







01 链表
| 编号 | 题目 | 思路 | 难度 | 频率 |
|---|---|---|---|---|
| BM1 | 反转链表 | 思路 | 简单 | 38.85% |
| BM2 | 链表内指定区间反转 | 思路 | 中等 | 27.57% |
| BM3 | 链表中的节点每k个一组翻转 | 思路 | 中等 | 36.39% |
| BM4 | 合并两个排序的链表 | 思路 | 简单 | 31.88% |
| BM5 | 合并k个已排序的链表 | 思路 | 较难 | 33.12% |
| BM6 | 判断链表中是否有环 | 思路 | 简单 | 36.46% |
| BM7 | 链表中环的入口结点 | 思路 | 中等 | 35.85% |
| BM8 | 链表中倒数最后k个结点 | 思路 | 简单 | 32.64% |
| BM9 | 删除链表的倒数第n个节点 | 思路 | 中等 | 36.01% |
| BM10 | 两个链表的第一个公共结点 | 思路 | 简单 | 37.17% |
| BM11 | 链表相加(二) | 思路 | 中等 | 33.91% |
| BM12 | 单链表的排序 | 思路 | 中等 | 45.40% |
| BM13 | 判断一个链表是否为回文结构 | 思路 | 简单 | 31.83% |
| BM14 | 链表的奇偶重排 | 思路 | 中等 | 43.05% |
| BM15 | 删除有序链表中重复的元素-I | 思路 | 简单 | 36.82% |
| BM16 | 删除有序链表中重复的元素-II | 思路 | 中等 | 32.01% |
02 二分查找/排序
| 编号 | 题目 | 思路 | 难度 | 频率 |
|---|---|---|---|---|
| BM17 | 二分查找-I | 思路 | 简单 | 29.19% |
| BM18 | 二维数组中的查找 | 思路 | 中等 | 26.24% |
| BM19 | 寻找峰值 | 思路 | 中等 | 27.01% |
| BM20 | 数组中的逆序对 | 思路 | 中等 | 17.02% |
| BM21 | 旋转数组的最小数字 | 思路 | 简单 | 33.39% |
| BM22 | 比较版本号 | 思路 | 中等 | 26.80% |
03 二叉树
| 编号 | 题目 | 思路 | 难度 | 频率 |
|---|---|---|---|---|
| BM23 | 二叉树的前序遍历 | 思路 | 简单 | 51.63% |
| BM24 | 二叉树的中序遍历 | 思路 | 中等 | 54.38% |
| BM25 | 二叉树的后序遍历 | 思路 | 简单 | 64.33% |
| BM26 | 求二叉树的层序遍历 | 思路 | 中等 | 45.52% |
| BM27 | 按之字形顺序打印二叉树 | 思路 | 中等 | 28.57% |
| BM28 | 二叉树的最大深度 | 思路 | 简单 | 60.03% |
| BM29 | 二叉树中和为某一值的路径(一) | 思路 | 简单 | 36.83% |
| BM30 | 二叉搜索树与双向链表 | 思路 | 中等 | 31.35% |
| BM31 | 对称的二叉树 | 思路 | 简单 | 32.52% |
| BM32 | 合并二叉树 | 思路 | 简单 | 68.61% |
| BM33 | 二叉树的镜像 | 思路 | 简单 | 65.30% |
| BM34 | 判断是不是二叉搜索树 | 思路 | 中等 | 27.23% |
| BM35 | 判断是不是完全二叉树 | 思路 | 中等 | 31.66% |
| BM36 | 判断是不是平衡二叉树 | 思路 | 简单 | 38.46% |
| BM37 | 二叉搜索树的最近公共祖先 | 思路 | 简单 | 42.44% |
| BM38 | 在二叉树中找到两个节点的最近公共祖先 | 思路 | 中等 | 42.20% |
| BM39 | 序列化二叉树 | 思路 | 较难 | 24.74% |
| BM40 | 重建二叉树 | 思路 | 中等 | 27.60% |
| BM41 | 输出二叉树的右视图 | 思路 | 中等 | 53.88% |
04 堆/栈/队列
| 编号 | 题目 | 思路 | 难度 | 频率 |
|---|---|---|---|---|
| BM42 | 用两个栈实现队列 | 思路 | 简单 | 41.27% |
| BM43 | 包含min函数的栈 | 思路 | 简单 | 34.79% |
| BM44 | 有效括号序列 | 思路 | 简单 | 30.83% |
| BM45 | 滑动窗口的最大值 | 思路 | 较难 | 26.96% |
| BM46 | 最小的K个数 | 思路 | 中等 | 27.59% |
| BM47 | 寻找第K大 | 思路 | 中等 | 27.86% |
| BM48 | 数据流中的中位数 | 思路 | 中等 | 29.35% |
| BM49 | 表达式求值 | 思路 | 中等 | 38.99% |
05 哈希
| 编号 | 题目 | 思路 | 难度 | 频率 |
|---|---|---|---|---|
| BM50 | 两数之和 | 思路 | 简单 | 34.76% |
| BM51 | 数组中出现次数超过一半的数字 | 思路 | 简单 | 32.74% |
| BM52 | 数组中只出现一次的两个数字 | 思路 | 中等 | 52.17% |
| BM53 | 缺失的第一个正整数 | 思路 | 中等 | 33.63% |
| BM54 | 三数之和 | 思路 | 中等 | 22.65% |
06 递归/回溯
| 编号 | 题目 | 思路 | 难度 | 频率 |
|---|---|---|---|---|
| BM55 | 没有重复项数字的全排列 | 思路 | 中等 | 53.80% |
| BM56 | 有重复项数字的全排列 | 思路 | 中等 | 35.77% |
| BM57 | 岛屿数量 | 思路 | 中等 | 38.95% |
| BM58 | 字符串的排列 | 思路 | 中等 | 23.33% |
| BM59 | N皇后问题 | 思路 | 较难 | 41.68% |
| BM60 | 括号生成 | 思路 | 中等 | 51.69% |
| BM61 | 矩阵最长递增路径 | 思路 | 中等 | 32.31% |
07 动态规划
| 编号 | 题目 | 思路 | 难度 | 频率 |
|---|---|---|---|---|
| BM62 | 斐波那契数列 | 思路 | 入门 | 36.47% |
| BM63 | 跳台阶 | 思路 | 简单 | 40.26% |
| BM64 | 最小花费爬楼梯 | 思路 | 简单 | 41.86% |
| BM65 | 最长公共子序列(二) | 思路 | 中等 | 32.29% |
| BM66 | 最长公共子串 | 思路 | 中等 | 32.84% |
| BM67 | 不同路径的数目(一) | 思路 | 简单 | 44.18% |
| BM68 | 矩阵的最小路径和 | 思路 | 中等 | 48.13% |
| BM69 | 把数字翻译成字符串 | 思路 | 中等 | 17.15% |
| BM70 | 兑换零钱(一) | 思路 | 中等 | 34.76% |
| BM71 | 最长上升子序列(一) | 思路 | 中等 | 25.39% |
| BM72 | 连续子数组的最大和 | 思路 | 简单 | 39.42% |
| BM73 | 最长回文子串 | 思路 | 中等 | 36.05% |
| BM74 | 数字字符串转化成IP地址 | 思路 | 中等 | 34.49% |
| BM75 | 编辑距离(一) | 思路 | 较难 | 42.05% |
| BM76 | 正则表达式匹配 | 思路 | 较难 | 27.07% |
| BM77 | 最长的括号子串 | 思路 | 较难 | 24.68% |
| BM78 | 打家劫舍(一) | 思路 | 中等 | 36.16% |
| BM79 | 打家劫舍(二) | 思路 | 中等 | 37.77% |
| BM80 | 买卖股票的最好时机(一) | 思路 | 简单 | 51.93% |
