









第42讲:使用 Spring HATEOAS 增强 REST 服务的语义
从本课时开始,我们将介绍一些与云原生微服务开发相关的话题,这些话题之间相互独立,都围绕一个较小的主题来展开。本课时将介绍如何使用 Spring HATEOAS 增强 REST 服务的语义。
HATEOAS
REST 是目前大部分 API 使用的架构,在实践 REST 架构时,不同的实现可能有不同的处理方式。很多 API 虽然号称采用 REST 架构,但是并没有遵循 REST 架构的约束要求,我们可以用 REST 成熟度模型来描述 REST 技术的成熟程度。
该模型把 REST 服务按照成熟度划分成 4 个层次:
-
第一个层次(Level 0)的 Web 服务只是使用 HTTP 作为传输方式,实际上它只是远程方法调用(RPC)的一种具体形式,SOAP 和 XML-RPC 都属于此类;
-
第二个层次(Level 1)的 Web 服务引入了资源(Resource)的概念,每个资源有对应的标识符和表达(Representation);
-
第三个层次(Level 2)的 Web 服务使用不同的 HTTP 方法来进行不同的操作,并且使用 HTTP 状态码来表示不同的结果,比如 HTTP GET 方法来获取资源,HTTP DELETE 方法来删除资源;
-
第四个层次(Level 3)的 Web 服务使用 HATEOAS,在资源的表达中包含了链接信息,客户端可以根据链接来发现可以执行的动作。
从上述 REST 成熟度模型中可以看到,使用 HATEOAS 的 REST 服务是成熟度最高的。HATEOAS(Hypermedia as the Engine of Application State)是 REST 架构风格中最复杂的约束,也是构建成熟 REST 服务的核心。它的重要性在于打破了客户端和服务器之间严格的契约,使得客户端可以智能地发现服务所提供的功能,而 REST 服务本身的演化和更新也变得更加容易。
对于不使用 HATEOAS 的 REST 服务,客户端和服务器的实现之间是紧密耦合的,客户端需要根据服务器提供的相关文档来了解服务所暴露的资源和对应的操作。当服务的实现发生了变化时,比如修改了资源的 URI,客户端也需要进行相应的修改。
在使用 HATEOAS 的 REST 服务中,客户端通过服务提供的资源的表达来智能地发现可以执行的操作。当服务发生了变化时,客户端并不需要作出修改,因为资源的 URI 和其他信息都是动态发现的。
HATEOAS 和 OpenAPI 所要解决的问题不同,OpenAPI 规范提出了一种描述 API 的标准方式。开发者需要从 API 的文档中手动地查找到调用某个 API 的地址,还需要从文档中了解不同 API 之间的对应关系。以一个订单的 API 为例,当需要调用该 API 来支付订单时,需要从文档中找到相应的地址。HATEOAS 解决的是 API 的使用问题。如果订单 API 使用 HATEOAS 来实现,那么在获取到当个订单资源的表达之后,从中可以找到一个关系是 payment 的链接,其中就包含了支付订单 API 的地址。这样的使用方式,比从 API 文档中查找要方便很多。
Spring HATEOAS
Spring 框架下的 spring-hateoas 子项目为 Spring Web 项目增加了 HATEOAS 支持,对于 Spring Boot 应用来说,只需要添加对 spring-boot-starter-hateoas 的依赖即可。下面介绍 Spring HATEOAS 的使用。
链接
HATEOAS 中最重要的概念是链接(Link),用来在不同的资源之间建立联系,链接由两个部分组成,分别是链接所指向的超文本的地址,以及链接所代表的关系的名称。链接的地址通常是同一服务中不同的 REST 资源的地址,而关系则根据当前资源和链接指向的资源之间的联系来确定。
IANA 定义了一些常用的关系名称,如下表所示。
| 名称 | 含义 |
|---|---|
| self | 指向当前资源的链接 |
| edit | 编辑当前资源的链接 |
| first | 指向列表中的第一个资源的链接 |
| next | 指向列表中的下一个资源的链接 |
| prev | 指向列表中的上一个资源的链接 |
| last | 指向列表中的最后一个资源的链接 |
| collection | 指向当前资源所在的集合的链接 |
| item | 指向当前资源中所代表的集合中的一个元素的链接 |
| payment | 对当前资源进行支付操作的链接 |
在开发中应该优先使用这些标准的关系,这些关系都在 IanaLinkRelations 中有常量定义。下面的代码给出了 Spring HATEOAS 中 Link 类的用法,通过 of 方法来创建 Link 对象。
Link.of("/self"); //默认使用关系self
Link.of("/edit", IanaLinkRelations.EDIT); //使用IANA定义的标准关系
Link.of("/custom", "custom"); //使用自定义关系
在创建 Link 对象时,使用的链接地址通常不是固定的,而是基于某种特定的模板来创建的,比如 /order/{orderId} 这样的模板。Spring HATEOAS 提供了对 URI 模板的支持。
在下面的代码中,我们直接使用带路径参数的 URI 模板来创建 Link 对象,通过 expand 方法可以用实际值来替代模板中的变量,从而得到实际的链接地址。Link 对象是不可变的,对该对象的方法的调用,都会创建一个新的 Link 对象。
Link link = Link.of("/order/{orderId}");
link = link.expand(ImmutableMap.of("orderId", "123")); // 链接的地址为 "/order/123"
如果需要对 URI 模板进行更复杂的操作,可以使用 UriTemplate 类。在下面的代码中,我们使用 UriTemplate.of 方法来创建 UriTemplate 对象,再通过 with 方法来添加新的查询参数,Link 对象在创建时可以使用 UriTemplate 对象作为参数。
UriTemplate uriTemplate = UriTemplate.of("/customer/{customerId}/orders")
.with(TemplateVariable.requestParameter("start"))
.with(TemplateVariable.requestParameterContinued("end"));
Link link = Link.of(uriTemplate, "order")
.expand(ImmutableMap.of("customerId", "123", "start", "s", "end", "e"));
// 链接的地址为 "/customer/123/orders?start=s&end=e"
表达模型
为了在资源的超文本表达中添加链接,需要对应用中已有的模型进行封装,这些链接并不属于应用模型的一部分,可以使用标准的方式来进行封装。Spring HATEOAS 提供了进行封装所使用的模型,包括 RepresentationModel 类及其子类。
下面是 RepresentationModel 类及其子类的结构图。
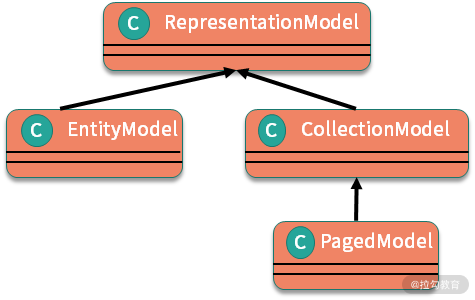
这些模型的说明如下表所示。
| 模型 | 说明 |
|---|---|
| RepresentationModel | 基础的模型,包含 Link 对象的列表 |
| CollectionModel | 用来封装实体集合的模型 |
| EntityModel | 用来封装单个实体的模型 |
| PagedModel | 包含了分页信息的模型 |
这些表达模型的使用方式取决于超文本模型与应用模型的匹配程度。如果表达模型仅用一个应用模型就可以完全表示,那么使用 EntityModel 来封装即可;否则需要创建新的模型类并继承自 RepresentationModel 类。
下面代码中的 getAddress 方法来自地址管理服务的 AddressController 类,与之前的实现相比,该方法增加了对 HATEOAS 的支持。该方法的返回值中包含的对象类型,从 AddressVO 类变成了 EntityModel 类,也就是用 EntityModel 来进行封装。在 getAddress 方法的实现中,EntityModel.of 方法用来封装已有的 AddressVO 对象,并添加新的关系为 self 的 Link 对象。
@GetMapping("/address/{addressId}")
public ResponseEntity<EntityModel<AddressVO>> getAddress(
@PathVariable("addressId") String addressId,
@RequestParam(value = "areaLevel", required = false, defaultValue = "1") int areaLevel) {
return this.addressService.getAddress(addressId, areaLevel)
.map(address -> EntityModel.of(address,
linkTo(methodOn(AddressController.class).getAddress(addressId, areaLevel)).withSelfRel()))
.map(ResponseEntity::ok)
.orElseGet(() -> ResponseEntity.notFound().build());
}
在创建 Link 对象时,我们并没有直接指定超文本的链接,而是从控制器的方法调用中创建。上述代码中使用的 methodOn 和 linkTo 方法都来自 WebMvcLinkBuilder 类,用来从 Spring MVC 控制器的方法中创建链接。methodOn 方法的作用是捕获对 AddressController 类的 getAddress 方法的调用,并传递了与当前方法一样的参数值;methodOn 方法的返回值被传递给 linkTo 方法来创建链接,withSelfRel 方法的作用是使用 self 作为链接的关系。
下面代码中的 JSON 文本是 getAddress 方法的返回值,从中可以看到 _links 属性中包含的链接。
{
"id": "a8530c62-d837-4aa3-9078-4b47f3c20c6b",
"areaId": 16,
"addressLine": "王府井社区居委会-0",
"lng": 116.414943,
"lat": 39.914146,
"areas": [],
"_links": {
"self": {
"href": "http://localhost:8502/address/a8530c62-d837-4aa3-9078-4b47f3c20c6b?areaLevel=0"
}
}
}
在表达一个集合时,可以使用 CollectionModel 来封装。下面的代码是添加了 HATEOAS 支持之后的 AddressController 类的 search 方法,该方法的返回值类型从 List<AddressVO> 变成了 CollectionModel<EntityModel<AddressVO>>,其中 CollectionModel 用来封装 List<AddressVO> 对象,而 EntityModel 用来封装单个的 AddressVO 对象。
对于 AddressService 类的 search 方法返回的 List<AddressVO> 对象,把其中包含的每个 AddressVO 对象都用 EntityModel.of 方法来封装,并添加相关的链接。整个集合再通过 CollectionModel.of 方法来封装。
@GetMapping("/search")
public CollectionModel<EntityModel<AddressVO>> search(
