







NAT模式-网络地址转换
Virtualserver via Network address translation(VS/NAT)
这个是通过网络地址转换的方法来实现调度的。首先调度器(LB)接收到客户的请求数据包时(请求的目的IP为VIP),根据调度算法决定将请求发送 给哪个后端的真实服务器(RS)。然后调度就把客户端发送的请求数据包的目标IP地址及端口改成后端真实服务器的IP地址(RIP),这样真实服务器 (RS)就能够接收到客户的请求数据包了。真实服务器响应完请求后,查看默认路由(NAT模式下我们需要把RS的默认路由设置为LB服务器。),把响应后的数据包发送给LB,LB再接收到响应包后,载均衡器再把数据包的原IP地址改为自己的IP,将目的地址改为客户端IP地址即可。
调度过程IP包详细图:
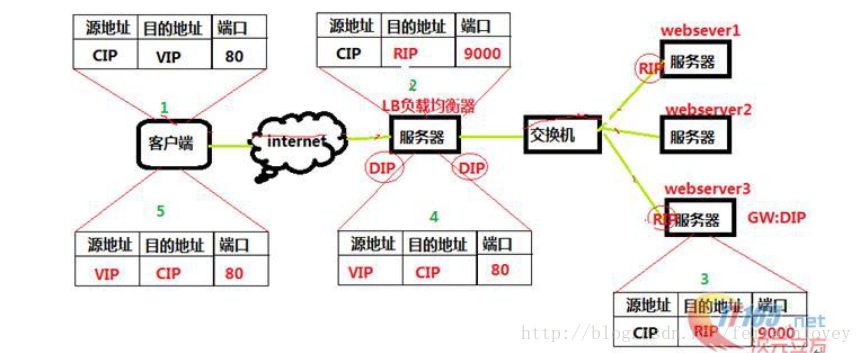
原理图简述:
- 客户端请求数据,目标IP为VIP
- 请求数据到达LB服务器,LB根据调度算法将目的地址修改为RIP地址及对应端口(此RIP地址是根据调度算法得出的。)并在连接HASH表中记录下这个连接。
- 数据包从LB服务器到达RS服务器webserver,然后webserver进行响应。Webserver的网关必须是LB,然后将数据返回给LB服务器。
- 收到RS的返回后的数据,根据连接HASH表修改源地址VIP&目标地址CIP,及对应端口80.然后数据就从LB出发到达客户端。
- 客户端收到的就只能看到VIP\DIP信息。
NAT模式优缺点:
- NAT技术将请求的报文和响应的报文都需要通过LB进行地址改写,因此网站访问量比较大的时候LB负载均衡调度器有比较大的瓶颈,一般要求最多之能10-20台节点
- 只需要在LB上配置一个公网IP地址就可以了。
- 每台内部的节点服务器的网关地址必须是调度器LB的内网地址。
- NAT模式支持对IP地址和端口进行转换。即用户请求的端口和真实服务器的端口可以不一致。
NAT模式的实现
Ipvsadm工具
管理集群服务
添加 -A -t|u|f service-address [-s scheduler]
-t: tcp协议集群
-u: udp协议集群
-f: 防火墙标记
修改 -E -D -t|u|f service-address
删除 -D
管理集群服务中的RS
添加 -a|e -t|u|f service-address -r server-address [options]
Options
-g:DR
-i:TUN
-m:NAT
修改 -e
删除 -d -t|u|f service-address -r server-address
查看
-Ln
--status 统计数据
--rate 速率
--time 显示超时时常
-c 显示当前的ipvs的连接数
-C 清空ipvs规则
-s
Ipvsadm -s >/path/to/somefile
-R
Ipvsadm -R>/path/form/somefileipvs原理(工作在内核,并且监控input链)
当一个TCP连接的初始SYN报文到达时,IPVS就选择一台服务器,将报文转发给它。此后通过查发报文的IP和TCP报文头地址,保证此连接的后继报文被转发到相同的服务器。这样,IPVS无法检查到请求的内容再选择服务器,这就要求后端的服务器组是提供相同的服务,不管请求被送到哪一台服务器,返回结果都应该是一样的。
IPVS是LVS的关键,因为LVS的IP负载平衡技术就是通过IPVS模块来实现的,IPVS是LVS集群系统的核心软件,它的主要作用 是:安装在Director Server上,同时在Director Server上虚拟出一个IP地址,用户必须通过这个虚拟的IP地址访问服务。这个虚拟IP一般称为LVS的VIP,即Virtual IP。访问的请求首先经过VIP到达负载调度器,然后由负载调度器从Real Server列表中选取一个服务节点响应用户的请求。
前提
Server1.example.com vip 172.16.100.1 DIP 172.25.254.1
