









19 如何搞清楚事务、连接池的关系?正确配置是怎样的?
你好,欢迎继续学习 Spring Data JPA 原理与实战。上一课时,我们讲解了数据源的基本原理和工作方式,你知道了数据源是创建数据连接的入口,数据源里面获得连接的时候也采用了连接池。那么这一讲我们来看下事务在 JPA 和 Spring 里面的详细配置和原理。
事务的基本原理
在学习 Spring 的事务之前,你首先要了解数据库的事务原理,我们以 MySQL 5.7 为例,讲解一下数据库事务的基础知识。
我们都知道 当 MySQL 使用 InnoDB 数据库引擎的时候,数据库是对事务有支持的。而事务最主要的作用是保证数据 ACID 的特性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),下面来一一解释。
原子性: 是指一个事务(Transaction)中的所有操作,要么全部完成,要么全部回滚,而不会有中间某个数据单独更新的操作。事务在执行过程中一旦发生错误,会被回滚(Rollback)到此次事务开始之前的状态,就像这个事务从来没有执行过一样。
一致性: 是指事务操作开始之前,和操作异常回滚以后,数据库的完整性没有被破坏。数据库事务 Commit 之后,数据也是按照我们预期正确执行的。即要通过事务保证数据的正确性。
持久性: 是指事务处理结束后,对数据的修改进行了持久化的永久保存,即便系统故障也不会丢失,其实就是保存到硬盘。
隔离性: 是指数据库允许多个连接,同时并发多个事务,又对同一个数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时,由于交叉执行而导致数据不一致的现象。而 MySQL 里面就是我们经常说的事务的四种隔离级别,即读未提交(Read Uncommitted)、读提交(Read Committed)、可重复读(Repeatable Read)和串行化(Serializable)。
由于隔离级别是事务知识点中最基础的部分,我们就简单介绍一下四种隔离级别。但是它特别重要,你要好好掌握。
四种 MySQL 事务的隔离级别
Read Uncommitted(读取未提交内容):此隔离级别,表示所有正在进行的事务都可以看到其他未提交事务的执行结果。不同的事务之间读取到其他事务中未提交的数据,通常这种情况也被称之为脏读(Dirty Read),会造成数据的逻辑处理错误,也就是我们在多线程里面经常说的数据不安全了。在业务开发中,几乎很少见到使用的,因为它的性能也不比其他级别要好多少。
Read Committed(读取提交内容): 此隔离级别是指,在一个事务相同的两次查询可能产生的结果会不一样,也就是第二次查询能读取到其他事务已经提交的最新数据。也就是我们常说的不可重复读(Nonrepeatable Read)的事务隔离级别。因为同一事务的其他实例在该实例处理期间,可能会对其他事务进行新的 commit,所以在同一个事务中的同一 select 上,多次执行可能返回不同结果。这是大多数数据库系统的默认隔离级别(但不是 MySQL 默认的隔离级别)。
Repeatable Read(可重读): 这是 MySQL 的默认事务隔离级别,它确保同一个事务多次查询相同的数据,能读到相同的数据。即使多个事务的修改已经 commit,本事务如果没有结束,永远读到的是相同数据,要注意它与Read Committed 的隔离级别的区别,是正好相反的。这会导致另一个棘手的问题:幻读 (Phantom Read),即读到的数据可能不是最新的。这个是最常见的,我们举个例子来说明。
第一步:用工具打开一个数据库的 DB 连接,如图所示。
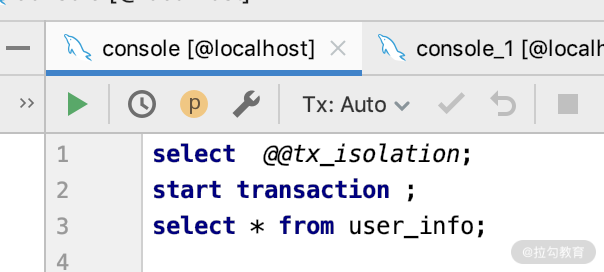
查看一下数据库的事务隔离级别。
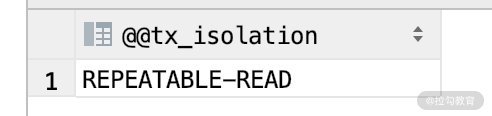
然后开启一个事务,查看一下 user_info 的数据,我们在 user_info 表里面插入了三条数据,如下图所示。
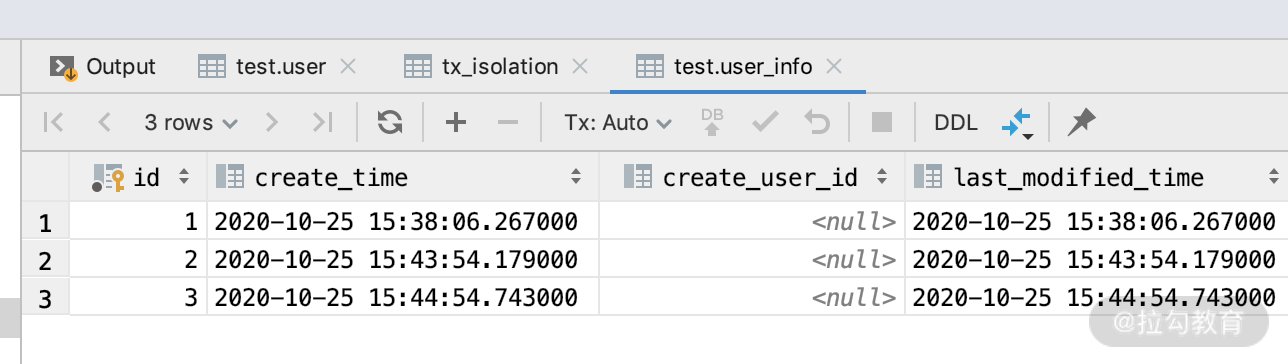
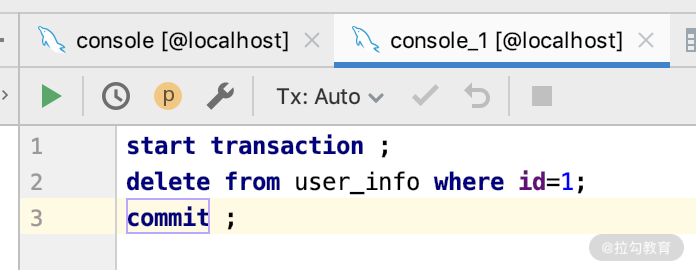
第二步:我们打开另外一个相同数据库的 DB 连接,删除一条数据,SQL 如下所示。
当删除执行成功之后,我们可以开启第三个连接,看一下数据库里面确实少了一条 ID=1 的数据。那么这个时候我们再返回第一个连接,第二次执行 select * from user_info,如下图所示,查到的还是三条数据。这就是我们经常说的可重复读。
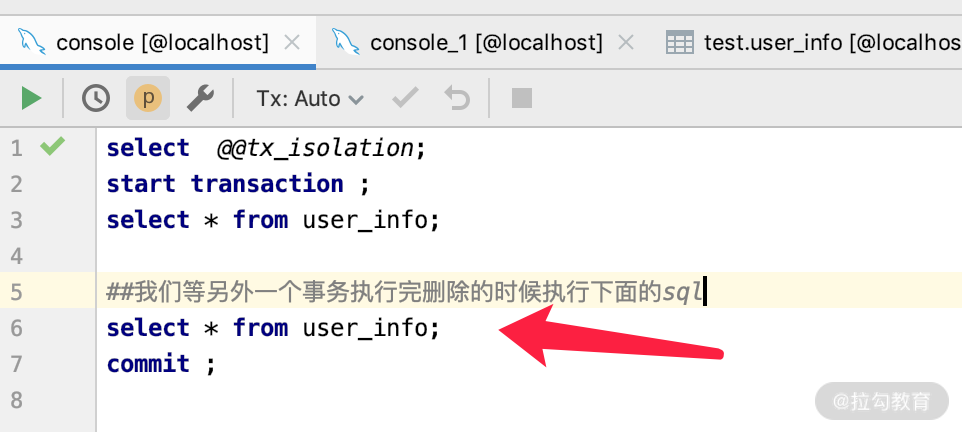
Serializable(可串行化):这是最高的隔离级别,它保证了每个事务是串行执行的,即强制事务排序,所有事务之间不可能产生冲突,从而解决幻读问题。如果配置在这个级别的事务,处理时间比较长,并发比较大的时候,就会导致大量的 db 连接超时现象和锁竞争,从而降低了数据处理的吞吐量。也就是这个性能比较低,所以除了某些财务系统之外,用的人不是特别多。
数据库的隔离级别我们了解完了,并不复杂,这四种类型中,你能清楚地知道Read Uncommitted 和 Read Committed就可以了,一般这两个用得是最多的。
下面看一下数据的事务和连接是什么关系呢?
MySQL 事务与连接的关系
我们要搞清楚事务和连接池的关系,必须要先知道二者存在的前提条件。
-
事务必须在同一个连接里面的,离开连接没有事务可言;
-
MySQL 数据库默认 autocommit=1,即每一条 SQL 执行完自动提交事务;
-
数据库里面的每一条 SQL 执行的时候必须有事务环境;
-
MySQL 创建连接的时候默认开启事务,关闭连接的时候如果存在事务没有 commit 的情况,则自动执行 rollback 操作;
-
不同的 connect 之间的事务是相互隔离的。
知道了这些条件,我们就可以继续探索二者的关系了。在 connection 当中,操作事务的方式只有两种。
MySQL 事务的两种操作方式
第一种:用 BEGIN、ROLLBACK、COMMIT 来实现。
-
BEGIN开始一个事务
-
ROLLBACK事务回滚
-
COMMIT事务确认
第二种:直接用 SET 来改变 MySQL 的自动提交模式。
-
SET AUTOCOMMIT=0禁止自动提交
-
SET AUTOCOMMIT=1开启自动提交
MySQL 数据库的最大连接数是什么?
而任何数据库的连接数都是有限的,受内存和 CPU 限制,你可以通过
show variables like 'max_connections' 查看此数据库的最大连接数、通过 show global status like 'Max_used_connections' 查看正在使用的连接数,还可以通过 set global max_connections=1500 来设置数据库的最大连接数。
除此之外,你可以在观察数据库的连接数的同时,通过观察 CPU 和内存的使用,来判断你自己的数据库中 server 的连接数最佳大小是多少。而既然是连接,那么肯定会有超时时间,默认是 8 小时。
这里我只是列举了 MySQL 数据库的事务处理原理,你可以用相同的思考方式看一下你在用的数据源的事务是什么机制的。
那么学习完了数据库事务的基础知识,我们再看一下 Spring 中事务的用法和配置是什么样的。
Spring 里面事务的配置方法
由于我们使用的是 Spring Boot,所以会通过 TransactionAutoConfiguration.java 加载 @EnableTransactionManagement 注解帮我们默认开启事务,关键代码如下图所示。
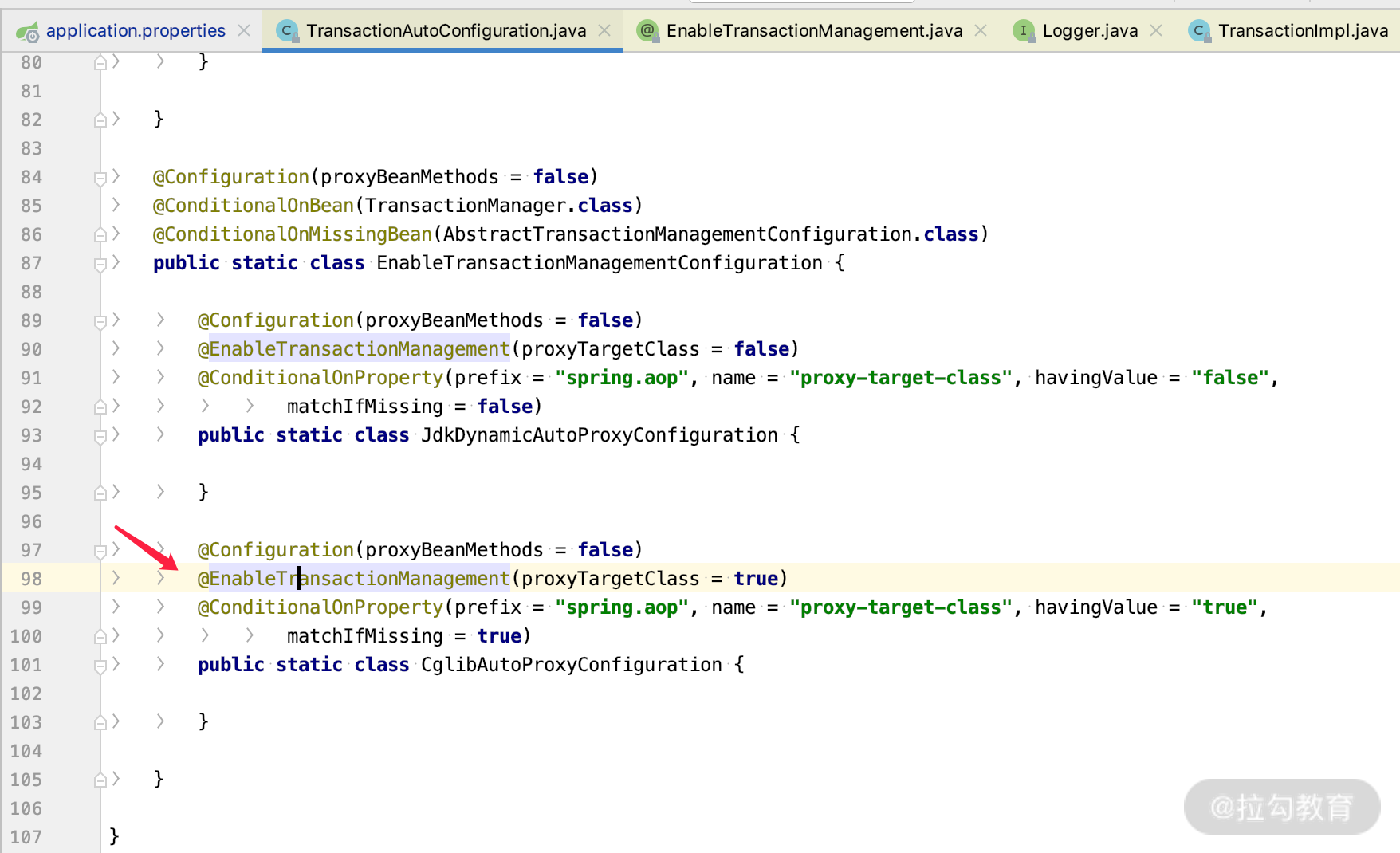
Spring 里面的事务有两种使用方式,常见的是直接通过 @Transaction 的方式进行配置,而我们打开 SimpleJpaRepository 源码类的话,会看到如下代码。
@Repository
@Transactional(readOnly = true)
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID> {
...
@Transactional
@Override
public void deleteAll(Iterable<? extends T> entities) {
.....
我们仔细看源码的时候就会发现,默认情况下,所有 SimpleJpaRepository 里面的方法都是只读事务,而一些更新的方法都是读写事务。
所以每个 Respository 的方法是都是有事务的,即使我们没有使用任何加 @Transactional 注解的方法,按照上面所讲的 MySQL 的 Transactional 开启原理,也会有数据库的事务。那么我们就来看下 @Transactional 的具体用法。
默认 @Transactional 注解式事务
注解式事务又称显式事务,需要手动显式注解声明,那么我们看看如何使用。
按照惯例,我们打开 @Transactional 的源码,如下所示。
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Transactional {
@AliasFor("transactionManager")
String value() default "";
@AliasFor("value")
String transactionManager() default "";
Propagation propagation() default Propagation.REQUIRED;
Isolation isolation() default Isolation.DEFAULT;
int timeout() default TransactionDefinition.TIMEOUT_DEFAULT;
boolean readOnly() default false;
Class<? extends Throwable>[] rollbackFor() default {};
String[] rollbackForClassName() default {};
Class<? extends Throwable>[] noRollbackFor() default {};
String[] noRollbackForClassName() default {};
}
针对 @Transactional 注解中常用的参数,我列了一个表格方便你查看。
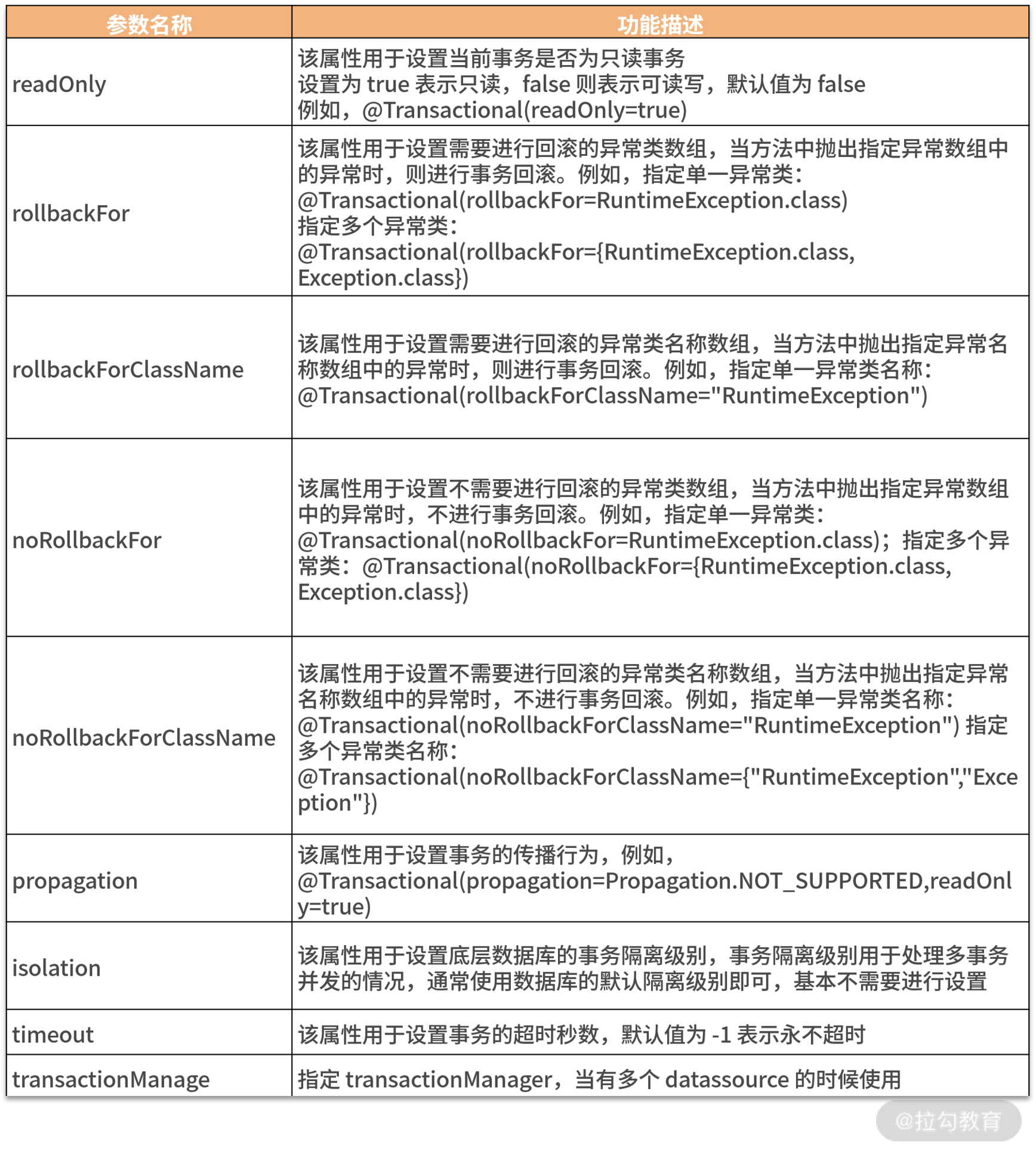
其他属性你基本上都可以知道是什么意思,下面重点说一下隔离级别和事务的传播机制。
隔离级别 Isolation isolation() default Isolation.DEFAULT:默认采用数据库的事务隔离级别。其中,Isolation 是个枚举值,基本和我们上面讲解的数据库隔离级别是一样的,如下图所示。

propagation:代表的是事务的传播机制,这个是 Spring 事务的核心业务逻辑,是 Spring 框架独有的,它和 MySQL 数据库没有一点关系。所谓事务的传播行为是指在同一线程中,在开始当前事务之前,需要判断一下当前线程中是否有另外一个事务存在,如果存在,提供了七个选项来指定当前事务的发生行为。我们可以看 org.springframework.transaction.annotation.Propagation 这类的枚举值来确定有哪些传播行为。7 个表示传播行为的枚举值如下所示。
public enum Propagation {
REQUIRED(0),
SUPPORTS(1),
MANDATORY(2),
REQUIRES_NEW(3),
NOT_SUPPORTED(4),
NEVER(5),
NESTED(6);
}
-
REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。这个值是默认的。
-
SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
-
MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
-
REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起。
-
NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
-
NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
-
NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 REQUIRED。
设置方法:通过使用 propagation 属性设置,例如下面这行代码。
@Transactional(propagation = Propagation.REQUIRES_NEW)
虽然用法很简单,但是也有使用 @Transactional 不生效的时候,那么在哪些场景中是不可用的呢?