@RequestParam("areaCode") Long areaCode,
@RequestParam("query") String query) {
return CollectionModel
.of(this.addressService.search(areaCode, query)
.stream()
.map(address -> EntityModel.of(address,
linkTo(
methodOn(AddressController.class)
.getAddress(address.getId(), 1))
.withSelfRel())
).collect(Collectors.toList()),
linkTo(methodOn(AddressController.class).search(areaCode, query))
.withSelfRel());
}
下面代码中的 JSON 文本是 search 方法的返回值,该 JSON 文本的结构与不使用 HATEOAS 之前存在很大差异,AddressVO 对象的列表被移到了 _embedded 属性中,这是因为 Spring HATEOAS 默认使用的是 HAL 格式,这种格式的改变会对使用者产生影响。值得一提的是 AddressVO 对象中增加了链接,这个链接的存在,使得客户端在解析了列表中的对象之后,可以自动发现访问每个对象的地址,而不再需要查看文档。
{
"_embedded": {
"addressVOList": [
{
"id": "2f934c5f-7e08-4902-a4c7-4df752361e42",
"areaId": 16,
"addressLine": "王府井社区居委会-0",
"lng": 116.414938,
"lat": 39.914294,
"areas": [],
"_links": {
"self": {
"href": "http://localhost:8502/address/2f934c5f-7e08-4902-a4c7-4df752361e42?areaLevel=1"
}
}
}
]
},
"_links": {
"self": {
"href": "http://localhost:8502/search?areaCode=110101001015&query=%E7%8E%8B%E5%BA%9C%E4%BA%95%E7%A4%BE%E5%8C%BA%E5%B1%85%E5%A7%94%E4%BC%9A"
}
}
}
EntityLinks
在创建链接时,我们之前的做法是从 Spring MVC 的控制器方法中来生成链接。在很多时候,控制器的方法只是对某个领域模型 LCRUD 操作的集合,在这种情况下,可以使用 EntityLinks 对象来生成链接,并使用控制器方法更简单。
如果要使用 EntityLinks 对象,控制器需要遵循一定的规范,如下所示:
-
在控制器类上使用 @ExposesResourceFor 注解来声明领域对象的类型;
-
在控制器类上声明访问集合资源的路径;
-
在控制器类的某个方法上有访问单个资源路径的映射。
下面是乘客管理服务中 PassengerController 类的部分代码。在 PassengerController 类上通过 @ExposesResourceFor 注解声明了对象类型 PassengerVO,并通过 @RequestMapping 注解声明了访问集合资源的路径。在 getPassenger 方法中,我们使用 EntityLinks 对象的 linkToItemResource 方法来生成访问单个 PassengerVO 资源的链接。
@RestController
@ExposesResourceFor(PassengerVO.class)
@RequestMapping("/passenger")
public class PassengerController {
@Autowired
PassengerService passengerService;
@Autowired
EntityLinks entityLinks;
@GetMapping("{id}")
public ResponseEntity<EntityModel<PassengerVO>> getPassenger(
@PathVariable("id") String passengerId) {
return this.passengerService.getPassenger(passengerId)
.map(passenger -> EntityModel
.of(passenger,
this.entityLinks
.linkToItemResource(PassengerVO.class, passengerId)
.withSelfRel()))
.map(ResponseEntity::ok)
.orElse(ResponseEntity.notFound().build());
}
}
EntityLinks 对象中还包含了一个 linkToCollectionResource 方法来生成访问集合资源的链接。
组装模型
在之前 AddressController 类的实现中,getAddress 和 search 方法都需要创建封装 AddressVO 对象的 EntityModel。为了减少代码重复,可以把模型的创建统一起来。
下面代码中的 AddressModel 类继承自 RepresentationModel 类,作为 AddressVO 对象的表达模型。表达模型只是属性的简单集合,并没有复杂的逻辑,因此所有的字段都是声明为 public 的。
public class AddressModel extends RepresentationModel<AddressModel> {
public String id;
public Integer areaId;
public Long areaCode;
public String addressLine;
public BigDecimal lng;
public BigDecimal lat;
}
下面代码中的 AddressModelAssembler 类用来把 AddressVO 对象转换成 AddressModel 对象,相关的转换操作在 toModel 方法中实现,最主要的工作是添加相关的链接。
public class AddressModelAssembler extends
RepresentationModelAssemblerSupport<AddressVO, AddressModel> {
public AddressModelAssembler() {
super(AddressController.class, AddressModel.class);
}
@Override
public AddressModel toModel(AddressVO entity) {
AddressModel model = new AddressModel();
model.add(linkTo(
methodOn(AddressController.class)
.getAddress(entity.getId(), 1))
.withSelfRel());
model.id = entity.getId();
model.areaId = entity.getAreaId();
model.areaCode = entity.getAreaCode();
model.addressLine = entity.getAddressLine();
model.lat = entity.getLat();
model.lng = entity.getLng();
return model;
}
}
需要注意的是,在 RepresentationModelAssemblerSupport 类中有一个 createModelWithId 方法,可以创建 AddressModel 对象并添加关系为 self 的链接,这个方法通过控制器类上的 @RequestMapping 注解来计算出引用单个资源的路径。不过这种方式对 AddressController 类并不适用,因为在 AddressController 类中,访问单个资源的路径模板是 /address/{addressId},而不是 /{addressId}。对于其他控制器类来说,如果遵循 RepresentationModelAssemblerSupport 类的惯例,那么使用 createModelWithId 方法会更简单。
在使用 AddressModelAssembler 类之后,进行模型转换的代码可以大大简化。在下面的代码中,AddressController 类的 search 方法使用 AddressModelAssembler 类的 toCollectionModel 方法来转换列表。
@GetMapping("/search")
public CollectionModel<AddressModel> search(
@RequestParam("areaCode") Long areaCode,
@RequestParam("query") String query) {
return this.assembler
.toCollectionModel(this.addressService.search(areaCode, query));
}
处理模型
我们一般在创建表达模型的同时,就完成了对链接的创建。在有些情况下,可能会需要对某些表达模型进行独立的处理,相应的处理方式可能不适合放在某个模型中,比如根据配置在运行时动态调整。这个时候,就可以实现 RepresentationModelProcessor 接口来添加对任意模型的处理。
在下面的代码中,AreaProcessor 类添加了对 AddressModel 的处理,并添加了关系为 area 的链接,指向获取地址所在的区域的详细信息 API。Spring HATEOAS 可以自动识别 RepresentationModelProcessor 类型的 bean,并应用其中包含的对模型的修改。
@Component
public class AreaProcessor implements
RepresentationModelProcessor<AddressModel> {
@Override
public AddressModel process(AddressModel model) {
model.add(
linkTo(methodOn(AddressController.class).getArea(model.areaCode, 1))
.withRel("area"));
return model;
}
}
媒体类型
媒体类型的作用是把 HATEOAS 模型转换成特定的超文本表达形式,大部分的表达形式以 JSON 作为基本的格式,只不过具体的格式有所不同。Spring HATEOAS 默认使用超文本应用语言(Hypertext Application Language,HAL)作为表达模型时的格式。HAL 使用 application/hal+json 作为媒体类型,其中最基本的概念是资源和链接。资源中可以包含链接和内嵌资源,内嵌资源包含在 _embedded 属性中,而链接信息则包含在 _links 属性中。
除了 HAL 之外,Spring HATEOAS 还支持其他不同的媒体类型,应用也可以开发自己的媒体类型。
总结
HATEOAS 可以增强 REST 服务的语义,从而方便客户端更好地使用服务,自动发现服务所提供的功能。通过本课时的学习,你可以了解 REST 成熟度模型、HATEOAS 的基本概念,以及如何使用 Spring HATEOAS 为 Spring Boot 微服务增加 HATEOAS 支持。
第43讲:使用 gRPC 作为服务之间的交互方式
在本专栏介绍微服务架构时,我们提到了外部和内部 API 及其区别,示例应用中的微服务采用 API 优先的设计方式,并基于 OpenAPI 规范来创建 REST API。除了 REST API 之外,另外一种常见的开放 API 的格式是 gRPC,本课时将对 gRPC 进行介绍。