Server2.example.com RIP1 172.25.254.2 Gateway:172.25.254.1
Server3.example.com RIP2 172.25.254.3 Gateway:172.25.254.1实践操作
[root@server1 ~]# yum install ipvsadm -y
[root@server1 ~]# ipvsadm -A -t 172.16.100.1:80 -s wrr
#添加一个虚拟IP为172.25.254.100的http服务(rr轮询如)
[root@server1 ~]# ipvsadm -a -t 172.16.100.1:80 -r 172.25.254.2 -m -w 1
[root@server1 ~]# ipvsadm -a -t 172.16.100.1:80 -r 172.25.254.3 -m -w 2
#r指的是添加真实服务器,-m指的是使用LVS-NAT模型,-w指定是权重,这里为1。
[root@server1 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.100.1:80 wrr
-> 172.25.254.2:80 Masq 1 0 0
-> 172.25.254.2:80 Masq 2 0 0
[root@server1 ~]# /etc/init.d/ipvsadm save
ipvsadm: Saving IPVS table to /etc/sysconfig/ipvsadm: [ OK ]
#在你的DS服务器上,开启主机转发。
[root@server1 ~]# vim /etc/sysctl.conf
net.ipv4.ip_forward = 1
[root@server1 ~]# ip addr add 172.16.100.1/24 dev eth0
#你还可以使用E/e修改尝试其他算法
[root@server1 ~]# ipvsadm -E -t 172.16.100.1:80 -s wrr
[root@server1 ~]# ipvsadm -e -t 172.16.100.1:80 -r 172.25.254.2 -m -w 2
[root@server1 ~]# ipvsadm -e -t 172.16.100.1:80 -r 172.25.254.3 -m -w 5TUN模式-隧道模式
virtual server via ip tunneling模式
采用NAT模式时,由于请求和响应的报文必须通过调度器地址重写,当客户请求越来越多时,调度器处理能力将成为瓶颈。为了解决这个问题,调度器把请求的报文通过IP隧道转发到真实的服务器。真实的服务器将响应处理后的数据直接返回给客户端。这样调度器就只处理请求入站报文,由于一 般网络服务应答数据比请求报文大很多,采用VS/TUN模式后,集群系统的最大吞吐量可以提高10倍。
VS/TUN的工作流程图如下所示,它和NAT模式不同的是,它在LB和RS之间的传输不用改写IP地址。而是把客户请求包封装在一个IP tunnel里面,然后发送给RS节点服务器,节点服务器接收到之后解开IP tunnel后,进行响应处理。并且直接把包通过自己的外网地址发送给客户不用经过LB服务器。
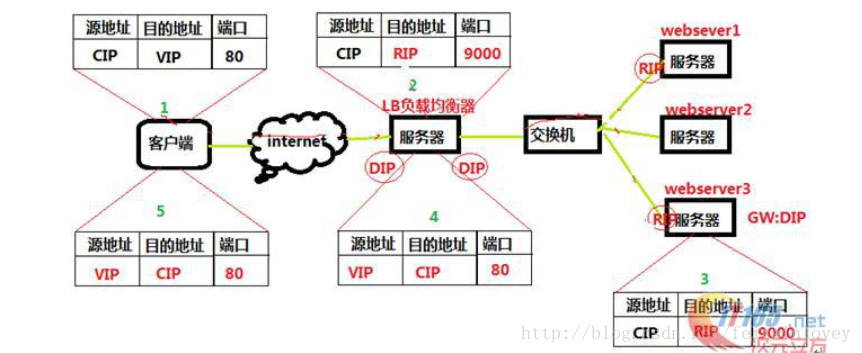
原理图简述:
- 客户请求数据包,目标地址VIP发送到LB上。
- LB接收到客户请求包,进行IP Tunnel封装。即在原有的包头加上IP Tunnel的包头。然后发送出去。
- RS节点服务器根据IP Tunnel包头信息(此时就又一种逻辑上的隐形隧道,只有LB和RS之间懂)收到请求包,然后解开IP Tunnel包头信息,得到客户的请求包并进行响应处理。
- 响应处理完毕之后,RS服务器使用自己的出公网的线路,将这个响应数据包发送给客户端。源IP地址还是VIP地址。(RS节点服务器需要在本地回环接口配置VIP,后续会讲)
TNU模式的实现
前提
Server1.example.com ip和vip分别为192.168.122.11和192.168.122.100