| BM81 | 买卖股票的最好时机(二) | 思路 | 中等 | 61.25% |
| BM82 | 买卖股票的最好时机(三) | 思路 | 较难 | 42.26% |
08 字符串
| 编号 | 题目 | 思路 | 难度 | 频率 |
|---|---|---|---|---|
| BM83 | 字符串变形 | 思路 | 简单 | 22.33% |
| BM84 | 最长公共前缀 | 思路 | 简单 | 31.48% |
| BM85 | 验证IP地址 | 思路 | 中等 | 19.66% |
| BM86 | 大数加法 | 思路 | 中等 | 39.35% |
09 双指针
| 编号 | 题目 | 思路 | 难度 | 频率 |
|---|---|---|---|---|
| BM87 | 合并两个有序的数组 | 思路 | 简单 | 35.80% |
| BM88 | 判断是否为回文字符串 | 思路 | 入门 | 59.27% |
| BM89 | 合并区间 | 思路 | 中等 | 26.98% |
| BM90 | 最小覆盖子串 | 思路 | 较难 | 26.72% |
| BM91 | 反转字符串 | 思路 | 入门 | 65.44% |
| BM92 | 最长无重复子数组 | 思路 | 中等 | 30.55% |
| BM93 | 盛水最多的容器 | 思路 | 中等 | 39.59% |
| BM94 | 接雨水问题 | 思路 | 较难 | 39.94% |
010 贪心算法
| 编号 | 题目 | 思路 | 难度 | 频率 |
|---|---|---|---|---|
| BM95 | 分糖果问题 | 思路 | 较难 | 22.93% |
| BM96 | 主持人调度(二) | 思路 | 中等 | 22.87% |
11 模拟
| 编号 | 题目 | 思路 | 难度 | 频率 |
|---|---|---|---|---|
| BM97 | 旋转数组 | 思路 | 中等 | 42.30% |
| BM98 | 螺旋矩阵 | 思路 | 简单 | 27.46% |
| BM99 | 顺时针旋转矩阵 | 思路 | 中等 | 51.14% |
| BM100 | 设计LRU缓存结构 | 思路 | 较难 | 41.36% |
| BM101 | 设计LFU缓存结构 | 思路 | 较难 | 30.80% |
反转链表
(1)使用栈解法:
import java.util.Stack;
public class Solution {
public ListNode ReverseList(ListNode head) {
Stack<ListNode> stack= new Stack<>();
//把链表节点全部摘掉放到栈中
while (head != null) {
stack.push(head);
head = head.next;
}
if (stack.isEmpty())
return null;
ListNode node = stack.pop();
ListNode dummy = node;
//栈中的结点全部出栈,然后重新连成一个新的链表
while (!stack.isEmpty()) {
ListNode tempNode = stack.pop();
node.next = tempNode;
node = node.next;
}
//最后一个结点就是反转前的头结点,一定要让他的next
//等于空,否则会构成环
node.next = null;
return dummy;
}
}
(2)双链表解法:

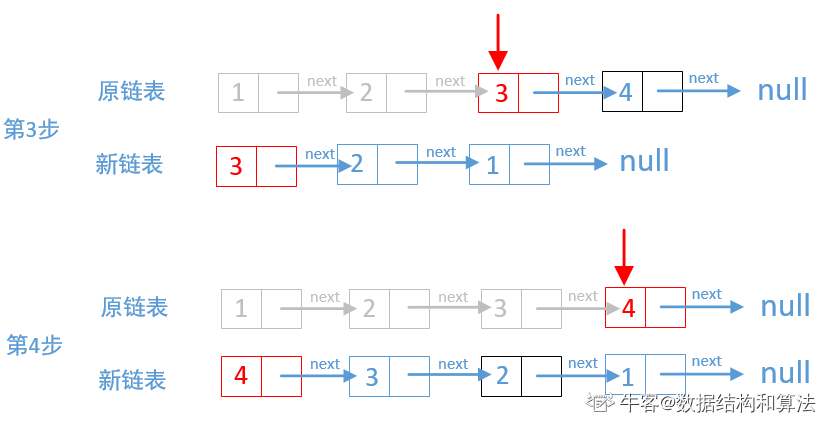
public ListNode ReverseList(ListNode head) {
//新链表
ListNode newHead = null;
while (head != null) {
//先保存访问的节点的下一个节点,保存起来
//留着下一步访问的
ListNode temp = head.next;
//每次访问的原链表节点都会成为新链表的头结点,
//其实就是把新链表挂到访问的原链表节点的
//后面就行了
head.next = newHead;
//更新新链表
newHead = head;
//重新赋值,继续访问
head = temp;
}
//返回新链表
return newHead;
}
(3)双指针解法:





public class Solution {
public ListNode ReverseList(ListNode head) {
if(head == null){
return null;
}
ListNode p1 = null;
ListNode p2 = head;
ListNode p3 = head.next;
while(p2 != null){
p2.next = p1;
p1 = p2;
p2 = p3;
if(p3 != null){
p3 = p3.next;
}
}
return p1;
}
}
链表内指定区间反转
(1)递归解法:
import java.util.*;
public class Solution {
ListNode temp = null;
public ListNode reverse(ListNode head, int n){
//只颠倒第一个节点,后续不管
if(n == 1){
temp = head.next;
return head;
}
//进入子问题
ListNode node = reverse(head.next, n - 1);
//反转
head.next.next = head;
//每个子问题反转后的尾拼接第n个位置后的节点
head.next = temp;
return node;
}
public ListNode reverseBetween (ListNode head, int m, int n) {
//从第一个节点开始
if(m == 1) return reverse(head, n);
//缩减子问题
ListNode node = reverseBetween(head.next, m - 1, n - 1);
//拼接已翻转
head.next = node;
return head;
}
}
(2)头插法迭代:
import java.util.*;
public class Solution {
public ListNode reverseBetween (ListNode head, int m, int n) {
//加个表头
ListNode res = new ListNode(-1);
res.next = head;
//前序节点
ListNode pre = res;
//当前节点
ListNode cur = head;
//找到m
for(int i = 1; i < m; i++){
pre = cur;
cur = cur.next;
}
//从m反转到n
ListNode temp = null;
for(int i = m; i < n; i++){
temp = cur.next;
cur.next = temp.next;
temp.next = pre.next;
pre.next = temp;
}
//返回去掉表头
return res.next;
}
}
排序
(1)冒泡排序
(2)快速排序
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
* 将给定数组排序
* @param arr int整型一维数组 待排序的数组
* @return int整型一维数组
*/
public int[] MySort (int[] arr) {
quickSort(arr , 0 , arr.length-1);
return arr;
}
public void quickSort(int[] list, int left, int right) {
if (left < right) {
// 分割数组,找到分割点
int point = partition(list, left, right);
// 递归调用,对左子数组进行快速排序