gRPC 介绍
在实现 API 的方式中,REST 和 gRPC 经常会被拿来进行比较,这两种方式各有长处和短处。REST 的优势在于简单易用,只需要使用 curl 这样的工具就可以与 API 交互;REST 一般使用 JSON 或 XML 这样的纯文本格式作为表达形式,使得开发和调试变得很容易。
gRPC 本质上是一种远程过程调用,默认使用 Protocol Buffers 作为传输格式,传输协议为 HTTP/2。Protocol Buffers 作为一种二进制格式,可以充分的节省传输带宽,但是相应的开发和调试会变得困难,需要首先对消息进行解码之后,才能得到原始的消息内容。与 REST 相比,gRPC 还可以充分利用 HTTP/2 的多路复用功能来提高性能。gRPC 在云原生中应用广泛,其本身也是 CNCF 中的孵化项目。
与 REST 相比,gRPC 支持 4 种不同的客户端与服务器的交互方式,如下表所示:
| 交互方式 | 说明 |
|---|---|
| 一元 RPC | 客户端发送单个请求,服务器返回单个消息响应 |
| 服务器流 RPC | 客户端发送单个请求,服务器返回一个消息流作为响应 |
| 客户端流 RPC | 客户端发送一个消息流作为请求,服务器返回单个消息作为响应 |
| 双向流 RPC | 客户端和服务器都可以发送消息流 |
在上表的 4 种交互方式中,双向流 RPC 的实现最为复杂,因为需要根据应用的需求来确定客户端和服务器发送消息的顺序。客户端和服务器的消息发送可能是交织在一起的,除了双向流 RPC 之外的其他 3 种交互方式在实现上都相对简单。
对于云原生微服务来说,服务的内部 API 推荐使用 gRPC 来提高性能和减少带宽消耗;而对于服务的外部 API 来说,REST 仍然是目前的主流,也可以同时提供 REST 和 gRPC 两种外部 API。如果外部 API 使用 REST,而内部 API 使用 gRPC,那么我们可以使用 API 网关进行协议翻译。
虽然 gRPC 并不限制消息的内容类型,你可以使用 JSON、XML 或 Thrift 作为消息格式,从支持的成熟度来说,Protocol Buffers 仍然是最佳的选择。下面首先对 Protocol Buffers 进行介绍(以下简称为 Protobuf)。
Protocol Buffers
Protobuf 是一种语言中立、平台中立和可扩展的机制,用来对结构化数据进行序列化。它由 Google 提出,目前是开源的技术。在使用 Protobuf 时,我们通过它提供的语言来描述消息的结构,然后再通过工具生成特定语言上的代码。通过生成的代码来进行消息的序列化,包括写入和读取消息。
Protobuf 的语言规范有两个版本 2 和 3,本课时介绍的是版本 3。Protobuf 中最基本的结构是消息类型,每个消息类型由多个字段组成。对于每个字段,我们需要定义它的名称、类型和编号。
消息的名称使用首字母大写的 CamelCase 格式,而字段名称则使用下划线分隔的小写格式。字段的类型有很多种,比如常见的标量类型,包括 int32、int64、float、double、bool、string 和 bytes 等。除此之外,还可以使用 enum 来定义枚举类型。
下面的代码展示了 Protobuf 中消息的定义,其中第一行的 syntax 声明了使用版本 3,message 用来声明消息类型。在枚举类型中,每个枚举项都需要指定对应的值,并且必须有一个值为 0 的枚举项。
syntax = "proto3";
message TestMessage {
int32 v1 = 1;
double v2 = 2;
string v3 = 3;
bool v4 = 4;
enum Color {
Red = 0;
Green = 1;
Blue = 2;
}
Color color = 5;
}
消息中的每个字段都有一个唯一的数字编号,在消息的二进制格式中,该编号会作为字段的标识符。在消息类型被使用之后,该编号不能被修改。编号从 1 ~ 15 的字段只需要一个字节就可以对字段的编号与类型进行编码,而编号为 16 ~ 2047 的字段则需要两个字节,从节省带宽的角度来说,编号 1 ~ 15 应该分配给出现频率较高的字段。
消息类型中定义的字段,如果没有特殊声明,那么在实际的消息中最多出现一次。而对于可能出现多次的字段,则需要使用 repeated 来进行声明。
另外一种特殊的字段类型是 oneof,表示消息中包含的某些字段,在同一时间只会至多设置一个字段的值。当设置其中一个字段的值之后,其他字段的值会被自动清空。在下面代码的 DemoMessage 中,test 的类型是 oneof,这就意味着 test 中定义的 name 和 type 字段不会同时出现。
message DemoMessage {
oneof test {
string name = 1;
int32 type = 2;
}
bool enabled = 3;
repeated string values = 4;
}
gRPC 使用
gRPC 的方法也在 Protobuf 定义文件中声明。gRPC 的一个重要特征是通过代码生成工具来产生服务器和客户端的存根代码,生成的存根代码封装了 gRPC 底层的传输协议的细节。以服务器存根代码来说,开发者所要处理的只是从 Protobuf 文件中生成的 Java 对象,并不需要了解对象序列化的细节;从业务逻辑上来说,也只需要实现对方法调用的处理逻辑即可,并不需要了解传输协议的细节。下面介绍如何为地址管理服务提供 gRPC 协议的 API。
Protobuf 文档
创建 gRPC 服务的第一步是编写 Protobuf 文档,该文档用来描述 gRPC 服务所支持的方法,以及方法的参数和返回值的消息格式。下面的代码是地址管理服务 gRPC 的 Protobuf 文档的部分代码,该文档主要由 3 个部分组成,通过不同的指令来描述。下表给出了 Protobuf 文件中的常用指令。
| 指令 | 说明 |
|---|---|
| option | 与代码生成相关的选项 |
| message | 不同消息类型的声明 |
| service | 所提供的 gRPC 服务 |
| rpc | 服务中包含的可供调用的方法 |
syntax = "proto3";
option java_multiple_files = true;
option java_package = "io.vividcode.happyride.addressservice.grpc";
option java_outer_classname = "AddressServiceProto";
message Area {
int32 id = 1;
int32 level = 2;
}
message Address {
string id = 1;
repeated Area areas = 6;
}
message GetAddressRequest {
string address_id = 1;
int32 area_level = 2;
}
message GetAddressResponse {
oneof optional_address {
Address address = 1;
}
}
message GetAreaRequest {
int64 area_code = 1;
int32 ancestor_level = 2;
}
message GetAreaResponse {
oneof optional_area {
Area area = 1;
}
}
message AddressSearchRequest {
int64 area_code = 1;
string query = 2;
}
service AddressService {
rpc GetAddress(GetAddressRequest) returns (GetAddressResponse);
rpc GetArea(GetAreaRequest) returns (GetAreaResponse);
rpc Search(AddressSearchRequest) returns (stream Address);
rpc GetAddresses(stream GetAddressRequest) returns (stream Address);
}
对于 Java 应用来说,我们可以用下表中给出的选项来对生成的代码进行配置。
| 选项 | 说明 |
|---|---|
| java_multiple_files | 当值为 true 时,Protobuf 文件中的每个 message 类型,都会生成各自的 Java 文件;否则,每个 message 类型都会作为单个 Java 类的内部类 |
| java_package | 生成的 Java 代码的包名 |
| java_outer_classname | 生成的 Java 类的名称。当 java_multiple_files 为 false 时,该类作为包含 message 类型的外部类 |
在 Protobuf 文件中的 message 类型,用来描述 gRPC 服务所提供的方法的参数和返回值的类型。一般来说,每个方法的参数和返回值都有各自独立的 message 类型声明。在方法的声明中,stream 表示流,可以出现在方法的参数或返回值的声明中,对应于不同的交互方式。在上面代码的声明中,GetAddress 和 GetArea 方法使用的是一元 RPC,而 Search 方法使用的是服务器流 RPC,GetAddresses 方法使用的是双向流 RPC。
代码生成
在完成了 protobuf 的声明之后,下一步是使用工具来生成相关的代码存根,生成代码时需要使用 protoc 工具及 gRPC 插件。在 Java 应用中,我们通过 Maven 插件来使用 protoc,Protobuf 文件保存在 src/main/proto 目录中。
下面的代码是相关的 Maven 配置,其中 os-maven-plugin 插件用来检测当前环境的操作系统版本,protobuf-maven-plugin 是运行 protoc 的 Maven 插件。
<build>
<extensions>
<extension>
<groupId>kr.motd.maven</groupId>
<artifactId>os-maven-plugin</artifactId>
<version>1.6.2</version>
</extension>
</extensions>
<plugins>
<plugin>
<groupId>org.xolstice.maven.plugins</groupId>
<artifactId>protobuf-maven-plugin</artifactId>
<version>0.6.1</version>
<configuration>
<protocArtifact>com.google.protobuf:protoc:${protoc.version}:exe:${os.detected.classifier}</protocArtifact>
<pluginId>grpc-java</pluginId>
<pluginArtifact>io.grpc:protoc-gen-grpc-java:${grpc.version}:exe:${os.detected.classifier}</pluginArtifact>
</configuration>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>compile-custom</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
在使用 Maven 构建之后,会在 Maven 项目的 target/generated-sources/protobuf 目录下生成 protobuf 相关的 Java 代码,其中 java 子目录中包含的是消息类型对应的 Java 代码,而 grpc-java 目录下面包含的是 gRPC 服务的代码。下面的代码给出了生成文件的目录结构。
.