Server2.example.com ip和vip分别为192.168.122.22和192.168.122.100
Server3.example.com ip和vip分别为192.168.122.33和192.168.122.100TNU实践操作
#在DR服务器,也就是server1上作如下操作:
ipvsadm -A -t 192.168.122.100:80 -s rr
ipvsadm -a -t 192.168.122.100:80 -r 192.168.122.22
ipvsadm -a -t 192.168.122.100:80 -r 192.168.122.33
#在RS服务器上作如下操作(server2和server3),抑制RS主机响应
yum install -y arptables_jf
arptables -A IN -d 192.168.122.100 -j DROP
arptables -A OUT -s 192.168.122.100 -j mangle --mangle-ip-s 192.168.122.22
/etc/init.d/arptables_jf save
#这里也可以使用下面的方法
/proc/sys/net/ipv4/conf/这个下面的all和eth0同时设置才生效
Arp_ignore:定义接受到arp请求的响应级别(修改为1)
0:只要本地配置有相应的地址时,就给与相应
1:仅在请求的目标地址配置请求到达的接口上的时侯,才给与响应
Arp_announce: 定义将自己地址向外通告的级别(修改为2)
0:将本地任何接口的任何地址向外通告
1:试图仅向目标网络通告与其网络匹配的地址
2:仅与本地接口上地址匹配的网络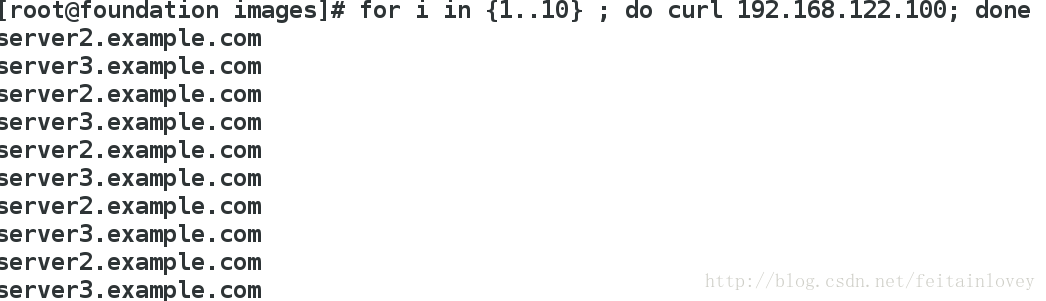
DR模式-直接路由模式
Virtual server via direct routing (vs/dr)
DR模式是通过改写请求报文的目标MAC地址,将请求发给真实服务器的,而真实服务器响应后的处理结果直接返回给客户端用户。同TUN模式一 样,DR模式可以极大的提高集群系统的伸缩性。而且DR模式没有IP隧道的开销,对集群中的真实服务器也没有必要必须支持IP隧道协议的要求。但是要求调 度器LB与真实服务器RS都有一块网卡连接到同一物理网段上,必须在同一个局域网环境。DR模式是互联网使用比较多的一种模式。
DR模式原理图:
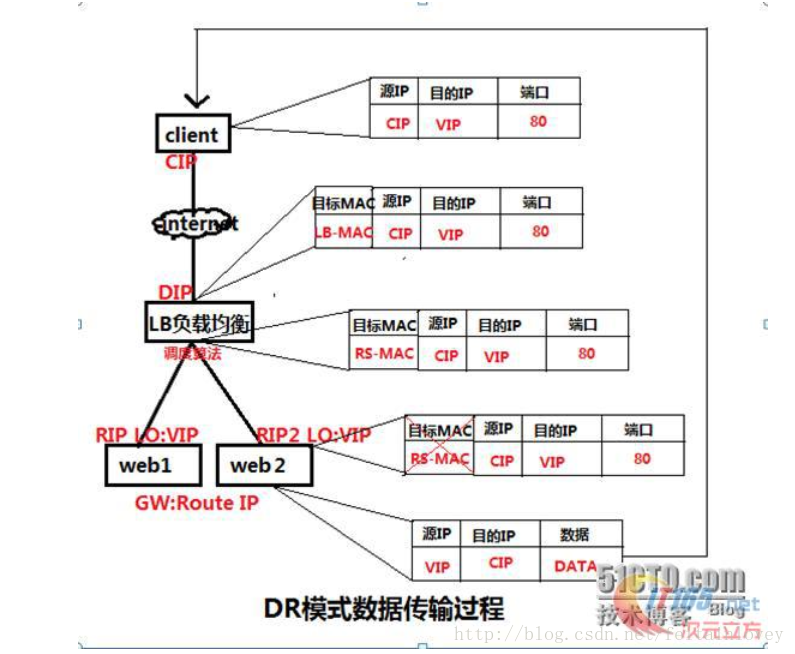
DR模式原理过程简述:
VS/DR模式的工作流程图如上图所示,它的连接调度和管理与NAT和TUN中的一样,它的报文转发方法和前两种不同。DR模式将报文直接路由给目 标真实服务器。在DR模式中,调度器根据各个真实服务器的负载情况,连接数多少等,动态地选择一台服务器,不修改目标IP地址和目标端口,也不封装IP报 文,而是将请求报文的数据帧的目标MAC地址改为真实服务器的MAC地址。然后再将修改的数据帧在服务器组的局域网上发送。因为数据帧的MAC地址是真实 服务器的MAC地址,并且又在同一个局域网。那么根据局域网的通讯原理,真实复位是一定能够收到由LB发出的数据包。真实服务器接收到请求数据包的时候, 解开IP包头查看到的目标IP是VIP。(此时只有自己的IP符合目标IP才会接收进来,所以我们需要在本地的回环借口上面配置VIP。另:由于网络接口都会进行ARP广播响应,但集群的其他机器都有这个VIP的lo接口,都响应就会冲突。所以我们需要把真实服务器的lo接口的ARP响应关闭掉,这里我们使用arptables)然后真实服务器做成请求响应,之后根据自己的路由信息将这个响应数据包发送回给客户,并且源IP地址还是VIP。
DR模式小结:
- 通过在调度器LB上修改数据包的目的MAC地址实现转发。注意源地址仍然是CIP,目的地址仍然是VIP地址。
- 请求的报文经过调度器,而RS响应处理后的报文无需经过调度器LB,因此并发访问量大时使用效率很高(和NAT模式比)
- 因为DR模式是通过MAC地址改写机制实现转发,因此所有RS节点和调度器LB只能在一个局域网里面
- RS主机需要绑定VIP地址在LO接口上,并且需要配置ARP抑制。
