







qspin-lock的原理以及实现
ticket spinlock已经有大量完善的分析文章,arm64 在kernel在4.16rc6之后就将默认的spinlock改为了qspinlock,目前分析的文章较少,并且看了下还是很难理解,我自己还是啃代码看完的,所以这里做个记录。
另外,还没遇到过qspinlock引起的问题,没看到运行时的相关数据结构,这篇文章只是分析代码得来的,没有实战经验不确定是否全部正确。
没啥用的前言介绍
如果已经了解相关背景只想看原理请跳过这段废话,如果并不清楚背景知识还请看一看,了解设计原理有利于理解程序的实现。
第一个版本 其实,kernel很早就实现了spinlock,之前的lock叫做ticket-spinlock,最早的ticket lock非常简单,自旋锁spinlock用一个整数值来表示,表明了锁是否可用,初值设为1。spin_lock()函数通过递减val(原子方式),然后查看是否为0,若为0则成功拿锁,若为负数则代表锁已属于他人,所以它进入spin状态,不断查询val值直到变为1。当锁的拥有者完成critical section的执行,将val置为1,即释放锁。这是最原始的实现,实际上就是原子变量,坏处在于没有排队机制,等待时间最长的CPU不一定能最先拿到锁。
第二个版本 后来,就是最常见的owner与next叫号机制实现的spinlock,这种机制的问题在于假设一个CPU持锁,7个CPU等待,等待的7个CPU都必须不停地读cache,当持锁者解锁,只有最先等待的CPU能够拿到,与其他的CPU无关,但是所有等待的CPU都必须重新刷新cache,因为解锁的时候会修改结构体成员,数据发生了变化。
第三个版本 考虑到这种性能浪费,就有人设计另一种锁 MCS-lock:为等待的CPU分配锁的副本,每个CPU只等待自己所属的副本发生改变(下文会把这种情况叫做在自己的副本自旋),这样避免cache刷新的问题。这种锁始终没有在kernel得到广泛使用(只有x86会有它的接口),因为他的结构里面多了一个指针导致结构体变大了,多了一个指针成员,而spinlock很多情况下都是内嵌在一些结构体里面使用,这样必然影响很多结构体的大小,内核对某些结构体的大小非常敏感,所以此方案几乎无人使用。
ARM 4.16内核之后使用的版本 最终,终于有人将MCS的结构压缩,在没有影响结构体大小的情况下实现【副本自旋】这一思想,这就是qspin-lock。本文不会介绍MCSlock相关,因为很容易把这两个锁搞混反而不利于学习,只要知道qspinlock利用了MCS的思想,甚至是数据结构,所以不要奇怪为啥会出现MCS的结构体。
数据结构介绍
首先,明确以下概念:
1.压缩结构,这是内核常用的手段,这往往意味着结构体里面含有联合体,以及程序里面大量的位操作
2.副本,这意味着除了锁的本体之外,有副本结构,而且需要某种手段将锁的本体与副本结构联系起来,通常是使用指针成员但是这里为了省空间并没有用指针
3.等待队列,要实现先到先得,等待最久的CPU最先拿到锁,就必须有等待队列
锁结构
在4.16版本,也就是刚刚引入qspinlock作为默认spinlock的版本,它的定义简直让人摸不着头脑:
typedef struct qspinlock {
atomic_t val;
} arch_spinlock_t;
就一个整数如何记录锁以及副本的信息?幸好后来的版本比如4.19做了切割,至少结构体容易读懂一些,后面的代码都会以4.19版本为例
typedef struct qspinlock {
union {
atomic_t val;
#ifdef __LITTLE_ENDIAN
struct {
u8 locked;
u8 pending;
};
struct {
u16 locked_pending;
u16 tail;
};
#else
struct {
u16 tail;
u16 locked_pending;
};
struct {
u8 reserved[2];
u8 pending;
u8 locked;
};
#endif
};
} arch_spinlock_t;
这里使用的是联合体,锁的本质仍然是一个整数,与tick-spinlock一样。宏__LITTLE_ENDIAN是用来区分大小端,保证不同的机器上结构的内存分布一样,多数机器都是小端的,因此它的内存结构和人类的读写习惯是不同的。并且根据CPU的数目不同,切割方式也不一样,这里只讨论常规情况,即 NR_CPUS < 16K(我觉得这么多的CPU大多数人是不会接触到的…)