@Transactional 的局限性
这里列举的是一个当前对象调用对象自己里面的方法不起作用的场景。
我们在 UserInfoServiceImpl 的 save 方法中调用了带事务的 calculate 方法,代码如下。
@Component
public class UserInfoServiceImpl implements UserInfoService {
@Autowired
private UserInfoRepository userInfoRepository;
/**
* 根据UserId产生的一些业务计算逻辑
*/
@Override
@Transactional(transactionManager = "db2TransactionManager")
public UserInfo calculate(Long userId) {
UserInfo userInfo = userInfoRepository.findById(userId).get();
userInfo.setAges(userInfo.getAges()+1);
//.....等等一些复杂事务内的操作
userInfo.setTelephone(Instant.now().toString());
return userInfoRepository.saveAndFlush(userInfo);
}
/**
* 此方法调用自身对象的方法,就会发现calculate方法上面的事务是失效的
*/
public UserInfo save(Long userId) {
return this.calculate(userId);
}
}
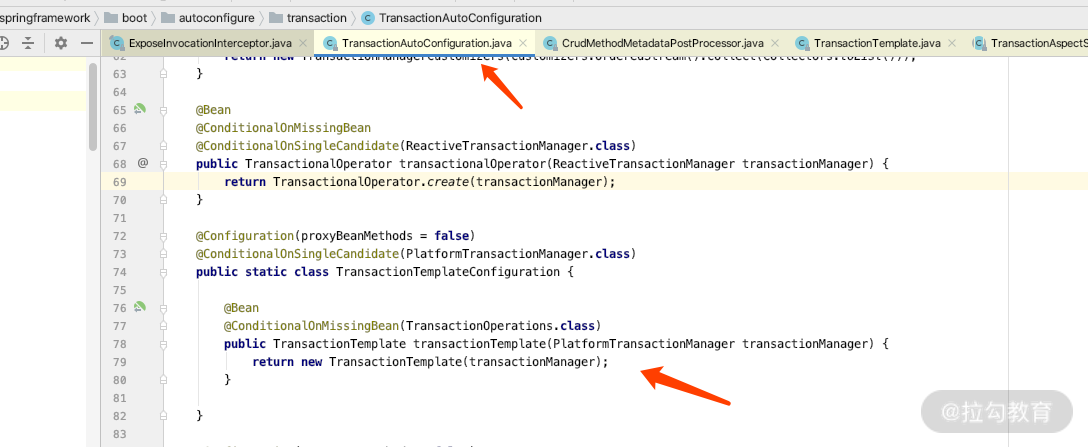
当在 UserInfoServiceImpl 类的外部调用 save 方法的时候,此时 save 方法里面调用了自身的 calculate 方法,你就会发现 calculate 方法上面的事务是没有效果的,这个是 Spring 的代理机制的问题。那么我们应该如何解决这个问题呢?可以引入一个类 TransactionTemplate,我们看下它的用法。
TransactionTemplate 的用法
此类是通过 TransactionAutoConfiguration 加载配置进去的,如下图所示。
我们通过源码可以看到此类提供了一个关键 execute 方法,如下图所示。
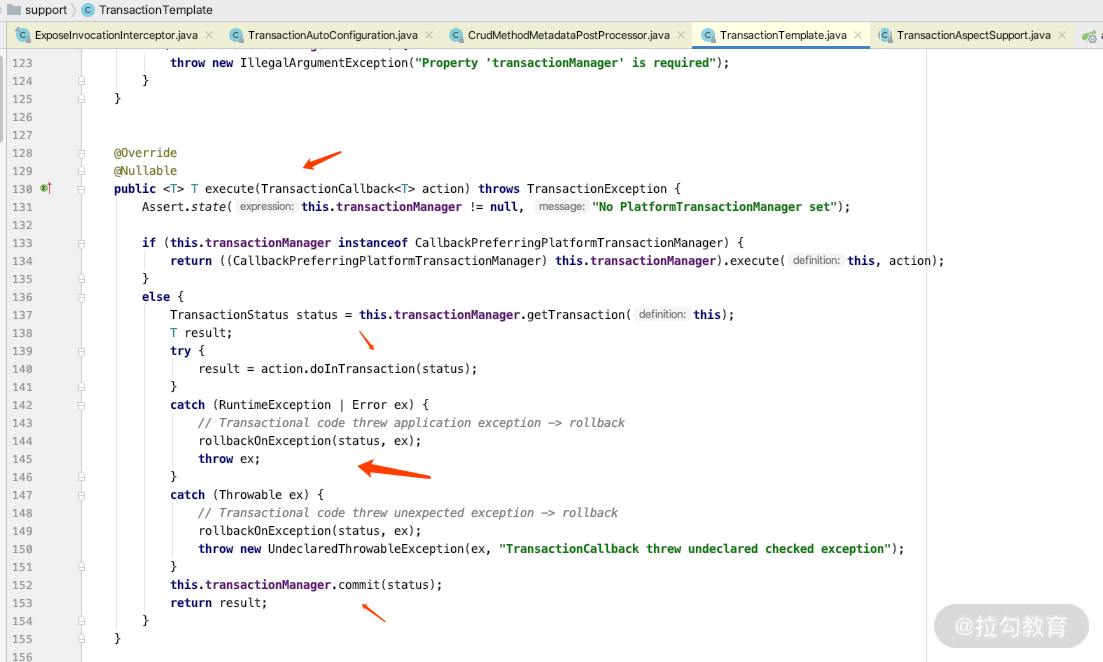
这里面会帮我们处理事务开始、rollback、commit 的逻辑,所以我们用的时候就非常简单,把上面的方法做如下改动。
public UserInfo save(Long userId) {
return transactionTemplate.execute(status -> this.calculate(userId));
}
此时外部再调用我们的 save 方法的时候,calculate 就会进入事务管理里面去了。当然了,我这里举的例子很简单,你也可以通过下面代码中的方法设置隔离级别和传播机制,以及超时时间和是否只读。
transactionTemplate = new TransactionTemplate(transactionManager);
//设置隔离级别
transactionTemplate.setIsolationLevel(TransactionDefinition.ISOLATION_REPEATABLE_READ);
//设置传播机制
transactionTemplate.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
//设置超时时间
transactionTemplate.setTimeout(1000);
//设置是否只读
transactionTemplate.setReadOnly(true);
我们也可以根据 transactionTemplate 的实现原理,自己实现一个 TransactionHelper,一起来看一下。
自定义 TransactionHelper
第一步:新建一个 TransactionHelper 类,进行事务管理,代码如下。
/**
* 利用spring进行管理
*/
@Component
public class TransactionHelper {
/**
* 利用spring 的机制和jdk8的function机制实现事务
*/
@Transactional(rollbackFor = Exception.class) //可以根据实际业务情况,指定明确的回滚异常
public <T, R> R transactional(Function<T, R> function, T t) {
return function.apply(t);
}
}
第二步:直接在 service 中就可以使用了,代码如下。
@Autowired
private TransactionHelper transactionHelper;==
/**
* 调用外部的transactionHelper类,利用transactionHelper方法上面的@Transaction注解使事务生效
*/
public UserInfo save(Long userId) {
return transactionHelper.transactional((uid)->this.calculate(uid),userId);
}
上面我介绍了显式事务,都是围绕 @Transactional 的显式指定的事务,我们也可以利用 AspectJ 进行隐式的事务配置。
隐式事务 / AspectJ 事务配置
只需要在我们的项目中新增一个类 AspectjTransactionConfig 即可,代码如下。
@Configuration
@EnableTransactionManagement
public class AspectjTransactionConfig {
public static final String transactionExecution = "execution (* com.example..service.*.*(..))";//指定拦截器作用的包路径
@Autowired
private PlatformTransactionManager transactionManager;
@Bean
public DefaultPointcutAdvisor defaultPointcutAdvisor() {
//指定一般要拦截哪些类
AspectJExpressionPointcut pointcut = new AspectJExpressionPointcut();
pointcut.setExpression(transactionExecution);
//配置advisor
DefaultPointcutAdvisor advisor = new DefaultPointcutAdvisor();
advisor.setPointcut(pointcut);
//根据正则表达式,指定上面的包路径里面的方法的事务策略
Properties attributes = new Properties();
attributes.setProperty("get*", "PROPAGATION_REQUIRED,-Exception");
attributes.setProperty("add*", "PROPAGATION_REQUIRED,-Exception");
attributes.setProperty("save*", "PROPAGATION_REQUIRED,-Exception");
attributes.setProperty("update*", "PROPAGATION_REQUIRED,-Exception");
attributes.setProperty("delete*", "PROPAGATION_REQUIRED,-Exception");
//创建Interceptor
TransactionInterceptor txAdvice = new TransactionInterceptor(transactionManager, attributes);
advisor.setAdvice(txAdvice);
return advisor;
}
}
这种方式,只要符合我们上面的正则表达规则的 service 方法,就会自动添加事务了;如果我们在方法上添加 @Transactional,也可以覆盖上面的默认规则。
不过这种方法近两年使用的团队越来越少了,因为注解的方式其实很方便,并且注解 @Transactional 的方式更容易让人理解,代码也更简单,你了解一下就好了。
上面的方法介绍完了,那么一个方法经历的 SQL 和过程都有哪些呢?我们通过日志分析一下。
通过日志分析配置方法的过程
大致可以分为以下几个步骤。
第一步,我们在数据连接中加上 logger=Slf4JLogger&profileSQL=true,用来显示 MySQL 执行的 SQL 日志,如图所示。

第二步,打开 Spring 的事务处理日志,用来观察事务的执行过程,代码如下。
# Log Transactions Details
logging.level.org.springframework.orm.jpa=DEBUG
logging.level.org.springframework.transaction=TRACE
logging.level.org.hibernate.engine.transaction.internal.TransactionImpl=DEBUG
# 监控连接的情况
logging.level.org.hibernate.resource.jdbc=trace
logging.level.com.zaxxer.hikari=DEBUG
第三步,我们执行一个 saveOrUpdate 的操作,详细的执行日志如下所示。

通过日志可以发现,我们执行一个 saveUserInfo 的动作,由于在其中配置了一个事务,所以可以看到 JpaTransactionManager 获得事务的过程,图上黄色的部分是同一个连接里面执行的 SQL 语句,其执行的整体过程如下所示。
-
get connection:从事务管理里面,获得连接就 begin 开始事务了。我们没有看到显示的 begin 的 SQL,基本上可以断定它利用了 MySQL 的 connection 初始化事务的特性。
-
set autocommit=0:关闭自动提交模式,这个时候必须要在程序里面 commit 或者 rollback。
-
select user_info:看看 user_info 数据库里面是否存在我们要保存的数据。
-
update user_info:发现数据库里面存在,执行更新操作。
-
commit:执行提交事务。
-
set autocommit=1:事务执行完,改回 autocommit 的默认值,每条 SQL 是独立的事务。
我们这里采用的是数据库默认的隔离级别,如果我们通过下面这行代码,改变默认隔离级别的话,再观察我们的日志。
@Transactional(isolation = Isolation.READ_COMMITTED)
你会发现在开始事务之前,它会先改变默认的事务隔离级别,如图所示。

而在事务结束之后,它还会还原此链接的事务隔离级别,又如下图所示。

如果你明白了 MySQL 的事务原理的话,再通过日志分析可以很容易地理解 Spring 的事务原理。我们在日志里面能看到 MySQL 的事务执行过程,同样也能看到 Spring 的 TransactionImpl 的事务执行过程。这是什么原理呢?我们来详细分析一下。
Spring 事务的实现原理
这里我重点介绍一下 @Transactional 的工作机制,这个主要是利用 Spring 的 AOP 原理,在加载所有类的时候,容器就会知道某些类需要对应地进行哪些 Interceptor 的处理。
例如我们所讲的 TransactionInterceptor,在启动的时候是怎么设置事务的、是什么样的处理机制,默认的代理机制又是什么样的呢?