- RS节点的默认网关不需要配置成LB,而是直接配置为上级路由的网关,能让RS直接出网就可以。
- 由于DR模式的调度器仅做MAC地址的改写,所以调度器LB就不能改写目标端口,那么RS服务器就得使用和VIP相同的端口提供服务。
DR模式的实现
前提
DR server1 VIP 172.25.254.100 DIP 172.25.254.1
RS1 Server2 VIP 172.25.254.100 RIP 172.25.254.2
RS2 Server3 VIP 172.25.254.100 RIP 172.25.254.3DR实践操作
#在DS服务器上作如下操作
[root@server1 ~]# ipvsadm -A -t 172.25.254.100:80 -s rr
[root@server1 ~]# ipvsadm -a -t 172.25.254.100:80 -r 172.25.254.2:80 -g
[root@server1 ~]# ipvsadm -a -t 172.25.254.100:80 -r 172.25.254.3:80 -g
[root@server1 ~]# /etc/init.d/ipvsadm save
ipvsadm: Saving IPVS table to /etc/sysconfig/ipvsadm: [ OK ]
#为RS服务器添加VIP
[root@server1 ~]# ip addr add 172.25.254.100 dev eth0
#在两台RS服务器上作如下操(以server2为例)同样需要在两台RS服务器上作添加VIP的工作
[root@server2 ~]# ip addr add 172.25.254.100 dev eth0
#下来我们为了防止客户端直接访问到我们的RS服务器上,我们要设置ARP协议,禁止广播我们的vip地址
安装软件
[root@server2 ~]# yum install -y arptables_jf
[root@server2 ~]# arptables -A IN -d 172.25.254.100 -j DROP
[root@server2 ~]# arptables -A OUT -s 172.25.254.100 -j mangle --mangle-ip-s 172.25.254.2
[root@server2 ~]# /etc/init.d/arptables_jf save
Saving current rules to /etc/sysconfig/arptables: [ OK ]用ldirectord实现DS高可用
(注意这里server2和server3上同样需要vip和抑制vip向外广播自己的虚拟ip)
工作原理
ldirectord守护进程通过向每台真实服务器真实IP(RIP)上的集群资源发送访问请求来实现对真实服务器的监控,这对所有类型的LVS集 群都是成立的:LVS-DR,LVS-NAT和LVS-TUN。正常情况下,为每个Director上的VIP地址运行一个ldirectord守护进 程,当真实服务器不响应运行在Director上的ldirectord守护进程时,ldirectord守护进程运行适当的ipvsadm命令将VIP 地址从IPVS表中移除。(以后,当真实服务器回到在线状态时,ldirectord使用适当的ipvsadm命令将真实服务器重新添加到IPVS表中)
为了监视web集群内的真实服务器,ldirectord守护进程使用HTTP协议向每个真实服务器请求一个专用的web页面,如果真实服务器是健 康的,Director知道将从真实服务器接收到什么内容,如果从真实服务器返回应答字串或web页面的时间太长,或根本没有返回任何内容,或返回的内容 不是预期的Director就知道该真实服务器出错了,并从IPVS表中将这个真实服务器移除。
实践配置
[root@server1 mnt]# yum install ldirectord-3.9.5-3.1.x86_64.rpm -y
[root@server1 mnt]# rpm -ql ldirectord
/etc/ha.d
......