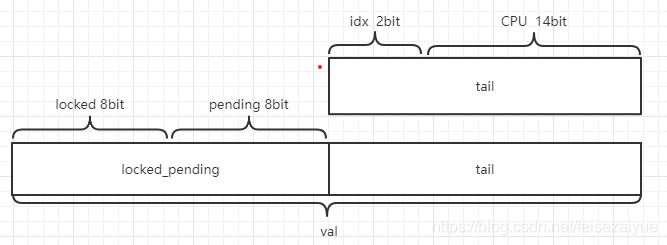
locked:用来表示这个锁是否被人持有,只会有1和0两种情况,即1被人持有,0无人持锁
pending:可以理解为最优先持锁位,即当unlock之后只有这个位的CPU最先持锁,也只会有1和0
tail:有idx+CPU构成,用来标识等待队列最后一个节点。
idx:就是index,它作为数组下标使用,介绍CPU副本的时候会一起介绍
CPU:用来表示CPU的编号+1,为何要+1?因为规定tail为0的时候表示等待队列中没有成员,如果不+1,0号CPU在等待队列中并且idx为0的情况下,tail也就是0了,那就无法区分队列中到底有没有人.
CPU副本
工作队列大家都知道,每次进程要将自己加入队列,都是临时建立一个结构体,将自己的信息写入结构体然后将结构体加入队列,qspinlock是否也是临时建立结构体作为副本?
答案是 否。工作队列是针对进程的,因此需要临时分配。而spinlock和其他的锁不同,它虽然在进程当中,但是其实对一个CPU而言它的数目是固定的。当一个进程在一个CPU上等待spinlock,此CPU能否持有其他spinlock?切换到另一个进程拿新的spinlock?当然不行,spinlock是关抢占的,此时切换进程属于非法调度。中断?是的只有中断可以,中断分为三种:softirq, hardirq和nmi。因此一个CPU最多最多只能等待四个spinlock,所以它最多处于4个spinlock的等待队列,它最多需要4个spinlock的副本。
于是,我们可以用一个数组来满足一个CPU的需求,如何满足所有CPU的需求?per-cpu数组即可。
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked;
int count;
};
static DEFINE_PER_CPU_ALIGNED(struct mcs_spinlock, mcs_nodes[MAX_NODES]);
locked:用来通知这个CPU,该你持锁了
count:每个CPU的第一个数组成员,即mcs_nodes[0].count才有作用,其余的成员的count值无意义。它用来统计这个CPU在多少spinlock的等待队列里面。听起来有点绕?前面我们说过,一个CPU最多最多只能等待四个spinlock,当它需要将自己的副本加入spinlock的等待队列时,mcs_nodes[4]有4个成员,如何决定将哪一个成员加入?有两种方法:1.将每种状态对应一个成员,比如进程上下文对应mcs_nodes[0],然后在获取spinlock时检测自己处于哪种状态,将对应的副本加入。看起来有点繁琐是不是?2.每次需要将自己加入等待队列,就将mcs_nodes[0].count +1,第一次将mcs_nodes[0]加入,第二次将mcs_nodes[1]加入,离开等待队列时将mcs_nodes[0].count -1。这样不用区分自己在哪种状态,只要保证每次加入的节点不会重复就行,kernel使用的就是第二种。
next:构成等待队列的链表成员。

这张图是很久之前画的,有一点错误,tail应该指向队列尾而不是队首,还请注意一下
代码分析
数据结构看完了,我们知道锁是struct qspinlock,他被切成了一块一块的,CPU将自己的副本加入等待队列,副本是定义好的per-cpu数组mcs_nodes[4],想要获取更详细的信息,就必须看代码。
代码也很简单,对于锁的操作就四种:初始化,加锁,解锁,try_lock。
初始化
唯一复杂的就是一对绕来绕去的宏,这里就不列出了,简单来说在不开启debug的情况下,就是struct qspinlock所有成员初始化为0。
加锁
简单来说,持锁失败分为三种情况:
1.进来发现锁处于特殊交接状态,等这个状态完成
2.只有1个CPU持锁,无人等待,那么我们持有pending位,在lock结构spin等待locked被清零,等待完成之后我们持锁
3.我们进来,发现pending位有人了或者tail不为0,说明有人在等,需要加入等待队列
a.等待队列已经有人了,我们加入等待队列,在自己的node spin等待lock被上一个节点置位,也就是上一个节点持锁通知我们,我们是队首了
b.pending位有人,但是等待队列为空,我们加入等待队列就是队首