Spring 事务源码分析
我们在 TransactionManagementConfigurationSelector 里面设置一个断点,就会知道代理的加载类 ProxyTransactionManagementConfiguration 对事务的处理机制。关键源码如下图所示。
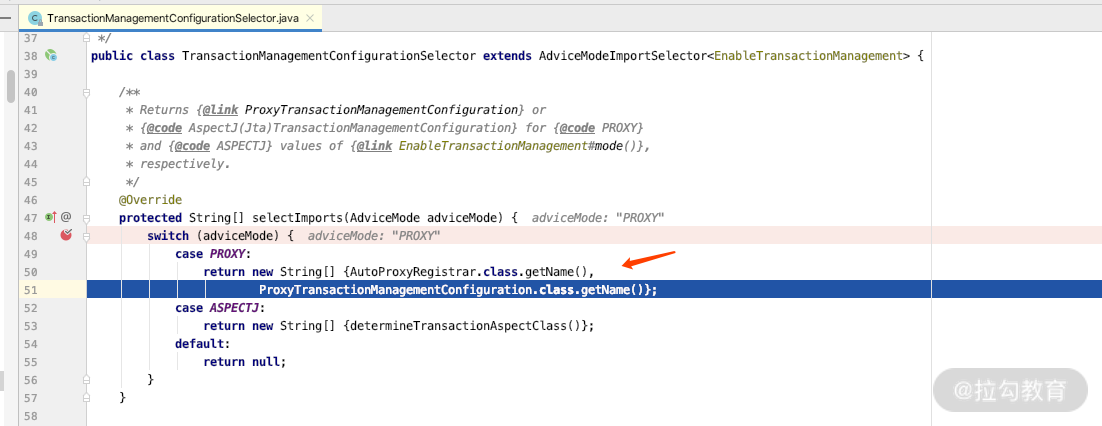
而我们打开 ProxyTransactionManagementConfiguration 的话,就会加载 TransactionInterceptor 的处理类,关键源码如下图所示。
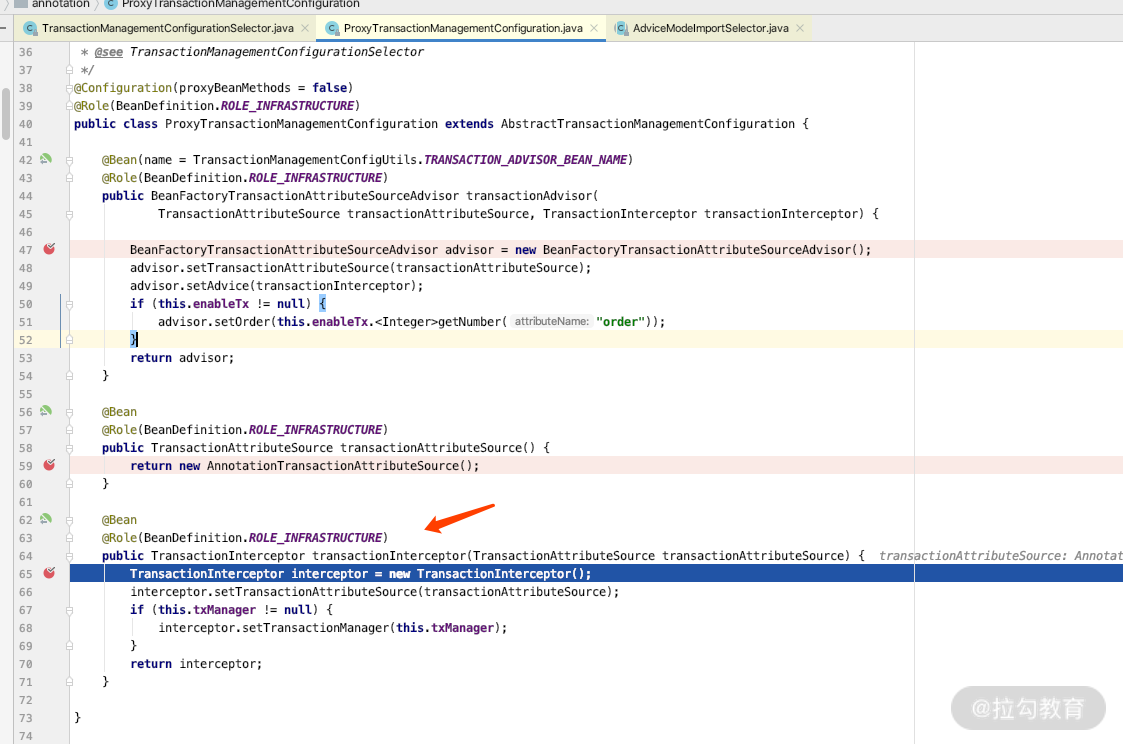
如果继续加载的话,里面就会加载带有 @Transactional 注解的类或者方法。关键源码如下图所示。
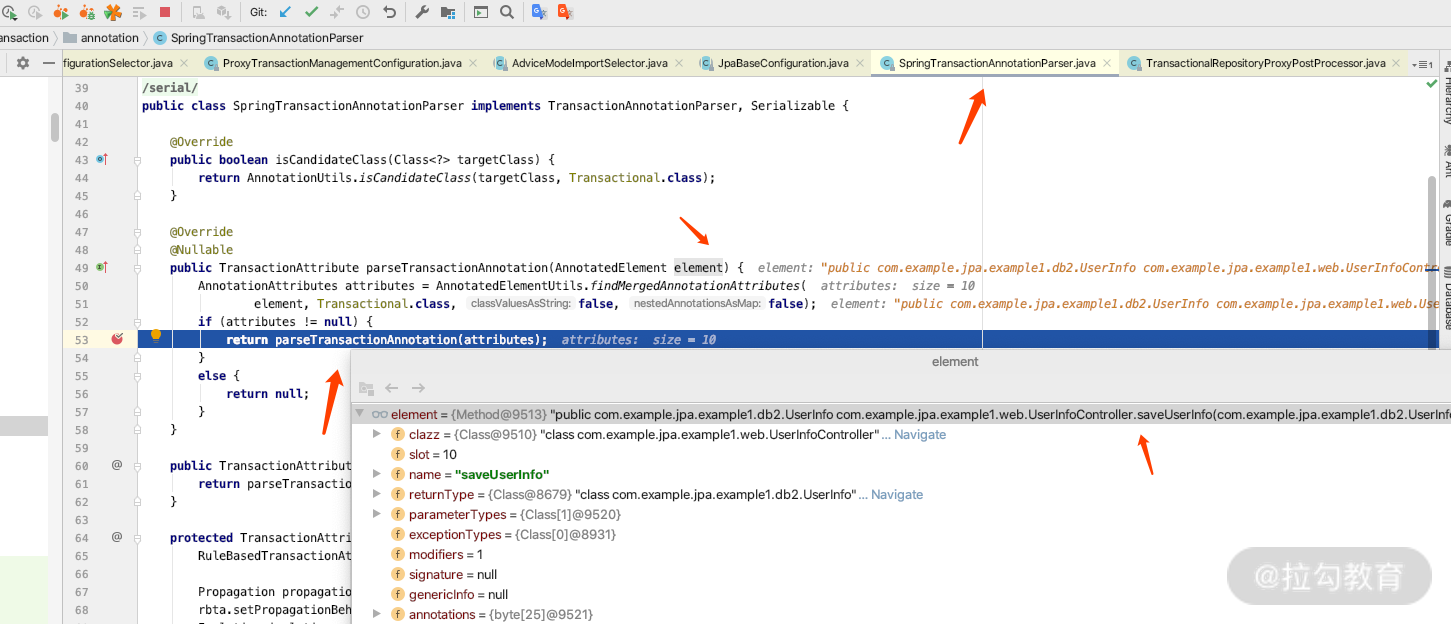
加载期间,通过 @Trnsactional 注解来确定哪些方法需要进行事务处理。
o.s.orm.jpa.JpaTransactionManager : Creating new transaction with name
而运行期间通过上面这条日志,就可以找到 JpaTransactionManager 里面通过 getTransaction 方法创建的事务,然后再通过 debuger 模式的 IDEA 线程栈进行分析,就能知道创建事务的整个过程。你可以一步一步地去断点进行查看,如下图所示。

如上图,我们可以知道 createTransactionIfNecessary 是用来判断是否需要创建事务的,有兴趣的话你可以点击进去看看,如下图所示。
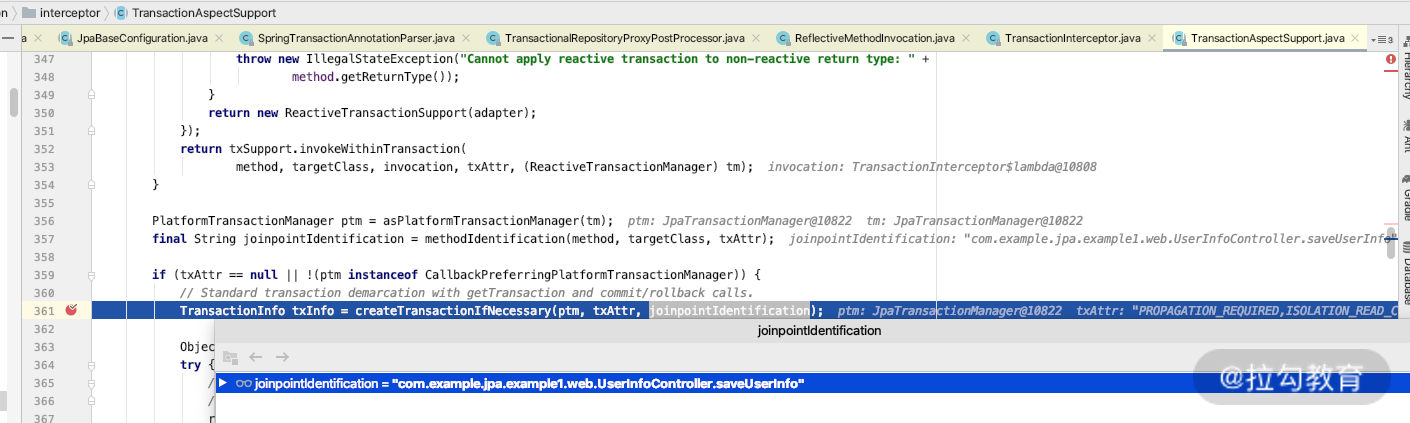
我们继续往下面 debug 的话,就会找到创建事务的关键代码,它会通过调用 AbstractPlatformTransactionManager 里面的 startTransaction 方法开启事务,如下图所示。
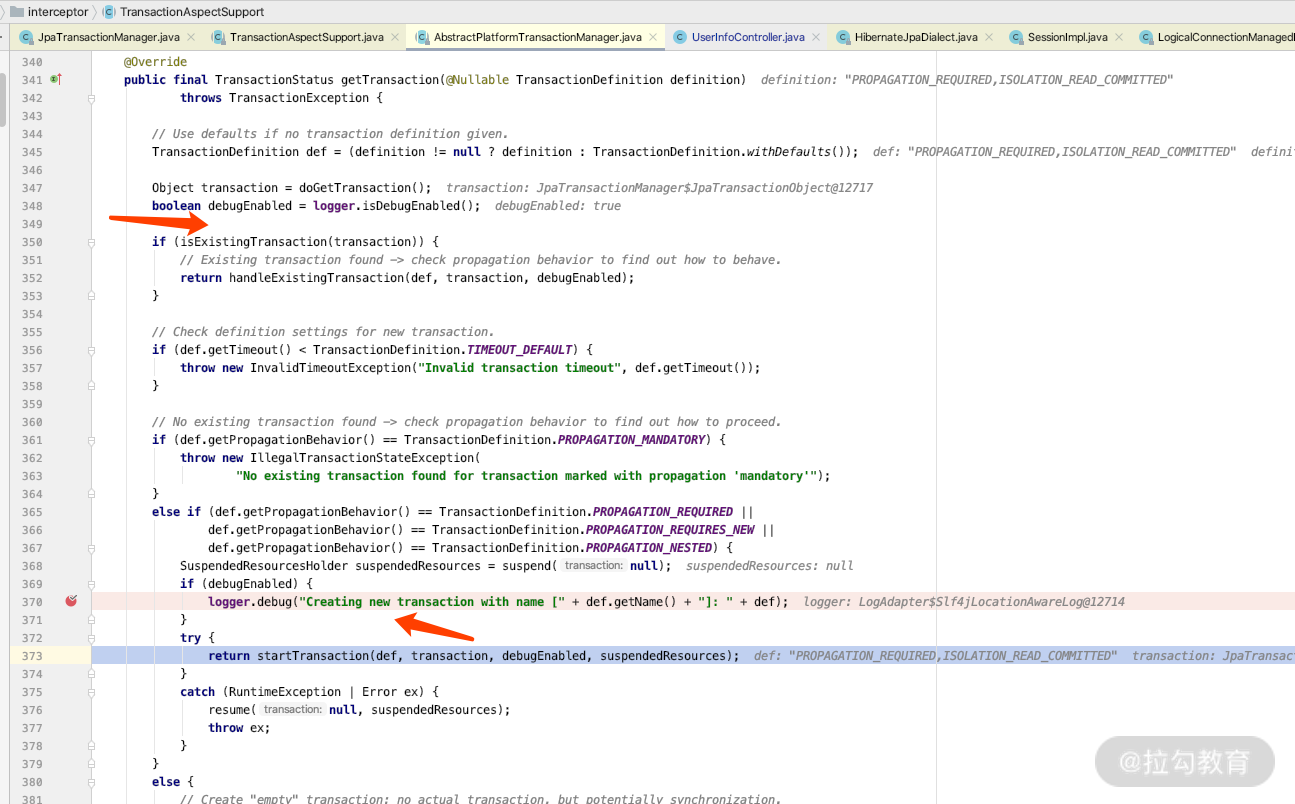
然后我们就可以继续往下断点进行分析了。断点走到最后的时候,你就可以看到开启事务的时候,必须要从我们的数据源里面获得连接。看一下断点的栈信息,这里有几个关键的 debug 点。如下图所示。
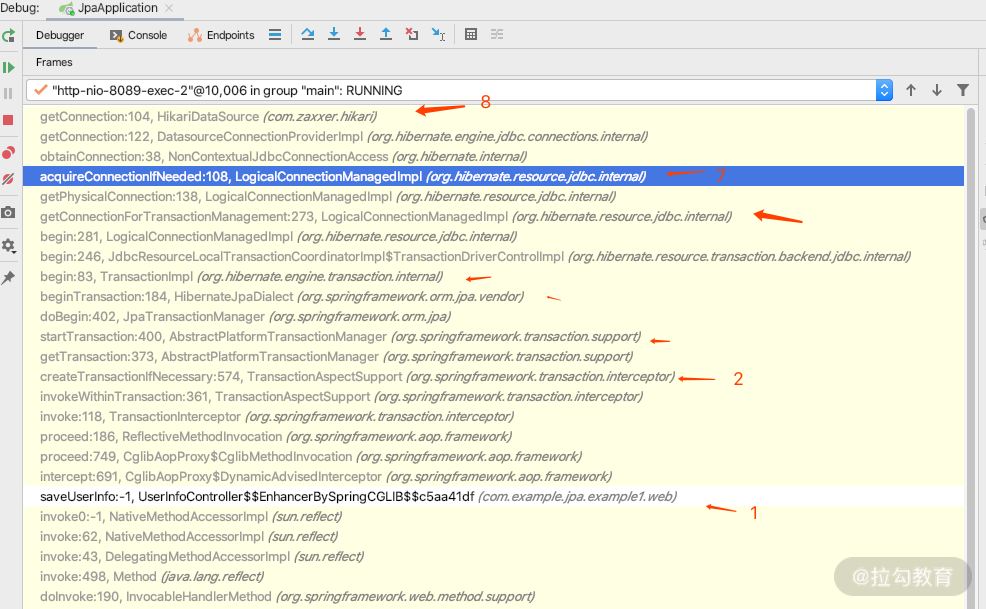
其中,
第一处:是处理带 @Transactional 的注解的方法,利用 CGLIB 进行事务拦截处理;
第二处:是根据 Spring 的事务传播机制,来判断是用现有的事务,还是创建新的事务;
第七处:是用来判断是否现有连接,如果有直接用,如果没有就从第八处的数据源里面的连接池中获取连接,第七处的关键代码如下。
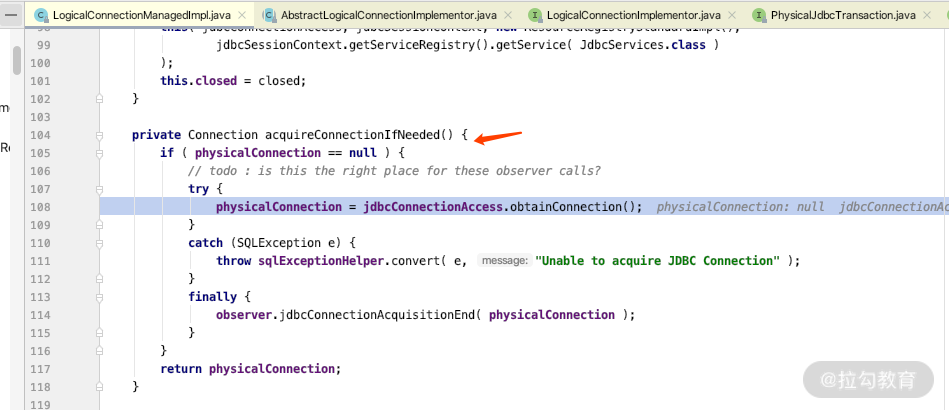
到这里,我们介绍完了事务获得连接的关键时机,那么还需要知道它是在什么时间释放连接到连接池里面的。我们在 LogicalConnectionManagedImpl 的 releaseConnection 方法中设置一个断点,如下图所示。
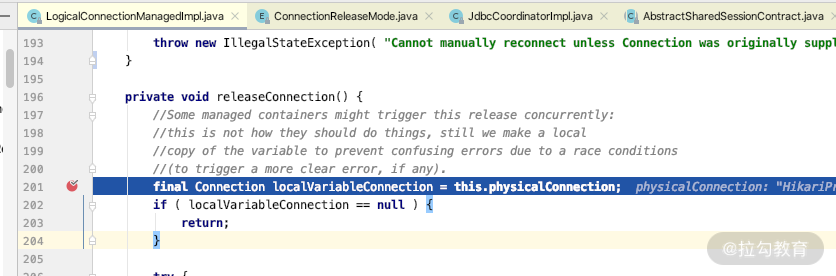
然后观察断点线性的执行方法,你会发现,在事务执行之后,它会将连接释放到连接池里面。
我们通过上面的 saveOrUpdate 的详细执行日志,可以观察出来,事务是在什么时机开启的、数据库连接是什么时机开启的、事务是在什么时机关闭的,以及数据库连接是在什么时机释放的,如果你没看出来,可以再仔细看一遍日志。
所以,Spring 中的事务和连接的关系是,开启事务的同时获取 DB 连接;事务完成的时候释放 DB 连接。通过 MySQL 的基础知识可以知道数据库连接是有限的,那么当我们给某些方法加事务的时候,都需要注意哪些内容呢?
事务和连接池在 JPA 中的注意事项
我们在“17 | DataSource 为何物?加载过程是怎样的?”中对数据源的介绍时,说过数据源的连接池不能配置过大,否则连接之前切换就会非常耗费应用内部的 CPU 和内存,从而降低应用对外提供 API 的吞吐量。
所以当我们使用事务的时候,需要注意如下 几个事项:
-
事务内的逻辑不能执行时间太长,否则就会导致占用 db 连接的时间过长,会造成数据库连接不够用的情况;
-
跨应用的操作,如 API 调用等,尽量不要在有事务的方法里面进行;
-
如果在真实业务场景中有耗时的操作,也需要带事务时(如扣款环节),那么请注意增加数据源配置的连接池数;
-
我们通过 MVC 的应用请求连接池数量,也要根据连接池的数量和事务的耗时情况灵活配置;而 tomcat 默认的请求连接池数量是 200 个,可以根据实际情况来增加或者减少请求的连接池数量,从而减少并发处理对事务的依赖。
总结
本讲中,我们通过 MySQL 的基本原理、Spring 的事务处理日志及其源码分析,知道了 Spring 里面处理事务的全过程。通过日志,你也可以学会分析设置的事务和 SQL 是不是按照预期执行的。
同时,我也为你讲述了连接和事务之间的关系,当你需要设置连接池的时候,可以进行参考;并且在工作中,如果遇到报连接池不够用的情况,也可以从容地知道原因:是不是事务的方法执行比较耗时?等等。
此外,当事务不起作用的时候,我也为你介绍了 TransactionTemplate 和 TransactionHelper 的方法,你可以拿去借鉴。
希望这一讲的内容可以帮助你搞清楚事务、连接池之间的关系。下一讲我们会介绍 Hibernate 在 JPA 中的配置有哪些。你可以先思考一下,也可以查找资料预习一下。我们下一讲再见。