#这里我们可以清楚的看到,注配置文件都在/etc/ha.d/
#所以要将主配置文件考如/etc/ha.d/下
[root@server1 ha.d]# cp /usr/share/doc/ldirectord-3.9.5/ldirectord.cf /etc/ha.d/
#这时我们需要将刚才的策略清掉,这样让ldirectord在启动的时候自动写入
[root@server1 ha.d]# ipvsadm -C
[root@server1 ha.d]# ipvsadm -L
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
[root@server1 ha.d]# vim ldirectord.cf
25 virtual=172.25.254.100:80
26 real=172.25.254.2:80 gate
27 real=172.25.254.3:80 gate
28 fallback=127.0.0.1:80 gateldirectord.cf中一些参数的意思
- quiescent=no
当一个节点在checktimeout设置的时间周期内没有响应是它是“静止的”(它的权重为0),当你设置了这个选项 后,ldirectord将会从IPVS表中移除真实服务器而不是“停止”它,从IPVS表移除节点将中断现有的客户端连接,并使LVS丢掉所有的连接跟 踪记录和持续连接模板,如果你不将这个选项设置为no,当某个节点崩溃时,对某些客户端计算机而言可能会显示为集群关闭了,因为在这个节点崩溃前这些客户 端计算机被分配给它了,而连接跟踪记录和程序连接模板仍然保留在Director上。
使用这个选项时,你可能也想在系统启动时使用下面这个命令[18]:
echo 1 > /proc/sys/net/ipv4/vs/expire_nodest_conn
如果客户端使用一个先前的连接跟踪记录尝试与相同的服务器对话,但此时该服务器已经失效了,可以设置这个内核变量为1使连接跟踪记录立即失效 - checktimeout=20
这个值就是ldirectord等待健康检查执行完毕的等待时间,单位秒。如果因为某些原因检查失败或在设置的时间周期内没有完成检查,ldirectord将会从IPVS表中移除真实服务器[16]。 - checkinterval=5
这个值指定ldirectord在两个检查之间的间隔时间。 - autoreload=yes
如果启用这个选项,它使ldirectord按时计算这个配置文件的md5校验和值,看其是否有改动,当发现有改动时自动应用那些改动,这个方 便的特性运行你容易地改变集群的配置,你对配置文件改动后几秒,ldirectord将察觉到有改动,调用ipvsadm命令实现改动,从有效服务器池中 移除真实服务器或按需要将它们添加到池中。
注意:你也可以通过向ldirectoed守护进程发送HUP信号(使用kill命令)强制它重新载入,或运行ldirectord reload。 - checktype=negotiate
这个选项指出ldirectord守护进程使用什么方法监视真实服务器,checktype有以下这样一些值:
negotiate :
这个方法连接到真实服务器发送你指定的请求,如果在checktimeout周期内真实服务器都没有返回你指定的应答字符串,这个节点就被认为 已经死掉了,你可以在每个节点上指定请求和应答字符串,或在ldirectord配置文件中添加两行内容,为所有节点设置同样的请求和应答字符串:
request=”.healthcheck.html”receive=”OKAY”connect :
这个方法只是在checkport指定的端口上连接到真实服务器,并假设真实服务器一切都ok,只需要知道真实服务器的TCO/IP连接是通畅的,这个方法没有negotiate可靠,当没有negotiate检查可用时,使用这个方法显得有点用处。
A number :
如果在这里输入一个数字代替negotiate或connect ,ldirectord将会执行你指定的数字次数的连接测试,然后再执行一次negotiate 测试,这个方法减少了真实服务器应答健康检查的要求,同时也减少了集群网络通讯[
off :
禁用ldirectord监视真实服务器的健康。

使用heartbeat对后端检查
工作原理
通过修改配置文件,指定哪一台Heartbeat服务器作为主服务器,则另一台将自动成为备份服务器。然后在指定备份服务器上配置Heartbeat守护进程来监听来自主服务器的心跳。如果备份服务器在指定时间内未监听到来自主服务器的心跳,就会启动故障转移程序,并取得主服务器上的相关资源服务所有权,接替主服务器继续不间断的提供服务,从而达到资源服务高可用性的目的
Heartbeat消息类型
Heartbeat软件在工作过程中,一般来说,有三种消息类型
- 心跳消息
心跳消息为约150字节的数据包,可能为单播、广播或多播的方式,控制心跳频率及出现故障要等待多久进行故障转换 - 集群转换消息
ip-request和ip-request-resp
