8127e-05 eta: 1:16:34 time: 2.1299 data_time: 0.0049 memory: 11027 loss: 1.3042
可以看到剩余时间也减少了
细节1:如何debug训练代码?
上面已经说了在命令行的启动命令:

如果我想在vscode去debug,应该怎么做?
xtuner是一个通过pip安装的Python包,并且它提供了一个命令行接口(CLI),但VSCode的调试器需要直接运行一个Python脚本而不是命令行命令,那么你需要找到xtuner的入口点脚本。通常,当一个Python包安装了命令行工具时,它会在Python的Scripts目录(Windows上)或bin目录(Unix-like系统上)中创建一个可执行文件。
第1步,通过which xtuner命令找到xtuner命令行工具的安装位置:"/opt/conda/envs/transformers2/bin/xtuner"
第2步,在VSCode的launch.json配置文件中,将program参数指向此脚本。示例如下:

第3步,运行debug。但是注意,VSCode中的调试配置config.json是依赖于当前打开的工作区的。
如果我想从头开始debug,想知道xtuner命令里面有什么过程,应该怎么办呢?
下面是xtuner文件(位于/opt/conda/envs/transformers2/bin/)的代码:
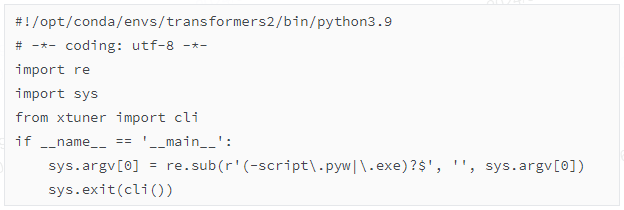
这个脚本是一个封装了 xtuner 库中的 cli 函数的命令行工具。这样的脚本通常是作为命令行界面的入口点,通过命令行执行 xtuner 命令来启动。
cli函数在哪里?第一种方法是,我需要去xtuner包所在的路径(/opt/conda/envs/transformers2/lib/python3.9/site-packages/xtuner)去寻找。我发现该路径里有一个 entry_point.py 文件 ,通常,名为 entry_point.py 或类似的文件会作为包的主入口点,尤其是当这个包提供命令行工具时。
第二种方法比较简单,在xtuner文件里打断点,然后可以自动定位到cli函数所在的位置。(也不一定,我用这种方法去逐行调试,各种文件之间跳来跳去,把我跳晕了)
接着可以看到,函数调用了源码中的train.py,其路径为:
/opt/conda/envs/transformers2/lib/python3.9/site-packages/xtuner/tools/train.py
这个函数定义了训练的流程。
这个函数的第一步,是加载了配置文件,即internlm_chat_7b_qlora_oasst1_e3_copy.py
具体的训练流程,则是调用了runner.py(位于MMengine包里),在runner.py里的train函数里,真正执行了训练的流程。
(也就是说,整个流程的顺序是:xtuner--entry_point.py--train.py--runner.py)
位于/opt/conda/envs/transformers2/lib/python3.9/site-packages/mmengine/runner/runner.py中的train函数中的这行代码真正执行了训练的流程:

点进去run()的源码,可以看到它经过了封装:


细节2:如何从原始数据的格式转成huggingface中的dataset格式?
上面提到,微调的整个流程的顺序是:xtuner--entry_point.py--train.py--runner.py
runner.py中的train函数负责训练的具体流程。其中,这个函数里有一条代码:

这行代码的作用是加载数据,self.build_train_loop会跳到loops.py和base_loop.py里,但是最终又会跳回runner.py。
具体将json文件改成模型需要的格式的地方,位于runner.py中的build_dataloader函数。
首先,关于dataloader的配置是这样的:

解释一些参数(下面的内容由GPT生成):
'num_workers': 数值为0,指定在数据加载时用于数据预处理的工作进程数量。0通常意味着所有数据加载将在主进程中完成。
'dataset': 这是一个嵌套的字典,包含训练数据集加载和处理的配置:
'type': 可能是数据加载函数或类的名称,这里是 process_hf_dataset。
'dataset': 包含数据集相关的配置,它本身又是一个嵌套字典:
'type': 指数据集加载函数或类的名称,这里是 load_dataset。
'path': 数据集的路径或名称,这里是 ./openassistant-guanaco。
'tokenizer': 包含分词器(tokenizer)相关配置的字典,用于文本处理和编码:
'type': 可能是加载分词器的函数或类的名称,这里是 from_pretrained。
'pretrained_model_name_or_path': 预训练模型的名称或路径。
'trust_remote_code': 布尔值,是否信任远程提供的代码。
'padding_side': 字符串,指定填充的一侧,这里是 'right'。
'cache_dir': 缓存目录的路径,用于存放下载或处理后的数据。
'max_length': 数值为2048,指定处理后的文本序列的最大长度。
'dataset_map_fn': 指定应用于数据集条目的映射函数的名称。
'template_map_fn': 又是一个嵌套字典,相关于模版映射函数配置:
'type': 映射函数或工厂函数的名称,这里是 template_map_fn_factory。
'template': 应该是用于数据映射的模版名称。
'remove_unused_columns': 布尔值,指定是否在数据集对象中移除不使用的列。
'shuffle_before_pack': 布尔值,数据打包前是否进行随机混洗。
'pack_to_max_length': 布尔值,指定是否将文本打包到最大长度限制。
'sampler': 决定从数据集中抽样批次的方式:
'type': 指定采样器的类或函数名称,这里是 DefaultSampler。
'shuffle': 布尔值,指示在每个epoch开始时是否对索引进行随机混洗。
'collate_fn': 在通过数据加载器(DataLoader)加载批次时用于合并单个数据条目的函数:
runner.py中的build_dataloader函数负责生成dataloader,生成dataloader的依据就是上面的关于dataloader的配置。此外,还有一些函数的调用,不在这里展开。
经过debug发现,位于/opt/conda/envs/transformers2/lib/python3.9/site-packages/xtuner/dataset/huggingface.py中的process函数负责加载数据。
在huggingface文件中,完成了从初始数据到dataset格式的转变,有以下几个关键步骤。
【关键步骤1】首先,下面这一行代码负责加载数据:

加载出来的dataset如下:

等价于

openassistant_best_replies_train.jsonl数据本身的格式是{"text": "### Human:...### Assistant:..."},可以被load_dataset识别
【关键步骤2】dataset_map_fn映射。
作用:把初始数据文件中的{"text": "### Human:...### Assistant:..."}改成{"text": "### Human:...### Assistant:...","conversation":[{'input': '...', 'output': '...'}]}的格式。
下面这一行代码负责将dataset做格式变换,将dataset_map_fn函数应用到dataset数据集的每个样本上。

这里的dataset_map_fn=oasst1_map_fn,是在一开始的配置文件里定义好了的。
在源代码中的xtuner/dataset/map_fns/dataset_map_fns路径下,有十几个已经定义好了的内置的map方法,包括了一些著名的数据集,比如alpaca_map_fn.py
对了,debug的时候学到了一个小trick,如果我不知道某个函数的源代码,只知道函数名称,而且不想去源代码里找的话,可以试试
print(inspect.getsource(dataset_map_fn))
Python内置的inspect模块可以帮你检查源代码。
oasst1_map_fn函数的源码见附录,调试细节就不放出来了。我在linux上跑整个流程的时候,发现一直没有办法debug进去map里的函数。我在本地电脑单独把这部分代码拎出来,发现是可以debug进去的。暂时不知道是什么原因。
经过map后,数据的格式如下:
[{'input': 'Напиши функцию на яз...о на экран', 'output': 'Вот функция, которая...удь ещё? 😊'}]
也就是说,这个dataset_map_fn步骤,把{"text": "### Human:...### Assistant:..."}改成{"text": "### Human:...### Assistant:...","conversation":[{'input': '...', 'output': '...'}]}的格式。
如果是多轮对话,则这个列表将会有多个字典,也就是说,这个列表的每个元素都是一次对话。
【关键步骤3】template_map_fn映射:

之前说到,送进模型的数据需要遵循一定的对话模板。在上一步骤中输出的对话格式并没有加入<|User|>这样指示角色名的信息,并不能直接输入到模型中。
在intern模型的这个版本中,模板如下所示:

对了,这里的template_map_fn是一个functools.partial 对象 ,在Python中,functools.partial 对象本质上是一个类似函数的对象,但它并不是一个标准的函数或方法,也没有一个明确的代码对象 。
需要使用print(inspect.getsource(template_map_fn.func))来获取源码,而不是print(inspect.getsource(template_map_fn))
dataset_map_fn有多种,不同的数据集有不同的map方法。但是template_map_fn只有一个,因为intern模型只认一种对话模板。(当然自定义改成其他模板也可以,需要重新训练)
template_map_fn的源码路径是xtuner/dataset/map_fns/template_map_fn.py
template_map_fn函数的源代码见附录。调试细节就不放出来了,和关键步骤2一样,我单独拎出来在本地是可以debug的。
经过template_map_fn前:

经过template_map_fn后:

也就是说,本步骤的作用是加入诸如<|User|>这样指示角色名的信息。此外,还添加了'need_eos_token'和'sep'两个关键字
【关键步骤4】encode_fn映射(分词、编码):
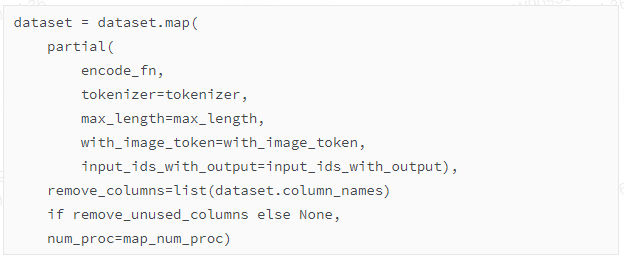
在这里完成分词,从{"text": "### Human:...### Assistant:...","conversation":[{'input': '...', 'output': '...'}]}的格式改成模型能够理解的格式:{"input_ids": "..."."labels":"..."}
encode_fn函数位于xtuner/dataset/utils.py里,应该和template_map_fn一样,对于intern模型,只有这一个encode_fn函数。以下是该函数的docstring:

可以看到,函数支持处理三种不同的对话数据集场景:增量预训练数据集、单轮对话数据集、多轮对话数据集。
intern模型分词器的基本信息如下:
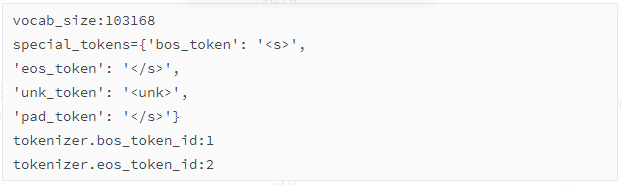
encode_fn函数的源代码见附录。和关键步骤2/关键步骤3一样,我单独拎出来在本地是可以debug的。
encode_fn函数是对每个example的'conversation'来做处理,其中某个数据(第一条数据,也是俄文数据)的格式如下:

接下来分析具体是如何分词的。
第(1)步:对问题(即俄文数据中的'input')分词
下面这行代码是对'input'来做分词,可以看到模板(比如<|User|>)也被分词了(当然,这是肯定的,因为所有的字符串都要经过分词,变成整数的格式)

但是,<|User|>并没有被分词器视为一个整体,这一点还是比较奇怪的。而且<|User|>也没有被分词器视为特殊token。
举一个例子,当前的input是'<|User|>:Напиши функцию на языке swift, которая сортирует массив целых чисел, а затем выводит его на экран\n<|Bot|>:'
其中'<|User|>:'经过分词后的结果是[333,352, 1621, 352,27232],占用了5个token,而不是1个token。'<|Bot|>:'也是一样,分词后的结果是[333, 352, 23845, 352, 27232]。这一点还是比较奇怪的。会不会是分词器的版本和模板的版本不匹配呢?
注意,还有一个细节,一般的分词器是直接调用tokenizer的call方法,call方法会返回attention_mask和token_type_ids,但是这里调用的是tokenizer.encode方法,只返回input_ids
第(2)步:在开头加入<s>对应分词后的结果
接着,在开头添加一个bos_token_id(bos_token_id就是,分词后的结果是1),因为开头需要有一个表示begin的符号。