quickSort(list, left, point - 1);
// 递归调用,对右子数组进行快速排序
quickSort(list, point + 1, right);
}
}
/**
* 分割数组,找到分割点
*/
public int partition(int[] list, int left, int right) {
// 用数组的第一个元素作为基准数
int first = list[left];
while (left < right) {
while (left < right && list[right] >= first) {
right--;
}
// 交换
swap(list, left, right);
while (left < right && list[left] <= first) {
left++;
}
// 交换
swap(list, left, right);
}
// 返回分割点所在的位置
return left;
}
private void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
(3)归并排序MergeSort
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
* 将给定数组排序
* @param arr int整型一维数组 待排序的数组
* @return int整型一维数组
*/
public int[] MySort (int[] arr) {
mergeSort(arr,0,arr.length-1);
return arr;
}
public void mergeSort(int[] arr,int l,int r){
if(l==r){
return;
}
int mid = l+((r-l)>>1); //中点位置,即(l+r)/2
mergeSort(arr,l,mid);
mergeSort(arr,mid+1,r);
merge(arr,l,mid,r);
}
public void merge(int[] arr,int l,int mid,int r){
int [] help= new int[r-l+1]; //辅助数组
int i=0;
int p1=l; //左半数组的下标
int p2=mid+1; //右半数组的下标
//判断是否越界
while(p1<=mid && p2<=r){
help[i++]=arr[p1]<arr[p2] ? arr[p1++] : arr[p2++];
}
//p1没有越界,说明p2越界了,将左边剩余元素拷贝到辅助数组
while(p1<=mid){
help[i++]=arr[p1++];
}
//p2没有越界,说明p1越界了
while(p2<=r){
help[i++]=arr[p2++];
}
//将辅助数组元素拷贝会原数组
for(i=0;i<help.length;i++){
arr[l+i]=help[i];
}
}
}
(4)堆排序

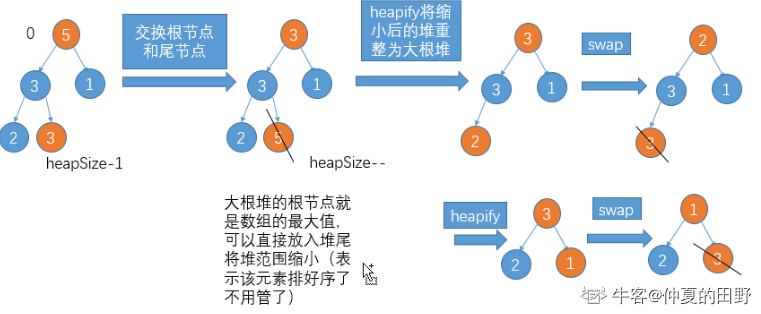
public int[] MySort (int[] arr) {
heapSort(arr);
return arr;
}
public static void heapSort(int[] arr){
if(arr == null || arr.length<2){
return;
}
for(int i=0;i<arr.length;i++){
heapInsert(arr,i); //构造完全二叉树
}
int size = arr.length;
swap(arr,0,--size);
while(size>0){
heapify(arr,0,size);// 最后一个数与根交换
swap(arr,0,--size);
}
}
//判断该结点与父结点的大小,大结点一直往,建立大根堆
public static void heapInsert(int[] arr,int index){
while(arr[index]>arr[(index-1)/2]){
swap(arr,index,(index-1)/2);
index=(index-1)/2;
}
}
//一个值变小往下沉的过程
public static void heapify(int[] arr,int index,int size){
int left=index*2+1;
while(left<size){
int largest = left + 1 < size && arr[left+1] > arr[left] ? left+1 : left;
largest = arr[largest] > arr[index] ? largest :index;
if(largest==index){
break;
}
swap(arr,largest,index);
index=largest;
left=index*2 +1;
}
}
//交换函数
public static void swap(int[] arr, int i, int j){
int tmp;
tmp=arr[i];
arr[i]=arr[j];
arr[j]=tmp;
}
(5)优先队列
-
优先队列不再遵循先入先出的原则,而是分为两种情况:
-
最大优先队列,无论入队顺序,当前最大的元素优先出队;
-
最小优先队列,无论入队顺序,当前最小的元素优先出队;
-
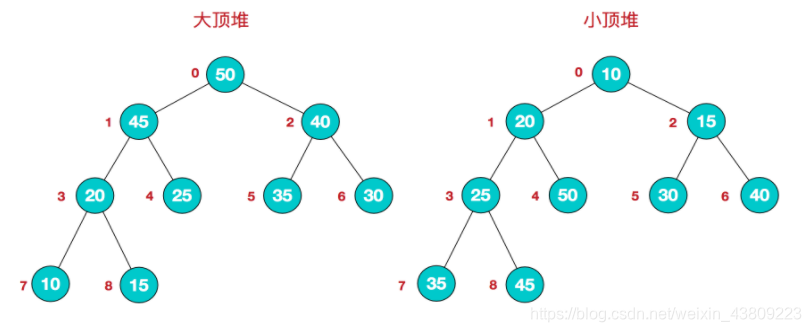
优先级队列,也叫二叉堆、堆(不要和内存中的堆区搞混了,一个是内存区域,一个是数据结构)。
堆的本质上是一种完全二叉树,分为: -
小根堆:树中每个非叶子结点都不大于其左右孩子结点的值,也就是根节点最小的堆,图a
-
大根堆:树中每个非叶子结点都不小于其左右孩子结点的值,也就是根节点最大的堆,图b

public int[] MySort (int[] arr) {
PriorityQueue<Integer> queue=new PriorityQueue<>(new Comparator<Integer>(){
public int compare(Integer a,Integer b){
return a.compareTo(b);
}
});
for(int i=0;i<arr.length;i++){
queue.offer(arr[i]);
}
int[] newarr=new int[arr.length];
for(int i=0;i<arr.length;i++){
newarr[i]=queue.poll();
}
return newarr;
}
设计LRU缓存结构
(1)解法1import java.util.*;
public class Solution {
private Map<Integer, Node> map = new HashMap<>();
private Node head = new Node(-1,-1);
private Node tail = new Node(-1,-1);
private int k;
public int[] LRU (int[][] operators, int k) {
this.k = k;
head.next = tail;
tail.prev = head;
int len = (int)Arrays.stream(operators).filter(x -> x[0] == 2).count();
int[] res = new int[len];
for(int i = 0, j = 0; i < operators.length; i++) {
if(operators[i][0] == 1) {
set(operators[i][1], operators[i][2]);
} else {
res[j++] = get(operators[i][1]);
}
}
return res;
}
private void set(int key, int val) {
if(get(key) > -1) {
map.get(k).val = val;
} else {