当主服务器恢复在线状态时,通过ip-request消息要求备机释放主服务器失败时备服务器取得的资源,然后备份服务器关闭释放主服务器失败时取得的资源及服务
备服务器释放主服务器失败时取得的资源及服务后,就会通过ip-request-resp消息通知主服务器它不在拥有该资源及服务,主服务器收到来自备节点的ip-request-resp消息通知后,启动失败时释放的资源及服务,并开始提供正常的访问服务 - 重传请求
Heartbeat IP地址接管和故障转移
Heartbeat是通过IP地址接管和ARP广播进行故障转移的
ARP广播:在主服务器故障时,备用节点接管资源后,会立即强制更新所有客户端本地的ARP表(即清除客户端本地缓存的失败服务器的vip地址和mac地址的解析记录)。确保客户端和新的主服务器对话。
ifconfig eth0:1 192.168.1.181 netmask 255.255.255.224 up (ip alias)
heartbeat软件默认是使用这个命令来添加VIP的
ip addr add 192.168.1.181/24 broadcast 192.168.1.255 dev eth1 (辅助ip)
keepalived软件默认使用这个命令来添加VIP
实践配置
#需要安装软件,在这里强调以下这两个安装包有依赖性,所以要一次性安装
#heartbeat-3.0.4-2.el6.x86_64.rpm heartbeat-libs-3.0.4-2.el6.x86_64.rpm
[root@server1 mnt]# yum install heartbeat-* -y
#同样我们要将配置文件写入到主配置文件目录下。
[root@server1 mnt]# cd /usr/share/doc/heartbeat-3.0.4/
[root@server1 heartbeat-3.0.4]# cp authkeys ha.cf haresources haresources /etc/ha.d- 配置ha.cf
#配置ha.cf
keepalive 2
#设定heartbeat之间的时间间隔为2秒。
udpport 694
#使用端口694进行bcast和ucast通信。这是默认的,并且在IANA官方注册的端口号。
warntime 10
#在日志中发出“late heartbeat“警告之前等待的时间,单位为秒。
deadtime 30
#在30秒后宣布节点死亡。
initdead 120
#在某些配置下,重启后网络需要一些时间才能正常工作。这个单独的”deadtime”选项可以处理这种情况。它的取值至少应该为通常deadtime的两倍;
bcast eth0
#表示在eth0接口上使用广播heartbeat(将eth1替换为eth0,eth2,或者您使用的任何接口)。
auto_failback on
#是否回切
node primary.mydomain.com
#该选项是必须配置的。集群中机器的主机名,与“uname –n”的输出相同。
ping 172.25.254.7
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster- 配置Authkeys
[root@server1 ha.d]# vim authkeys
[root@server1 ha.d]# chmod 600 authkeys
需要配置的第三个文件authkeys决定了您的认证密钥。共有三种认证方式:crc,md5,和sha1。您可能会问:
“我应该用哪个方法呢?”简而言之: 如果您的Heartbeat运行于安全网络之上,如本例中的交叉线,可以使用
crc,从资源的角度来看,这是代价最低的方法。如果网络并不安全,但您也希望降低CPU使用,则使用md5。最
后,如果您想得到最好的认证,而不考虑CPU使用情况,则使用sha1,它在三者之中最难破解。
文件格式如下:
auth <number>
<number> <authmethod> [<authkey>]
因此,对于sha1,示例的/etc/ha.d/authkeys可能是
auth 1
1 sha1 key-for-sha1-any-text-you-want
对于md5,只要将上面内容中的sha1换成md5就可以了。 对于crc,可作如下配置:
auth 2
2 crc
不论您在关键字auth后面指定的是什么索引值,在后面必须要作为键值再次出现。如果您指定“auth 4”,
则在后面一定要有一行的内容为“4 <signaturetype>”。
确保该文件的访问权限是安全的,如600。- 修改haresources
[root@server1 ha.d]# vim haresources
server1.example.com IPaddr::172.25.254.100/24/eth0 ldirectord httpd
[root@server1 ha.d]# chkconfig ldirectord off
[root@server1 ha.d]# /etc/init.d/ldirectord stop