成为队首之后,在lock结构spin等待locked和pending都被清零,等待完成之后我们持锁,如果有下个节点通知下个节点他是队首了
下面来看看代码,这里会有很多的位操作来赋值取值,我把这些宏简化出来放在这里
mask就是用来与lock->val相与获取对应字段的值,offset就是该字段与第一个bit的距离,VAL表示只设置该字段之后lock->val的值
#define _Q_SET_MASK(type) (((1U << _Q_ ## type ## _BITS) - 1)\
<< _Q_ ## type ## _OFFSET)
#define _Q_LOCKED_OFFSET 0
#define _Q_LOCKED_BITS 8
#define _Q_LOCKED_MASK 0xff
#define _Q_PENDING_OFFSET 8
#define _Q_PENDING_BITS 8
#define _Q_PENDING_MASK 0xff00
#define _Q_TAIL_IDX_OFFSET 16
#define _Q_TAIL_IDX_BITS 2
#define _Q_TAIL_IDX_MASK 0x3ff00
#define _Q_TAIL_CPU_OFFSET 18
#define _Q_TAIL_CPU_BITS 14
#define _Q_TAIL_CPU_MASK 0xfffc0000
#define _Q_TAIL_OFFSET 16
#define _Q_TAIL_MASK 0xffff
#define _Q_LOCKED_VAL 0x1
#define _Q_PENDING_VAL 0x100
typedef struct qspinlock {
union {
atomic_t val;
struct {
u8 locked;
u8 pending;
};
struct {
u16 locked_pending;
u16 tail;
};
} arch_spinlock_t;
需要注意的是struct qspinlock,一定要记住联合体的内存是共享的,lock->val取出的值是locked + pending + tail
从设计者的注释可以看出,设计者将整个锁分为三部分 (queue tail, pending bit, lock value),使用 x,x,x这一组数表示三个部分对应的值
//在没有debug的情况下,加锁的函数就只有这一步
static __always_inline void queued_spin_lock(struct qspinlock *lock)
{
u32 val;
val = atomic_cmpxchg_acquire(&lock->val, 0, _Q_LOCKED_VAL);
//atomic_cmpxchg_acquire 比较lock->val与0,相同则设置lock->val = _Q_LOCKED_VAL,返回val的旧值,否则直接返回val。
//lock->val是联合体的所有成员的结合,这里判断如果三个部分都为0,即无人持锁,无人持有pending,无人在等待队列,那么直接获取锁
//即设置val的locked为1
if (likely(val == 0))
return;
queued_spin_lock_slowpath(lock, val); //这里就是直接获取锁失败的情况,需要进行等待了
}
atomic_cmpxchg_acquire这种类型的函数是spinlock里面常用的用于原子操作的函数,往往代码中没有功能注释,网络上也很难查找,直接看代码是十几层嵌套的宏定义难以查看,我会尽量把这些函数的功能与返回值都注释出来。
void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
{
struct mcs_spinlock *prev, *next, *node;
u32 old, tail;
int idx;
------------------第一种情况:进入时为特殊的交接状态-----------------
//刚进来,发现val == _Q_PENDING_VAL,这意味着locked = 0,tail = 0,但是pending = 1
//无人持锁,等待队列为空,pending位被人持有
//之前说过pending持有者是最先等待锁的人,那么此时处于特殊的交接状态
//持锁者unlock,我们前面有人等待,但是继承人pending持有者还没反应过来没有拿锁
