







背景
OPPO是一家全球化的科技公司,随着公司的快速发展,业务方向越来越多,对中间件的依赖也越来越紧密,中间件的集群的数量成倍数增长,在中间件的部署,使用,以及运维出现各种问题。
1.中间件与业务应用混部在物理机,资源隔离困难
2.集群申请周期长,人工介入多,交互流程复杂
3.中间件整体CPU、内存、磁盘资源利用率低
4.业务使用中间件资源使用难以量化,成本核算困难
5.稳定性不足,故障恢复慢,步骤繁琐
6.传统物理机制没办法提供很强的资源弹性
容器化前业务申请中间件集群流程如下:
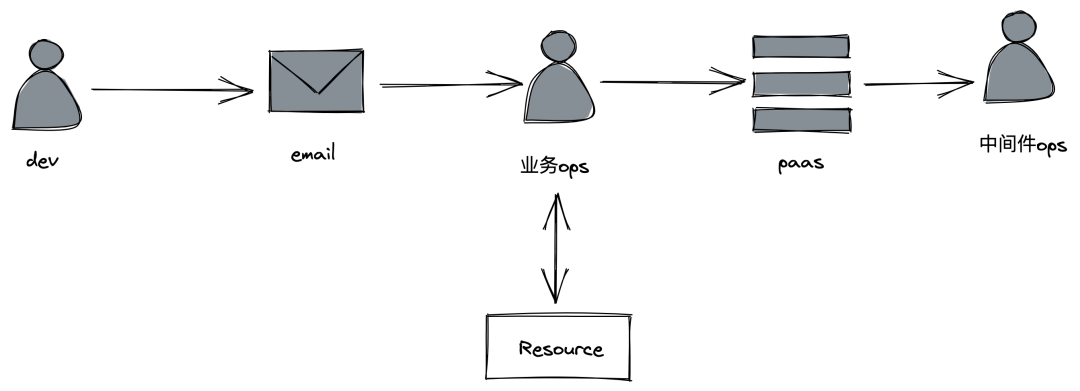
容器化前中间件基于传统的物理机进行部署,业务申请中间件,需填写中间件集群的所需机器规格,邮件到业务运维,业务运维与资源交互小组申请机器,然后业务运维在PaaS平台申请中间件集群,手动录入机器列表,中间件运维审批前,根据机器列表手动安装好中间件部署的Agent,最终通过Agent将中间件集群部署到业务的提供机器中。容器技术和云原生的火热,将为中间件的部署,使用以及运维带来变革。
容器化挑战
目前在OPPO有非常强的维护和定制K8S的团队,因此在我们中间件侧不用去考虑K8S底座的编排,调度,运维,容器管理等(专人专事),而是从上层中间件应用侧去考虑容器化的挑战。
1.有转态中间件容器故障后重新调度如何保持原有状态(固定IP和数据保持)
2.IO密集性的中间件如何做IO隔离
3.当性能不足或资源利用率不高时,如何快速探测并进行扩缩容(HPA和VPA)
4.如何做到故障自愈对用户无感知,对业务无损
5.如何云原生化以及未来展望
容器化
状态保持
在中间件容器化生产环境K8S暂未使用共享存储,而是使用本地盘FlexVolume+LVM,但共享块存储和共享文件存储也在陆续推进中,因此目前若容器所在的宿主机宕机,容器重新调度虽能保持IP固定不变,但数据会丢失,因此在中间件层面需保障高可用,数据有主备等关系。
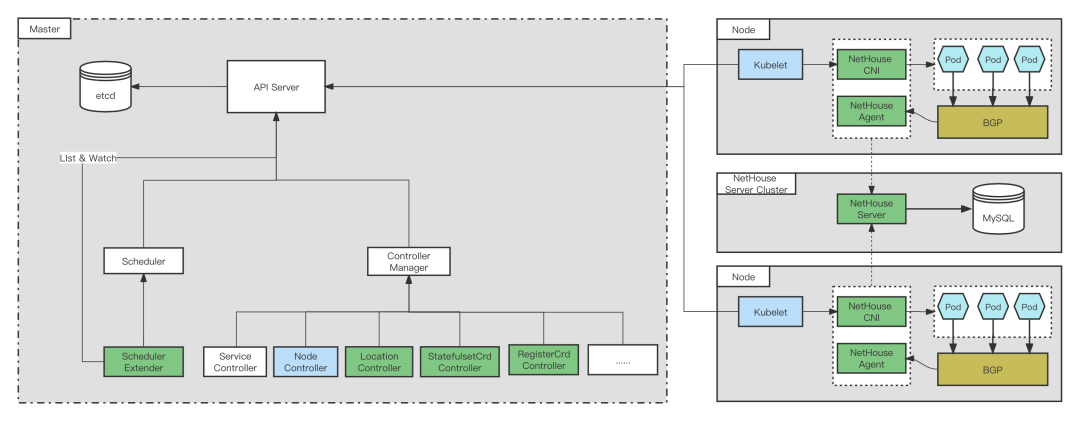
为了固定IP,自研了LocationController,StatefulSetController,ResitorController,NetHouse,扩展了Scheduler(SchedulerExtender),修改Kubelet,NodeController等源码。
Kubelet根据Pod的annotation,在有使用固定的需求时,创建Pod的时候需要打上对应的annotation,然后kubelet会打到创建的sandbox container的label里。调用cni接口申请网络时传参加入保留IP标识的标示,网络侧返回保留的Pod IP。当Pod删除时候,从sandbox container拿出这个信息,调用cni接口时,传入ns、podname和保留IP标识的标示,从而通知到网络该IP要保留。
SchedulerExtender调度模块获取缓存的Location CRD,进行调度,当有Pod需要调度会进行检查是否有IP保持不变的annotation,如果有检查是否有同名的Location CRD,如果有Location CRD,说明之前进行IP保持不变,在获取networkzone,返回符合networkzone条件的Node列表,如果没有Location CRD,说明是初次调度,返回所有满足条件的Node列表。SchedulerExtender的Controller模块负责创建和更新Location CRD。
LocationController watch location的add/update/delete事件,如果这个location的deletiontimestamp不为空(使用Finalize
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