├── grpc-java
│ └── io
│ └── vividcode
│ └── happyride
│ └── addressservice
│ └── grpc
│ └── AddressServiceGrpc.java
└── java
└── io
└── vividcode
└── happyride
└── addressservice
└── grpc
├── Address.java
├── AddressOrBuilder.java
├── AddressSearchRequest.java
├── AddressSearchRequestOrBuilder.java
├── AddressServiceProto.java
├── Area.java
├── AreaOrBuilder.java
├── GetAddressRequest.java
├── GetAddressRequestOrBuilder.java
├── GetAddressResponse.java
├── GetAddressResponseOrBuilder.java
├── GetAreaRequest.java
├── GetAreaRequestOrBuilder.java
├── GetAreaResponse.java
└── GetAreaResponseOrBuilder.java
生成的 AddressServiceGrpc 类中包含了 gRPC 服务器和客户端的代码,其中 AddressServiceImplBase 是服务端的基本实现类,其中的每个方法都对应 Protobuf 文件中服务 AddressService 中声明的方法。在服务端实现中,只需要继承 AddressServiceImplBase 类,并覆写这些方法即可。
服务端实现
下面的代码给出了具体服务端实现类 AddressGrpcService 的部分代码。在 getAddress 方法中,方法的参数类型 GetAddressRequest 对应于 protobuf 中同名方法的参数的消息类型,而 StreamObserver 对象用来产生作为响应的消息。
StreamObserver 接口中的方法与反应式编程中的 Observer 是相同的,具体的方法如下表所示。
| 方法 | 说明 |
|---|---|
| onNext(V value) | 产生一个消息 |
| onError(Throwable t) | 产生一个错误并终止流 |
| onCompleted() | 正常终止流 |
Protobuf 中的每个消息都使用构建器模式来创建。下面代码中的 buildAddress 方法用来把 AddressVO 对象转换成 protobuf 中的 Address 类型的消息。而对于产生的消息,可通过 StreamObserver 对象的 onNext 方法来发送,等全部消息发送完成之后,使用 onCompleted 来结束流。在运行时,getAddress 方法最多只调用 onNext 方法一次,而 search 方法则可能多次调用 onNext 方法来产生多条消息。虽然 getAddress 方法使用的是一元 RPC 的交互模式,但是在实现中,仍然以流的形式来表示。
@GRpcService
public class AddressGrpcService extends AddressServiceImplBase {
@Autowired
AddressService addressService;
@Autowired
AreaService areaService;
@Override
public void getAddress(GetAddressRequest request,
StreamObserver<GetAddressResponse> responseObserver) {
GetAddressResponse.Builder builder = GetAddressResponse.newBuilder();
this.addressService
.getAddress(request.getAddressId(), request.getAreaLevel())
.ifPresent(address -> builder.setAddress(this.buildAddress(address)));
responseObserver.onNext(builder.build());
responseObserver.onCompleted();
}
@Override
public void search(AddressSearchRequest request,
StreamObserver<Address> responseObserver) {
this.addressService.search(request.getAreaCode(), request.getQuery())
.forEach(
address -> responseObserver.onNext(this.buildAddress(address)));
responseObserver.onCompleted();
}
private Address buildAddress(AddressVO address) {
return Address.newBuilder().setId(address.getId())
.setAreaId(address.getAreaId())
.setAddressLine(address.getAddressLine())
.setLat(address.getLat().toPlainString())
.setLng(address.getLng().toPlainString())
.addAllAreas(address.getAreas().stream()
.map(this::buildArea).collect(Collectors.toList()))
.build();
}
}
下面的代码是使用双向流 RPC 的 getAddresses 方法,该方法的返回值同样是一个 StreamObserver 对象,表示客户端请求的流。当作为返回值 StreamObserver 对象的 onNext 方法被调用时,说明客户端发送了一个新的消息,对于这个消息的处理方式是往 responseObserver 表示的流中写入作为响应的 Address 类型的消息。
public StreamObserver<GetAddressRequest> getAddresses(
StreamObserver<Address> responseObserver) {
return new StreamObserver<GetAddressRequest>() {
@Override
public void onNext(GetAddressRequest request) {
AddressGrpcService.this.addressService
.getAddress(request.getAddressId(), request.getAreaLevel())
.ifPresent(
address -> responseObserver.onNext(
AddressGrpcService.this.buildAddress(address)));
}
@Override
public void onError(Throwable t) {
AddressGrpcService.LOGGER.warn("Error", t);
}
@Override
public void onCompleted() {
responseObserver.onCompleted();
}
};
}
AddressGrpcService 类上的注解 @GRpcService 来自 grpc-spring-boot-starter 库,用来在 Spring Boot 中集成 gRPC 服务。该第三方库可以自动启动 gRPC 服务器,免去了烦琐的配置。gRPC 服务器默认在 6565 端口启动,可以通过配置项 grpc.port 来修改。
客户端实现
我们可以用生成的 gRPC 服务的客户端来调用服务。生成的代码中包含了 3 种不同类型的客户端,如下表所示:
| 客户端 | 说明 |
|---|---|
| AddressServiceStub | 使用 StreamObserver 的异步调用客户端 |
| AddressServiceBlockingStub | 执行同步调用的阻塞客户端 |
| AddressServiceFutureStub | 使用 Guava 中 ListenableFuture 的客户端 |
在这 3 种客户端中,同步调用的客户端使用最简单,在创建客户端时,需要提供 Channel 对象。在下面的代码中,ManagedChannelBuilder 类用来创建连接到本机的 6565 端口的 Channel 对象,而 AddressServiceGrpc 类的 newBlockingStub 方法用来创建阻塞客户端的 AddressServiceBlockingStub 对象,该对象中方法的返回值是实际响应消息类型的对象。
Channel channel = ManagedChannelBuilder.forAddress("localhost", 6565)
.usePlaintext().build();
AddressServiceBlockingStub blockingStub = AddressServiceGrpc
.newBlockingStub(channel);
Iterator<Address> result = blockingStub
.search(AddressSearchRequest.newBuilder()
.setAreaCode(110101001015L)
.setQuery("王府井社区居委会")
.build());
result.forEachRemaining(System.out::println);
下面的代码给出了异步非阻塞客户端的使用方式。通过 AddressServiceGrpc 类的 newStub 方法可以创建出作为客户端的 AddressServiceStub 对象。在调用 getAddresses 方法时,返回的 StreamObserver<GetAddressRequest> 对象用来发送请求消息,而作为参数的 StreamObserver<Address> 对象则用来处理服务器返回的消息。CountDownLatch 对象的作用是等待响应流的结束。
Channel channel = ManagedChannelBuilder.forAddress("localhost", 6565)
.usePlaintext().build();
AddressServiceStub asyncStub = AddressServiceGrpc.newStub(channel);
CountDownLatch finishLatch = new CountDownLatch(1);
StreamObserver<GetAddressRequest> requestObserver = asyncStub
.getAddresses(new StreamObserver<Address>() {
@Override
public void onNext(Address value) {
System.out.println(value);
}
@Override
public void onError(Throwable t) {
t.printStackTrace();
finishLatch.countDown();
}
@Override
public void onCompleted() {
System.out.println("Completed");
finishLatch.countDown();
}
});
for (int i = 1; i <= 3; i++) {
requestObserver.onNext(
GetAddressRequest.newBuilder()
.setAddressId("962fddbc-54cc-4758-bf01-56e2833c6443")
.setAreaLevel(i).build());
}
requestObserver.onCompleted();
finishLatch.await(1, TimeUnit.MINUTES);
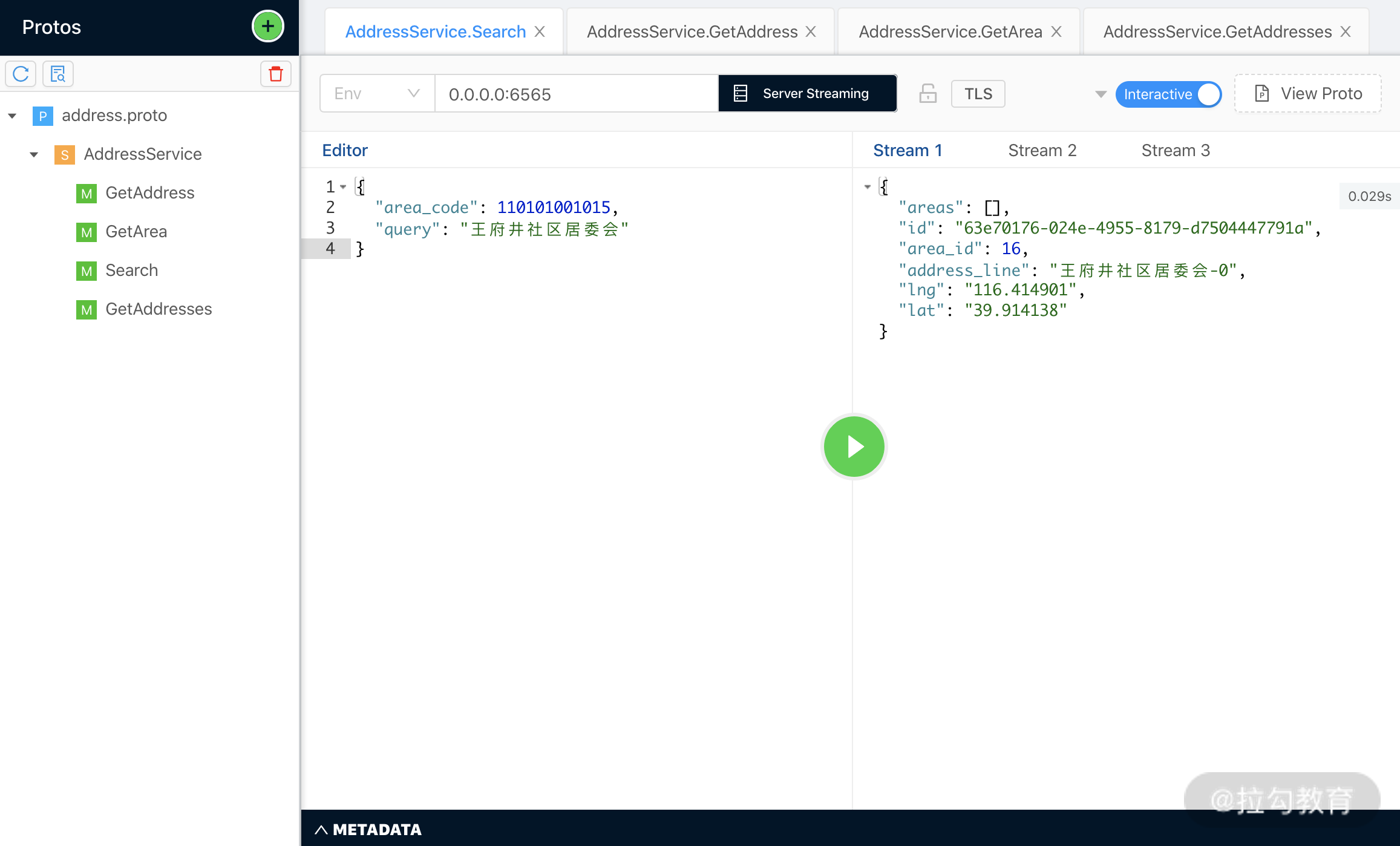
在本地开发和调试中,直接使用 Java 客户端不太方便,推荐使用单独的 gRPC 工具,如 BloomRPC。BloomRPC 可以导入 Protobuf 文件并调用 gRPC 服务,如下图所示。
总结
相对于 REST API,gRPC 提供了更灵活的交互方式、更好的性能和更少的带宽占用,适用于云原生应用中微服务之间的交互。通过本课时的学习,你可以对 gRPC 和 Protocol Buffers 有基本的了解,以及如何在应用中创建 gRPC 服务,并通过客户端来调用 gRPC 服务。
第44讲:使用 Quarku 开发微服务
云原生技术的出现,为微服务架构的应用带来了在实现技术选型上的灵活性。使用 Kubernetes 和容器化技术,每个微服务可以选择最适合的技术栈,不限定特定的编程语言或平台。以 Java 来说,任何可以开发 Java 应用的框架和库都可以使用。不过,云原生应用有其特殊的运行需求,主要体现在应用的打包体积、启动时间和运行时的消耗上。
云原生应用以容器镜像的形式来打包,更小的镜像尺寸,就意味着更少的存储空间和更快的传输速度。虽然现在存储空间相对比较廉价,但是考虑到每次构建过程都会产生不可变的容器镜像,在运行时需要保存的容器镜像数量是很多的。每个 Git 提交都有对应的容器镜像。如果能够尽可能地减少单个应用的镜像的尺寸,累积下来所节省的空间是很可观的。
云原生应用的启动速度应该尽可能地快,这是为了满足故障恢复和水平扩展的要求。Kubernetes 经常需要启动新的 Pod,更快的启动速度意味着更快速的响应时间。云原生应用需要共享集群上的资源,单个应用所耗费的资源当然越少越好。
开发框架
在云原生应用的开发中,我们可以把 Java 应用的框架大致分成两类:第一类是传统的 Java 应用框架,以 Spring Boot 为例;第二类是专门为云原生和微服务设计的 Java 应用框架,以 Quarkus、Micronaut、Helidon、Eclipse MicroProfile 为代表,这些新兴框架的特点在于高度的模块化。这一点符合微服务的基本特征,那就是每个微服务只专注于实现特定的功能。通过模块化,每个微服务在实现时,只需要选择特定的模块即可,这可以减少服务所依赖的第三方库的数量,从而减少打包的尺寸。