//这时候就等待这个特殊状态过去
if (val == _Q_PENDING_VAL) {
int cnt = _Q_PENDING_LOOPS;
val = atomic_cond_read_relaxed(&lock->val,
(VAL != _Q_PENDING_VAL) || !cnt--);
//循环读取lock->val,直到脱离这个状态,可以是pending位被清零,也可是locked被置位,也可以是等待队列中出现成员
//但是此处VAL是哪来的?C语言是区分大小写的,此文件中没有定义VAL。答案在问题1。
}
/*
* 如果除了locked还有其他位被置(tail或者pending)说明有其他的竞争者
* 我们此时肯定不是第一个等待者,跳转到需要加入等待队列的情况
*/
//代码段1开始 <-----------------------
if (val & ~_Q_LOCKED_MASK)
goto queue;
------------------第一种情况结束-----------------
------------------第二种情况:我们是第一个等待者-----------------
/*
* 来到这里意味着只有locked被置位,pending和tail都为0
* 此时我们就是第一个等待者,设置pending位(持有pending位),基于locked位进行自旋等待直到其为0
* val为锁的旧值
*/
val = queued_fetch_set_pending_acquire(lock);
//代码段1结束
/*
* 代码段1 开始已经判断了val & ~_Q_LOCKED_MASK,为何此处还要重复一次?
* 因为queued_fetch_set_pending_acquire是一个等待的过程,这个过程之后val的值可能发生变化
* 如果我们设置了pending位之前有其他CPU进入了等待队列,即tail发生了改变,存在竞争情况
* 清除设置的pending位,进入需要加入等待队列的情况
*/
if (unlikely(val & ~_Q_LOCKED_MASK)) {
if (!(val & _Q_PENDING_MASK))
clear_pending(lock);
goto queue;
}
/*
* 到达此处时,我们持有了pending位,并且tail位0,即等待队列为空
*/
if (val & _Q_LOCKED_MASK)
//atomic_cond_read_acquire,不停的读取lock->val,直到locked位被清零,即在此处spin等待locked位
atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_MASK));
/*
* 到达此处,locked位也被清零了,我们此时持有pending位
* 现在,该我们持锁了,清除pending位,表明我们不需要再等待,设置locked位持锁,正式拿到锁
*/
clear_pending_set_locked(lock);
qstat_inc(qstat_lock_pending, true);
return;
------------------第二种情况结束-----------------
------------------第三种情况:需要加入等待队列-----------------
queue:
qstat_inc(qstat_lock_slowpath, true);
pv_queue:
node = this_cpu_ptr(&mcs_nodes[0]);
//还记得上面对于count值的解释嘛?就是就是将每个CPU的mcs_nodes[0].count作为计数器,记录次CPU加入了多少spinlock的等待队列
//第一次使用mcs_nodes[0]节点加入,第二次就使用mcs_nodes[1]
idx = node->count++;
//将本CPU的CPU编号+1的值和idx,也就是节点编号制作成tail,(idx 2bit CPU num 14bit)
tail = encode_tail(smp_processor_id(), idx);
node += idx; //实际上等价于node = mcs_nodes[idx]
node->locked = 0;
node->next = NULL;
/*
* 看看在我们做准备的这么长时间里,spinlock会不会已经被解锁了,如果被解锁了