20 Spring JPA 中的 Hibernate 加载过程与配置项是怎么回事?
你好,欢迎来到第 20 讲。前面我们已经学习完了两个模块:基础知识以及高阶用法与实战的内容,不知道你掌握得如何,有疑问的地方一定要留言提问,或者和大家一起讨论,请记住学习的路上你不是一个人在战斗。
那么从这一讲开始,我们进入“模块三:原理与问题排查”知识的学习。这一模块,我将带你了解Hibernate 的加载过程、Session 和事务之间的关系,帮助你知道在遇到 LazyException 以及经典的 N+1 SQL 问题时该如何解决,希望你在工作中可以灵活运用所学知识。
这一讲,我们来分析一下在 Spring Data JPA 的项目下面 Hibernate 的配置参数有哪些,先从 Hibernate 的整体架构进行分析。
Hibernate 架构分析
首先看一下 Hibernate 5.2 版本中,官方提供的架构图。
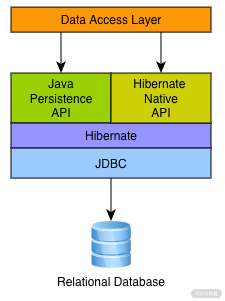
从架构图上,我们可以知道 Hiberante 实现的 ORM 的接口有两种,一种是 Hiberante 自己的 API 接口;一种是 Java Persistence API 的接口实现。
因为 Hibernate 其实是比 Java Persistence API 早几年发展的,后来才有了 Java 的持久化协议。以我个人的观点来看,随着时间的推移,Hiberante 的实现逻辑可能会逐渐被弱化,由 Java Persistence API 统一对外提供服务。
那么有了这个基础,我们研究 Hibernate 在 Spring Data JPA 里面的作用,得出的结论就是:Hibernate 5.2 是 Spring Data JPA 持久化操作的核心。我们再从类上面具体看一下,关键类的图如下所示:
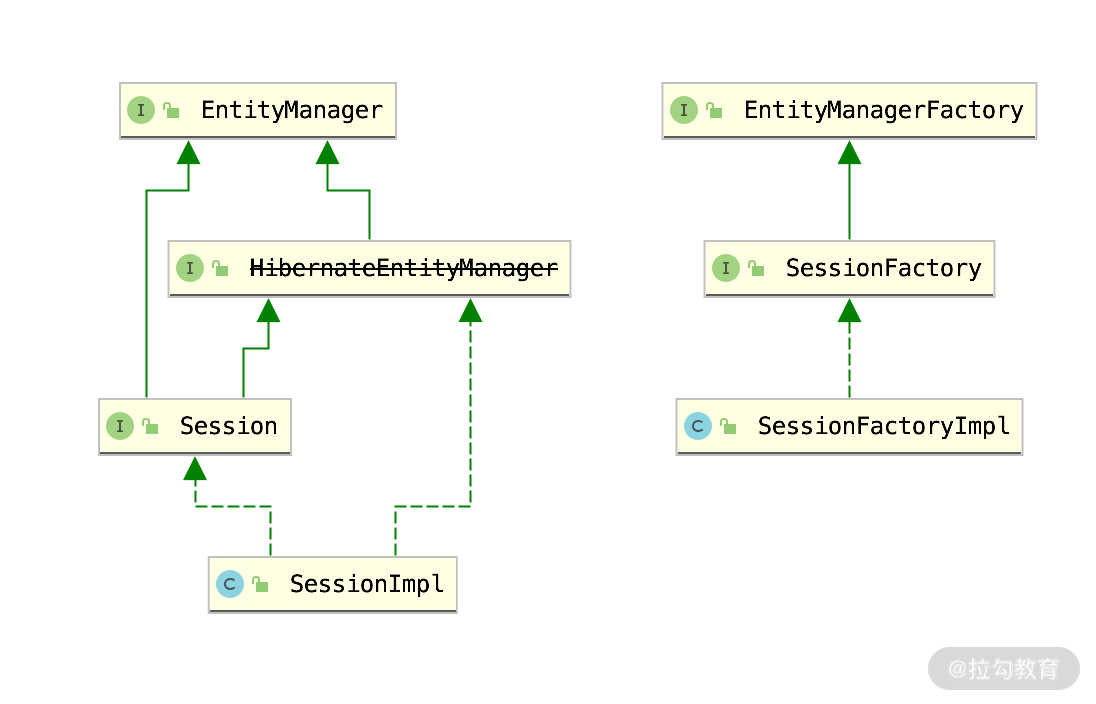
结合类的关系图来看,Session 接口和 SessionFactory 接口都是 Hibernate 的概念,而 EntityManger 和 EntityManagerFactory 都是 Java Persistence API 协议规定的接口。
不过 HibernateEntityManger 从 Hibernate 5.2 之后就开始不推荐使用了,而是建议直接使用 EntityManager 接口即可。那么我们看看 Hibernate 在 Spring BOOT 里面是如何被加载进去的。
Hibernate 5 在 Spring Boot 2 里面的加载过程
不同的 Spring Boot 版本,可能加载类的实现逻辑是不一样的,但是分析过程都是相同的。我们先打开 spring.factories 文件,如下图所示,其中可以自动加载 Hibernate 的只有一个类,那就是 HibernateJpaAutoConfiguration。
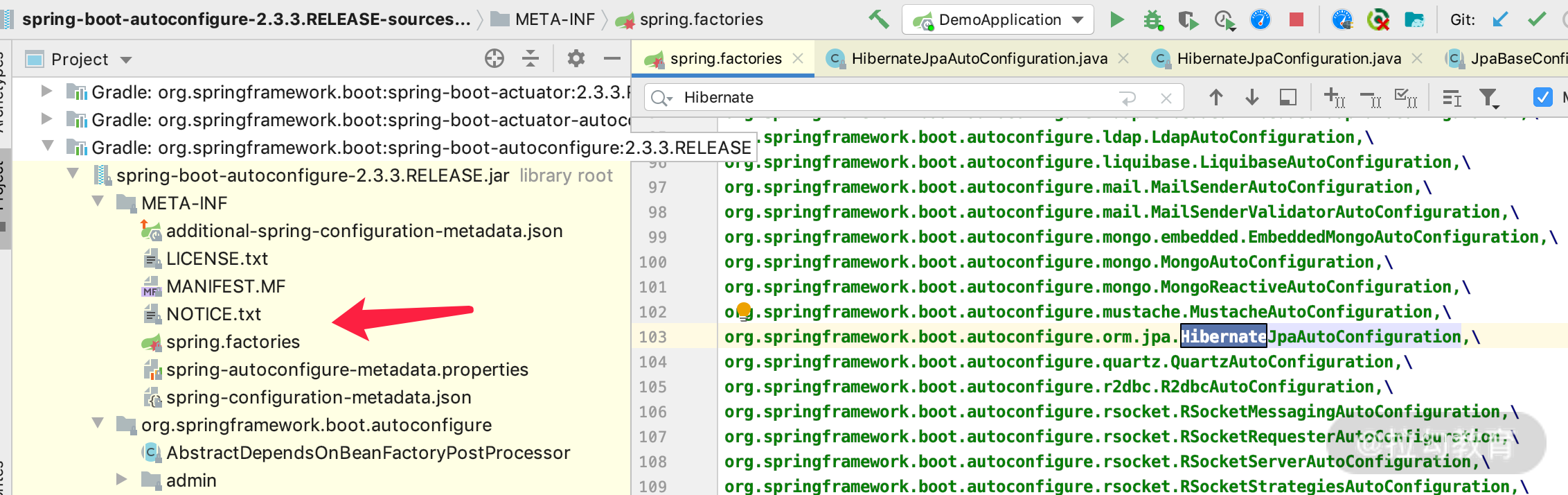
HibernateJpaAutoConfiguration 就是 Spring Boot 加载 Hibernate 的主要入口,所以我们可以直接打开这个类看一下。
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ LocalContainerEntityManagerFactoryBean.class, EntityManager.class, SessionImplementor.class })
@EnableConfigurationProperties(JpaProperties.class)//JPAProperties的配置
@AutoConfigureAfter({ DataSourceAutoConfiguration.class })
@Import(HibernateJpaConfiguration.class) //hibernate加载的关键类
public class HibernateJpaAutoConfiguration {
}
其中,我们第一个需要关注的就是 JpaProperties 类,因为通过这个类我们可以间接知道,application.properties 里面可以配置的 spring.jpa 的属性有哪些。
JpaProperties 属性
我们打开 JpaProperties 类看一下,如下图所示。
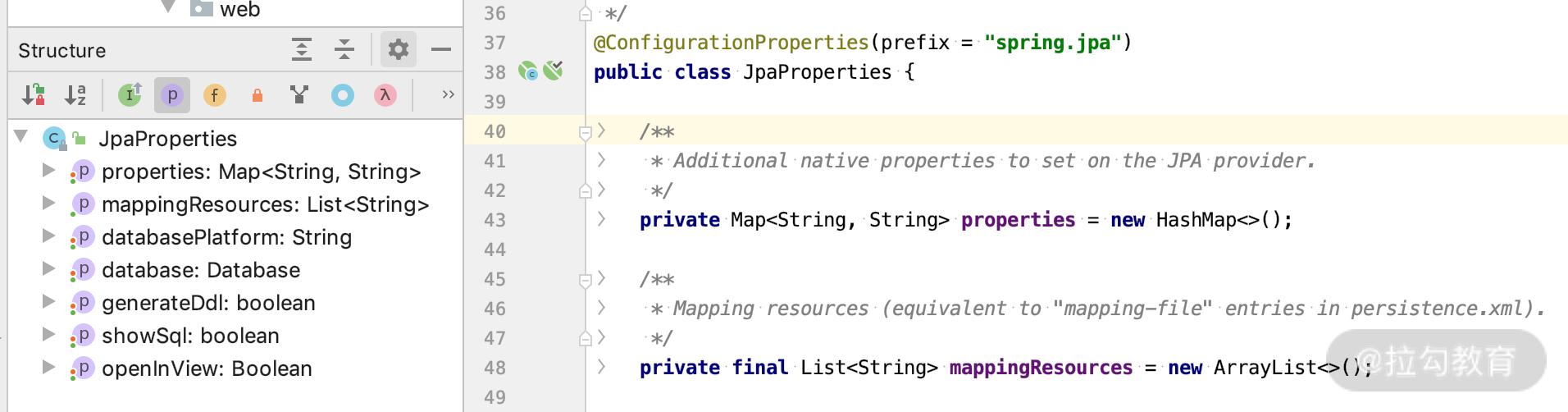
通过这个类,我们可以在 application.properties 里面得到如下配置项。
# 可以配置JPA的实现者的原始属性的配置,如:这里我们用的JPA的实现者是hibernate
# 那么hibernate里面的一些属性设置就可以通过如下方式实现,具体properties里面有哪些,本讲会详细介绍,我们先知道这里可以设置即可
spring.jpa.properties.hibernate.hbm2ddl.auto=none
#hibernate的persistence.xml文件有哪些,目前已经不推荐使用
#spring.jpa.mapping-resources=
# 指定数据源的类型,如果不指定,Spring Boot加载Datasource的时候会根据URL的协议自己判断
# 如:spring.datasource.url=jdbc:mysql://localhost:3306/test 上面可以明确知道是mysql数据源,所以这个可以不需要指定;
# 应用场景,当我们通过代理的方式,可能通过datasource.url没办法判断数据源类型的时候,可以通过如下方式指定,可选的值有:DB2,H2,HSQL,INFORMIX,MYSQL,ORACLE,POSTGRESQL,SQL_SERVER,SYBASE)
spring.jpa.database=mysql
# 是否在启动阶段根据实体初始化数据库的schema,默认false,当我们用内存数据库做测试的时候可以打开,很有用
spring.jpa.generate-ddl=false
# 和spring.jpa.database用法差不多,指定数据库的平台,默认会自己发现;一般不需要指定,database-platform指定的必须是org.hibernate.dialect.Dialect的子类,如mysql默认是用下面的platform
spring.jpa.database-platform=org.hibernate.dialect.MySQLInnoDBDialect
# 是否在view层打开session,默认是true,其实大部分场景不需要打开,我们可以设置成false,
# 22课时我们再详细讲解
spring.jpa.open-in-view=false
# 是否显示sql,当执行JPA的数据库操作的时候,默认是false,在本地开发的时候我们可以把这个打开,有助于分析sql是不是我们预期的
# 在生产环境的时候建议给这个设置成false,改由logging.level.org.hibernate.SQL=DEBUG代替,这样的话日志默认是基于logback输出的
# 而不是直接打印到控制台的,有利于增加traceid和线程ID等信息,便于分析
spring.jpa.show-sql=true
其中,spring.jpa.show-sql=true 输出的 sql 效果如下所示。
Hibernate: insert into user_info (create_time, create_user_id, last_modified_time, last_modified_user_id, version, ages, email_address, last_name, telephone, id) values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
上面是孤立无援的 System.out.println 的效果,如果是在线上环境,多线程的情况下就不知道是哪个线程输出来的,而 logging.level.org.hibernate.SQL=DEBUG 输出的 sql 效果如下所示。
2020-11-08 16:54:22.275 DEBUG 6589 --- [nio-8087-exec-1] org.hibernate.SQL : insert into user_info (create_time, create_user_id, last_modified_time, last_modified_user_id, version, ages, email_address, last_name, telephone, id) values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
这样我们可以轻易知道线程 ID 和执行时间,甚至可以有 tranceID 和 spanID 进行日志跟踪,方便分析是哪个线程打印的。
我们了解完了 JpaProperties,下面再看另外一个关键类 HibernateJpaConfiguration,它也是 HibernateJpaAutoConfiguration 导入进来加载的。
HibernateJpaConfiguration 分析
我们通过上述 HibernateJpaAutoConfiguration 里面的 @Import(HibernateJpaConfiguration.class),打开 HibernateJpaConfiguration.class 看看是什么情况。
@Configuration(proxyBeanMethods = false)
@EnableConfigurationProperties(HibernateProperties.class)
@ConditionalOnSingleCandidate(DataSource.class)
class HibernateJpaConfiguration extends JpaBaseConfiguration {
.......//其他我们暂不关心的代码我们可以先省略}
通过源码我们可以得到 Hibernate 在 JPA 中配置的三个重要线索,下面详细说明。
第一个线索:HibernatePropertes 这个配置类对应的是 spring.jpa.hibernate 的配置。
我们通过源码可以看得出来,@EnableConfigurationProperties(HibernateProperties.class) 启用了 HibernatePropertes 的配置类,如下图所示。
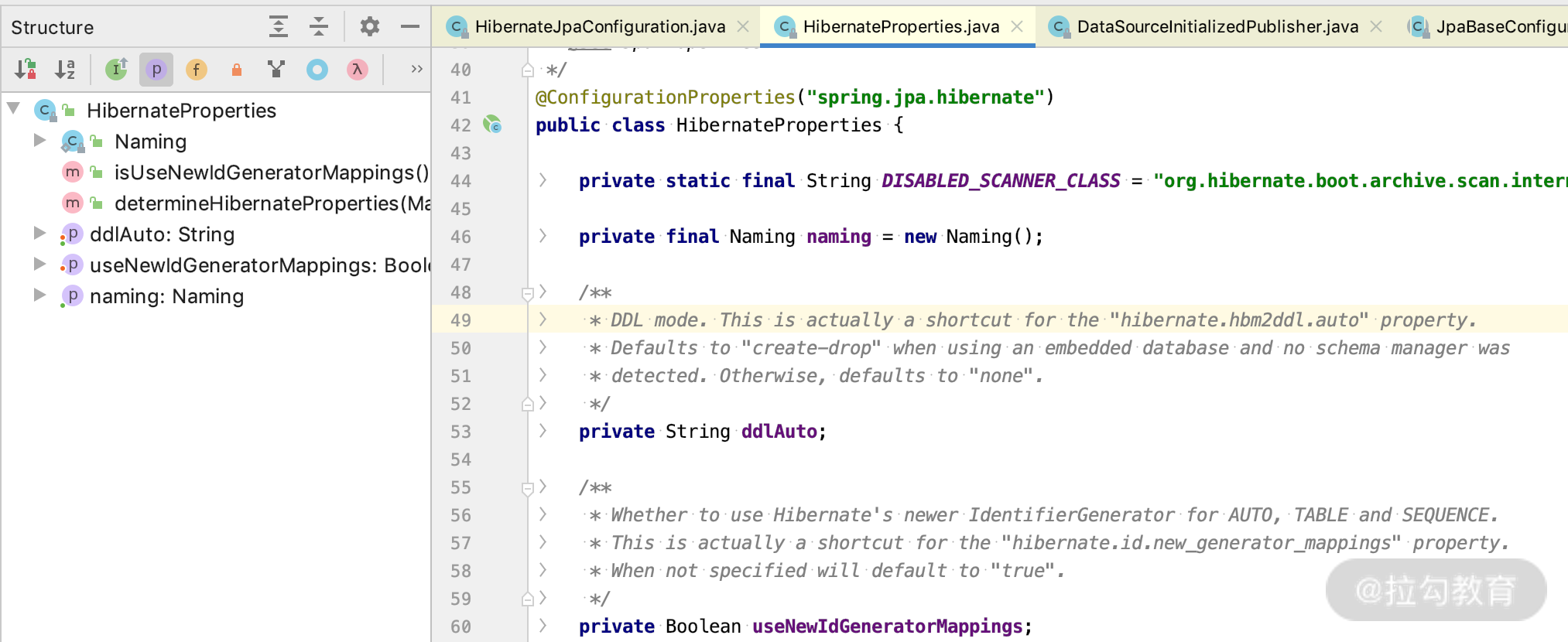
其中可以看到 application.properties 的配置项,如下所示。
# 正如我们之前课时讲到的nameing的物理策略值有:org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy(默认)和org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
spring.jpa.hibernate.naming.physical-strategy=
# ddl的生成策略,默认none;如果我们没有指定任何数据源的url,采用的是spring的集成数据源,也就是内存数据源H2的时候,默认值是create-drop;
# 所以你会发现当我们每次用H2的时候什么都没做,它就会自动帮我们创建表等,内存数据库和写测试用的时候,create-drop就非常方便了;不过,当我们生产数据库的时候一定要设置成none;
spring.jpa.hibernate.ddl-auto=none
# 当我们的@Id配置成@GeneratedValue(strategy= GenerationType.AUTO)的时候是否采用hibernate的Id-generator-mappings(即会默认帮我们创建一张表hibernate_sequence来存储和生成ID),默认是true
spring.jpa.hibernate.use-new-id-generator-mappings=true
第二个线索:通过源码我们还可以看得出来,HibernateJpaConfiguration 的父类 JpaBaseConfiguration 也会优先加载,此类就是 Spring Boot 加载 JPA 的核心逻辑。
那么我们打开 JpaBaseConfiguration 类看一下源码。
@Configuration(proxyBeanMethods = false)
@EnableConfigurationProperties(JpaProperties.class)
//DataSourceInitializedPublisher用来进行数据源的初始化操作
@Import(DataSourceInitializedPublisher.Registrar.class)
public abstract class JpaBaseConfiguration implements BeanFactoryAware {
protected JpaBaseConfiguration(DataSource dataSource, JpaProperties properties,
ObjectProvider<JtaTransactionManager> jtaTransactionManager) {
this.dataSource = dataSource;
this.properties = properties;
//jtaTransactionManager赋值,正常情况下我们用不到,一般用来解决分布式事务的场景才会用到。
this.jtaTransactionManager = jtaTransactionManager.getIfAvailable();
}
//加载JPA的实现方式
@Bean
@ConditionalOnMissingBean
public JpaVendorAdapter jpaVendorAdapter() {
//createJpaVendorAdapter是由子类HibernateJpaConfiguration实现的,创建JPA的实现类
AbstractJpaVendorAdapter adapter = createJpaVendorAdapter();
adapter.setShowSql(this.properties.isShowSql());
if (this.properties.getDatabase() != null) {
adapter.setDatabase(this.properties.getDatabase());
}
if (this.properties.getDatabasePlatform() != null) {
adapter.setDatabasePlatform(this.properties.getDatabasePlatform());
}
adapter.setGenerateDdl(this.properties.isGenerateDdl());
return adapter;
}
.......其他我们暂时不关心的代码先省略}
我们从上面的源码中可以看到,@Import(DataSourceInitializedPublisher.Registrar.class) 是用来初始化数据的;从构造函数中我们也可以看到其是否有用到 jtaTransactionManager(这个是分布式事务才会用到);而 createJpaVendorAdapter() 是在 HibernateJpaConfiguration 里面实现的,这个要重点说一下,关键代码如下。
class HibernateJpaConfiguration extends JpaBaseConfiguration {
//这里是hibernate和Jpa的结合,可以看到使用的HibernateJpaVendorAdapter作为JPA的实现者,感兴趣的话你可以打开HibernateJpaVendorAdapter里面设置一些断点,就会知道Spring boot是如何一步一步加载Hibernate的了;
@Override
protected AbstractJpaVendorAdapter createJpaVendorAdapter() {
return new HibernateJpaVendorAdapter();
}
.......}
现在我们知道了 HibernateJpaVendorAdapter 的加载逻辑,而 HibernateJpaVendorAdapter 里面实现了 Hibernate 的初始化逻辑,我在这里不多说了,你过后可以仔细 debug 看一下,基本上就是 Hibernate 5.2 官方的加载逻辑。那么 Hibernate Jpa 对应的原始配置有哪些呢?