此时的input_ids=[1, 333, 352, 1621, 352, 27232, 98937, 98715, 98818, 98729, 99012, 98729, 262, 99089, ...]
其实可以先在开头加入这个字符串,然后再分词。
这样的话会就变成对<|User|>:Напиши...来分词。可能这种方式会导致分词器错误分词?我做了实验,至少在当前版本的分词器下,不会导致错误分词。
注意,此时还没有结束。因为input_ids只有对问题的编码,还没有对答案的编码。为什么不一次性对问题和答案都编码?因为此时要先暂停一下来处理label。
第(3)步:先对label中不需要计算loss的部分用-100来占位
在PyTorch等深度学习框架中,一般使用交叉熵损失(Cross Entropy Loss)来训练拟合这类标签数据。在交叉熵损失中,-100作为默认的忽略索引(ignore index)。也就是说,只要某个位置的标签是-100,损失函数就会在计算过程中跳过这个位置,不会将它包括在损失计算之内。
这行代码创建了labels的前半部分。最后的+1,指的是开头加入的的位置。

截止到现在,已经完成了提问(或者说问题/prompt)部分的分词。而且此时,input_ids和labels的长度是一致的,都是105。
第(4)步:对回答完成类似第(1)(2)(3)的操作,拼接在input_ids和labels的后面。
此时,input_ids和labels的长度是一致的,都是564。
有一个小细节,不像<|User|>,它对应的编码只有一个元素:103028
第(5)步(可选):增加eos_token_id
上面第(2)步提到,句子的最开头加入了bos_token_id。此时,在整个句子的最结尾,可以加入eos_token_id。这一部分是以if语句存在的,在本示例中,没有加入eos_token_id
第(6)步:加入sep符号
sep符号,即'\n',这并不是分词器的特殊符号,而是template_map_fn中传入的。
对于input_ids,在整个句子的最结尾,加入364,即'\n'经过编码后的数字
对于labels,在整个句子的最结尾,加入-100
此时,input_ids和labels的长度是一致的,都是565。
第(7)步:检查是否超过设定的长度,如果超过,则截断。
检查如果某条数据中label的所有的值都小于0,则舍去。
我画了一个图,总结经过分词后的格式:

注意,只是用来表示模型的一次回答的结束。至于\n,我没有明白这个符号的含义,感觉和的作用重复了。
【关键步骤5】(可选)pack_to_max_length,即将不同的数据合并成一条数据

首先打乱数据,然后对索引重新编排。接着执行map函数和Packer映射。这里的batched=True,将会默认将1000个数据同时输入进去做处理,这样才方便将多条数据合并。
Packer的源代码和encode_fn函数一样,位于xtuner/dataset/utils.py里。
但是代码的逻辑是单纯地把不同的数据拼接在一起。比如设定的max_length=2048,第一条数据的长度是1000,第二条数据的长度是1000,第三条数据的长度是500。按照我的思路,应该是第一条和第二条数据合并在一起,然后第三条数据和后面的数据合并在一起。但是源码中的思路是,第一条数据+第二条数据+第三条数据的前48个token合并成一个数据。这样下来,基本上每条数据的长度都是2048。这样会造成一条数据被截断,划分成两条数据,合理吗?我觉得不太合理。
【总结】
以下的数据集的格式都是huggingface的datasets对象中的一条数据的格式
关键步骤1(加载数据集):
{"text": "### Human:...### Assistant:..."}
关键步骤2(解析提问和回答,以input和output的形式抽出来):
{"text": "### Human:...### Assistant:...",
"conversation":[{'input': '...', 'output': '...'}]}
关键步骤3(加入对话模板):
{"text": "### Human:...### Assistant:...",
"conversation":[
{'input': '<|User|>:...',
'need_eos_token':False,
'sep':'\n',
'output': '...'}]}
关键步骤4(经过分词器编码):
{'input_ids': [1, 333, 352, 1621, 352, 27232, 6863, 629, 3433, ...],
'labels': [-100, -100, -100, -100, -100, -100, -100, -100, -100, ...]}
附录1:加载数据的源码
源码地址:https://github.com/InternLM/xtuner
由于文章篇幅过长,下章将介绍更多细节解析及XTuner实战——自定义数据集微调&让模型改变自身定位。
往
期
推
荐

长按关注内核工匠微信
Linux内核黑科技| 技术文章| 精选教程



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