if(map.size() == k) {
int rk = tail.prev.key;
tail.prev.prev.next = tail;
tail.prev = tail.prev.prev;
map.remove(rk);
}
Node node = new Node(key, val);
map.put(key, node);
moveToHead(node);
}
}
private int get(int key) {
if(map.containsKey(key)) {
Node node = map.get(key);
node.prev.next = node.next;
node.next.prev = node.prev;
moveToHead(node);
return node.val;
}
return -1;
}
private void moveToHead(Node node) {
node.next = head.next;
head.next.prev = node;
head.next = node;
node.prev = head;
}
static class Node{
int key, val;
Node prev, next;
public Node(int key, int val) {
this.key = key;
this.val = val;
}
}
}
(2)解法2
import java.util.*;
public class Solution {
public int[] LRU (int[][] operators, int k) {
// write code here
ArrayList<Integer> list = new ArrayList<>();
LRUCache lru = new LRUCache(k);
for(int[] opt:operators){
if(opt[0] == 1){
lru.put(opt[1],opt[2]);
}else{
list.add(lru.get(opt[1]));
}
}
int[] res = new int[list.size()];
int i = 0;
for(int val:list){
res[i] = list.get(i);
i++;
}
return res;
}
}
//设置LRU缓存结构
class LRUCache{
int cap;
LinkedHashMap<Integer, Integer> cache = new LinkedHashMap<>();
public LRUCache(int capactity){
this.cap = capactity;
}
// 将key变为最近使用
private void makeRecently(int key){
int val = cache.get(key);
//删除key,重新插入到队尾
cache.remove(key);
cache.put(key, val);
}
//获取值
public int get(int key){
if(!cache.containsKey(key)){
return -1;
}
//将这个key变为最近使用的
makeRecently(key);
return cache.get(key);
}
//存进值
public void put(int key,int val){
if(cache.containsKey(key)){
cache.put(key, val);
//设置为最近使用
makeRecently(key);
return;
}
//超出缓存的大小
if(cache.size() >= this.cap){
//拿到链表头部的key(其最久未使用的key)
int oldstKet = cache.keySet().iterator().next();
cache.remove(oldstKet);
}
//将新的key添加到链表尾部
cache.put(key,val);
}
}
设计LFU缓存结构
import java.util.*;
public class Solution {
//设置节点结构
static class Node{
int freq;
int key;
int val;
//初始化
public Node(int freq, int key, int val) {
this.freq = freq;
this.key = key;
this.val = val;
}
}
//频率到双向链表的哈希表
private Map<Integer, LinkedList<Node> > freq_mp = new HashMap<>();
//key到节点的哈希表
private Map<Integer, Node> mp = new HashMap<>();
//记录缓存剩余容量
private int size = 0;
//记录当前最小频次
private int min_freq = 0;
public int[] LFU (int[][] operators, int k) {
//构建初始化连接
//链表剩余大小
this.size = k;
//获取操作数
int len = (int)Arrays.stream(operators).filter(x -> x[0] == 2).count();
int[] res = new int[len];
//遍历所有操作
for(int i = 0, j = 0; i < operators.length; i++){
if(operators[i][0] == 1)
//set操作
set(operators[i][1], operators[i][2]);
else
//get操作
res[j++] = get(operators[i][1]);
}
return res;
}
//调用函数时更新频率或者val值
private void update(Node node, int key, int value) {
//找到频率
int freq = node.freq;
//原频率中删除该节点
freq_mp.get(freq).remove(node);
//哈希表中该频率已无节点,直接删除
if(freq_mp.get(freq).isEmpty()){
freq_mp.remove(freq);
//若当前频率为最小,最小频率加1
if(min_freq == freq)
min_freq++;
}
if(!freq_mp.containsKey(freq + 1))
freq_mp.put(freq + 1, new LinkedList<Node>());
//插入频率加一的双向链表表头,链表中对应:freq key value
freq_mp.get(freq + 1).addFirst(new Node(freq + 1, key, value));
mp.put(key, freq_mp.get(freq + 1).getFirst());
}
//set操作函数
private void set(int key, int value) {
//在哈希表中找到key值
if(mp.containsKey(key))
//若是哈希表中有,则更新值与频率
update(mp.get(key), key, value);
else{
//哈希表中没有,即链表中没有
if(size == 0){
//满容量取频率最低且最早的删掉
int oldkey = freq_mp.get(min_freq).getLast().key;
//频率哈希表的链表中删除
freq_mp.get(min_freq).removeLast();
if(freq_mp.get(min_freq).isEmpty())
freq_mp.remove(min_freq);
//链表哈希表中删除
mp.remove(oldkey);
}
//若有空闲则直接加入,容量减1
else
size--;
//最小频率置为1
min_freq = 1;
//在频率为1的双向链表表头插入该键
if(!freq_mp.containsKey(1))
