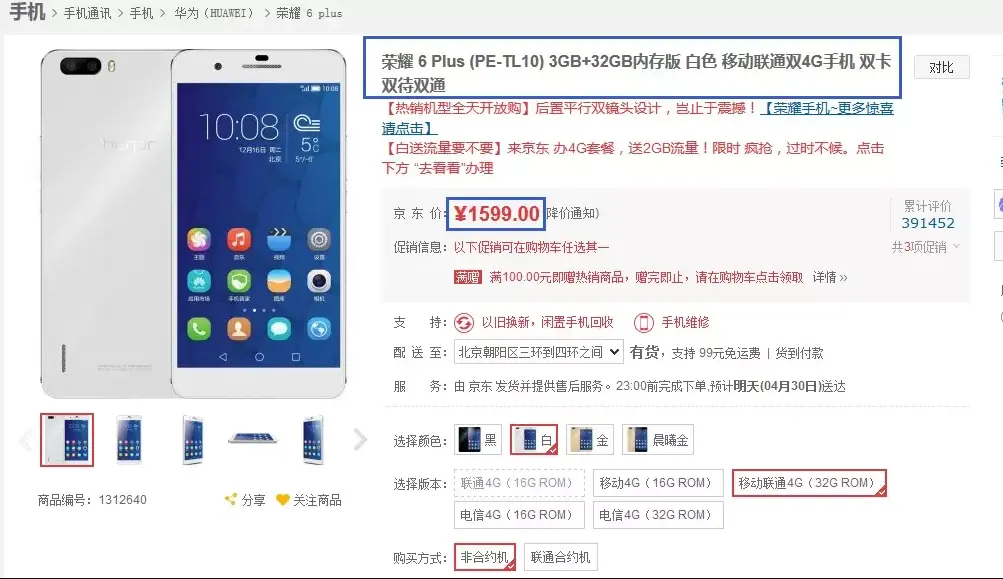
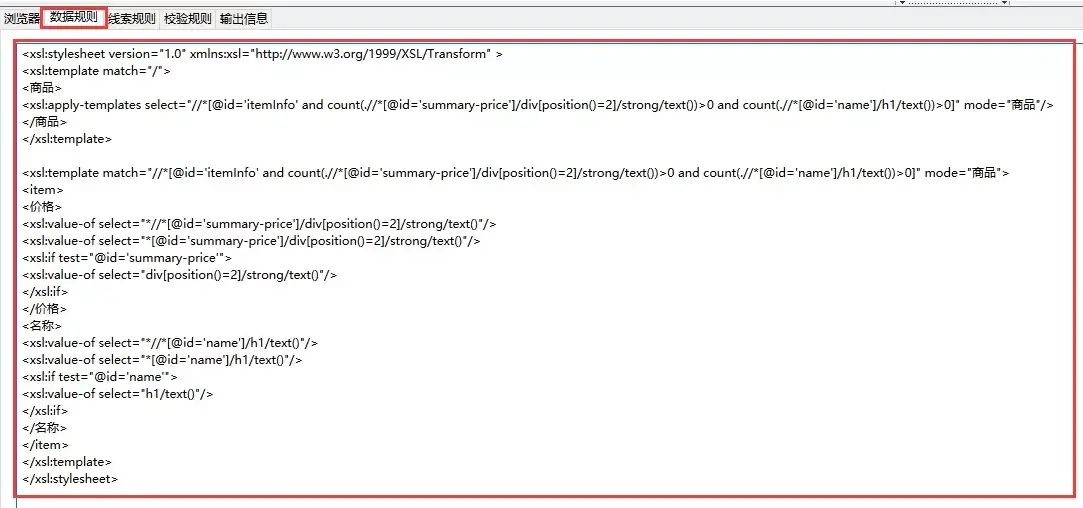
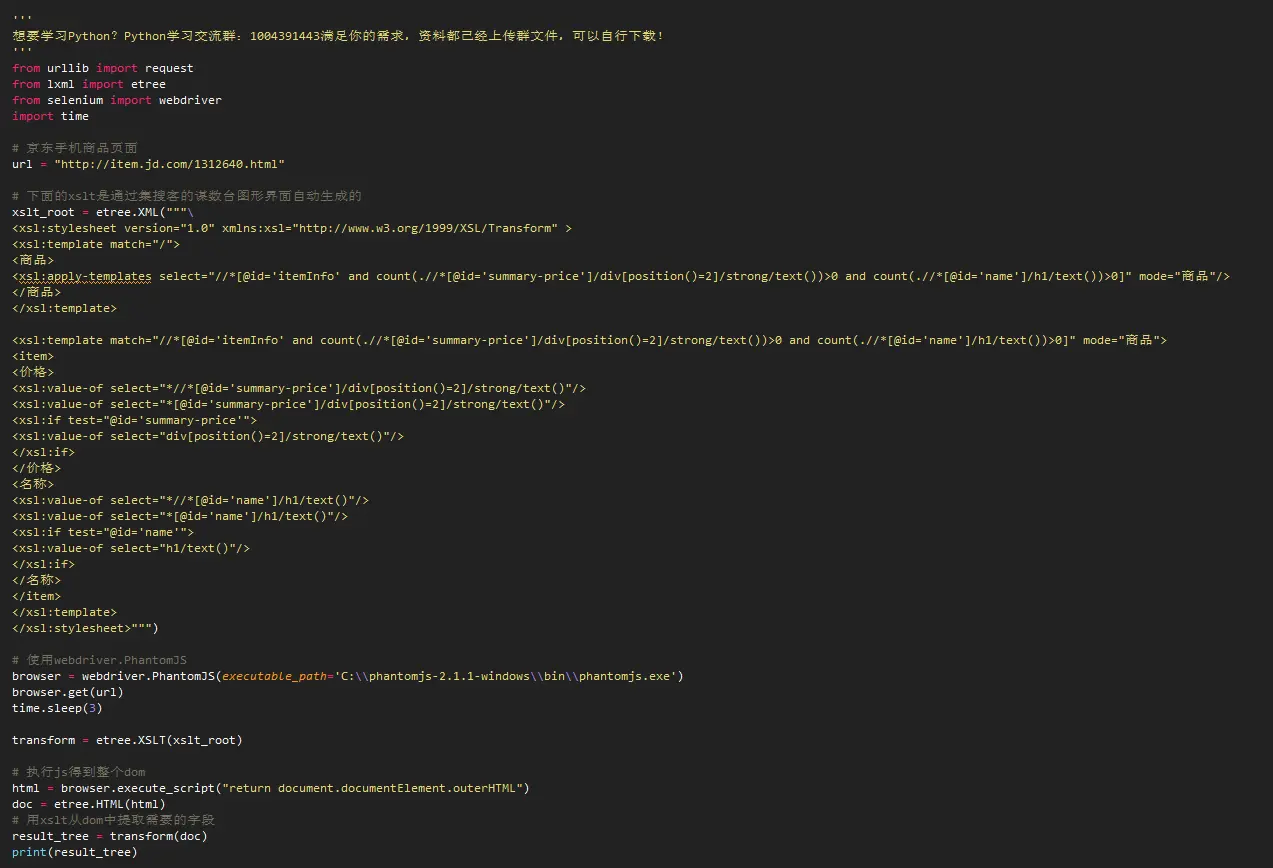
源代码和实验过程 假如我们要抓取京东手机页面的手机名称和价格(价格在网页源码是找不到的),如下图: 第一步:利用集搜客谋数台的直观标注功能,可以极快速度自动生成一个调试好的抓取规则,其实是一个标准的xslt程序,如下图,把生成的xslt程序拷贝到下面的程序中即可。注意:本文只是记录实验过程,实际系统中,将采用多种方式把xslt程序注入到内容提取器重。 . 第二步:执行如下代码(在windows10, python3.2下测试通过),请注意:xslt是一个比较长的字符串,如果删除这个字符串,代码没有几行,足以见得Python之强大 第三步:下图可以看到,网页中的手机名称和价格被正确抓取下来了
























 208
208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






