







SVM
1.概述
SVM全称Support_Vector_Machine,即支持向量机,是机器学习中的一种监督学习分类算法,一般用于二分类问题。对于线性可分的二分类问题,SVM可以直接求解,对于非线性可分问题,其也可以通过核函数将低维映射到高维空间从而转变为线性可分。对于多分类问题,SVM经过适当的转换,也能加以解决。相对于传统的分类算法如logistic回归,k近邻法,决策树,感知机,高斯判别分析法(GDA)等,SVM尤其独到的优势。相对于神经网络复杂的训练计算量,SVM在训练方面较少计算量的同时也能得到很好的训练效果。
2.问题的提出
考虑一个线性可分的二分类问题
m个训练样本 x 是特征向量,
y 是目标变量{x(i),y(i)},x(i)∈Rn,y(i)∈{1,−1},i=1,2,⋯,m
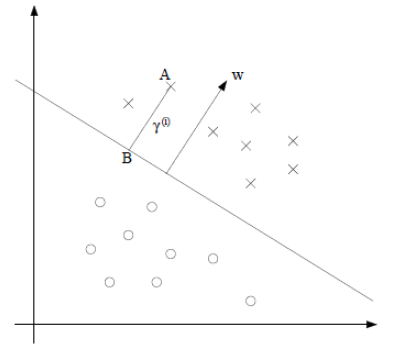
决策函数: hw,b(x)=g(wTx+b),g(z)={1,ifx>00,ifx<0
直线代表 wTx+b=0首先定义一些符号
functional margin(函数边界)
r^=min{r^(i)},i=1,2,⋯,m;r^(i)=y(i)∗(wTx(i)+b)
geometrical margin(几何边界)
r=min{r(i)},i=1,2,⋯,m;r(i)=y(i)∗(wTx(i)+b)∥w∥
符号解释:
- 函数边界:由于
y(i)
只能取
1,−1
,所以当
wT∗x(i)+b>>0
时,
y=1
和
y=−1
分别表示点分布在距离超平面
wTx+b=0
两边很远的地方,注意如果加倍
w
与
x ,函数边界是会加倍的
- 函数边界:由于
y(i)
只能取
1,−1
,所以当
wT∗x(i)+b>>0
时,
y=1
和
y=−1
分别表示点分布在距离超平面
wTx+b=0
两边很远的地方,注意如果加倍
w
与
目标:几何边界最大,即
max{r}
3.问题的转化
依次转化:
- max{r}
- max{min{r(i)=y(i)∗(wTx(i)+b)∥w∥};i=1,2,⋯,m}
- ⎧⎩⎨max{r}s.t.y(i)∗(wTx(i)+b)∥w∥≥r
- {max{r^∥w∥}s.t.y(i)∗(wTx(i)+b)≥r^
- 注意函数边界的改变不影响优化问题的求解结果
letr^=1
问题转化为:
{max{1∥w∥}s.t.y(i)∗(wTx(i)+b)≥1
最终转化为optimization problem,而且目标函数是convex的,即凸函数
{min{12w2}s.t.y(i)∗(wTx(i)+b)≥1最终得到优化问题(1)
4.问题求解
(1)可以用通常的QP(二次规划)方法求解,matlab或lingo都有相应工具箱。
(2)既然本文叫SVM,当然会用到不同的解法,而且SVM的解法在训练集很大的时候,比一般的QP解法效率高。
广义拉格朗日数乘法
对于3中得到的优化问题(1)有:
{L(w,b,α)=12w2−∑mi=1α(i)[y(i)∗(wTx(i)+b)−1]α(i)≥0- 满足约束条件
y(i)∗(wTx(i)+b)≥1
下有:
max{L(w,b,α)}=1w2=f(w)
- 满足约束条件
y(i)∗(wTx(i)+b)≥1
下有:
优化问题变为:
⎧⎩⎨⎪⎪minw,b{maxα{L(w,b,α)}}s.t.y(i)∗(wTx(i)+b)≥1α(i)≥0
在满足KKT条件下有(对偶优化问题)
-
minw,b{maxα{L(w,b,α)}}=maxα{minw,b{L(w,b,α)}}
通常对偶问题(dual problem) max{min{f(w,α)}} 比原始问题(primal problem) min{max{f(w,α)}} 更容易求解,尤其是在训练样本数量很大的情况下,KKT条件又称为互补松弛条件
∇w,bL(w¯,b¯,α¯)=0;
w¯,b¯是primaloptimal;α¯是dualoptimal
α¯(i)gi(w¯,b¯)=0 ,
y(i)∗(wTx(i)+b)=1 时,通常有 α≠0 ,这些点称为Support Vector,即支持向量 y(i)∗(wTx(i)+b)>1 时,有 α=0 ,通常大多数 α 为0,减少了计算量
-
minw,b{maxα{L(w,b,α)}}=maxα{minw,b{L(w,b,α)}}
解决 minw,b{L(w,b,α)}
求偏导令为0可得 {w=∑mi=1α(i)y(i)x(i)∑mi=1α(i)y(i)=0
带入原式:
⎧⎩⎨⎪⎪maxα{∑mi=1α(i)−12∑mi,j=1y(i)y(j)α(i)α(j)<x(i),x(j)>}α(i)≥0∑mi=1α(i)y(i)=0
- 求得 α 则可得到 w,b
- 目标表示为 wTx+b=∑mi=1α(i)y(i)<x(i),x>+b
-
kernel(x,y)=<xT,y>
称为核函数,能较少高维空间计算量,通常知道了核函数,计算量相对于找对应的
x,y
向量小得多,而且若
x,y
是无限维向量,也可通过核函数映射。常用的核函数有:
- 高斯核 K(x,z)=exp(−∥z−x∥2σ2)
- 多项式核 K(x,z)=(x−z)a
5.问题的优化
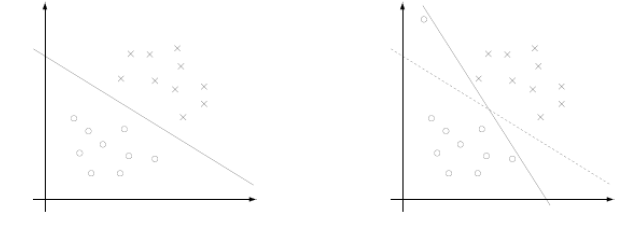
4中推导出了求 α 使得最大化的问题。但其存在一定问题。
当训练集如右图分布在超平面两侧时,结果并不好,因此我们可以给 r^=1 添加松弛条件,允许少数点小于1,甚至分类到错误的一面