* 那就直接持锁,然后mcs_nodes[0].count-- 退出就可以了
*/
if (queued_spin_trylock(lock))
goto release;
//lock->tail设置为我们生成的新的tail,old为返回的旧的val
old = xchg_tail(lock, tail);
next = NULL;
/*
* 如果旧的tail不为0,说明等待队列里面已经有节点了
*/
if (old & _Q_TAIL_MASK) {
prev = decode_tail(old);//从旧的tail中拿到之前的等待队列的尾结点
/* 链表的尾插,新的节点加入链表 */
WRITE_ONCE(prev->next, node);
//不停的读取直到locked位被清零,即在此处spin等待locked位
//加入等待队列并且非链表头的节点在自己的CPU副本上自旋等待自己的locked成员被置位
arch_mcs_spin_lock_contended(&node->locked);
/*
* 到达此处时,我们自己的node->locked被其他人置位了,这是通知我们现在我们是等待链表的第一个了
*/
next = READ_ONCE(node->next);
if (next)
//我们现在还是不是尾结点?不是的话提前加载下一结点的cache,后面需要操作下一节点的数据的,这里是优化处理
prefetchw(next);
}
//到达此处时,可能是等待链表为空因此我们就是第一个节点
//也可能是等待我们等到了node->locked被置位,这是前一个节点告诉我们现在我们是等待链表第一个节点了
//等待链表的第一个节点等待lock的pending位和locked位全部被清零
//atomic_cond_read_acquire 在lock中spin等待pending位和locked位全部被清零
//为什么这里不是等待pending位清零然后持有pending位再去等待locked?问题二
val = atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_PENDING_MASK));
locked:
/*
* 现在,lock中spinpending位和locked位全部被清零
* 我们是等待队列的第一个节点,该我们持锁了
*/
//如果tail还是我们设置的,说明我们同时是等待队列的最后一个节点,后面没人了
//设置lock->val = 1(_Q_LOCKED_VAL),这是设置locked位,同时清零tail,因为我们是最后一个,等我们持锁等待队列就为空了
if (((val & _Q_TAIL_MASK) == tail) &&
atomic_try_cmpxchg_relaxed(&lock->val, &val, _Q_LOCKED_VAL))
goto release; /* No contention */
/* 如果tail发生了改变,说明后面有新的节点,这里先持锁 lock->locked = 1 */
set_locked(lock);
//读取下一节点
if (!next)
next = smp_cond_load_relaxed(&node->next, (VAL));
//还记得上面我们在等待队列中是等待什么?是等待自己node->locked被置位
//这个是谁置位的?答案出来了,上一个节点持锁完成之后干的
//这里就是将下一个节点的node->locked设置为1,通知他,恭喜,你是等待队列的第一个了
arch_mcs_spin_unlock_contended(&next->locked);
release:
/*
* 现在我们离开了等待队列,mcs_nodes[0].count用来表示我们在多少个spinlock的等待队列里面
* 现在该把它-1了
*/
__this_cpu_dec(mcs_nodes[0].count);
------------------第三种情况结束-----------------
}
解锁与尝试解锁
解锁很简单,设置lock->locked = 0就行了,不需要去通知谁。因为后面的人都盯着呢,一旦数据发生改变就会自行上位,不需要你通知。
尝试解锁,也就是try_lock,它的本质就是看一下是否处于 无人持有pending+等待队列为空+locked为0 的没有持锁没人等待的状态,是的话就拿锁,不回去等锁直接返回。
一些问题
问题一:谁人定义的VAL?宏里面为什么会突然多出一个这个?