第三个线索:spring.jpa.properties 配置项有哪些?
我们如果接着在 HibernateJpaConfiguration 类里面 debug 查看关键代码的话,可以找到如下代码。
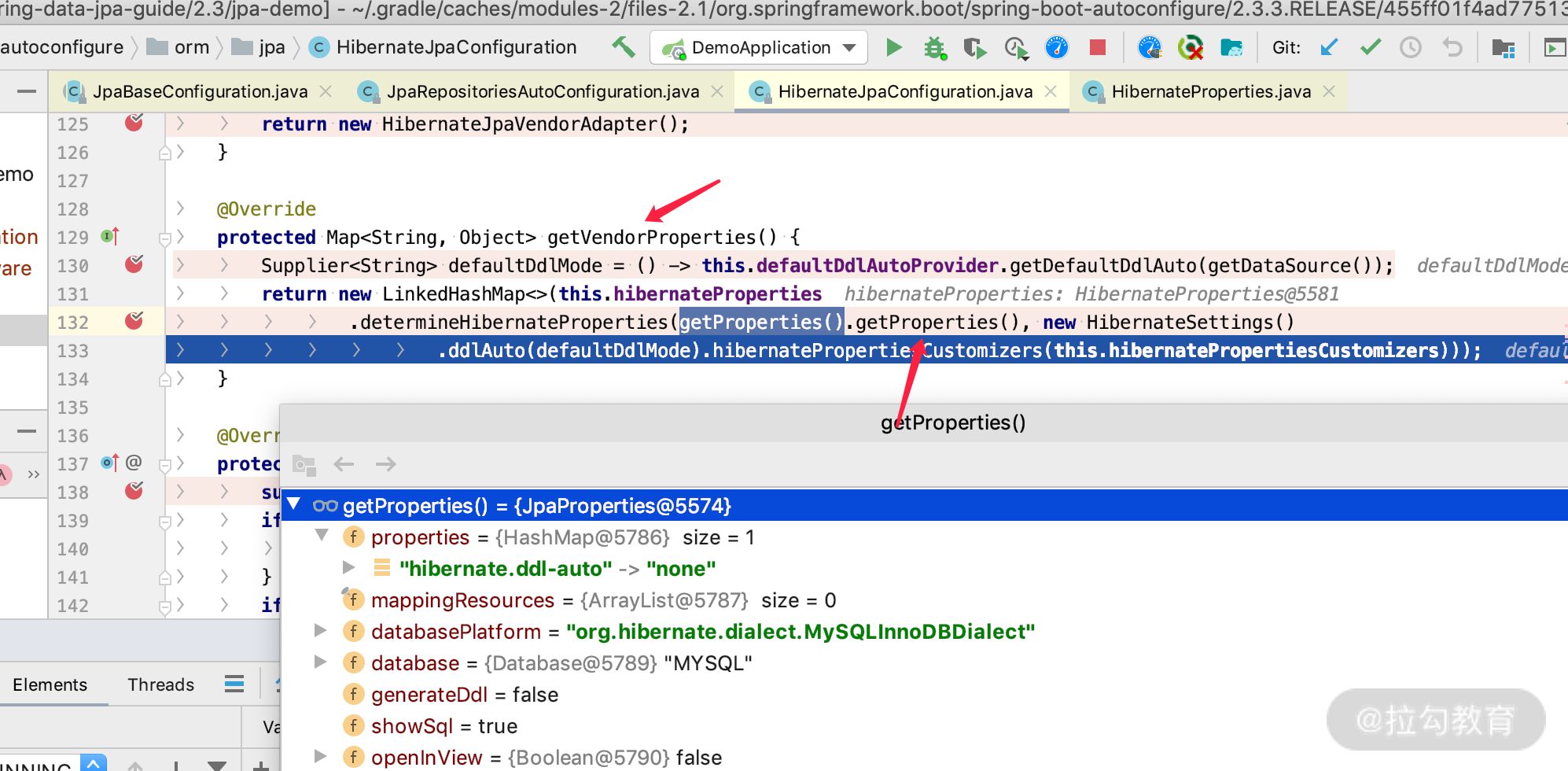
上图中的代码显示,JpaProperties 类里面的 properties 属性,也就是 spring.jpa.properties 的配置加载到了 vendorProperties(即 Hibernate 5.2)里面。而 properties 里面是 HashMap 结构,那么它都可以支持哪些配置呢?
我们打开 org.hibernate.cfg.AvailableSettings 可以看到 Hibernate 支持的配置项大概有 100 多个配置信息,如下所示。
String JPA_PERSISTENCE_PROVIDER = "javax.persistence.provider";
String JPA_TRANSACTION_TYPE = "javax.persistence.transactionType";
String JPA_JTA_DATASOURCE = "javax.persistence.jtaDataSource";
String JPA_NON_JTA_DATASOURCE = "javax.persistence.nonJtaDataSource";
String JPA_JDBC_DRIVER = "javax.persistence.jdbc.driver";
String JPA_JDBC_URL = "javax.persistence.jdbc.url";
String JPA_JDBC_USER = "javax.persistence.jdbc.user";
String JPA_JDBC_PASSWORD = "javax.persistence.jdbc.password";
String JPA_SHARED_CACHE_MODE = "javax.persistence.sharedCache.mode";
String JPA_SHARED_CACHE_RETRIEVE_MODE ="javax.persistence.cache.retrieveMode";
String JPA_SHARED_CACHE_STORE_MODE ="javax.persistence.cache.storeMode";
String JPA_VALIDATION_MODE = "javax.persistence.validation.mode";
String JPA_VALIDATION_FACTORY = "javax.persistence.validation.factory";
String JPA_PERSIST_VALIDATION_GROUP = "javax.persistence.validation.group.pre-persist";
String JPA_UPDATE_VALIDATION_GROUP = "javax.persistence.validation.group.pre-update";
String JPA_REMOVE_VALIDATION_GROUP = "javax.persistence.validation.group.pre-remove";
String JPA_LOCK_SCOPE = "javax.persistence.lock.scope";
String JPA_LOCK_TIMEOUT = "javax.persistence.lock.timeout";
String CDI_BEAN_MANAGER = "javax.persistence.bean.manager";
String CLASSLOADERS = "hibernate.classLoaders";
String TC_CLASSLOADER = "hibernate.classLoader.tccl_lookup_precedence";
String APP_CLASSLOADER = "hibernate.classLoader.application";
String RESOURCES_CLASSLOADER = "hibernate.classLoader.resources";
String HIBERNATE_CLASSLOADER = "hibernate.classLoader.hibernate";
String ENVIRONMENT_CLASSLOADER = "hibernate.classLoader.environment";
String JPA_METAMODEL_GENERATION = "hibernate.ejb.metamodel.generation";
String JPA_METAMODEL_POPULATION = "hibernate.ejb.metamodel.population";
String STATIC_METAMODEL_POPULATION = "hibernate.jpa.static_metamodel.population";
String CONNECTION_PROVIDER ="hibernate.connection.provider_class";
String DRIVER ="hibernate.connection.driver_class";
String URL ="hibernate.connection.url";
String USER ="hibernate.connection.username";
String PASS ="hibernate.connection.password";
String ISOLATION ="hibernate.connection.isolation";
String AUTOCOMMIT = "hibernate.connection.autocommit";
String POOL_SIZE ="hibernate.connection.pool_size";
String DATASOURCE ="hibernate.connection.datasource";
String CONNECTION_PROVIDER_DISABLES_AUTOCOMMIT= "hibernate.connection.provider_disables_autocommit";
String CONNECTION_PREFIX = "hibernate.connection";
String JNDI_CLASS ="hibernate.jndi.class";
String JNDI_URL ="hibernate.jndi.url";
String JNDI_PREFIX = "hibernate.jndi";
String DIALECT ="hibernate.dialect";
String DIALECT_RESOLVERS = "hibernate.dialect_resolvers";
String STORAGE_ENGINE = "hibernate.dialect.storage_engine";
String SCHEMA_MANAGEMENT_TOOL = "hibernate.schema_management_tool";
String TRANSACTION_COORDINATOR_STRATEGY = "hibernate.transaction.coordinator_class";
String JTA_PLATFORM = "hibernate.transaction.jta.platform";
String PREFER_USER_TRANSACTION = "hibernate.jta.prefer_user_transaction";
String JTA_PLATFORM_RESOLVER = "hibernate.transaction.jta.platform_resolver";
String JTA_CACHE_TM = "hibernate.jta.cacheTransactionManager";
String JTA_CACHE_UT = "hibernate.jta.cacheUserTransaction";
String JDBC_TYLE_PARAMS_ZERO_BASE = "hibernate.query.sql.jdbc_style_params_base";
String DEFAULT_CATALOG = "hibernate.default_catalog";
String DEFAULT_SCHEMA = "hibernate.default_schema";
String DEFAULT_CACHE_CONCURRENCY_STRATEGY = "hibernate.cache.default_cache_concurrency_strategy";
String USE_NEW_ID_GENERATOR_MAPPINGS = "hibernate.id.new_generator_mappings";
String FORCE_DISCRIMINATOR_IN_SELECTS_BY_DEFAULT = "hibernate.discriminator.force_in_select";
String IMPLICIT_DISCRIMINATOR_COLUMNS_FOR_JOINED_SUBCLASS = "hibernate.discriminator.implicit_for_joined";
String IGNORE_EXPLICIT_DISCRIMINATOR_COLUMNS_FOR_JOINED_SUBCLASS = "hibernate.discriminator.ignore_explicit_for_joined";
String USE_NATIONALIZED_CHARACTER_DATA = "hibernate.use_nationalized_character_data";
String SCANNER_DEPRECATED = "hibernate.ejb.resource_scanner";
String SCANNER = "hibernate.archive.scanner";
String SCANNER_ARCHIVE_INTERPRETER = "hibernate.archive.interpreter";
String SCANNER_DISCOVERY = "hibernate.archive.autodetection";
String IMPLICIT_NAMING_STRATEGY = "hibernate.implicit_naming_strategy";
String PHYSICAL_NAMING_STRATEGY = "hibernate.physical_naming_strategy";
String ARTIFACT_PROCESSING_ORDER = "hibernate.mapping.precedence";
String KEYWORD_AUTO_QUOTING_ENABLED = "hibernate.auto_quote_keyword";
String XML_MAPPING_ENABLED = "hibernate.xml_mapping_enabled";
String SESSION_FACTORY_NAME = "hibernate.session_factory_name";
String SESSION_FACTORY_NAME_IS_JNDI = "hibernate.session_factory_name_is_jndi";
String SHOW_SQL ="hibernate.show_sql";
String FORMAT_SQL ="hibernate.format_sql";
String USE_SQL_COMMENTS ="hibernate.use_sql_comments";
String MAX_FETCH_DEPTH = "hibernate.max_fetch_depth";
String DEFAULT_BATCH_FETCH_SIZE = "hibernate.default_batch_fetch_size";
String USE_STREAMS_FOR_BINARY = "hibernate.jdbc.use_streams_for_binary";
String USE_SCROLLABLE_RESULTSET = "hibernate.jdbc.use_scrollable_resultset";
String USE_GET_GENERATED_KEYS = "hibernate.jdbc.use_get_generated_keys";
String STATEMENT_FETCH_SIZE = "hibernate.jdbc.fetch_size";
String STATEMENT_BATCH_SIZE = "hibernate.jdbc.batch_size";
String BATCH_STRATEGY = "hibernate.jdbc.factory_class";
String BATCH_VERSIONED_DATA = "hibernate.jdbc.batch_versioned_data";
String JDBC_TIME_ZONE = "hibernate.jdbc.time_zone";
String AUTO_CLOSE_SESSION = "hibernate.transaction.auto_close_session";
String FLUSH_BEFORE_COMPLETION = "hibernate.transaction.flush_before_completion";
String ACQUIRE_CONNECTIONS = "hibernate.connection.acquisition_mode";
String RELEASE_CONNECTIONS = "hibernate.connection.release_mode";
String CONNECTION_HANDLING = "hibernate.connection.handling_mode";
String CURRENT_SESSION_CONTEXT_CLASS = "hibernate.current_session_context_class";
String USE_IDENTIFIER_ROLLBACK = "hibernate.use_identifier_rollback";
String USE_REFLECTION_OPTIMIZER = "hibernate.bytecode.use_reflection_optimizer";
String ENFORCE_LEGACY_PROXY_CLASSNAMES = "hibernate.bytecode.enforce_legacy_proxy_classnames";
String ALLOW_ENHANCEMENT_AS_PROXY = "hibernate.bytecode.allow_enhancement_as_proxy";
String QUERY_TRANSLATOR = "hibernate.query.factory_class";
String QUERY_SUBSTITUTIONS = "hibernate.query.substitutions";
String QUERY_STARTUP_CHECKING = "hibernate.query.startup_check";
String CONVENTIONAL_JAVA_CONSTANTS = "hibernate.query.conventional_java_constants";
String SQL_EXCEPTION_CONVERTER = "hibernate.jdbc.sql_exception_converter";
String WRAP_RESULT_SETS = "hibernate.jdbc.wrap_result_sets";
String NATIVE_EXCEPTION_HANDLING_51_COMPLIANCE = "hibernate.native_exception_handling_51_compliance";
String ORDER_UPDATES = "hibernate.order_updates";
String ORDER_INSERTS = "hibernate.order_inserts";
String JPA_CALLBACKS_ENABLED = "hibernate.jpa_callbacks.enabled";
String DEFAULT_NULL_ORDERING = "hibernate.order_by.default_null_ordering";
String LOG_JDBC_WARNINGS = "hibernate.jdbc.log.warnings";
String BEAN_CONTAINER = "hibernate.resource.beans.container";
String C3P0_CONFIG_PREFIX = "hibernate.c3p0";
String C3P0_MAX_SIZE = "hibernate.c3p0.max_size";
String C3P0_MIN_SIZE = "hibernate.c3p0.min_size";
String C3P0_TIMEOUT = "hibernate.c3p0.timeout";
String C3P0_MAX_STATEMENTS = "hibernate.c3p0.max_statements";
String C3P0_ACQUIRE_INCREMENT = "hibernate.c3p0.acquire_increment";
String C3P0_IDLE_TEST_PERIOD = "hibernate.c3p0.idle_test_period";
String PROXOOL_CONFIG_PREFIX = "hibernate.proxool";
String PROXOOL_PREFIX = PROXOOL_CONFIG_PREFIX;
String PROXOOL_XML = "hibernate.proxool.xml";
String PROXOOL_PROPERTIES = "hibernate.proxool.properties";
String PROXOOL_EXISTING_POOL = "hibernate.proxool.existing_pool";
String PROXOOL_POOL_ALIAS = "hibernate.proxool.pool_alias";
String CACHE_REGION_FACTORY = "hibernate.cache.region.factory_class";
String CACHE_KEYS_FACTORY = "hibernate.cache.keys_factory";
String CACHE_PROVIDER_CONFIG = "hibernate.cache.provider_configuration_file_resource_path";
String USE_SECOND_LEVEL_CACHE = "hibernate.cache.use_second_level_cache";
String USE_QUERY_CACHE = "hibernate.cache.use_query_cache";
String QUERY_CACHE_FACTORY = "hibernate.cache.query_cache_factory";
String CACHE_REGION_PREFIX = "hibernate.cache.region_prefix";
String USE_MINIMAL_PUTS = "hibernate.cache.use_minimal_puts";
String USE_STRUCTURED_CACHE = "hibernate.cache.use_structured_entries";
String AUTO_EVICT_COLLECTION_CACHE = "hibernate.cache.auto_evict_collection_cache";
String USE_DIRECT_REFERENCE_CACHE_ENTRIES = "hibernate.cache.use_reference_entries";
String DEFAULT_ENTITY_MODE = "hibernate.default_entity_mode";
String GLOBALLY_QUOTED_IDENTIFIERS = "hibernate.globally_quoted_identifiers";
String GLOBALLY_QUOTED_IDENTIFIERS_SKIP_COLUMN_DEFINITIONS = "hibernate.globally_quoted_identifiers_skip_column_definitions";
String CHECK_NULLABILITY = "hibernate.check_nullability";
String BYTECODE_PROVIDER = "hibernate.bytecode.provider";
String JPAQL_STRICT_COMPLIANCE= "hibernate.query.jpaql_strict_compliance";
String PREFER_POOLED_VALUES_LO = "hibernate.id.optimizer.pooled.prefer_lo";
String PREFERRED_POOLED_OPTIMIZER = "hibernate.id.optimizer.pooled.preferred";
String QUERY_PLAN_CACHE_MAX_STRONG_REFERENCES = "hibernate.query.plan_cache_max_strong_references";
String QUERY_PLAN_CACHE_MAX_SOFT_REFERENCES = "hibernate.query.plan_cache_max_soft_references";
String QUERY_PLAN_CACHE_MAX_SIZE = "hibernate.query.plan_cache_max_size";
String QUERY_PLAN_CACHE_PARAMETER_METADATA_MAX_SIZE = "hibernate.query.plan_parameter_metadata_max_size";