我们修改限制条件,并修改目标函数
⎧⎩⎨⎪⎪min{12w2+csummi=1ξi}y(i)∗(wTx(i)+b)≥1−ξiξi≥0
通过类似的对偶问题的求解,我们得到
⎧⎩⎨⎪⎪⎪⎪⎪⎪⎪⎪W=maxα{∑mi=1α(i)−12∑mi,j=1y(i)y(j)α(i)α(j)<x(i),x(j)>}0≤α≤c∑mi=1α(i)y(i)=0
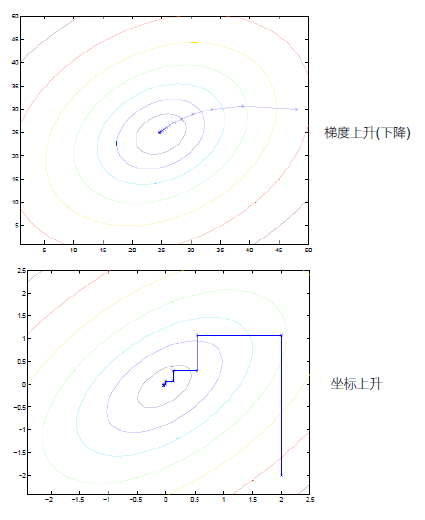
6.优化后问题的求解
- 坐标上升法求解最大值
#伪代码
loop {
for i in range(m):
alpha(i):=alpha(i) which let {w} maximum
}坐标上升与梯度上升的对比图
SMO
#伪代码
L<=alpha<=H
loop {
for i,j in range(m):
alpha(i):=min{ (alpha(i) or L or H ) which let {w} maximum }
alpha(j):=min{ (alpha(j) or L or H ) which let {w} maximum }
}7.实战
- trainsets 总共90组
-0.017612 14.0530640
-1.395634 4.6625411
-0.752157 6.5386200
-1.322371 7.1528530
…………………………
-1.076637 -3.1818881
1.821096 10.2839900
3.010150 8.4017661
-1.099458 1.6882741
-0.834872 -1.7338691
-0.846637 3.8490751
1.400102 12.6287810
1.752842 5.4681661
0.078557 0.0597361 testsets 总共10组
0.089392 -0.7153001
1.825662 12.6938080
0.197445 9.7446380
0.126117 0.9223111
-0.679797 1.2205301
0.677983 2.5566661
0.761349 10.6938620
-2.168791 0.1436321
1.388610 9.3419970
0.317029 14.7390250logistic回归效果
- 权值 weight=[[11.93391219][1.12324688][−1.60965531]]
- 原始测试文件真值 y=[1.0,0.0,0.0,1.0,1.0,1.0,0.0,1.0,0.0,0.0]
- logistic回归预测值: y1=[1.0,0.0,0.0,1.0,1.0,1.0,0.0,1.0,0.0,0.0]
- 正确率还是蛮高的
- 附上代码:
#!/usr/bin/env
#coding:utf-8
import numpy
import sys
from matplotlib import pyplot
import random
def makedata(filename):
try:
f = open(filename,"r")
lines = f.readlines()
datalist = []
datalist = [i.split() for i in lines ]
datalist = [ [ float(i) for i in line] for line in datalist ]
for i in range(len(datalist)):
datalist[i].insert(0,1.0)
except:
return
finally:
return datalist
f.close()
def makedat(filename):
try:
f = open(filename,"r")
lines = f.readlines()
datalist = []
datalist = [i.split() for i in lines ]
datalist = [ [ float(i) for i in line] for line in datalist ]
x = [ line[0:len(line)-1] for line in datalist ]
y = [ line[-1] for line in datalist ]
except:
return
finally:
return x,y
f.close()
def sigma(z):
return 1.0/(1+numpy.exp(-z))
#batch regression
def logisticFunc(dataset,itertimes,alpha):
weight = numpy.ones((len(dataset[0])-1,1))
value = [ int(i[-1]) for i in dataset ]
value = numpy.mat(value).transpose()
params = [ i[0:-1] for i in dataset ]
params = numpy.mat(params)
for i in range(int(itertimes)):
error = value-sigma(params*weight)
weight = weight+alpha*params.transpose()*error