以arch_mcs_spin_lock_contended(&node->locked)为例,这里是在等待locked被清零,其实现如下:
#define arch_mcs_spin_lock_contended(l) \
do { \
smp_cond_load_acquire(l, VAL); \
} while (0)
#endif
#define smp_cond_load_acquire(ptr, cond_expr) \
({ \
typeof(ptr) __PTR = (ptr); \
typeof(*ptr) VAL; \
for (;;) { \
VAL = smp_load_acquire(__PTR); \
if (cond_expr) \
break; \
__cmpwait_relaxed(__PTR, VAL); \
} \
VAL; \
})
smp_cond_load_acquired的入参突然多出一个VAL。
这个VAL在后续的函数中相当于cond_expr,用来判断何时等待结束。其实这里传入VAL是宏函数的特殊玩法,宏函数不是函数,他的传参方式不是值传递,而是直接替换。上面的宏相当于:
arch_mcs_spin_lock_contended(&node->locked)
({ \
__PTR = (&node->locked); \
typeof(*ptr) VAL; \
for (;;) { \
VAL = 读(__PTR); \
if (VAL) \
break; \ \
} \
VAL; \
})
即传入VAL相当于将读取的结果作为判断循环结束的条件。同理,其他宏中突然多出的VAL也是起到代替入参的值的作用。
问题二:不是等待pending位清零然后持有pending位再去等待locked?
从代码来看pending位较为特殊,它仅仅是作为第二个CPU等待时无需加入等待队列的一种优化,来提高效率。它不是如同locked位一样必须有人占的位置,其他条件下,都不会去动pending位。
我们到底在等待什么?
1.对于持有pending位的,在lock结构spin等待locked位
2.对于等待队列的队首,在lock结构spin等待locked位 && pending位
3.对于等待队列的非队首节点,在自己的node副本spin等待node->lock位。
所以qslock真正能够防止cache刷新问题的,其实只在第四个CPU生效,对于核心数较少的机器,比如4核-8核的设备,由于多了链表操作qspinlock与ticket-spinlock性能谁强还不一定。
qspinlock debug的一些技巧
通常遇到spinlock需要debug的情况,往往都是死锁问题,或者内存问题。内存问题熟悉数据结构即可。
例如我们要判断一块内存是否是一个正常的struct qspinlock结构,可以看以下几点:
- lock和pending结构是否是0或者1,因为多数情况下只能是这两个数值
- tail结构能否还原成标准的cpu | index,然后根据这个找到对应的cpu的mcs_node
死锁类问题需要解决的无非是谁持锁,谁等锁
- 通常可以在出现问题,例如发生soft lockup的cpu栈上获取到需要的spinlock地址
- 要想找到所有的等锁进程,有两种方式,cpu数目不多的情况下遍历所有在cpu上活跃的进程的栈,看看是否是在等待spinlock即可
如果是的话,就可以在栈里面拿到它在等待的spinlock地址。
cpu数目较多,例如108核的机器,则使用tail去寻找mcs_node组成的链表。 - 找到所有的等锁者不难,最难的问题是如何找到owner。
在未开启debug的情况下,spinlock不会记录owner,并且owner也不会在任何链表里面
目前也没有特别好的方案,可以尝试
a) 如果使用的是crash tool之类的工具分析vmcore,试试search -t在所有进程栈上检索spinlock的地址。因为一般使用spin_lock函数持有spinlock之后会马上退栈运行其他函数,所以spinlock的地址不一定在持锁者的进程栈上,但是还是有概率瞎猫碰到死耗子,所以建议试试
b) 同样中断栈也可能会有类似的情况,可以也试试
c) 持锁者之前是有概率在等锁的,所以它的mcs_spinlock可能会残留有持锁时的信息
d) 实在没办法,就只能尝试复现或者加入debug信息了。例如某个spinlock只在固定的几个流程里面被获取,就可以使用kprobe在获取之后打印一个信息,这种方式在用户态就能完成,无需修改内核,可以根据打印的cpu快速定位到持锁者。
最简单的方法还是开启debug选项复测,开启之后就会记录owner了
typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} raw_spinlock_t;
禁止其他CSDN用户转载,现在搜的全是各种转载的,同平台的就别转了

















 83
83

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