String NON_CONTEXTUAL_LOB_CREATION = "hibernate.jdbc.lob.non_contextual_creation";
String HBM2DDL_AUTO = "hibernate.hbm2ddl.auto";
String HBM2DDL_DATABASE_ACTION = "javax.persistence.schema-generation.database.action";
String HBM2DDL_SCRIPTS_ACTION = "javax.persistence.schema-generation.scripts.action";
String HBM2DDL_CONNECTION = "javax.persistence.schema-generation-connection";
String HBM2DDL_DB_NAME = "javax.persistence.database-product-name";
String HBM2DDL_DB_MAJOR_VERSION = "javax.persistence.database-major-version";
String HBM2DDL_DB_MINOR_VERSION = "javax.persistence.database-minor-version";
String HBM2DDL_CREATE_SOURCE = "javax.persistence.schema-generation.create-source";
String HBM2DDL_DROP_SOURCE = "javax.persistence.schema-generation.drop-source";
String HBM2DDL_CREATE_SCRIPT_SOURCE = "javax.persistence.schema-generation.create-script-source";
String HBM2DDL_DROP_SCRIPT_SOURCE = "javax.persistence.schema-generation.drop-script-source";
String HBM2DDL_SCRIPTS_CREATE_TARGET = "javax.persistence.schema-generation.scripts.create-target";
String HBM2DDL_SCRIPTS_DROP_TARGET = "javax.persistence.schema-generation.scripts.drop-target";
String HBM2DDL_IMPORT_FILES = "hibernate.hbm2ddl.import_files";
String HBM2DDL_LOAD_SCRIPT_SOURCE = "javax.persistence.sql-load-script-source";
String HBM2DDL_IMPORT_FILES_SQL_EXTRACTOR = "hibernate.hbm2ddl.import_files_sql_extractor";
String HBM2DDL_CREATE_NAMESPACES = "hibernate.hbm2ddl.create_namespaces";
String HBM2DLL_CREATE_NAMESPACES = "hibernate.hbm2dll.create_namespaces";
String HBM2DDL_CREATE_SCHEMAS = "javax.persistence.create-database-schemas";
String HBM2DLL_CREATE_SCHEMAS = HBM2DDL_CREATE_SCHEMAS;
String HBM2DDL_FILTER_PROVIDER = "hibernate.hbm2ddl.schema_filter_provider";
String HBM2DDL_JDBC_METADATA_EXTRACTOR_STRATEGY = "hibernate.hbm2ddl.jdbc_metadata_extraction_strategy";
String HBM2DDL_DELIMITER = "hibernate.hbm2ddl.delimiter";
String HBM2DDL_CHARSET_NAME = "hibernate.hbm2ddl.charset_name";
String HBM2DDL_HALT_ON_ERROR = "hibernate.hbm2ddl.halt_on_error";
String JMX_ENABLED = "hibernate.jmx.enabled";
String JMX_PLATFORM_SERVER = "hibernate.jmx.usePlatformServer";
String JMX_AGENT_ID = "hibernate.jmx.agentId";
String JMX_DOMAIN_NAME = "hibernate.jmx.defaultDomain";
String JMX_SF_NAME = "hibernate.jmx.sessionFactoryName";
String JMX_DEFAULT_OBJ_NAME_DOMAIN = "org.hibernate.core";
String CUSTOM_ENTITY_DIRTINESS_STRATEGY = "hibernate.entity_dirtiness_strategy";
String USE_ENTITY_WHERE_CLAUSE_FOR_COLLECTIONS = "hibernate.use_entity_where_clause_for_collections";
String MULTI_TENANT = "hibernate.multiTenancy";
String MULTI_TENANT_CONNECTION_PROVIDER = "hibernate.multi_tenant_connection_provider";
String MULTI_TENANT_IDENTIFIER_RESOLVER = "hibernate.tenant_identifier_resolver";
String INTERCEPTOR = "hibernate.session_factory.interceptor";
String SESSION_SCOPED_INTERCEPTOR = "hibernate.session_factory.session_scoped_interceptor";
String STATEMENT_INSPECTOR = "hibernate.session_factory.statement_inspector";
String ENABLE_LAZY_LOAD_NO_TRANS = "hibernate.enable_lazy_load_no_trans";
String HQL_BULK_ID_STRATEGY = "hibernate.hql.bulk_id_strategy";
String BATCH_FETCH_STYLE = "hibernate.batch_fetch_style";
String DELAY_ENTITY_LOADER_CREATIONS = "hibernate.loader.delay_entity_loader_creations";
String JTA_TRACK_BY_THREAD = "hibernate.jta.track_by_thread";
String JACC_CONTEXT_ID = "hibernate.jacc_context_id";
String JACC_PREFIX = "hibernate.jacc";
String JACC_ENABLED = "hibernate.jacc.enabled";
String ENABLE_SYNONYMS = "hibernate.synonyms";
String EXTRA_PHYSICAL_TABLE_TYPES = "hibernate.hbm2ddl.extra_physical_table_types";
String DEPRECATED_EXTRA_PHYSICAL_TABLE_TYPES = "hibernate.hbm2dll.extra_physical_table_types";
String UNIQUE_CONSTRAINT_SCHEMA_UPDATE_STRATEGY = "hibernate.schema_update.unique_constraint_strategy";
String GENERATE_STATISTICS = "hibernate.generate_statistics";
String LOG_SESSION_METRICS = "hibernate.session.events.log";
String LOG_SLOW_QUERY = "hibernate.session.events.log.LOG_QUERIES_SLOWER_THAN_MS";
String AUTO_SESSION_EVENTS_LISTENER = "hibernate.session.events.auto";
String PROCEDURE_NULL_PARAM_PASSING = "hibernate.proc.param_null_passing";
String CREATE_EMPTY_COMPOSITES_ENABLED = "hibernate.create_empty_composites.enabled";
String ALLOW_JTA_TRANSACTION_ACCESS = "hibernate.jta.allowTransactionAccess";
String ALLOW_UPDATE_OUTSIDE_TRANSACTION = "hibernate.allow_update_outside_transaction";
String COLLECTION_JOIN_SUBQUERY = "hibernate.collection_join_subquery";
String ALLOW_REFRESH_DETACHED_ENTITY = "hibernate.allow_refresh_detached_entity";
String MERGE_ENTITY_COPY_OBSERVER = "hibernate.event.merge.entity_copy_observer";
String USE_LEGACY_LIMIT_HANDLERS = "hibernate.legacy_limit_handler";
String VALIDATE_QUERY_PARAMETERS = "hibernate.query.validate_parameters";
String CRITERIA_LITERAL_HANDLING_MODE = "hibernate.criteria.literal_handling_mode";
String PREFER_GENERATOR_NAME_AS_DEFAULT_SEQUENCE_NAME = "hibernate.model.generator_name_as_sequence_name";
String JPA_TRANSACTION_COMPLIANCE = "hibernate.jpa.compliance.transaction";
String JPA_QUERY_COMPLIANCE = "hibernate.jpa.compliance.query";
String JPA_LIST_COMPLIANCE = "hibernate.jpa.compliance.list";
String JPA_CLOSED_COMPLIANCE = "hibernate.jpa.compliance.closed";
String JPA_PROXY_COMPLIANCE = "hibernate.jpa.compliance.proxy";
String JPA_CACHING_COMPLIANCE = "hibernate.jpa.compliance.caching";
String JPA_ID_GENERATOR_GLOBAL_SCOPE_COMPLIANCE = "hibernate.jpa.compliance.global_id_generators";
String TABLE_GENERATOR_STORE_LAST_USED = "hibernate.id.generator.stored_last_used";
String FAIL_ON_PAGINATION_OVER_COLLECTION_FETCH = "hibernate.query.fail_on_pagination_over_collection_fetch";
String IMMUTABLE_ENTITY_UPDATE_QUERY_HANDLING_MODE = "hibernate.query.immutable_entity_update_query_handling_mode";
String IN_CLAUSE_PARAMETER_PADDING = "hibernate.query.in_clause_parameter_padding";
String QUERY_STATISTICS_MAX_SIZE = "hibernate.statistics.query_max_size";
String SEQUENCE_INCREMENT_SIZE_MISMATCH_STRATEGY = "hibernate.id.sequence.increment_size_mismatch_strategy";
String OMIT_JOIN_OF_SUPERCLASS_TABLES = "hibernate.query.omit_join_of_superclass_tables";
我担心有些同学懒得去看源码,所以就都贴到这里来了,你可以大概了解一下,做到心中有数。
那么接下来我们看看该怎么使用 AvailableSettings 里面的配置呢?
AvailableSettings 里面的配置项的用法
我们只需要将 AvailableSettings 变量的值放到 spring.jpa.properties 里面即可,如下这些是我们常用的。
##开启hibernate statistics的信息,如session、连接等日志:
spring.jpa.properties.hibernate.generate_statistics=true
# 格式化 SQL
spring.jpa.properties.hibernate.format_sql: true
# 显示 SQL
spring.jpa.properties.hibernate.show_sql: true
# 添加 HQL 相关的注释信息
spring.jpa.properties.hibernate.use_sql_comments: true
# hbm2ddl的策略 validate, update, create, create-drop, none,建议配置成validate,
# 这样在我们启动项目的时候就知道生产数据库的表结构是否正确的了,而不用等到运行期间才发现问题。
spring.jpa.properties.hibernate.hbm2ddl.auto=validate
# 关联关系的时候取数据的深度,默认是3层,我们可以设置成2级,防止其他开发乱用,提高sql性能
spring.jpa.properties.hibernate.max_fetch_depth=2
# 批量fetch大小默认 -1
spring.jpa.properties.hibernate.default_batch_fetch_size= 100
# 事务完成之前是否进行flush操作,即同步到db里面去,默认是true
spring.jpa.properties.hibernate.transaction.flush_before_completion=true
# 事务结束之后是否关闭session,默认false
spring.jpa.properties.hibernate.transaction.auto_close_session=false
# 有的时候不只要批量查询,也会批量更新,默认batch size是15,我们可以根据实际情况自由调整,可以提高批量更新的效率;
spring.jpa.properties.hibernate.jdbc.batch_size=100
其他的配置不经常用,我们就不需要关心了,你只知道在哪里看就好,实际用到时,发现哪些是我没举例的,你直接看源码会非常好理解的。
这里我为什么要特别强调这个 Hibernate 的配置类呢?因为有的时候我们遇到问题会去网上搜索解决方案,发现别人给的配置可能不对,那么你就可以想到从这个源码中进行查看,并找到解决办法。
本讲我们只关心了 JpaVendorAdapter 和 properties 的创建逻辑,我们前面在讲数据源的时候也说过这个类,里面有我们关心的 PlatformTransactionManager transactionManager 和 LocalContainerEntityManagerFactoryBean entityManagerFactory 的创建逻辑,而 JpaBaseConfiguration 这个类实现的逻辑还有很多,我在第 22 讲介绍 Session 的配置 open-in-view 的时候还会再详细介绍这个类。
那么说了这么多加载的类,它们之间是什么关系呢?我们通过一个图来知晓一下。
自动加载过程类之间的关系图
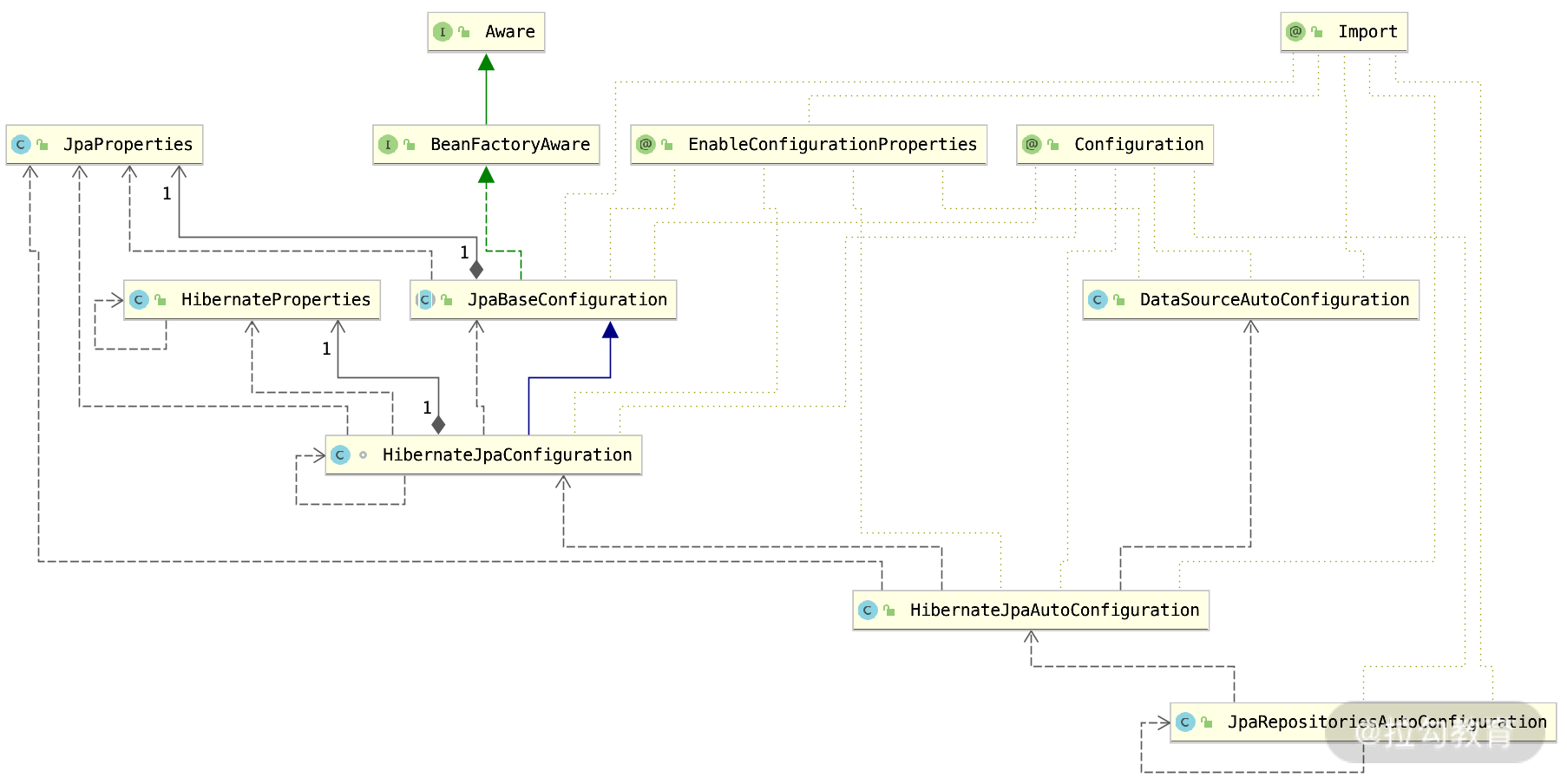
从上图中,我们可以看出以下几点内容。
-
JpaBaseConfiguration 是 Jpa 和 Hibernate 被加载的基石,里面通过 BeanFactoryAware 的接口的 bean 加载生命周期也实现了一些逻辑。
-
HibernateJpaConfiguration 是 JpaBaseConfiguration 的子类,覆盖了一些父类里面的配置相关的特殊逻辑,并且里面引用了 JpaPropeties 和 HibernateProperties 的配置项。
-
HibernateJpaAutoConfiguration 是 Spring Boot 自动加载 HibernateJpaConfiguration 的桥梁,起到了 importHibernateJpaConfiguration 和加载 HibernateJpaConfiguration 的作用。
-
JpaRepositoriesAutoConfiguration 和 HibernateJpaAutoConfiguration、DataSourceAutoConfiguration 分别加载 JpaRepositories 的逻辑和 HibernateJPA、数据源,都是被 spring.factories 自动装配进入到 Spring Boot 里面的,而三者之间有加载的先后顺序。
-
上图的 UML 还展示了几个 Configuration 类的加载顺序和依赖关系,顺序是从上到下进行加载的,其中 DataSourceAutoConfiguration 最先加载、HibernateJpaAutoConfiguration 第二顺序加载、JpaRepositoriesAutoConfiguration 最后加载。
我们了解完了 Hibernate 5 在 Spring Boot 里面的加载过程,那么来看下 JpaRepositoriesAutoConfiguration 的主要作用有哪些。
Spring Data JPA Repositories Bootstrap Mode
我们通过上面分享的整个加载过程可以发现,DataSourceAutoConfiguration 完成了数据源的加载,HibernateJpaAutoConfiguration 完成了 Hibernate 的加载过程,而 JpaRepositoriesAutoConfiguration 要做的就是解决我们之前定义的 Repositories 相关的实体和接口的加载初始化过程,这是 Spring Data JPA 的主要实现逻辑,和 Hiberante、数据源没什么关系了。
我们可以通过 JpaRepositoriesAutoConfiguration 的源码发现其主要职责和实现方式,利用异步线程池初始化 repositories,关键源码如下:
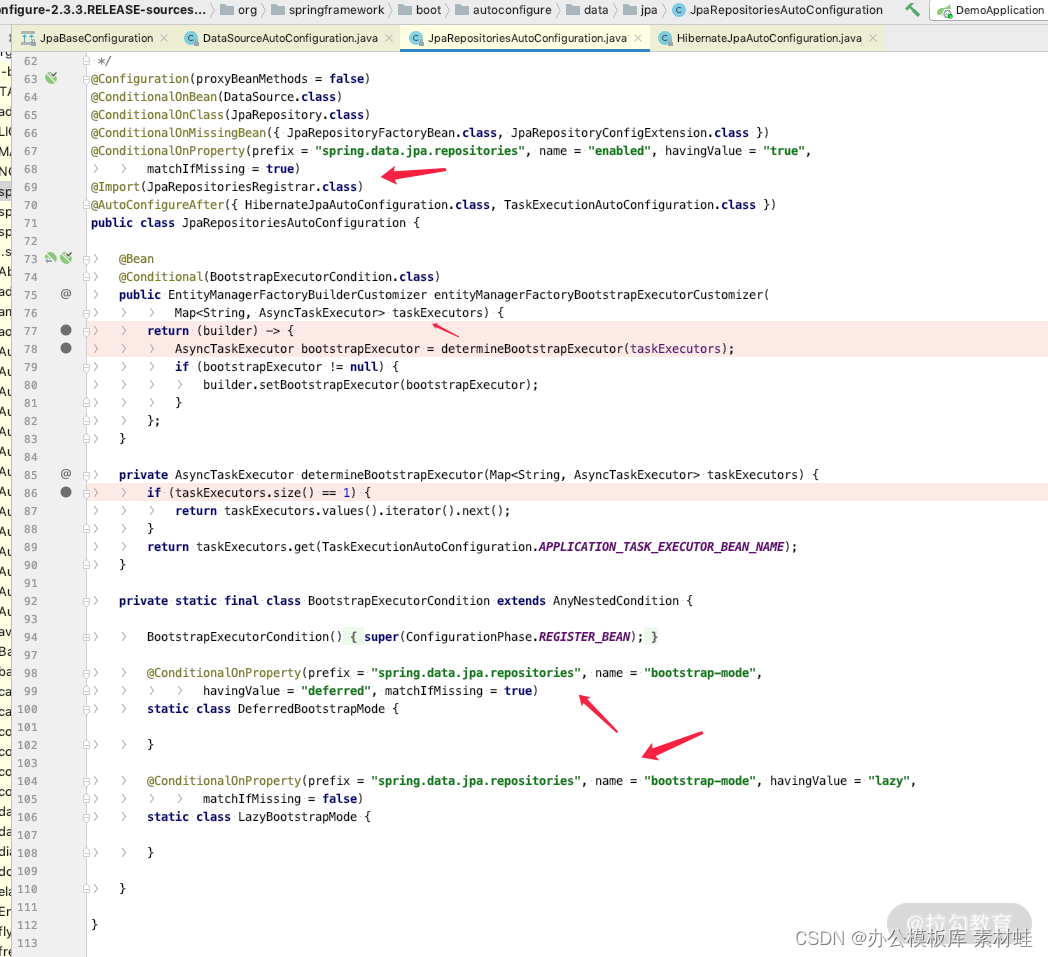
而其中加载 repositories 有三种方式,即 spring.data.jpa.repositories.bootstrap-mode 的三个值,分别为 deferred、 lazy、 default,下面详细说明。
-
deferred:是默认值,表示在启动的时候会进行数据库字段的检查,而 repositories 相关的实例的初始化是 lazy 模式,也就是在第一次用到 repositories 实例的时候再进行初始化。这个比较适合用在测试环境和生产环境中,因为测试不可能覆盖所有场景,万一谁多加个字段或者少一个字段,这样在启动的阶段就可以及时发现问题,不能等进行到生产环境才暴露。
-
lazy:表示启动阶段不会进行数据库字段的检查,也不会初始化 repositories 相关的实例,而是在第一次用到 repositories 实例的时候再进行初始化。这个比较适合用在开发的阶段,可以加快应用的启动速度。如果生产环境中,我们为了提高业务高峰期间水平来扩展应用的启动速度,也可以采用这种模式。
-
default:默认加载方式,但从 Spring Boot 2.0 之后就不是默认值了,表示立即验证、立即初始化 repositories 实例,这种方式启动的速度最慢,但是最保险,运行期间的请求最快,因为避免了第一次请求初始化 repositories 实例的过程。
我们通过在 application.properties 里面修改这一行代码,来测试一下 lazy 的加载方式。
spring.data.jpa.repositories.bootstrap-mode=lazy
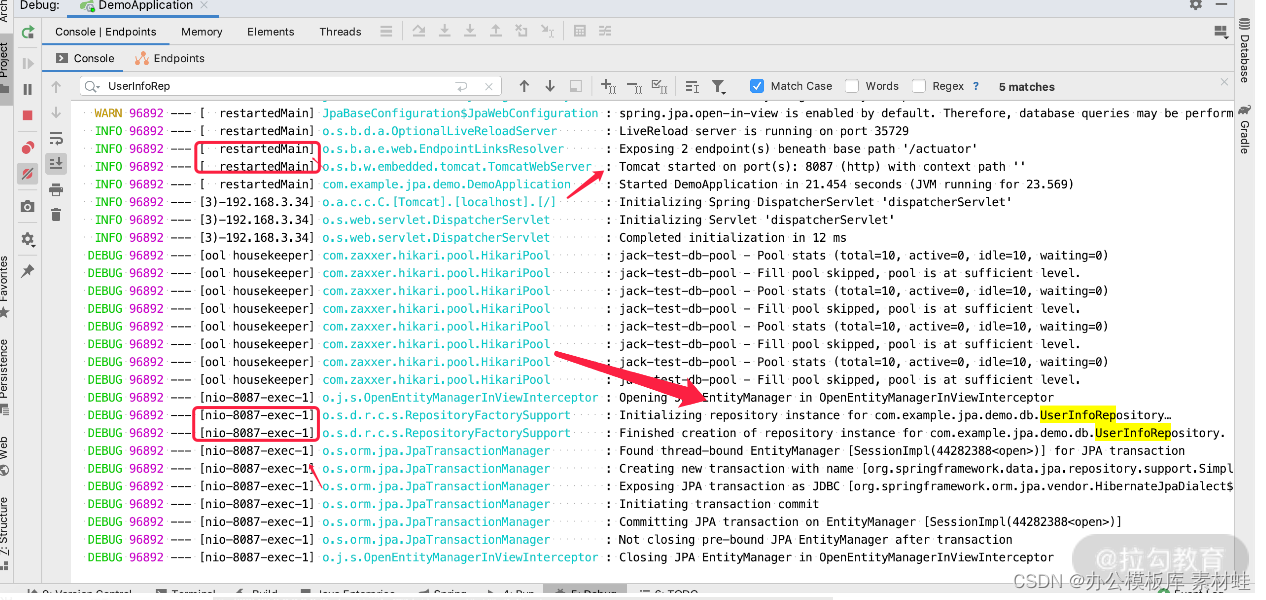
然后启动我们的项目,就会发现在 tomcat 容器加载完之后,没有用到 UserInfoRepository 之前,这个 UserInfoRepository 是不会进行初始化的。而当我们发一个请求用到了 UserInfoRepository,就进行了初始化。
我们通过日志也可以看到,启动的线程和初始化的线程是不一样的,而初始化的线程是 NIO 线程的名字,表示 request 的 http 线程池里面的线程,具体如下图所示。
我们在分析 Hibernate 的加载方式的时候,会发现日志的重要性,那么都有哪些日志供我们观察呢?如何开启?