return weight
#random grad ascend regression
def randLogisticFunc(dataset,itertimes,alpha):
weight = numpy.ones((len(dataset[0])-1,1))
value = [ int(i[-1]) for i in dataset ]
value = numpy.mat(value).transpose()
params = [ i[0:-1] for i in dataset ]
params = numpy.mat(params)
for i in range(int(itertimes)):
randid = random.randint(0,len(dataset)-1)
error = value[randid]-sigma(params[randid]*weight)
weight = weight+alpha*params[randid].transpose()*error
return weight
def plot(data,weight):
x1 = []
x2 = []
y1 = []
y2 = []
for i in data:
if i[-1] == 1:
x1.append(i[1])
y1.append(i[2])
else:
x2.append(i[1])
y2.append(i[2])
x = numpy.linspace(-3,3,1000)
weight = numpy.array(weight)
y = (-weight[0][0]-weight[1][0]*x)/weight[2][0]
fg = pyplot.figure()
sp = fg.add_subplot(111)
sp.scatter(x1,y1,s=30,c="red")
sp.scatter(x2,y2,s=30,c="blue")
sp.plot(x,y)
pyplot.show()
def predict(weight,x1):
yi = []
for i in x1:
if weight[0][0]+i[0]*weight[1][0]+i[1]*weight[2][0]>=0:
yi.append(1)
else:
yi.append(0)
print yi
def main():
trainfile = sys.argv[1]
itertimes = int(sys.argv[2])
alpha = float(sys.argv[3])
testfile = sys.argv[4]
data = makedata(trainfile)
testx,testy = makedat(testfile)
weight = logisticFunc(data,itertimes,alpha)
print weight
predict(weight,testx)
print testy
#weight = randLogisticFunc(data,itertimes,alpha)
#print weight
plot(data,weight)
if __name__=='__main__':
main()- SVM效果(采用高斯核,使用sklearn库)
- 原始测试文件真值 y=[1.0,0.0,0.0,1.0,1.0,1.0,0.0,1.0,0.0,0.0]
- svm预测值: y1=array([1.,0.,0.,1.,1.,1.,0.,1.,0.,0.])
- 正确率也挺高的
- 附上代码:
#!/usr/bin/env python
#coding:utf-8
from sklearn import svm
import sys
def makedata(filename):
try:
f = open(filename,"r")
lines = f.readlines()
datalist = []
datalist = [i.split() for i in lines ]
datalist = [ [ float(i) for i in line] for line in datalist ]
x = [ line[0:len(line)-1] for line in datalist ]
y = [ line[-1] for line in datalist ]
except:
return
finally:
return x,y
f.close()
def learn(x,y):
clf = svm.SVC()
clf.fit(x,y)
return clf
def predict(x1,y1,clf):
print "svm fit results",clf.predict(x1)
print "original test file results",y1
if __name__=="__main__":
inputfile = sys.argv[1]
testfile = sys.argv[2]
x,y = makedata(inputfile)
x1,y1 = makedata(testfile)
clf = learn(x,y)
predict(x1, y1, clf)













 1502
1502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