提到云原生 Java 应用的开发,就必须要提到 GraalVM,这是 Oracle 开发的支持多语言的虚拟机平台,其所支持的编程语言包括 Java、Kotlin 和 Scala 这样的 JVM 语言,也包括 C/C++、JavaScript、Ruby 和 Python 等。对云原生应用来说,GraalVM 的一个重要功能是可以把 Java 应用打包成可执行的原生镜像,从而减少应用的打包尺寸,加快启动速度和减少运行时的资源消耗,这是一个为云原生应用量身定做的功能。是否支持 GraalVM,已经成为衡量云原生微服务开发框架的重要指标。
下面介绍如何使用 Quarkus 框架来实现地址管理服务。
Quarkus 框架
下面对 Quarkus 框架进行介绍。
创建应用
最简单的创建 Quarkus 应用的方式是使用 Quarkus 提供的 Maven 插件。在下面的代码中,通过运行 Maven 插件的 create 目标来创建新的 Quarkus 应用的骨架代码。
$ mvn io.quarkus:quarkus-maven-plugin:1.6.1.Final:create \
-DprojectGroupId=io.vividcode.happyride \
-DprojectArtifactId=happyride-address-service-quarkus \
-DprojectVersion=1.0.0-SNAPSHOT
Quarkus 的模块化以扩展为单位,应用可以根据需要添加不同类型的扩展。通过下面的命令可以列出来目前 Quarkus 所支持的全部扩展。
$ mvn quarkus:list-extensions
通过 Maven 插件的 add-extension 目标可以添加新的扩展,如下所示。与 add-extension 相对应的 remove-extension 目标可以删除扩展,扩展的标识符可以从 list-extensions 目标的输出中获得。
$ mvn quarkus:add-extension -Dextensions="quarkus-flyway, quarkus-resteasy, quarkus-resteasy-jackson, quarkus-hibernate-orm-panache, quarkus-jdbc-postgresql"
与扩展相关的命令本质上只是对 Maven 项目的 POM 文件进行修改,来添加或删除相关的依赖。我们也可以不使用这些命令,而直接修改 POM 文件本身,所产生的效果是一样的。
依赖注入
在 Java 应用的开发中,依赖注入是一个不可或缺的功能,可以极大地简化代码的编写,Spring 框架实现了自己的控制反转容器和依赖注入支持。Quarkus 的依赖注入功能基于 JSR 365:Contexts and Dependency Injection for Java 2.0,也就是 CDI 2.0 规范,不过 Quarkus 仅实现了 CDI 2.0 规范中的部分内容,在绝大部分情况下已经足够了。
依赖注入分为 Bean 的创建和使用两个部分。在创建 Bean 时,我们可以使用 CDI 提供的注解来创建不同作用域的 Bean,如下表所示。
| 注解 | 作用域 |
|---|---|
| @ApplicationScoped | 与整个应用的上下文绑定 |
| @SessionScoped | 与当前的用户会话上下文绑定 |
| @RequestScoped | 与当前的请求上下文绑定 |
在下面的代码中,AddressService 类型的 Bean 出现在应用上下文中。
@ApplicationScoped
public class AddressService {
}
在使用 Bean 时,通过 @Inject 注解来进行声明,可以注入的方式包括字段、构造方法和 Setter 方法。在下面的代码中,以字段的方式注入了 AddressService 类型的 Bean。在使用字段的方式注入依赖时,不建议使用 private 作为字段的可见性,因为这会对原生镜像的生成产生影响。使用 package private 可见性是推荐的做法。
public class AddressResource {
@Inject
AddressService addressService;
}
Quarkus 默认提供了 3 种不同的概要文件,分别是 dev、test 和 prod。通过 @IfBuildProfile 注解可以限定一个 Bean 只在特定的概要文件中出现。在下面的代码中,AddressLoader 类的 Bean 只在 dev 概要文件中出现。
@ApplicationScoped
@IfBuildProfile("dev")
public class AddressLoader {
}
数据访问
在 Quarkus 中,我们可以用 Hibernate 来访问关系型数据库,这也是 Java 应用中访问关系型数据库的通用做法。 在应用中可以通过标准的方式来使用 Hibernate,也就是使用依赖注入的 EntityManager 对象来进行实体的持久化。不过更好的做法是使用 Panache 库,它在很大程度上简化了对 Hibernate 的使用。在使用 Panache 之前,需要在 Quarkus 应用中添加相关的扩展。
Panache 支持两种不同的使用模式:第一种使用活动记录(Active Record)模式,把数据查询的逻辑添加在实体类中;第二种是使用仓库(Repository)模式,把数据查询的逻辑添加在仓库类,这也是 Spring Data JPA 使用的模式。由于第 11 课时已经介绍了仓库模式的使用,本课时介绍活动记录模式。
下面代码中的 Address 是 Panache 中的实体类。Address 的父类 PanacheEntityBase 提供了与实体的 LCRUD 操作相关的方法,包括 list、find、update 和 delete 等。Address 类使用标准的 JPA 注解来描述实体和关系。Address 类使用 String 类型的标识符,因此需要自定义的 id 字段。如果你的实体使用自动生成的 Long 类型的标识符,那么可以直接继承自 PanacheEntity 类,而不需要添加额外的 id 字段。
除了字段的声明之外,Address 类还包含了一个静态方法 findByAreaCodeAndAddressLine,用来根据 areaCode 和 query 进行查找,这里用到了 Hibernate 的 HQL 来进行查询。
@Entity
@Table(name = "addresses")
public class Address extends PanacheEntityBase {
@Id
public String id;
@ManyToOne
@JoinColumn(name = "area_id")
public Area area;
@Column(name = "address_line")
@Size(max = 255)
public String addressLine;
@Column(name = "lng")
public BigDecimal lng;
@Column(name = "lat")
public BigDecimal lat;
public static List<Address> findByAreaCodeAndAddressLine(Long areaCode,
String query) {
return list("area.areaCode = :areaCode and addressLine LIKE :query",
ImmutableMap.of(
"areaCode", areaCode,
"query", "%" + query + "%"
));
}
}
服务层
服务层的实现类使用实体类来进行数据查询。下面代码中的 AddressService 类是进行地址查询的服务实现,该服务类通过 @Transactional 注解启用了事务支持。
@ApplicationScoped
@Transactional
public class AddressService {
public List<AddressVO> search(Long areaCode, String query) {
return Address.findByAreaCodeAndAddressLine(areaCode, query)
.stream()
.map(AddressHelper::fromAddress)
.collect(Collectors.toList());
}
}
REST 服务
在 Quarkus 中,可以使用 resteasy 扩展来发布 REST 服务。与 Spring MVC 不同的是,Resteasy 使用 JAX-RS 的注解来对 REST 资源进行声明,在进行 JSON 序列化时,可以选择 JSON-B 或 Jackson,只需要添加对应的扩展即可。
下面代码中的 AddressResource 类是地址资源的实现,其中以依赖注入的方式使用服务层实现类 AddressService。
@Path("/")
public class AddressResource {
@Inject
AddressService addressService;
@Path("/search")
@GET
@Produces(MediaType.APPLICATION_JSON)
public List<AddressVO> search(
@QueryParam("areaCode") Long areaCode,
@QueryParam("query") String query) {
return this.addressService.search(areaCode, query);
}
}
应用配置
配置是 Quarkus 应用不可或缺的一部分。地址管理服务需要通过配置来设置关系式数据库的连接信息。最简单的对 Quarkus 进行配置的方式是编辑 src/main/resources 目录下的 application.properties 文件,如下面的代码所示,该配置文件中包含对应于不同扩展的配置项。配置项的名称以 a.b.c 的形式来表示,相互关联的配置项具有相同的前缀,比如,quarkus.flyway 前缀表示 Flyway 相关的配置。
quarkus.datasource.db-kind=postgresql
quarkus.datasource.username=${DB_USERNAME:postgres}
quarkus.datasource.password=${DB_PASSWORD:postgres}
quarkus.datasource.jdbc.url=jdbc:postgresql://${DB_HOST:localhost}:${DB_PORT:8430}/${DB_NAME:happyride-address}
quarkus.hibernate-orm.database.default-schema=happyride
quarkus.flyway.migrate-at-start=true
quarkus.flyway.schemas=happyride
除了 Quarkus 中扩展的配置项之外,应用也可以添加自定义的配置项。在应用中,使用配置项最简单的方式是添加 @ConfigProperty 注解。在下面的代码中,value 的值与配置项 app.value 进行绑定。
@ConfigProperty(name = "app.value")
String value;
Quarkus 同样支持 Spring Boot 中的类型安全的配置类。下面代码中的配置类 AppConfiguration 使用 @ConfigProperties 注解与前缀为 app 的配置项进行绑定。配置类中的字段与同名的配置项进行绑定。
@ConfigProperties(prefix = "app")
public class AppConfiguration {
private String value;
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}
当需要获取配置时,只需要以依赖注入的形式来获取 AppConfiguration 类的对象即可。
@Inject
AppConfiguration appConfiguration;
除了属性文件之外,Quarkus 也支持 YAML 格式的配置文件,需要 config-yaml 扩展的支持。
单元测试
Quarkus 提供了对单元测试的支持。在单元测试中,可以分别对数据访问层、服务层和 REST 资源进行测试。Quarkus 也支持使用 Mockito 来模拟对象。
下面代码中的 AddressResourceTest 类是 AddressResource 的单元测试用例。@QuarkusTest 注解的作用是声明 Quarkus 测试类。在 @BeforeAll 注解声明的初始化方法中,我们使用 Mockito 来模拟 AddressResource 类中用到的 AddressService 和 AreaService 对象,其中模拟的 AddressService 对象的 search 方法,总是返回包含单个特定的 AddressVO 对象的列表。QuarkusMock 的 installMockForType 方法用来注册 Mock 对象。
在 testSearch 方法中,我们通过 REST Assured 库来发送请求到 REST 资源,并验证 HTTP 响应的状态码和内容,返回的 JSON 数组中应该只包含一个元素。
@QuarkusTest
public class AddressResourceTest {
@BeforeAll
public static void setup() {
AddressService addressService = Mockito.mock(AddressService.class);
Mockito.when(addressService.search(anyLong(), anyString())).thenReturn(
Collections.singletonList(createAddress()));
QuarkusMock.installMockForType(addressService, AddressService.class);