freq_mp.put(1, new LinkedList<Node>());
freq_mp.get(1).addFirst(new Node(1, key, value));
//哈希表key值指向链表中该位置
mp.put(key, freq_mp.get(1).getFirst());
}
}
//get操作函数
private int get(int key) {
int res = -1;
//查找哈希表
if(mp.containsKey(key)){
Node node = mp.get(key);
//根据哈希表直接获取值
res = node.val;
//更新频率
update(node, key, res);
}
return res;
}
}
实现二叉树先序-中序和后序遍历
(1)递归解法
public void preorder(TreeNode root, List<Integer> list) {
if (root != null) {
list.add(root.val);
preorder(root.left, list);
preorder(root.right, list);
}
}
public void inorder(TreeNode root, List<Integer> list) {
if (root != null) {
inorder(root.left, list);
list.add(root.val);
inorder(root.right, list);
}
}
public void postorder(TreeNode root, List<Integer> list) {
if (root != null) {
postorder(root.left, list);
postorder(root.right, list);
list.add(root.val);
}
}
(2)迭代解法
1) 前序遍历迭代
- 算法1
- 1.根节点入栈
- 2.当栈非空时,栈顶出栈,把出栈的节点值添加到 list 结尾,然后依次再入栈其右子节点和左子节点
- ps:因为前序遍历要左子节点在右子节点前面,所以先入栈右子节点,后入栈左子节点
- 算法2
- 1.辅助变量 curr 初始化为根节点
- 2.当 curr != null 时,就保存这个节点值到 list 中,然后将其入栈并置 curr 为它自己的左子节点
- 3.当 curr == null 时,说明已经遍历到二叉树的左下节点了,这时前序遍历应该遍历右子树了,首先 pop 出已经遍历保存过的父节点,然后置 curr 为 pop 出的父节点的右子节点
- 算法3
- 和算法2的区别:父节点遍历到之后直接保存下来不再入栈,随后入栈其右子节点,这样出栈的时候也不必再置为其右子节点
public void preorder(TreeNode root, ArrayList<Integer> list) {
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode curr = stack.pop();
list.add(curr.val);
if (curr.right != null) {
stack.push(curr.right);
}
if (curr.left != null) {
stack.push(curr.left);
}
}
}
public void preorder(TreeNode root, ArrayList<Integer> list) {
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
while (!stack.isEmpty() || curr != null) {
if (curr != null) {
list.add(curr.val);
stack.push(curr);
curr = curr.left;
} else {
curr = stack.pop();
curr = curr.right;
}
}
}
public void preorder(TreeNode root, ArrayList<Integer> list) {
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
while (!stack.isEmpty() || curr != null) {
if (curr != null) {
list.add(curr.val);
if (curr.right != null) {
stack.push(curr.right);
}
curr = curr.left;
} else {
curr = stack.pop();
}
}
}
2)中序遍历迭代
- 算法1
- 1.辅助变量 curr 初始化 root
- 3.当栈非空或 curr 非 null 时,循环
- 3.1 curr != null 时,说明还有左子节点存在,将 curr 入栈,并且将 curr 置为它自己的左子节点(和前序遍历的区别在于这里遍历到先不保存到 list 中,出栈的时候再将其保存到 list 中)
- 3.2 curr == null 时,说明到二叉树左下的节点了,这时栈顶的父节点出栈赋值给 curr ,并保存节点值到 list ,将 curr 置为栈顶节点的右子节点继续循环
- 算法2
- 算法1的另一种形式
public void inorder(TreeNode root, ArrayList<Integer> list) {
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
while (!stack.isEmpty() || curr != null) {
if (curr != null) {
stack.push(curr);
curr = curr.left;
} else {
curr = stack.pop();
list.add(curr.val);
curr = curr.right;
}
}
}
public void inorder(TreeNode root, ArrayList<Integer> list) {
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
while (!stack.isEmpty() || curr != null) {
while (curr != null) {
stack.push(curr);
curr = curr.left;
}
curr = stack.pop();
list.add(curr.val);
curr = curr.right;
}
}
3) 后序遍历迭代
- 三种算法分别对应前序遍历的反操作:
- 前序遍历从尾部添加元素,后序遍历从头部添加元素
- 前序遍历去左子树,后序遍历去右子树
public void postorder(TreeNode root, ArrayList<Integer> list) {
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode curr = stack.pop();
list.add(0, curr.val);
if(curr.left != null) {
stack.push(curr.left);
}
if(curr.right != null) {
stack.push(curr.right);
}
}
}
public void postorder(TreeNode root, List<Integer> list) {
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
while (!stack.isEmpty() || curr != null) {
if (curr != null) {
stack.push(curr);
list.add(0, curr.val);
curr = curr.right;
} else {
curr = stack.pop();
curr = curr.left;
}
}
}