Stopping ldirectord... success
[root@server1 ha.d]# ip addr del 172.25.254.100/24 dev eth0
#这时我们需要另外一个DS来分担我们一个DS的压力
#这时我们在需要一个server4,来作DS,同样server4需要安装heartbeat软件
[root@server4 mnt]# yum install heartbeat-3.0.4-2.el6.x86_64.rpm heartbeat-libs-3.0.4-2.el6.x86_64.rpm -y
[root@server1 ha.d]# scp ha.cf haresources authkeys root@172.25.254.4:/etc/ha.d/
#在server4上需要修改这个
[root@server4 ha.d]# vim haresources
Server4.example.com IPaddr::172.25.254.100/24/eth0 ldirectord httpd增加DRBD存储
DRBD介绍
Distributed Replicated Block Device(DRBD)是基于块设备在不同的高可用服务器对之间同步和镜像数据的软件,通过它可以实现在网络中的两台服务器之间基于块设备级别的实时或 异步镜像或同步复制,其实就是类似于rsync+inotify(sersync)这样的架构项目软件。只不过DRBD是基于文件系统底层的,即 block层级同步,而rsync是在文件系统之上的实际物理文件同步,因此DRBD效率更高、效果更好。相当于网络中的RAID1功能。
提示:上面提到的块设备可以是磁盘分区、LVM逻辑卷、或整块磁盘等,DRBD的同步不能基于目录
工作原理
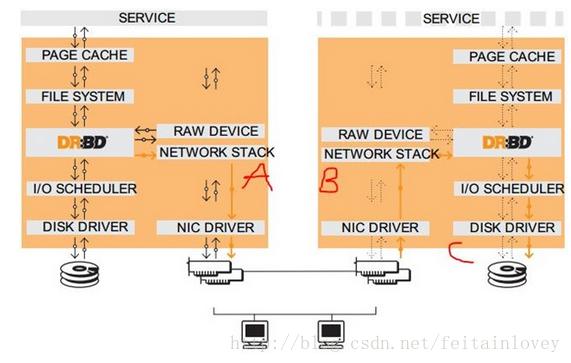
官方文档里给出的DRBD工作栈模型,可以看到DRBD需要运行在各个节点上,且是运行在节点主机的内核中,所以DRBD是内核模块,在Linux2.6.33版本起开始整合进内核。上图假设左节点为活动节点(实箭头),右节点为备用节点。左节点接收到数据发往内核的数据通路,DRBD在数据通路中注册钩子检查数据(类似ipvs), 当发现接收到的数据是发往到自己管理的存储位置,就复制另一份,一份存储到本机的DRBD存储设备,另一份就发给TCP/IP协议栈,通过网卡网络传输到 另一节点主机的网上TCP/IP协议栈;而另一节点运行的DRBD模块同样在数据通路上检查数据,当发现传输过来的数据时,就存储到DRBD存储设备对应 的位置。
如果左节点宕机,右节点可以在高可用集群中成为活动节点,当接收到数据先存储到本地,当左节点恢复上线时,再把宕机后右节点变动的数据镜像到左节点。镜像过程完成后还需要返回成功/失败的回应消息,这个回应消息可以在传输过程中的不同位置返回,如图上的A/B/C标识位置,可以分为三种复制模式:
A:Async, 异步,本地写成功后立即返回,数据放在发送buffer中,可能丢失,但传输性能好;
B:semi sync, 半同步;
C:sync, 同步,本地和对方写成功确认后返回,数据可靠性高,一般都用这种;
- 详细介绍3种模式协议
q 协议A<异步>
即异步复制协议。当本地磁盘写入完成,并且拷贝数据包进入本地TCP发送缓冲区里后,就认为在主节点的本地写操作完成。这种模式,在发生强制故障转 移的时候可能发生数据丢失的现象。协议A常用在长距离复制环境中。当它和DRBD代理结合使用的时候,它成为一个有效的灾难恢复解决方案。
q 协议B<异步>
即内存同步(半同步)复制协议。当本地磁盘写入发生,并且拷贝数据包到达对等层节点时,就认为在主节点中的本地写操作完成。正常情况下,在故障转移 事件中,写入的数据不会丢失。然而,如果节点同时停电,主节点的数据存储将发生不可逆的损坏,大部分最近在主节点中写入完成的数据可能会丢失。
q 协议C<实时>
即实时同步复制协议。只有当本地磁盘和远程磁盘都确认写入完成时,就认为在主节点的本地写操作完成。结果,即使一个节点崩溃,也不会丢失任何数据。唯一丢失数据的可能是两个节点同时崩溃。
到目前为止,协议C是安装DRBD是最常使用的复制协议。选择协议将影响流量,从而影响网络延时
对于使用A、B协议要考虑丢失数据的风险,当数据写在缓冲区里面,没有真正写在磁盘上,系统崩溃会导致数据丢失,有些带电池的硬盘控制器,不但自带 电池而且自带缓存,会在系统意外断电或崩溃后将最后的数据写入磁盘,这类控制器一般使用disk flush,从而保证性能的前提下提高数据安全性。
实践操作
[root@server1 mnt]# yum install rpm-build -y
[root@server1 mnt]# tar -zxf drbd-8.4.3.tar.gz
[root@server1 drbd-8.4.3]# ./configure --with-km --enable-spec
#注意需要很多依赖包,这里很多就不列出来了,你需要一个一个的安装,提示安装什么就安装什么.