QuarkusMock
.installMockForType(Mockito.mock(AreaService.class), AreaService.class);
}
@Test
public void testSearch() {
given()
.when()
.queryParam("areaCode", "1")
.queryParam("query", "test")
.get("/search")
.then()
.statusCode(200)
.body("$", hasSize(1));
}
private static AddressVO createAddress() {
AddressVO address = new AddressVO();
address.setId(UUID.randomUUID().toString());
address.setAreaId(0);
address.setAddressLine("Test");
address.setLat(BigDecimal.ZERO);
address.setLng(BigDecimal.ONE);
return address;
}
}
本地开发
在本地开发中,我们可以通过下面的命令来启动 Quarkus 应用。
$ mvn quarkus:dev
通过这种方式启动的Quarkus应用运行在开发模式,会应用概要文件 dev。在开发模式中,Quarkus支持热部署。在修改了 Java 代码或资源文件之后,当刷新浏览器时,Quarkus 会重新编译 Java 文件,并重新部署应用。开发人员并不需要重启服务器,就可以查看更新之后的结果,这种开发模式,可以极大地提升开发效率。
应用打包
使用 mvn package 命令可以对 Quarkus 应用进行打包。在运行完该命令之后,除了标准的 JAR 文件之外,还会生成一个带 runner 后缀的 JAR 文件,用来启动应用。运行应用所需的第三方依赖导出在 lib 目录中。在发布应用时,只需要把带 runner 后缀的 JAR 文件和 lib 目录复制到同一个目录下,并使用 java -jar 命令来运行 JAR 文件即可。
在云平台上运行时,我们需要创建 Quarkus 应用的容器镜像。在 Quarkus 应用的骨架代码中,Maven 项目的 src/main/docker 目录中已经包含了 3 个 Dockerfile,如下表所示。
| Dockerfile | 说明 |
|---|---|
| Dockerfile.jvm | 在 JVM 中运行,使用带 runner 后缀的 JAR 文件 |
| Dockerfile.fast-jar | 在 JVM 中运行,使用 fast-jar 的打包格式 |
| Dockerfile.native | 打包成 GraalVM 的原生镜像 |
fast-jar 是 Quarkus 1.5 中引入的新打包格式,可以提升启动速度。打包的应用会出现在 target/quarkus-app 目录下,需要在配置文件中添加额外的选项来启用这种打包方式,如下所示。
quarkus.package.type=fast-jar
通过下面的命令可以构建出相应的容器镜像。
$ docker build -f src/main/docker/Dockerfile.fast-jar -t quarkus/happyride-address-service-quarkus-jvm .
原生镜像
在创建原生镜像之前,首先要安装 GraalVM。我们可以从 GraalVM 的 GitHub 上下载 GraalVM 的社区版,也可以通过 Homebrew 或 SDKMAN 这样的工具来安装,安装版本为 20.1.0。安装之后,需要配置环境变量 GRAALVM_HOME 来指向安装目录。
GraalVM 的原生镜像生成工具是一个可选的组件,需要手动安装,可使用下面的命令来安装组件 native-image。
${GRAALVM_HOME}/bin/gu install native-image
使用下面的命令可以创建出 Quarkus 应用的可执行文件,quarkus.native.container-build=true 选项的作用是创建适用于容器运行的原生可执行文件。需要注意的是,创建原生镜像需要较大的内存资源,并且比较耗时,需要确保 Docker 运行时有足够的内存资源。
$ mvn package -Pnative -Dquarkus.native.container-build=true
接着使用下面的命令来创建容器镜像。
$ docker build -f src/main/docker/Dockerfile.native -t quarkus/happyride-address-service-quarkus-native .
下面的代码给出了 docker images 命令的输出,从中可以看到,使用 GraalVM 原生镜像的容器镜像的尺寸只有 182 M,远小于使用 JVM 的容器镜像。除了容器镜像的尺寸之外,原生镜像的容器的启动速度也更快。
REPOSITORY SIZE
quarkus/happyride-address-service-quarkus-native 182MB
quarkus/happyride-address-service-quarkus-jvm 533MB
总结
在云原生微服务架构应用的开发中,我们可以使用不同的 Java 微服务开发框架,并不仅限于 Spring Boot。通过本课时的学习,你可以了解到微服务开发框架 Quarkus,以及如何用 Quarkus 来开发和测试微服务,并构建出原生镜像,从而提高微服务的启动速度。
第45讲:消费者驱动的服务契约测试
本课时作为云原生微服务专栏的最后一个课时,将介绍如何进行消费者驱动的服务契约测试。
API 测试
在云原生微服务架构应用的开发中,一个很重要的问题是如何对单个微服务的 API 进行测试。第 10 课时介绍了 API 优先的设计策略,也就是从 OpenAPI 规范文档出发,让 API 的消费者和提供者可以并行工作。OpenAPI 规范成为 API 的消费者和提供者之间的契约,OpenAPI 规范文档通过消费者和提供者的协商和沟通来确定,这种方式虽然保证了 API 契约的稳定性,但是存在一个很大的问题,那就是如何验证提供者所实际提供的 API 满足契约的要求。
下图给出了一个微服务架构应用中的不同微服务之间的 API 调用关系,其中服务 A 需要调用服务 B 和 D 的 API。当需要测试服务 A 时,一种做法是在所有服务都部署之后,再进行集成测试。这种做法的问题是测试环境的搭建很复杂,除了每个服务自身之外,还需要运行其他支撑服务。
另外一种做法是为服务 B 和 D 分别创建模拟对象(Mock),由 Mock 来模拟服务 B 和 D 的功能。这种做法的好处是运行测试的环境简单,测试的执行速度也很快,也是一般使用的做法。
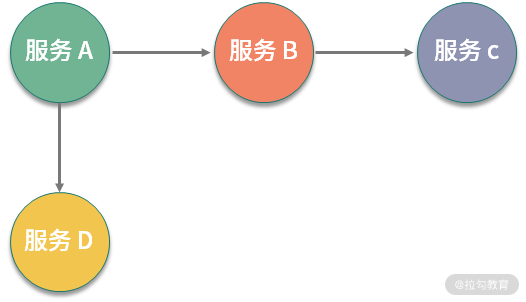
模拟对象一般由 API 的消费者来创建,比如,服务 A 需要创建服务 B 和 D 的模拟对象。由于模拟对象由 API 消费者来创建,所以模拟对象反映的是消费者对于 API 的理解,与 API 提供者对 API 的理解可能存在偏差。当服务 A 完成测试,并与服务 B 和 D 进行集成时,可能会发现在运行时出现错误。这种问题的出现,会大大降低服务 A 的测试的可信度。
消费者驱动的契约
消费者驱动的契约(Consumer Driven Contract)是一种 API 开发的实践,把行为驱动开发的思想应用到了 API 的设计中,消费者驱动的含义是由 API 的消费者来驱动 API 的设计。如果 API 的目的是满足消费者的需求,那么 API 的消费者对于 API 有决定权,包括 API 中包含的全部路径,以及每个路径的请求和响应的内容格式。API 的提供者需要按照消费者指定的契约,来完成 API 的具体实现。
消费者驱动的契约的不足之处在于,它并不适合于开放 API 的设计,因为开放 API 有非常多的消费者,不太可能为了单个消费者而做出改变。微服务之间的 API 则没有这个限制,可以使用消费者驱动的方式来设计。
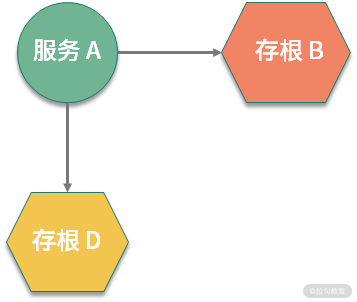
本课时通过 Spring Cloud Contract 来说明消费者驱动的契约的做法。Spring Cloud Contract 的特点是从声明式的契约中自动创建出可执行的存根代码,以及测试用例。
在下图中,服务 B 和 D 分别被替换成相应的存根,测试运行起来更简单。
本课时所介绍的示例与专栏所使用的示例存在一定的关联性,但是对应用的场景进行了简化。本课时的示例中各有一个 API 的提供者和消费者,API 的提供者是验证行程的服务,而消费者是行程管理服务。当行程管理服务接收到创建行程的请求时,需要调到行程验证服务来进行验证,并根据返回的结果来进行不同的处理。这个示例的场景非常简单,可以展示 Spring Cloud Contract 的用法。完整的代码请在 GitHub中下载。
从实际的业务场景来说,API 的提供者和消费者之间的契约很简单,在验证行程时,需要提供行程的金额数量,返回的结果则说明行程是否有效。当金额小于或等于 1000 时,行程被认为有效;否则,行程被认为是无效的。虽然场景简单,但实际的契约需要更加具体的描述。如果以 API 优先的方式来设计,会先从 OpenAPI 文档规范开始。下面我们来看一下如何使用消费者驱动的契约来完成。
创建契约
首先需要由消费者来创建契约,契约并不是以 OpenAPI 规范文档这样的形式化方式来描述,而只是一些请求和对应的响应示例,每个示例称为一个契约。API 的消费者根据需求,定义出需要使用的 API 路径、请求和响应的内容。从这里就可以看出契约和 OpenAPI 规范的最大区别:OpenAPI 规范描述的是 API 的请求和响应内容的格式,而契约则描述的是具体的请求和期望的响应实例。
下面的代码给出了行程验证服务的 OpenAPI 规范文档的声明,其中包含了一个路径 /trip_validation,以及 POST 方法的请求格式和响应格式。从这个规范中我们可以看到,表示请求的 TripValidationRequest 类型中有一个 double 类型的 amount 属性,而表示响应的 TripValidationResponse 类型中有一个 boolean 类型的 valid 属性。很明显,表示金额的 amount 属性的值,与作为结果的 valid 属性之间,存在业务逻辑上的对应关系,但是这个对应关系没有体现在 OpenAPI 文档规范中。
openapi: '3.0.3'
info:
title: 行程验证服务
version: '1.0'
servers:
- url: http://localhost:8090/
tags:
- name: trip
description: 行程
paths:
/trip_validation:
post:
tags:
- trip
summary: 验证行程
operationId: validateTrip
requestBody:
content:
application/json:
schema:
$ref: "#/components/schemas/TripValidationRequest"
required: true
responses:
'200':
description: 验证结果
content:
application/json:
schema:
$ref: "#/components/schemas/TripValidationResponse"
components:
schemas:
TripValidationRequest:
type: object
properties:
amount:
type: number
format: double
required:
- amount
TripValidationResponse:
type: object
properties:
valid:
type: boolean
required:
- valid
与 OpenAPI 规范不同,契约描述的是请求和响应的示例。我们可以使用 Groovy 或 YAML 来描述契约,推荐使用 Groovy,因为可以使用 IDE 来进行代码提示和编译检查。下面是一个契约的 Groovy 代码的示例。
Groovy 文件的名称是 tripValidationPassed.groovy,并保存在 API 提供者项目的 src/test/resources/contracts/trip 目录中。根据命名惯例,契约文件被存放在 src/test/resources/contracts 目录中,不同的子目录代表不同的功能集。
Groovy 文件通过 DSL 来描述请求和响应的契约。Contract.make 方法用来创建新的 Contract 对象。在 DSL 中,request 描述 HTTP 请求的详情,包括 HTTP 方法、URL、请求内容和 HTTP 头;response 描述 HTTP 响应的详情,包括 HTTP 状态码、响应内容和 HTTP 头。该契约描述的场景是,当请求的 amount 属性的值为 999 时,返回的响应中的 valid 属性的值为 true。
package contracts.trip
import org.springframework.cloud.contract.spec.Contract
Contract.make {
request {
method 'POST'
url '/trip_validation'
body([
amount: 999.00
])
headers {
contentType('application/json')
}
}
response {
status OK()
body([
valid: true
])
headers {
contentType('application/json')
}
}
}
与上述契约相似的是另外一个名为 tripValidationFailed.groovy 的契约,用来描述行程验证不通过的场景,该契约的请求中 amount 的值为 1100,而响应中 valid 的值为 false。
需要注意的是,我们只添加了两个契约,分别对应行程验证的结果为有效和无效这两种情况。在契约中所指定的 amount 的具体值并不重要,只需要满足所限定的条件即可。
生成存根代码
契约被添加在 API 提供者项目中,我们接着从契约中生成存根代码。存根代码的生成由 Spring Cloud Contract 的 Maven 插件来完成,下面的代码展示了如何配置该 Maven 插件。