public void postorder(TreeNode root, List<Integer> list) {
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
while (!stack.isEmpty() || curr != null) {
if (curr != null) {
list.add(0, curr.val);
if (curr.left != null) {
stack.push(curr.left);
}
curr = curr.right;
} else {
curr = stack.pop();
}
}
}
求二叉树的层序遍历
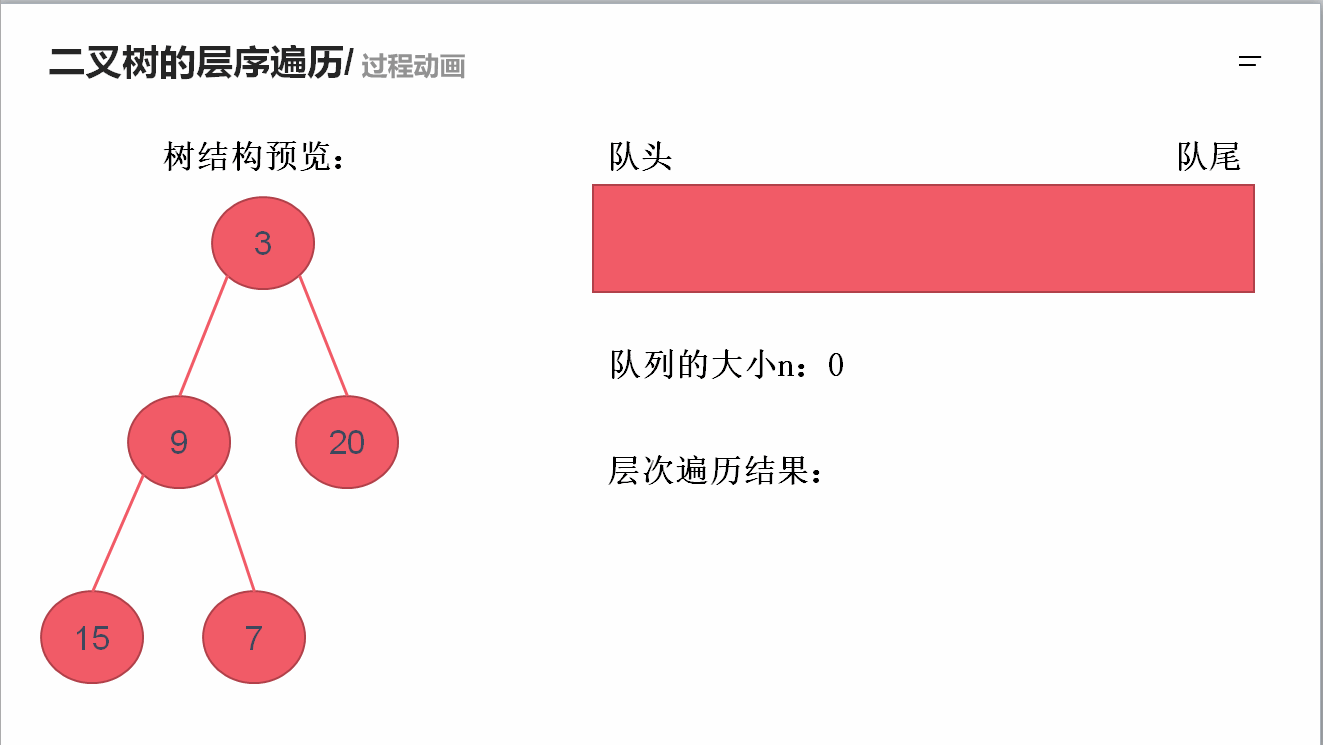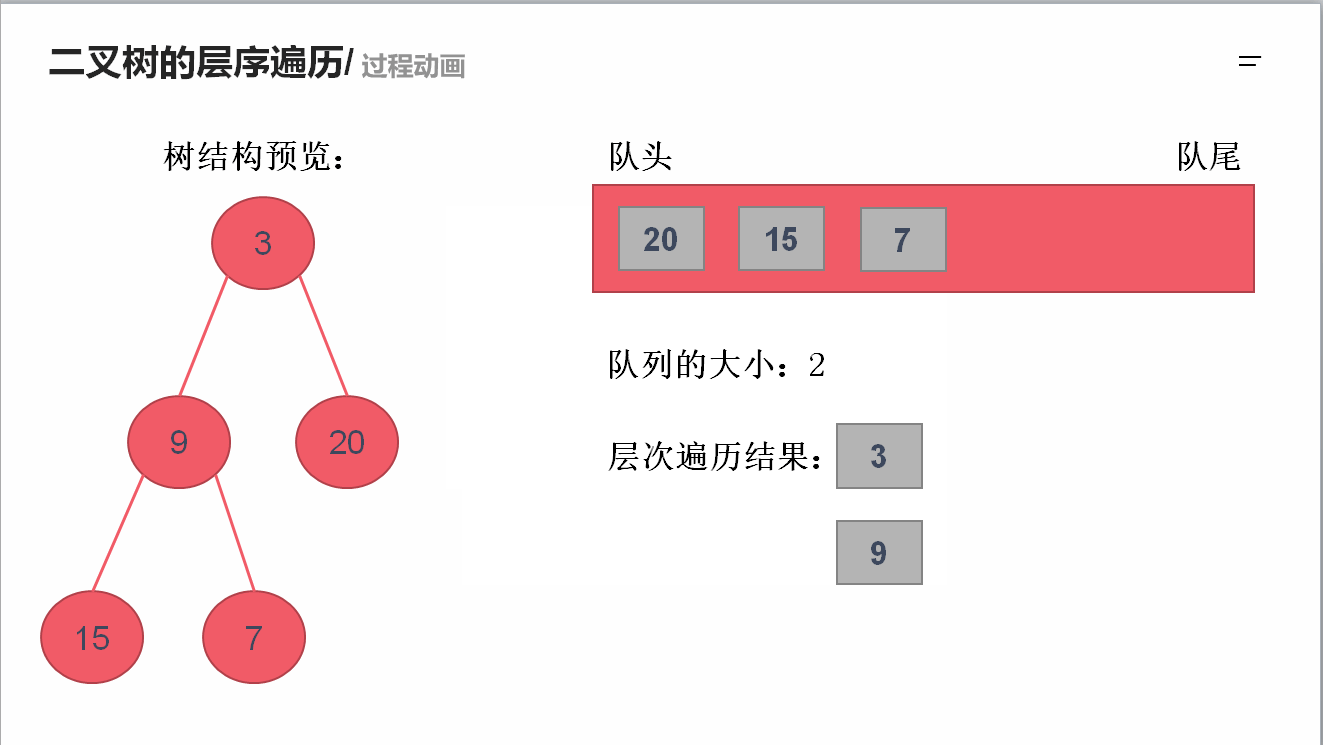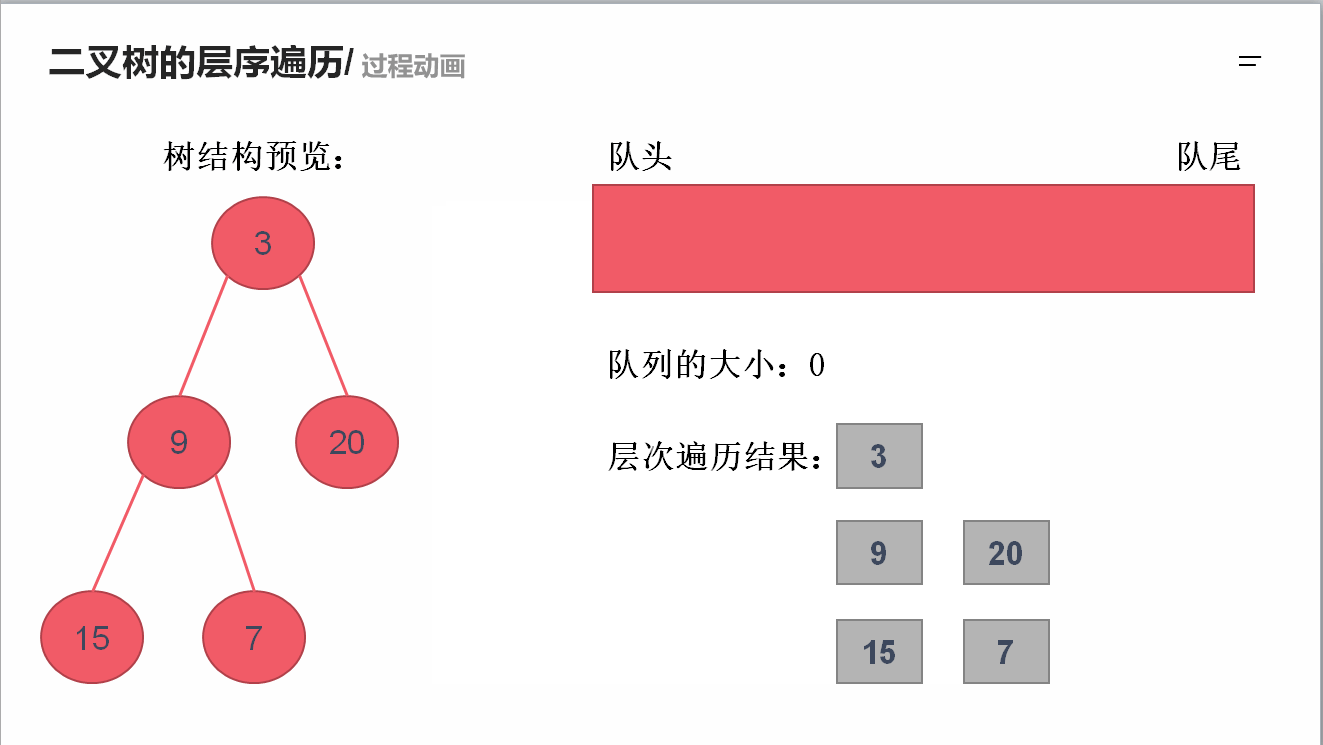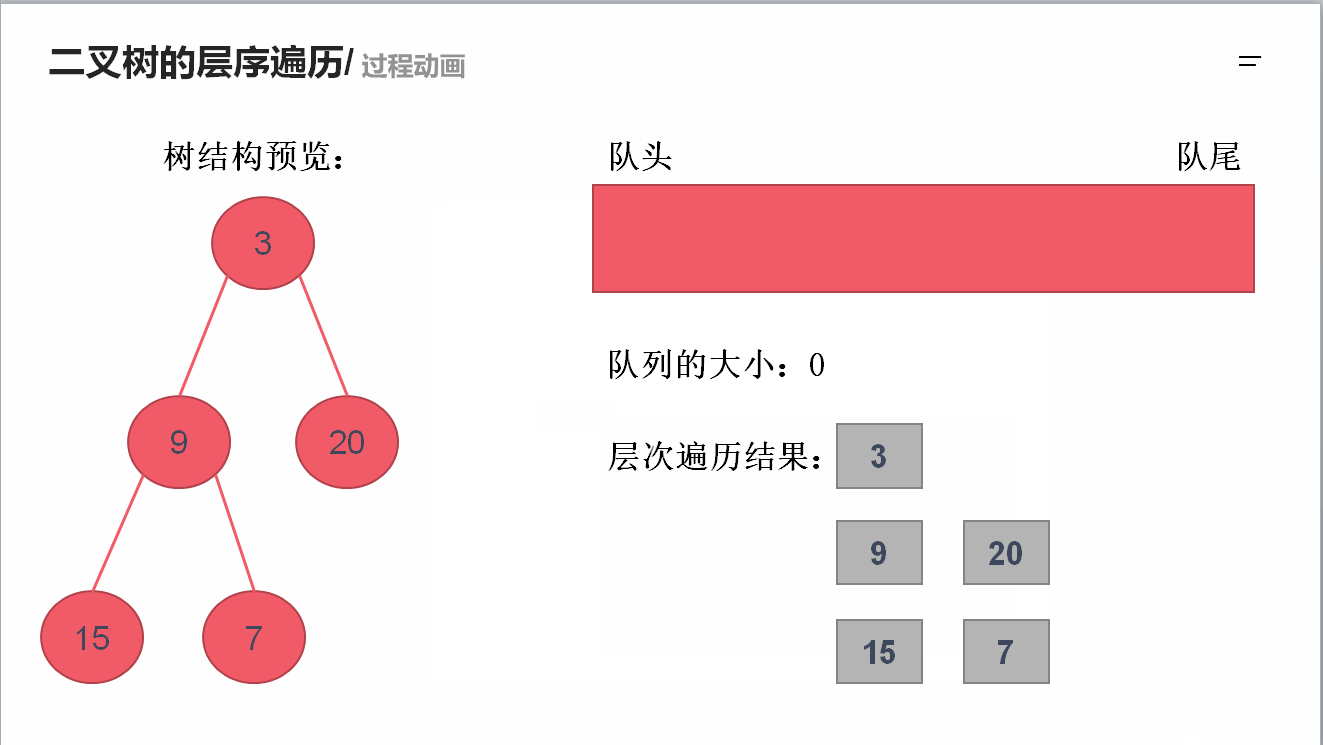需要借助队列的先进先出特性来实现
java Queue中 remove/poll, add/offer, element/peek区别
offer,add区别:
一些队列有大小限制,因此如果想在一个满的队列中加入一个新项,多出的项就会被拒绝。
这时新的 offer 方法就可以起作用了。它不是对调用 add() 方法抛出一个 unchecked 异常,而只是得到由 offer() 返回的 false。
poll,remove区别:
remove() 和 poll() 方法都是从队列中删除第一个元素。remove() 的行为与 Collection 接口的版本相似,
但是新的 poll() 方法在用空集合调用时不是抛出异常,只是返回 null。因此新的方法更适合容易出现异常条件的情况。
peek,element区别:
element() 和 peek() 用于在队列的头部查询元素。与 remove() 方法类似,在队列为空时, element() 抛出一个异常,而 peek() 返回 null
(1)队列解法:
import java.util.Queue;
import java.util.LinkedList;
import java.util.ArrayList;
public class Solution {
public ArrayList<ArrayList<Integer>> levelOrder(TreeNode root) {
ArrayList<ArrayList<Integer>> result = new ArrayList<ArrayList<Integer>>();
if(root != null){
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()){
int size = queue.size();
ArrayList<Integer> newLevel = new ArrayList<Integer>();
for(int i=0; i<size; i++){
TreeNode temp = queue.poll();
newLevel.add(temp.val);
if(temp.left != null)
queue.offer(temp.left);
if(temp.right != null)
queue.offer(temp.right);
}
result.add(newLevel);
}
}
return result;
}
}
(2)递归解法:
public class Solution {
private ArrayList<ArrayList<Integer>> result = new ArrayList<ArrayList<Integer>>();
public ArrayList<ArrayList<Integer>> levelOrder (TreeNode root) {
order(root, 0);
return result;
}
private void order(TreeNode root, int level) {
if (root == null) return;
if (result.size() <= level) // 用level来判断
result.add(new ArrayList<Integer>());
result.get(level).add(root.val);
order(root.left, level+1);
order(root.right, level+1);
}
}
最小的K个数
对于n个整数中最小的K个数的查找,可以使用各种排序算法:冒泡/堆排/快排/希尔排序等等。将此n个整数从小到大排序之后,前k个数就是所求的结果。
但是当原数组中的数据顺序不可修改,并且n的值过于大的时候,各种排序算法要将n个数加载到内存中,即:如果是海量数据中查找出最小的k个数,那么这种办法是效率很低的。接下来介绍另外一种算法:
创建一个大小为k的数组,遍历n个整数,如果遍历到的数小于大小为k数组的最大值,则将此数与其最大值替换。
由于每次都要拿n个整数和数组中的最大值比较,所以选择大根堆这一数据结构(大家要分清楚大根堆这一数据结构和堆排序之间的区别:堆排序是在大根堆这一数据结构上进行排序的一种排序算法,一个是数据结构,一个是算法)
(1)解法一:普通排序
直接排序,然后去前k小数据。
- 快速排序
import java.util.*;
public class Solution {
public ArrayList<Integer> GetLeastNumbers_Solution(int[] input, int k) {
ArrayList<Integer> ans = new ArrayList<>();
if(input == null || input.length == 0 || k == 0) {
return ans;
}
partition(0, input.length-1, input, k);
for(int i = 0; i < k; i++) {
ans.add(input[i]);
}
return ans;
}
public void partition(int left, int right, int[] nums, int k) {
if(left >= right) {
return;
}
int pivot = nums[left];
int i = left, j = right;
while(i < j) {
while(i < j && nums[j] > pivot) {
j--;
}
if(i < j) {
nums[i] = nums[j];
i++;
}
while(i < j && nums[i] < pivot) {
i++;
}
if(i < j) {
nums[j] = nums[i];
j--;
}
}
nums[i] = pivot;
if(i == k) {
return;
} else if(i > k) {
partition(left, i-1, nums, k);
} else {
partition(i+1, right, nums, k);
}
}
}
使用TreeMap:
public ArrayList<Integer> GetLeastNumbers_Solution(int[] input, int k) {
ArrayList<Integer> res = new ArrayList<>(k);
//根据题意要求,如果K>数组的长度,返回一个空的数组
if (k > input.length || k == 0)
return res;
//map中key存放数组中元素,value存放这个元素的个数
TreeMap<Integer, Integer> map = new TreeMap<>();
int count = 0;
for (int i = 0; i < input.length; i++) {
//map中先存放k个元素,之后map中元素始终维持在k个
if (count < k) {