Debug 时候,日志的配置
### 日志级别的灵活运用
## hibernate相关
# 显示sql的执行日志,如果开了这个,show_sql就可以不用了
logging.level.org.hibernate.SQL=debug
# hibernate id的生成日志
logging.level.org.hibernate.id=debug
# hibernate所有的操作都是PreparedStatement,把sql的执行参数显示出来
logging.level.org.hibernate.type.descriptor.sql.BasicBinder=TRACE
# sql执行完提取的返回值
logging.level.org.hibernate.type.descriptor.sql=trace
# 请求参数
logging.level.org.hibernate.type=debug
# 缓存相关
logging.level.org.hibernate.cache=debug
# 统计hibernate的执行状态
logging.level.org.hibernate.stat=debug
# 查看所有的缓存操作
logging.level.org.hibernate.event.internal=trace
logging.level.org.springframework.cache=trace
# hibernate 的监控指标日志
logging.level.org.hibernate.engine.internal.StatisticalLoggingSessionEventListener=DEBUG
### 连接池的相关日志
## hikari连接池的状态日志,以及连接池是否完好 #连接池的日志效果:HikariCPPool - Pool stats (total=20, active=0, idle=20, waiting=0)
logging.level.com.zaxxer.hikari=TRACE
#开启 debug可以看到 AvailableSettings里面的默认配置的值都有哪些,会输出类似下面的日志格式
# org.hibernate.cfg.Settings : Statistics: enabled
# org.hibernate.cfg.Settings : Default batch fetch size: -1
logging.level.org.hibernate.cfg=debug
#hikari数据的配置项日志
logging.level.com.zaxxer.hikari.HikariConfig=TRACE
### 查看事务相关的日志,事务获取,释放日志
logging.level.org.springframework.orm.jpa=DEBUG
logging.level.org.springframework.transaction=TRACE
logging.level.org.hibernate.engine.transaction.internal.TransactionImpl=DEBUG
### 分析connect 以及 orm和 data的处理过程更全的日志
logging.level.org.springframework.data=trace
logging.level.org.springframework.orm=trace
上面是我在分析复杂问题和原理的时候常用的日志配置项目,这里给你提供一个技巧,当我们分析一个问题的时候,如果不知道日志具体在哪个类里面,通过设置 logging.level.root=trace 的话,日志又非常多几乎没有办法看,那么我们可以缩小范围,不如说我们分析的是 hikari 包里面相关的问题。
我们可以把整个日志级别 logging.level.root=info 设置成 info,把其他所有的日志都关闭,并把 logging.level.com.zaxxer=trace 设置成最大的,保持日志不受干扰,然后观察日志再逐渐减少查看范围。
总结
这一讲我通过源码分析,帮助你了解了 JpaRepositoriesAutoConfiguration、HibernateJpaAutoConfiguration、DataSourceAutoConfiguration 的主要作用和加载顺序的依赖,还介绍了 Spring Hibernate 的配置项有哪些。
你在工作中可以举一反三,通过 debug 断点一步一步分析出来这一讲没涉及的东西。比如可以自己做一个项目,跟着我的步骤操作,你会对这部分的内容有更深刻的体会。这样当遇到一些问题,并且网上没有合适的资料时,你可以试着采用本讲中我分享给你的思路来解决。
下一讲,我会为你介绍一个 Hibernate 实现的 JPA 的概念:Persistence Context。欢迎你提前预习,并结合这一讲内容去思考,有疑问的地方请留言,我会及时给予答复。
21 Peritence Context 所表达的核心概念是什么?
你好,欢迎学习第 21 讲。上一讲我们介绍了 Hibernate 和 JPA 在 Spring Boot 里面的配置项相关内容,那么这一讲其实是对前一讲内容的延续,我们再介绍一下 Hibernate 和 JPA 的一个核心概念 Persistence Context。
这个概念是 JPA 入门者,或者初中级开发人员最容易用错的一部分内容,今天我们就来弄清楚它的来龙去脉,分析原理及用法,帮你更好地掌握,以便熟练运用。我们先从了解核心概念入手。
Persistence Context 相关的核心概念有哪些?
EntityManagerFactory 和 Persistence Unit 是什么?
按照 JPA 协议里面的定义:persistence unit 是一些持久化配置的集合,里面包含了数据源的配置、EntityManagerFactory 的配置,spring 3.1 之前主要是通过 persistence.xml 的方式来配置一个 persistence unit。
而 spring 3.1 之后已经不再推荐这种方式了,但是还保留了 persistence unit 的概念,我们只需要在配置 LocalContainerEntityManagerFactory 的时候,指定 persistence unit 的名字即可,正如我在“18 | 生产环境多数据源的处理方法有哪些?”中讲解多数据的时候一样。
请看下面代码,我们直接指定 persistenceUnit 的 name 即可。
@Bean(name = "db2EntityManagerFactory")
public LocalContainerEntityManagerFactoryBean entityManagerFactory(EntityManagerFactoryBuilder builder, @Qualifier("db2DataSource") DataSource db2DataSource) {
return builder.dataSource(db2DataSource)
.packages("com.example.jpa.example1.db2") //数据2的实体所在的路径
.persistenceUnit("db2")// persistenceUnit的名字采用db2
.build();
}
EntityManagerFactory 的用途就比较明显了,即根据不同的数据源,来管理 Entity 和创建 EntityManger,在整个 application 的生命周期中是单例状态。所以在 spring 的 application 里面获得 EntityManagerFactory 有两种方式。
第一种:通过 Spring 的 Bean 的方式注入。
@Autowired
@Qualifier(value="db2EntityManagerFactory")
private EntityManagerFactory entityManagerFactory;
这种方式是我比较推荐的,它利用了 Spring 自身的 Bean 的管理机制。
第二种:利用 java.persistence.PersistenceUnit 注解的方式获取。
@PersistenceUnit("db2")
private EntityManagerFactory entityManagerFactory;
EntityManager 和 PersistenceContext 是什么?
按照 JPA 协议的规范,我们先理解一下 PersistenceContext,它是用来管理会话里面的 Entity 状态的一个上下文环境,使 Entity 的实例有了不同的状态,也就是我们所说的实体实例的生命周期。
而这些实体在 PersistenceContext 中的不同状态都是通过 EntityManager 提供的一些方法进行管理的,也就是说:
-
PersistenceContext 是持久化上下文,是 JPA 协议定义的,而 Hibernate 的实现是通过 Session 创建和销毁的,也就是说一个 Session 有且仅有一个 PersistenceContext;
-
PersistenceContext 既然是持久化上下文,里面管理的是 Entity 的状态;
-
EntityManager 是通过 PersistenceContext 创建的,用来管理 PersistenceContext 中 Entity 状态的方法,离开 PersistenceContext 持久化上下文,EntityManager 没有意义;
-
EntityManger 是操作对象的唯一入口,一个请求里面可能会有多个 EntityManger 对象。
下面我们看一下 PersistenceContext 是怎么创建的。直接打开 SessionImpl 的构造方法,就可以知道 PersistenceContext 是和 Session 的生命周期绑定的,关键代码如下:
//session实例初始化的入口
public SessionImpl(SessionFactoryImpl factory, SessionCreationOptions options) {
super( factory, options );
//Session里面创建了persistenceContext,每次session都是新对象
this.persistenceContext = createPersistenceContext();
......省略一些不重要的代码
protected StatefulPersistenceContext createPersistenceContext() {
return new StatefulPersistenceContext( this );
}
//StatefulPersistenceContext就是PersistenceContext的实现类
public class StatefulPersistenceContext implements PersistenceContext {......}
我们通过上面的讲述,知道了 PersistenceContext 的创建和销毁机制,那么 EntityManger 如何获得呢?需要通过 @PersistenceContext 的方式进行获取,代码如下:
@PersistenceContext
private EntityManager em;
而其中 @PersistenceContext 的属性配置有如下这些。
public @interface PersistenceContext {
String name() default "";
//PersistenceContextUnit的名字,多数据源的时候有用
String unitName() default "";
//是指创建的EntityManager的生命周期是存在事务内还是可以跨事务,默认为生命周期和事务一样;
PersistenceContextType type() default PersistenceContextType.TRANSACTION;
//同步的类型:只有SYNCHRONIZED和UNSYNCHRONIZED两个值用来表示,但开启事务的时候是否自动加入已开启的事务里面,默认SYNCHRONIZED表示自动加入,不创建新的事务。而UNSYNCHRONIZED表示,不自动加入上下文已经有的事务,自动开启新的事务;这里你使用的时候需要注意看一下事务的日志;
SynchronizationType synchronization() default SynchronizationType.SYNCHRONIZED;
//持久化的配置属性,这里指我们上一课时讲过的hibernate中AvailableSettings里面的值
PersistenceProperty[] properties() default {};
}
一般情况下保持默认即可,你也可以根据实际情况自由组合,我再举个复杂点的例子。
@PersistenceContext(
unitName = "db2",//采用数据源2的
//可以跨事务的EntityManager
type = PersistenceContextType.EXTENDED,
properties = {
//通过properties改变一下自动flush的机制
@PersistenceProperty(
name="org.hibernate.flushMode",
value= "MANUAL"//改成手动刷新方式
)
}
)
private EntityManager entityManager;
以上就是 Persistence Context 的相关基础概念。其中,实体的生命周期指的是什么呢?我们来了解一下。
实体对象的生命周期
既然 PersistenceContext 是存储 Entity 的,那么 Entity 在 PersistenceContext 里面肯定有不同的状态。对此,JPA 协议定义了四种状态:new、manager、detached、removed。我们通过一个图来整体认识一下。
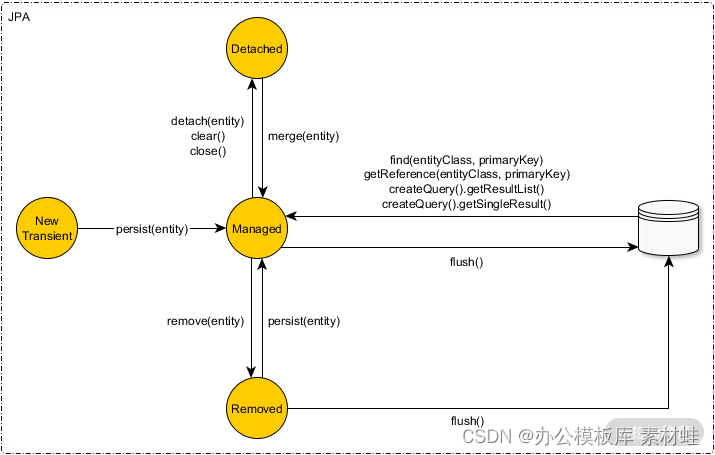
注:图片来自网络
第一种:New 状态的对象
当我们使用关键字 new 的时候创建的实体对象,称为 new 状态的 Entity 对象。它需要同时满足两个条件:new 状态的实体 Id 和 Version 字段都是 null;new 状态的实体没有在 PersistenceContext 中出现过。
那么如果我们要把 new 状态的 Entity 放到 PersistenceContext 里面,有两种方法:执行 entityManager.persist(entity) 方法;通过关联关系的实体关系配置 cascade=PERSIST or cascade=ALL 这种类型,并且关联关系的一方,也执行了 entityManager.persist(entity) 方法。
我们使用一个案例来说明一下。
@Test
public void testPersist() {
UserInfo userInfo = UserInfo.builder().lastName("jack").build();
//通过contains方法可以验证对象是否在PersistenceContext里面,此时不在
Assertions.assertFalse(entityManager.contains(userInfo));
//通过persist方法把对象放到PersistenceContext里面
entityManager.persist(userInfo);
//通过contains方法可以验证对象是否在PersistenceContext里面,此时在
Assertions.assertTrue(entityManager.contains(userInfo));
Assertions.assertNotNull(userInfo.getId());
}
这就是 new 状态的实体对象,我们再来看一下和它类似的 Deteched 状态的对象。
第二种:Detached(游离)的实体对象
Detached 状态的对象表示和 PersistenceContext 脱离关系的 Entity 对象。它和 new 状态的对象的不同点在于:
-
Detached 是 new 状态的实体对象没有持久化 ID(即没有 ID 和 version);
-
变成持久化对象需要进行 merger 操作,merger 操作会 copy 一个新的实体对象,然后把新的实体对象变成 Manager 状态。
而 Detached 和 new 状态的对象相同点也有两个方面:
-
都和 PersistenceContext 脱离了关系;
-
当执行 flush 操作或者 commit 操作的时候,不会进行数据库同步。
如果想让 Manager(persist) 状态的对象从 PersistenceContext 里面游离出来变成 Detached 的状态,可以通过 EntityManager 的 Detach 方法实现,如下面这行代码。
entityManager.detach(entity);
当执行完 entityManager.clear()、entityManager.close(),或者事务 commit()、事务 rollback() 之后,所有曾经在 PersistenceContext 里面的实体都会变成 Detached 状态。
而游离状态的对象想回到 PersistenceContext 里面变成 manager 状态的话,只能执行 entityManager 的 merge 方法,也就是下面这行代码。
entityManager.merge(entity);
游离状态的实体执行 EntityManager 中 persist 方法的时候就会报异常,我们举个例子:
@Test
public void testMergeException() {
//通过new的方式构建一个游离状态的对象
UserInfo userInfo = UserInfo.builder().id(1L).lastName("jack").version(1).build();
//验证是否存在于persistence context 里面,new的肯定不存在
Assertions.assertFalse(entityManager.contains(userInfo));
//当执行persist方法的时候就会报异常
Assertions.assertThrows(PersistentObjectException.class,()->entityManager.persist(userInfo));
//detached状态的实体通过merge的方式保存在了persistence context里面
UserInfo user2 = entityManager.merge(userInfo);
//验证一下存在于持久化上下文里面
Assertions.assertTrue(entityManager.contains(user2));
}
以上就是 new 和 Detached 状态的实体对象,我们再来看第三种——Manager 状态的实体又是什么样的呢?