[root@server1 drbd-8.4.3]# rpmbuild -bb drbd.spec #编译生成 drbd rpm 包
[root@server1 drbd-8.4.3]# rpmbuild -bb drbd-km.spec #编译 drbd 内核模块
#将制作好的rpm包scp到server4上
[root@server1 x86_64]# rpm -ivh *
[root@server1 x86_64]# scp * root@172.25.254.4:/tools
[root@server4 tools]# rpm -ivh *
#然后给serer1和server4在给4G的虚拟硬盘
[root@server1 x86_64]# cat /etc/drbd.conf
include "drbd.d/global_common.conf";
include "drbd.d/*.res";
#可以看到这里在/debb.d目录下有俩个文件,所以我们要创建他
resource demo{
meta-disk internal;
device /dev/drbd1;
syncer {
verify-alg sha1;
}
on server1 {
disk /dev/vdb;
address 172.25.254.1:7789;
}
on server{
disk /dev/vdb;
address 172.25.254.4:7789;
}
}
[root@server1 drbd.d]# scp demo.res root@172.25.254.4:/etc/drbd.d/
#Server1和server4都需要执行如下命令
[root@server1 drbd.d]# drbdadm create-md demo
[root@server1 drbd.d]# /etc/init.d/drbd start
#将 demo 设置为 primary 节点,并同步数据:(在 demo 主机server1行以下命令)
[root@server1 drbd.d]# drbdsetup /dev/drbd1 primary --force
#格式化:
[root@server1 drbd.d]# mkfs.ext4 /dev/drbd1
[root@server1 drbd.d]# mount /dev/drbd1 /mnt
#将server4设置成secondary 节点:
drbdadm secondary demo注意:两台主机上的/dev/drbd1 不能同时挂载,只有状态为 primary 时,才能被挂载使用,而此时另一方的状态为 secondary
接下来我们安装mysql用来存储数据
安装软件[root@server1 drbd.d]# yum install mysql-server
[root@server1 mnt]# cd /var/lib/mysql/
[root@server1 mysql]# cp -r * /mnt/
[root@server1 mnt]# chmod -R mysql.mysql
[root@server1 /]# /etc/init.d/mysqld start
[root@server1 /]# /etc/init.d/mysqld stop
[root@server1 /]# umount /mnt
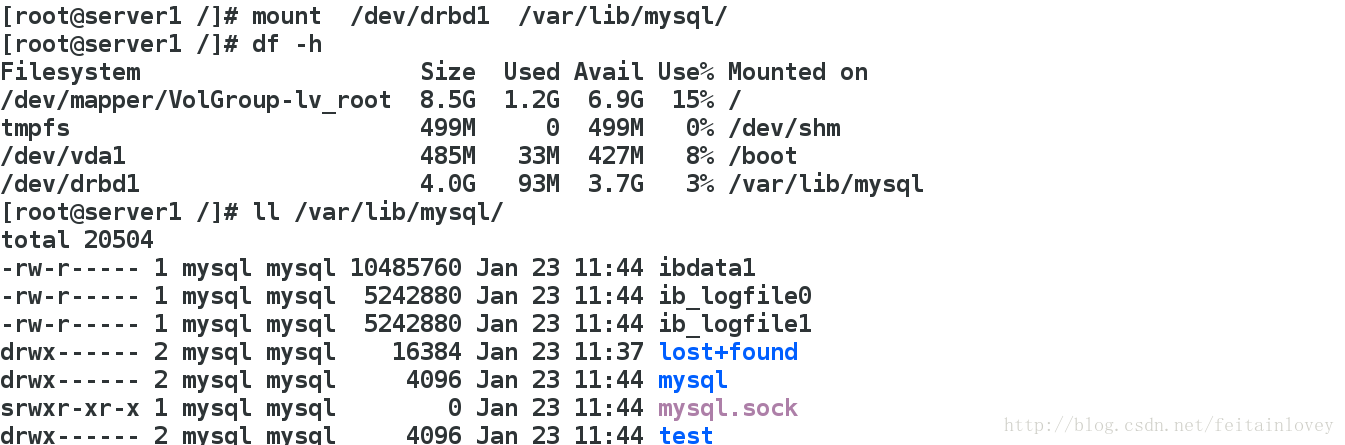
注意:这时如果启动mysql 报错Another MySQL daemon already running with the same unix socket,需要删掉msyql.sock文件。
[root@server1 mysql]# rm -rf mysql.sock
[root@server1 mysql]# /etc/init.d/mysqld start
Starting mysqld:
用高可用lvs+heartbeat+ldirectord测试
停掉mysql,卸载上面挂载在/var/lib/mysql上面的/dev/drbd1,最后停掉heartbeat,这里注意,但是drbd服务必须手动启动。
[root@server1 x86_64]# rpm -qlp drbd-heartbeat-8.4.3-2.el6.x86_64.rpm
/etc/ha.d/resource.d/drbddisk
/etc/ha.d/resource.d/drbdupper
/usr/share/man/man8/drbddisk.8.gz
[root@server1 resource.d]# cd /etc/ha.d/resource.d/
[root@server1 resource.d]# vim haresources
server1 IPaddr::172.25.254.100/24/eth0 drbddisk::demo Filesystem::/dev/drbd1::/var/lib/mysql::ext4 mysqld
[root@server4 resource.d]# vim haresources
server4 IPaddr::172.25.254.100/24/eth0 drbddisk::demo Filesystem::/dev/drbd1::/var/lib/mysql::ext4 mysqld














 1053
1053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