map.put(input[i], map.getOrDefault(input[i], 0) + 1);
count++;
continue;
}
Map.Entry<Integer, Integer> entry = map.lastEntry();
//从第k+1个元素开始,每次存放的时候都要和map中最大的那个比较,如果比map中最大的小,
//就把map中最大的给移除,然后把当前元素加入到map中
if (entry.getKey() > input[i]) {
//移除map中最大的元素,如果只有一个直接移除。如果有多个(数组中会有重复的元素),移除一个就行
if (entry.getValue() == 1) {
map.pollLastEntry();
} else {
map.put(entry.getKey(), entry.getValue() - 1);
}
//把当前元素加入到map中
map.put(input[i], map.getOrDefault(input[i], 0) + 1);
}
}
//把map中key存放到集合list中
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
int keyCount = entry.getValue();
while (keyCount-- > 0) {
res.add(entry.getKey());
}
}
return res;
}
(2)解法二:堆排序
建立一个容量为k的大根堆的优先队列。遍历一遍元素,如果队列大小<k,就直接入队,否则,让当前元素与队顶元素相比,如果队顶元素大,则出队,将当前元素入队
-
public class Solution { public ArrayList<Integer> GetLeastNumbers_Solution(int [] input, int k) { if(input == null || input.length==0 || k>input.length) return new ArrayList(); ArrayList<Integer> result = new ArrayList<>(); heapSort(input); for(int i=0;i<k;i++){ result.add(input[i]); } return result; } //堆排序 public void heapSort(int arr[]){ int temp; for(int i = arr.length/2 -1;i>=0;i--){ adjustHeap(arr,i,arr.length); } for(int j=arr.length-1;j>0;j--){ temp = arr[j]; arr[j] = arr[0]; arr[0] = temp; //调整对堆结构 adjustHeap(arr,0,j); } } //调整当前以 i 索引处为堆的结构 public void adjustHeap(int[] arr,int i,int length){ //首先将 当前堆顶元素 arr[i] 保存起来 int temp = arr[i]; //接下来的循环就是在当前整个堆中不断地循环,找到堆中的最大值 for(int k = i*2+1;k<length;k = k*2+1){ // k = i*2+1,就是当前堆的左子节点的索引, // 那么 k+1,代表的就是右子节点的索引 // 在数组界限内 判断 当前堆顶节点的左右节点哪个大 if(k+1<length && arr[k]<arr[k+1]){ //如果左子节点小于右子节点,我们将k指向右子节点的索引 k += 1; // 此时 k 指向的位置就是当前堆下 值最大的位置 } //判断arr[k]和堆顶顶元素的关系 if(arr[k] > temp){ //我们将较大值 赋给堆顶 arr[i] = arr[k]; //接着再以k处为堆顶,继续向下循环遍历 i = k; }else{ break; } } //将最初保存的堆顶元素赋值给“最终替换了”它的那个元素的索引上 //相当于就是将堆顶元素向下沉,所能沉到的最低位置就是 当前的 i arr[i] = temp; } } -
public class Solution { public ArrayList<Integer> GetLeastNumbers_Solution(int [] input, int k) { ArrayList<Integer> list = new ArrayList<>(); if (input == null || input.length == 0 || k > input.length || k == 0) return list; int[] arr = new int[k + 1];//数组下标0的位置作为哨兵,不存储数据 //初始化数组 for (int i = 1; i < k + 1; i++) arr[i] = input[i - 1]; buildMaxHeap(arr, k + 1);//构造大根堆 for (int i = k; i < input.length; i++) { if (input[i] < arr[1]) { arr[1] = input[i]; adjustDown(arr, 1, k + 1);//将改变了根节点的二叉树继续调整为大根堆 } } for (int i = 1; i < arr.length; i++) { list.add(arr[i]); } return list; } /** * @Author: ZwZ * @Description: 构造大根堆 * @Param: [arr, length] length:数组长度 作为是否跳出循环的条件 */ public void buildMaxHeap(int[] arr, int length) { if (arr == null || arr.length == 0 || arr.length == 1) return; for (int i = (length - 1) / 2; i > 0; i--) { adjustDown(arr, i, arr.length); } } /** * @Author: ZwZ * @Description: 堆排序中对一个子二叉树进行堆排序 * @Param: [arr, k, length] */ public void adjustDown(int[] arr, int k, int length) { arr[0] = arr[k];//哨兵 for (int i = 2 * k; i <= length; i *= 2) { if (i < length - 1 && arr[i] < arr[i + 1]) i++;//取k较大的子结点的下标 if (i > length - 1 || arr[0] >= arr[i]) break; else { arr[k] = arr[i]; k = i; //向下筛选 } } arr[k] = arr[0]; } }
(3)解法三:快排思想
对数组[l, r]一次快排partition过程可得到,[l, p), p, [p+1, r)三个区间,[l,p)为小于等于p的值
[p+1,r)为大于等于p的值。
然后再判断p,利用二分法
-
如果[l,p), p,也就是p+1个元素(因为下标从0开始),如果p+1 == k, 找到答案
-
如果p+1 < k, 说明答案在[p+1, r)区间内,
-
如果p+1 > k , 说明答案在[l, p)内
写法1:
public class Solution {
ArrayList<Integer> result = new ArrayList<>();
public ArrayList<Integer> GetLeastNumbers_Solution(int [] input, int k) {
if(k == 0 || k >input.length) {
return result;
}
quickSearch(input, 0, input.length - 1, k - 1);
return result;
}
