







 本课程深入讲解了神经网络的运作原理,包括随机梯度下降法如何帮助逃离局部最优解,以及神经网络模型的构建。通过反向传播算法,探讨了神经网络的学习和优化过程,为后续的深度学习理论奠定了基础。
本课程深入讲解了神经网络的运作原理,包括随机梯度下降法如何帮助逃离局部最优解,以及神经网络模型的构建。通过反向传播算法,探讨了神经网络的学习和优化过程,为后续的深度学习理论奠定了基础。
课程简介:
本节课主要介绍人工神经网络.通过介绍评定模型,随机梯度下降法,生物启发和感知器系统,讲师用视图和数学解析式详细地讲解了神经网络的运行过程以及原理.
课程大纲:
1、Stochastic Gradient Descent ( 随机梯度下降法 )
2、Neural Network Model ( 神经网络模型 )
3、Backpropagation Algorithm ( 反向传播算法 )
4、Summarize
1、Stochastic Gradient Descent
在上一节课里,我们利用梯度下降法找到最优的方向,然后向该方向移动一小步,但是很有可能会导致陷入一个差的局部最优解,而且每次移动都要计算全部的点,因此计算量大。那如果每次移动只看一个点,根据当前的点找到最优的方向进行移动,当所有的点都被选择后,理论上总的移动方向是跟之前的方法一致的,因为数学期望是相等的。但是利用随机的选取一个点,却有可能让我们逃脱非常差的局部最优点的陷阱,当然无法逃脱全部的陷阱。那是因为当你随便选取一点的时候,它的方向并不一定就是最优化的那个方向,因此下一步有可能移动到高点去,然后在新的位置重新寻找出路,这样就有更大的可能性获得较好的局部最优点。考虑下面的图片,在左图中,当我们第一次选择的初始化位置是第一个黑点的时候,那么根据整体梯度下降法,就会陷入那个非常糟糕的局部嘴有点去了。然而如果我们选择的是随机梯度下降法,就有可能因为某个点的方向是偏离最优点的而使得前进的方向是想着右边的,这样就可以跳过该陷阱了。由图中,根据整体梯度下降法,当遇到平缓区域的时候,该方法就会认为找到最优点了,就会停滞不前。而随机梯度下降法却由于不同点的方向不一致从而推动了算法继续向前移动,于是我们再次逃脱了该陷阱了。
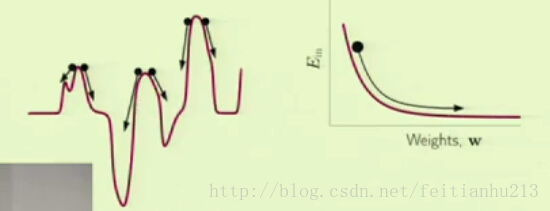
应用随机梯度下降法有如下好处:
1、计算代价小,因为每次只选取一个点进行计算
2、随机性有助于逃脱局部最小点,找到较好的最小点
3、简单,因为每次只选取一个点进行计算
2、Neural Network Model ( 神经网络模型 )
在学习感知器模型的时候我们知道当输入数据点超过三个的时候,最坏情况下我们没办法把所有的点全部正确分类,即 dVC = 3。然而如果利用两个感知器模型进行分类,然后再综合这两个模型的结果得到最总的结果,我们就有办法把所有的 4 个点全部分类,如下图:

对于更多的点,我们可以利用更多的模型进行分类。通过综合不同模型的结果,就有可能通过感知器模型找到最优的解(权重)。
利用以下图形进行直观的解释:

上图中共有第一列是输入,后面三列表示三层模型,共 5 个感知器模型(每个圆圈表示一个感知器模型,也叫一个神经元或节点)。最后的感知器输出的就是最终的结果。
每一条线上都有一些数值,这些便是我们需要学习的权重(参数),开始的时候是未知的。上述模型其实就是一个神经网络。
理论上通过这些感知器的排列组合(任意个),可以产生任何输出。
定义:
神经网络的模型是通过组合不同的简单模型而得到的一个综合的模型,组合方式如下图所示:

其中第一列是输入数据,最右边的是输出,剩下的是隐藏层,该网络的层次 L = 3.
每条线表示一个权值,需要学习确定,而每个 θ 表示一个模型(任何模型,可以互不相等),每条线所属的层次跟其所指向的模型所在的层次相同.
下一层模型的输入是上一层模型的输出乘上对应的权值(所在的线的值)。
为了方便对神经网路进行讨论,这里假定每个模型的 θ(s) = (1-e^s)/(1+e^s), 处理的数据是二分类。此外,定义如下符号:

w是我们需要学习的参数,对应图中的线,上标 l 表示当前的 w 属于第 l 层,下标表示该线出发的节点位置。j 表示该线指向的节点位置。值得注意的是 i 的取值范围,之所以能够去得到 i 是因为存在常数项: x0
于是我们有:

其中 x 表示输出,s 表示输入。
当 l = 0 的时候表示的是原始的数据,这时候 0 < j < d + 1
对 x 的求解是一个递归的过程,先求出第 1 层,再求第二层...直到最终输出。
该模型要解决如下两大难题:
1、generalization:众多的模型、参数、权重等导致自由度很大,正如在误差偏差分析里面所讲到的,假设集大会增大找到最优函数的难度。
2、optimization:应该如何进行学习才能把这么多参数学好?
第三部分将设法解决上述问题。
3、Backpropagation Algorithm ( 反向传播算法 )
这一部分基本是数学分析,看得有点晕,理解的也不是很好,只能是不断地截图了...
利用随机梯度下降法,每次只关注一个点。因此我们需要找出 Ein(W) 关于每一个数据的偏微分:▽e(W)。其中 e(W) = (h(xn),yn)。方便起见,令 e(W) = ( h(xn) - yn)^2(理论上可以用一切有效的误差度量函数)。
有 

因为 Sj(l) = Xi(l-1) * Wij(l) 所以(注:这里的 (l) 表示的是上标为 l ):令 

当 l = 1 的时候 Xi(l) 表示的是原始输入的数据,因此我们可以递归的求得上述等式右边的第二项,只要我们能够求出第一项就可以对 w 进行学习了。
为了求出第一项,先从最后一层开始,因为最后一层距离整个算法的输出最接近,且 θ(S1(L)) 就是 X1(L),( 注:其中 L 是上标 ),有:

当最后一层求出后,便可以递归的求出前面的值了。如下:( 之所以要求和是因为位于 l-1 层的节点受到 l 层的所有节点的反馈)


下面是伪代码:

总结:
第一部分承接了上一节课,介绍了一种更好的梯度测量方法,也为神经网络参数学习打下了基础。第二部分主要是介绍神经网络的基本概念及作用。最后一部分是基于数学的分析,从而把神经网络模型转换到计算机可以处理的层面,因此最后一部分是理论联系实际。















 1813
1813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