<plugin>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-contract-maven-plugin</artifactId>
<version>${spring-cloud-contract.version}</version>
<extensions>true</extensions>
<configuration>
<testFramework>JUNIT5</testFramework>
<packageWithBaseClasses>io.vividcode.contract.trip
</packageWithBaseClasses>
</configuration>
</plugin>
在运行了 mvn clean install -DskipTests 命令之后,会在 targets 目录生成一个带 stubs 后缀的 JAR 文件,该文件就是生成的存根代码,它被安装到了本地 Maven 仓库中。
API 消费者的测试
我们再回到 API 的消费者,也就是行程管理服务,这其中的 REST 控制器如下面的代码所示。在 createTrip 方法中,首先使用 TripService 来计算出行程的费用金额,再调用行程验证服务的 API 来进行验证,最后根据验证结果返回不同的响应。行程验证服务的 URL 通过配置项 trip_validation.url 来指定。
@RestController
public class TripController {
@Value("${trip_validation.url:}")
String tripValidationServiceUrl;
@Autowired
TripService tripService;
@Autowired
RestTemplate restTemplate;
@PostMapping(value = "/trip", consumes = MediaType.APPLICATION_JSON_VALUE)
public ResponseEntity<Response<CreateTripData>> createTrip(
@RequestBody CreateTripRequest request) {
double amount = this.tripService
.calculate(request.getStart(), request.getEnd());
ResponseEntity<TripValidationResponse> response = this.restTemplate
.exchange(RequestEntity
.post(
URI.create(this.tripValidationServiceUrl + "/trip_validation"))
.contentType(MediaType.APPLICATION_JSON)
.body(new TripValidationRequest(amount)),
TripValidationResponse.class);
if (response.getBody() != null
&& response.getBody().isValid()) {
return ResponseEntity.ok(Response
.success(new CreateTripData(UUID.randomUUID().toString())));
}
return ResponseEntity.ok(Response.error(new Error(100, "invalid trip")));
}
}
在 API 消费者项目中,我们添加对 TripController 的测试用例,测试用例的完整代码如下所示。该测试用例是一个标准的 Spring Boot 测试,在测试时,会在随机端口启动 Spring Boot 服务器,并通过 REST Assured 发送 HTTP 请求到 TripController,然后验证响应的内容是否正确。变量 serverPort 表示的是 Spring Boot 服务器实际运行的端口。
@SpringBootTest(webEnvironment = WebEnvironment.RANDOM_PORT)
@AutoConfigureStubRunner(stubsMode = StubRunnerProperties.StubsMode.LOCAL, ids = "io.vividcode:producer")
@DisplayName("Trip validation")
public class TripValidationTest {
@Autowired
TripController tripController;
@LocalServerPort
int serverPort;
@StubRunnerPort("producer")
int producerPort;
@BeforeEach
public void setupProducer() {
this.tripController.tripValidationServiceUrl =
"http://localhost:" + this.producerPort;
}
@Test
@DisplayName("validation success")
public void testTripValidationSuccess() {
given()
.body(new CreateTripRequest("test1", "test", "normal"))
.contentType("application/json")
.post("http://localhost:" + this.serverPort + "/trip")
.then()
.statusCode(200)
.body("status", is("SUCCESS"));
}
@Test
@DisplayName("validation failed")
public void testTripValidationFailed() {
given()
.body(new CreateTripRequest("test1", "test", "long"))
.contentType("application/json")
.post("http://localhost:" + this.serverPort + "/trip")
.then()
.statusCode(200)
.body("status", is("ERROR"));
}
}
在这个测试用例中,我们用到了一个特殊的注解 @AutoConfigureStubRunner 来运行契约对应的存根代码,该注解的属性 stubsMode 表示的是获取存根代码的方式,LOCAL 表示从本地 Maven 仓库中获取,而 REMOTE 则表示从远程 Maven 仓库中获取。属性 ids 表示的是存根代码的 Maven 工件的标识符,当不指定版本号时,默认使用最新版本的工件,属性 ids 的值与 API 提供者相对应。
在测试的运行过程中,Spring Cloud Contract 会启动一个 WireMock服务器,并把契约中声明的请求和响应规则,添加到 WireMock 中。当 TripController 访问行程验证服务时,实际访问的是 WireMock 服务器,而 WireMock 会根据契约来返回不同请求对应的响应。由于 WireMock 会在随机端口启动,@StubRunnerPort 注解用来获取实际运行的端口,并绑定到字段 producerPort 中。在进行测试之前,会使用 producerPort 字段来设置 TripController 所连接的行程验证服务的 URL。从底层的实现来说,Spring Cloud Contract 实际上把契约文件,转换成了 WireMock 的 JSON 配置文件,由 WireMock 模拟 API 提供者的行为。
为了运行存根代码,需要添加下面代码中给出的 Maven 依赖。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-contract-stub-runner</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</exclusion>
</exclusions>
</dependency>
使用 mvn test 命令就可以进行 API 消费者的测试,通过这种方式,API 消费者可以确保遵循了契约来调用 API。
API 提供者的测试
我们接着需要确保 API 的提供者正确的实现了契约。下面代码给出了行程验证服务的控制器的实现,该控制器的实现非常简单,只是根据 amount 的值来进行判断。
@RestController
public class TripValidationController {
@PostMapping("/trip_validation")
public TripValidationResponse validate(
@RequestBody TripValidationRequest request) {
boolean valid = request.amount <= 1000;
return new TripValidationResponse(valid);
}
}
我们可以使用 Spring Cloud Contract 的 Maven 插件来从契约中自动生成测试用例,只需要使用 mvn generate-test-sources 命令即可。在生成之前,首先需要创建一个类作为生成的测试用例的基类。
下面代码中的 TripBase 类是行程验证服务的测试的基类。在 setup 方法中,通过 RestAssuredMockMvc 的 standaloneSetup 方法来配置需要访问的控制器对象;基类的名称 TripBase 是通过命名惯例得到的,其中的后缀 Base 是固定的,而 Trip 来自契约文件所在的目录的名称。
public class TripBase {
@BeforeEach
public void setup() {
RestAssuredMockMvc.standaloneSetup(new TripValidationController());
}
}
下面代码中的 TripTest 是自动生成的测试类,其中的每个测试方法对应于一个契约。在每个测试中,根据契约中声明的请求和响应的内容,REST Assured 会发送请求到控制器,并验证响应的内容。
public class TripTest extends TripBase {
@Test
public void validate_tripValidationFailed() throws Exception {
// given:
MockMvcRequestSpecification request = given()
.header("Content-Type", "application/json")
.body("{\"amount\":1100.00}");
// when:
ResponseOptions response = given().spec(request)
.post("/trip_validation");
// then:
assertThat(response.statusCode()).isEqualTo(200);
assertThat(response.header("Content-Type")).matches("application/json.*");
// and:
DocumentContext parsedJson = JsonPath.parse(response.getBody().asString());
assertThatJson(parsedJson).field("['valid']").isEqualTo(false);
}
@Test
public void validate_tripValidationPassed() throws Exception {
// given:
MockMvcRequestSpecification request = given()
.header("Content-Type", "application/json")
.body("{\"amount\":100.00}");
// when:
ResponseOptions response = given().spec(request)
.post("/trip_validation");
// then:
assertThat(response.statusCode()).isEqualTo(200);
assertThat(response.header("Content-Type")).matches("application/json.*");
// and:
DocumentContext parsedJson = JsonPath.parse(response.getBody().asString());
assertThatJson(parsedJson).field("['valid']").isEqualTo(true);
}
}
通过自动化单元测试的做法,我们可以保证 API 提供者的实现,满足消费者所声明的契约的要求。考虑下面一种情况,如果 API 提供者认为行程金额的上限 1000 的值过高,而需要改成 900,那么可以修改 TripValidationController 的实现,把其中的一行修改成如下所示:
boolean valid = request.amount <= 900;
再运行测试时会发现测试失败,产生的错误如下所示。从错误中可以看到,契约中的声明是,当 amount 值为 999 时,响应中的 valid 的值应该为 true,而 TripValidationController 实际返回的响应中的 valid 的值是 false,这就表示了契约被破坏。
[ERROR] Tests run: 2, Failures: 0, Errors: 1, Skipped: 0, Time elapsed: 1.767 s <<< FAILURE! - in io.vividcode.contract.trip.TripTest
[ERROR] validate_tripValidationPassed Time elapsed: 0.033 s <<< ERROR!