第三种:Manager(persist) 状态的实体
Manager 状态的实体,顾名思义,是指在 PersistenceContext 里面管理的实体,而此种状态的实体当我们执行事务的 commit(),或者 entityManager 的 flush 方法的时候,就会进行数据库的同步操作。可以说是和数据库的数据有映射关系。
New 状态如果要变成 Manager 的状态,需要执行 persist 方法;而 Detached 状态的实体如果想变成 Manager 的状态,则需要执行 merge 方法。在 session 的生命周期中,任何从数据库里面查询到的 Entity 都会自动成为 Manager 的状态,如 entityManager.findById(id)、entityManager.getReference 等方法。
而 Manager 状态的 Entity 要同步到数据库里面,必须执行 EntityManager 里面的 flush 方法。也就是说我们对 Entity 对象做的任何增删改查,必须通过 entityManager.flush() 执行之后才会变成 SQL 同步到 DB 里面。什么意思呢?我们看个例子。
@Test
@Rollback(value = false)
public void testManagerException() {
UserInfo userInfo = UserInfo.builder().lastName("jack").build();
entityManager.persist(userInfo);
System.out.println("没有执行 flush()方法,产生insert sql");
entityManager.flush();
System.out.println("执行了flush()方法,产生了insert sql");
Assertions.assertTrue(entityManager.contains(userInfo));
}
执行完之后,我们可以看到如下输出:
没有执行 flush()方法,产生insert sql
Hibernate: insert into user_info (create_time, create_user_id, last_modified_time, last_modified_user_id, version, ages, email_address, last_name, telephone, id) values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
执行了flush()方法,产生了insert sql
那么这个时候你可能会问了,并没有看到我们在之前写的 Repository 例子里面手动执行过任何 flush() 操作呀,那么请你带着这个问题继续往下看。了解下实体的第四个状态:Removed。
第四种:Removed 的实体状态
Removed 的状态,顾名思义就是指删除了的实体,但是此实体还在 PersistenceContext 里面,只是在其中表示为 Removed 的状态,它和 Detached 状态的实体最主要的区别就是不在 PersistenceContext 里面,但都有 ID 属性。
而 Removed 状态的实体,当我们执行 entityManager.flush() 方法的时候,就会生成一条 delete 语句到数据库里面。Removed 状态的实体,在执行 flush() 方法之前,执行 entityManger.persist(removedEntity) 方法时候,就会去掉删除的表示,变成 Managed 的状态实例。我们还是看个例子。
@Test
public void testDelete() {
UserInfo userInfo = UserInfo.builder().lastName("jack").build();
entityManager.persist(userInfo);
entityManager.flush();
System.out.println("执行了flush()方法,产生了insert sql");
entityManager.remove(userInfo);
entityManager.flush();
System.out.println("执行了flush()方法之后,又产生了delete sql");
}
执行完之后可以看到如下日志:
Hibernate: insert into user_info (create_time, create_user_id, last_modified_time, last_modified_user_id, version, ages, email_address, last_name, telephone, id) values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
执行了flush()方法,产生了insert sql
Hibernate: delete from user_info where id=? and version=?
执行了flush()方法之后,又产生了delete sql
到这里四种实体对象的状态就介绍完了,通过上面的详细解释,你知道了 Entity 的不同状态的时机是什么样的、不同状态直接的转化方式是什么样的,并且知道实体状态的任何变化都是在 Persistence Context 中进行的,和数据一点关系没有。
这仅仅是 JPA 和 Hibernate 为了提高方法执行的性能而设计的缓存实体机制,也是 JPA 和 MyBatis 的主要区别之处。
MyBatis 是对数据库的操作所见即所得的模式;而使用 JPA,你的任何操作都不会产生 DB 的sql。那么什么时间才能进行 DB 的 sql 操作呢?我们看一下 flush 的实现机制。
解密 EntityManager 的 flush() 方法
flush 方法的用法很简单,就是我们在需要 DB 同步 sql 执行的时候,执行 entityManager.flush() 即可,它的作用如下所示。
Flush 的作用
flush 重要的、唯一的作用,就是将 Persistence Context 中变化的实体转化成 sql 语句,同步执行到数据库里面。换句话来说,如果我们不执行 flush() 方法的话,通过 EntityManager 操作的任何 Entity 过程都不会同步到数据库里面。
而 flush() 方法很多时候不需要我们手动操作,这里我直接通过 entityManager 操作 flush() 方法,仅仅是为了向你演示执行过程。实际工作中很少会这样操作,而是会直接利用 JPA 和 Hibernate 底层框架帮我们实现的自动 flush 的机制。
Flush 的机制是什么?
JPA 协议规定了 EntityManager 可以通过如下方法修改 FlushMode。
//entity manager 里面提供的修改FlushMode的方法
public void setFlushMode(FlushModeType flushMode);
//FlushModeType只有两个值,自动和事务提交之前
public enum FlushModeType {
//事务commit之前
COMMIT,
//自动规则,默认
AUTO
}
而 Hiberbernate 还提供了一种手动触发的机制,可以通过如下代码的方式进行修改。
@PersistenceContext(properties = {@PersistenceProperty(
name = "org.hibernate.flushMode",
value = "MANUAL"//手动flush
)})
private EntityManager entityManager;
手动和 commit 的时候很好理解,就是手动执行 flush 方法,像我们案例中的写法一样;事务就是代码在执行事务 commit 的时候,必须要执行 flush() 方法,否则怎么将 PersistenceContext 中变化了的对象同步到数据库里面呢?下面我重点说一下 flush 的自动机制。
Flush 的自动机制
默认情况下,JPA 和 Hibernate 都是采用的 AUTO 的 Flush 机制,自动触发的规则如下:
-
事务 commit 之前,即指执行 transactionManager.commit() 之前都会触发,这个很好理解;
-
执行任何的 JPQL 或者 native SQL(代替直接操作 Entity 的方法)都会触发 flush。这句话怎么理解呢?我们举个例子。
@Test
public void testPersist() {
UserInfo userInfo = UserInfo.builder().lastName("jack").build();
//通过contains方法可以验证对象是否在PersistenceContext里面,此时不在
Assertions.assertFalse(entityManager.contains(userInfo));
//通过persist方法把对象放到PersistenceContext里面
entityManager.persist(userInfo);//是直接操作Entity的,不会触发flush操作
//entityManager.remove(userInfo);//是直接操作Entity的,不会触发flush操作
System.out.println("没有执行 flush()方法,产生insert sql");
UserInfo userInfo2 = entityManager.find(UserInfo.class,2L);//是直接操作Entity的,这个就不会触发flush操作
// userInfoRepository.queryByFlushTest();//是操作JPQL的,这个就会先触发flush操作;
System.out.println("flush()方法,产生insert sql");
//通过contains方法可以验证对象是否在PersistenceContext里面,此时在
Assertions.assertTrue(entityManager.contains(userInfo));
Assertions.assertNotNull(userInfo.getId());
}
而只有执行类似 .queryByFlushTest() 这个方法的时候,才会触发 flush,因为它是用的 JPQL 的机制执行的。
上面的方法触发了 flush 的日志,会输出如下格式,你可以看到这里多了一个 insert 语句。
没有执行 flush()方法,产生insert sql
Hibernate: insert into user_info (create_time, create_user_id, last_modified_time, last_modified_user_id, version, ages, email_address, last_name, telephone, id) values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
Hibernate: select userinfo0_.id as id1_0_, userinfo0_.create_time as create_t2_0_, userinfo0_.create_user_id as create_u3_0_, userinfo0_.last_modified_time as last_mod4_0_, userinfo0_.last_modified_user_id as last_mod5_0_, userinfo0_.version as version6_0_, userinfo0_.ages as ages7_0_, userinfo0_.email_address as email_ad8_0_, userinfo0_.last_name as last_nam9_0_, userinfo0_.telephone as telepho10_0_ from user_info userinfo0_ where userinfo0_.id=2
flush()方法,产生insert sql
没有触发 flush 的日志输出的是如下格式,其中没有 insert 语句。
没有执行 flush()方法,产生insert sql
Hibernate: select userinfo0_.id as id1_0_0_, userinfo0_.create_time as create_t2_0_0_, userinfo0_.create_user_id as create_u3_0_0_, userinfo0_.last_modified_time as last_mod4_0_0_, userinfo0_.last_modified_user_id as last_mod5_0_0_, userinfo0_.version as version6_0_0_, userinfo0_.ages as ages7_0_0_, userinfo0_.email_address as email_ad8_0_0_, userinfo0_.last_name as last_nam9_0_0_, userinfo0_.telephone as telepho10_0_0_ from user_info userinfo0_ where userinfo0_.id=?
flush()方法,产生insert sql
我们了解完了 flush 的自动触发机制还不够,因为 flush 的自动刷新机制还会改变 update、insert、delete 的执行顺序。
Flush 的时候会改变 SQL 的执行顺序
flush() 方法调用之后,同一个事务内,sql 的执行顺序会变成如下模式:insert 的先执行、delete 的第二个执行、update 的第三个执行。我们举个例子,方法如下:
entityManager.remove(u3);
UserInfo userInfo = UserInfo.builder().lastName("jack").build();
entityManager.persist(userInfo);
看一下执行的 sql 会变成如下模样,即先 insert 后 delete。
Hibernate: insert into user_info 。。。。。。
Hibernate: delete from user_info where id=? and version=?
这种会改变顺序的现象,主要是由 persistence context 的实体状态机制导致的,所以在 Hibernate 的环境中,顺序会变成如下的 ActionQueue 的模式:
-
OrphanRemovalAction -
EntityInsertActionorEntityIdentityInsertAction -
EntityUpdateAction -
CollectionRemoveAction -
CollectionUpdateAction -
CollectionRecreateAction -
EntityDeleteAction
flush 的作用你已经知道了,它会把 sql 同步执行到数据库里面。但是需要注意的是,虽然 sql 到数据库里面执行了,那么最终数据是不是持久化,是不是被其他事务看到还会受到控制呢?Flush 与事务 Commit 的关系如何?
Flush 与事务 Commit 的关系
大概有以下几点:
-
在当前的事务执行 commit 的时候,会触发 flush 方法;
-
在当前的事务执行完 commit 的时候,如果隔离级别是可重复读的话,flush 之后执行的 update、insert、delete 的操作,会被其他的新事务看到最新结果;
-
假设当前的事务是可重复读的,当我们手动执行 flush 方法之后,没有执行事务 commit 方法,那么其他事务是看不到最新值变化的,但是最新值变化对当前没有 commit 的事务是有效的;
-
如果执行了 flush 之后,当前事务发生了 rollback 操作,那么数据将会被回滚(数据库的机制)。
以上介绍的都是 flush 的机制,那么 **Repository 里面的 saveAndFlush 有什么作用呢?
saveAndFlush 和 save 的区别
细心的同学会发现 **Repository 里面有一个 saveAndFlush(entity); 的方法,我们通过查看可以发现如下内容:
@Transactional
@Override
public <S extends T> S saveAndFlush(S entity) {
//执行了save方法之后,调用了flush()方法
S result = save(entity);
flush();
return result;
}
而另一个 **Repository 里面的 save 的方法,我们查看其源码如下:
//没有做flush操作,只是,执行了persist或者merge的操作
@Transactional
@Override
public <S extends T> S save(S entity) {
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
所以这个时候我们应该很清楚 Repository 里面提供的 saveAndFlush 和 save 的区别,有如下几点:
-
saveAndFlush 执行完,再执行 flush,会刷新整个 PersistenceContext 里面的实体并进入到数据库里面,那么当我们频繁调用 saveAndFlush 就失去了 cache 的意义,这个时候就和执行 mybatis 的 saveOrUpdate 是一样的效果;
-
当多次调用相同的 save 方法的时候,最终 flush 执行只会产生一条 sql,在性能上会比 saveAndFlush 高一点;
-
不管是 saveAndFlush 还是 save,都受当前事务控制,事务在没有 commit 之前,都只会影响当前事务的操作;
综上,两种本质的区别就是 flush 执行的时机不一样而已,对数据库中数据的事务一致性没有任何影响。然而有的时候,即使我们调用了 flush 的方法也是一条 sql 都没有,为什么呢?我们再来了解一个概念:Dirty。
Entity 的 Dirty 判断逻辑及其作用
在 PersistenceContext 里面还有一个重要概念,就是当实体不是 Dirty 状态,也就是没有任何变化的时候,是不会进行任何 db 操作的。所以即使我们执行 flush 和 commit,实体没有变化,就没有必要执行,这也能大大减少数据库的压力。
下面通过一个例子,认识一下 Dirty 的效果。
Dirty 的效果的例子
//我们假设数据库里面存在一条id=1的数据,我们不做任何改变执行save或者saveAndFlush,除了select之外,不会产生任何sql语句;
@Test
@Transactional
@Rollback(value = false)
public void testDirty() {
UserInfo userInfo = userInfoRepository.findById(1L).get();
userInfoRepository.saveAndFlush(userInfo);
userInfoRepository.save(userInfo);
}
那么当我们尝试改变一下 userInfo 里面的值,当执行如下方法的时候就会产生 update 的 sql。
@Test
@Transactional
@Rollback(value = false)
public void testDirty() {
UserInfo userInfo = userInfoRepository.findById(1L).get();
userInfo.setLastName("jack_test_dirty");
userInfoRepository.saveAndFlush(userInfo);
}
那么实体的 Dirty 判断过程是什么样的呢?我们通过源码来看一下。
Entity 判断 Dirty 的过程
如果我们通过 debug 一步一步分析的话可以找到,DefaultFlushEntityEventListener 的源码里面 isUpdateNecessary 的关键方法如下所示:
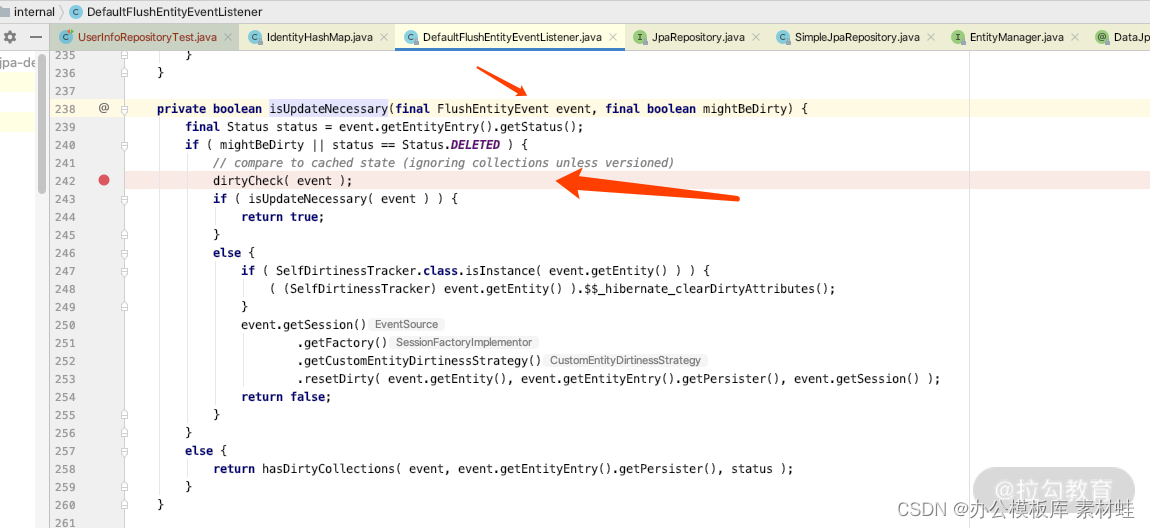
我们进一步 debug 看 dirtyCheck 的实现,可以看发现如下关键点,从而找出发生变化的 proerties。
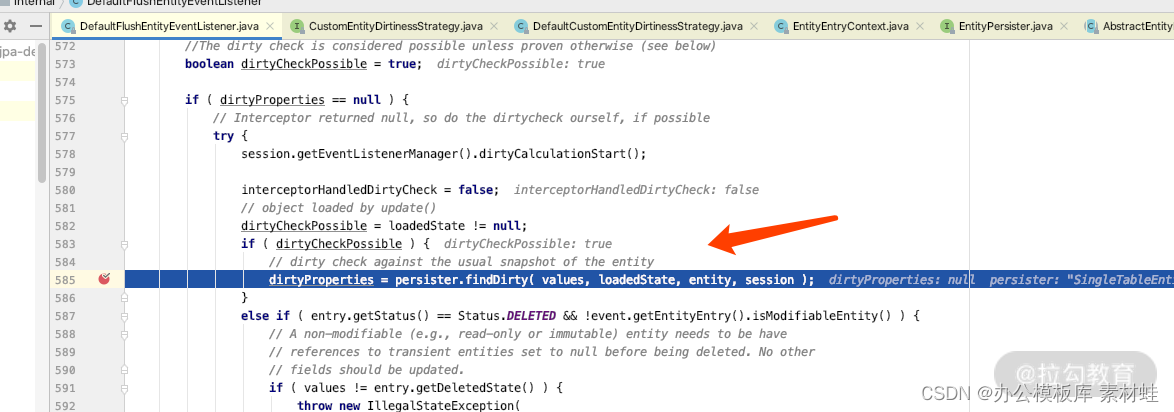
我们再仔细看 persister.findDirty(values, loadedState, entity, session),可以看出来源码里面是通过一个字段一个字段比较的,所以可以知道 PsersistenceContext 中的前后两个 Entity 的哪些字段发生了变化。因此当我们执行完 save 之后,没有产生任何 sql(因为没有变化)。你知道了这个原理之后,就不用再为此“大惊小怪”了。
总结起来就是,在 flush 的时候,Hibernate 会一个个判断实体的前后对象中哪个属性发生变化了,如果没有发生变化,则不产生 update 的 sql 语句;只有变化才会才生 update sql,并且可以做到同一个事务里面的多次 update 合并,从而在一定程度上可以减轻 DB 的压力。
总结
这一讲我为你介绍了 PersistenceContext 的概念、EntityManager 的作用,以及 flush 操作是什么时机进行的,它和事务的关系如何。其中也夹杂了我多年来的经验分享,希望你可以从头到尾学下来。
如果你能完全理解这一讲的内容,那么对于 JPA 和 Hibernate 的核心原理你算是掌握一大半了,没掌握的同学的也不要紧,跟着我的操作,每一篇都仔细探究,你也会逐渐掌握这门技术的,加油吧!
下一课时我会为你介绍 PersistenceContext 的容器 Session 相关的概念,到时见。















 207
207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