java.lang.IllegalStateException: Parsed JSON [{"valid":false}] doesn't match the JSON path [$[?(@.['valid'] == true)]]
at io.vividcode.contract.trip.TripTest.validate_tripValidationPassed(TripTest.java:56)
契约被破坏的原因有很多,有可能是 API 提供者的业务逻辑产生了变化,也有可能是 API 提供者的实现产生了 bug。如果是前者,那么契约应该被更新,以反映业务逻辑的变化;如果是后者,则 API 提供者应该修改自身的实现。不管是哪种情况,契约的存在,以及确保契约被遵守的自动化测试,都可以保证 API 的稳定性。
工作模式
最后介绍一下使用消费者驱动的契约时的工作模式,契约虽然是保存在 API 提供者项目中,但是由 API 消费者来创建的。消费者团队的开发人员可以直接对提供者的项目进行修改,也可以通过 Pull Request 的方式来提交改动,这就明确了消费者对契约的所有权。
在实际的开发中,契约的存根 JAR 文件会被发布到远程的 Maven 仓库中,这样保证了团队的所有人员都可以使用存根代码来运行测试。每次对契约进行了修改之后,只需要重新运行 Maven 插件来生成存根代码即可。存根代码有自己的版本,可以追踪变化的历史记录。
总结
微服务架构的应用中的集成测试是一个很复杂的问题,使用消费者驱动的服务契约测试,可以很好地解决测试的运行速度和可靠性的问题。通过本课时的学习,你可以了解消费者驱动的契约测试的基本概念,以及如何用 Spring Cloud Contract 来实现。
结束语:微服务架构展望
你好,本专栏的内容到这里已经全部更新完毕了。在这个专栏中,我对云原生微服务相关的很多内容都进行了介绍,比如涉及开发、测试、部署和运维等多个方面,每个方面又有非常多关联的概念和技术,要全部了解这些相关知识并不是一件容易的事情,因为除了已有的概念和技术之外,技术本身也在不断推陈出新。本课时将对云原生微服务架构相关的技术进行展望。
云原生技术是微服务落地的最佳搭配
云原生微服务架构是云原生技术和微服务架构的结合。微服务作为一个架构风格,所解决的问题是复杂软件系统的架构与设计;云原生技术是一种实现方式,所解决的问题是软件系统的运行和维护。微服务架构可以选择不同的实现方式,如 Spring Cloud 或私有实现,并不一定非要使用云原生技术;同样的,云原生技术可以用来实现不同架构的应用,包括微服务应用或是单体应用。
不过,云原生技术和微服务架构确实是非常适合的组合。这其中的原因在于,云原生技术可以有效地弥补微服务架构所带来的实现上的复杂度;微服务架构难以落地的一个重要原因是它过于复杂,对开发团队的组织管理、技术水平和运维能力都提出了极高的要求。因此,一直以来只有少数技术实力雄厚的大企业会采用微服务架构。随着云原生技术的流行,在弥补了微服务架构的这一个短板之后,极大地降低了微服务架构实现的复杂度,使得广大的中小企业有能力在实践中应用微服务架构。云原生技术促进了微服务架构的推广,也是微服务架构落地的最佳搭配。
云原生技术的发展趋势一
云原生技术的第一个发展趋势是标准化和规范化,该技术的基础是容器化和容器编排技术,最经常会用到的技术是 Kubernetes 和 Docker 等。随着云原生技术的发展,在 CNCF 和 Linux 基金会等组织的促进下,云原生技术的标准化和规范化工作正在不断推进,其目的是促进技术的发展和避免供应商锁定的问题,这对于整个云原生技术的生态系统是至关重要的。
目前已经有的标准和规范包括开放容器倡议(Open Container Initiative)提出的镜像规范和运行时规范,以及 CNCF 中的一些项目,如下表所示:
| 项目名称 | 说明 |
|---|---|
| OpenMetrics | 性能指标数据的输出格式 |
| OpenTelemetry | 遥测数据收集规范,由 OpenTracing 和 OpenCensus 项目合并而来 |
| Service Mesh Interface | 服务网格规范 |
| Serverless Workflow | Serverless 应用的声明式工作流规范 |
云原生技术的发展趋势二
云原生技术的第二个发展趋势是平台化,以服务网格技术为代表,这一趋势的出发点是增强云平台的能力,从而降低运维的复杂度。流量控制、身份认证和访问控制、性能指标数据收集、分布式服务追踪和集中式日志管理等功能,都可以由底层平台来提供,这就极大地降低了中小企业在运行和维护云原生应用时的复杂度。从另外一个方面来说,这也促进了相关开源软件和商业解决方案的发展。我们看到了 Istio 和 Linkerd 这样的开源服务网格实现的流行,也有越来越多的公司提供商用的支持,这给不同技术水平的企业提供了最适合的选择。
云原生技术的发展趋势三
云原生技术的第三个发展趋势是应用管理技术的进步,以操作员(Operator)模式为代表。在 Kubernetes 平台上部署和更新应用一直以来都比较复杂,传统的基于资源声明 YAML 文件的做法,已经逐步被 Helm 所替代。操作员模式在 Helm 的基础上更进一步,以更高效、自动化和可扩展的方式对应用部署进行管理。CNCF 中的孵化项目 Operator Framework 是创建 Operator 的框架,OperatorHub 则是社区共享 Operator 实现的平台。
云原生技术的发展趋势四
最后一个发展趋势与云原生应用开发相关。我们看到了越来越多的微服务开发框架的出现,不同的编程语言都有相应的开源实现,以 Java 平台为例,Quarkus、Micronaut、Helidon 和 Eclipse MicroProfile 都是流行的选择。这些框架对微服务开发做了很多优化,尽可能地降低应用第三方依赖的数量。GraalVM 的原生镜像功能,可以创建出尺寸小、启动速度快、耗费资源更少的 Java 微服务容器镜像。可以预期的是,所有的 Java 微服务框架都会提供 GraalVM 的支持。
结语
以上就是关于云原生技术的一些发展趋势展望,希望可以对正在学习云原生技术的你有所帮助。在学习云原生技术时,最重要的是找准学习重点并加以实践,根据每个开发人员在团队中的职责,所要学习和侧重的点也不同,可能是开发、测试或是运维相关的内容。
-
从开发来说,需要掌握微服务开发框架的使用,以及单元测试的编写,并考虑与容器化技术的集成;
-
从测试来说,需要掌握云原生微服务中集成测试的执行与自动化,尤其是 API 契约测试;
-
从运维来说,需要掌握云原生应用的部署、更新和维护,包括相关开源工具的使用、第三方服务的集成,以及运行时的故障恢复等。
云原生微服务应用的开发和运维是一个系统工程,不同的开发人员都可以在团队中找到适合的位置。通过不断地实战开发和经验积累,来逐步提升自己对技术的认识,增强技术实力。
如果你觉得课程不错,从中有所收获的话,不要忘了推荐给身边的朋友哦。前路漫漫,一起加油~















 1090
1090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