void quickSearch(int[] nums, int left, int right, int k) {
int index = partition(nums, left, right);
if (index == k) {
for (int i = 0; i <=k; i++) {
result.add(nums[i]);
}
}else if (index > k) {
quickSearch(nums, left, index - 1, k);
} else {
quickSearch(nums, index + 1, right, k);
}
}
int partition(int[]nums, int left, int right) {
int value = nums[left];
int index = left;
for (int i = left; i <= right; i++) {
if (nums[i] < value) {
index++;
swap(nums, i, index);
}
}
swap(nums, index, left);
return index;
}
void swap(int[] nums, int left, int right) {
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
}
}
写法2:
public class Solution {
public ArrayList<Integer> GetLeastNumbers_Solution(int[] input, int k) {
ArrayList<Integer> ans = new ArrayList<>();
if(input == null || input.length == 0 || k == 0) {
return ans;
}
partition(0, input.length-1, input, k);
for(int i = 0; i < k; i++) {
ans.add(input[i]);
}
return ans;
}
public void partition(int left, int right, int[] nums, int k) {
if(left >= right) {
return;
}
int pivot = nums[left];
int i = left, j = right;
while(i < j) {
while(i < j && nums[j] > pivot) {
j--;
}
if(i < j) {
nums[i] = nums[j];
i++;
}
while(i < j && nums[i] < pivot) {
i++;
}
if(i < j) {
nums[j] = nums[i];
j--;
}
}
nums[i] = pivot;
if(i == k) {
return;
} else if(i > k) {
partition(left, i-1, nums, k);
} else {
partition(i+1, right, nums, k);
}
}
}
(4)解法四:大顶堆
输入n个整数,找出其中最小的K个数。例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4。 维护一个大小为 K 的最小堆过程如下:使用大顶堆。在添加一个元素之后,如果大顶堆的大小大于 K, 那么将大顶堆的堆顶元素去除,也就是将当前堆中值最大的元素去除,从而使得留在堆中的元素都比被去除的元素来得小。 应该使用大顶堆来维护最小堆,而不能直接创建一个小顶堆并设置一个大小,企图让小顶堆中的元素都是最小元素 Java 的 PriorityQueue 实现了堆的能力,PriorityQueue 默认是小顶堆, 可以在在初始化时使用 Lambda 表达式 (o1, o2) -> o2 - o1 来实现大顶堆。
public class GetLeastNumbers_Solution {
public ArrayList<Integer> GetLeastNumbers_Solution(int [] nums,int k){
if (k > nums.length || k <0)return new ArrayList<>();
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(((o1, o2) -> o2-o1));
for (int i = 0; i <nums.length ; i++) {
maxHeap.add(nums[i]);
if (maxHeap.size() >k){
maxHeap.poll();
}
}
return new ArrayList<>(maxHeap);
}
}
寻找第K大
(1)快排:import java.util.*;
public class Solution {
public int findKth(int[] a, int n, int K) {
// write code here
return findK(a, 0, n-1, K);
}
public static int partition(int[] arr, int left, int right) {
int pivot = arr[left];
while (left < right) {
while (left < right && arr[right] <= pivot) {
right--;
}
arr[left] = arr[right];
while (left < right && arr[left] >= pivot) {
left++;
}
arr[right] = arr[left];
}
arr[left] = pivot;
return left;
}
public static int findK(int[] arr, int left, int right, int k) {
if (left <= right) {
int pivot = partition(arr, left, right);
if (pivot == k - 1) {
return arr[pivot];
} else if (pivot < k - 1) {
return findK(arr, pivot + 1, right, k);
} else {
return findK(arr, left, pivot - 1, k);
}
}
return -1;
}
}
(2)小顶堆:
public class Solution {
public int findKth(int[] a, int n, int K) {
PriorityQueue<Integer> queue = new PriorityQueue<>(K,new Comparator<Integer>(){
@Override
public int compare(Integer o1 , Integer o2){
//初始化一个小顶堆
return o1.compareTo(o2);
}
});
for (int ele : a){
if (queue.size() < K || ele > queue.peek())
queue.offer(ele);
while (queue.size() > K)
queue.poll();
}
return queue.peek();
}
}
数据流中的中位数
(1) 使用集合排序
import java.util.*;
public class Solution {
ArrayList<Integer> list = new ArrayList<>();//创建一个数组列表(list)
public void Insert(Integer num) {
list.add(num);//往数组列表(list)中添加元素
}
public Double GetMedian() {
//集合工具类(Collections)对数组列表排序
Collections.sort(list);
int length = list.size();
//求中位数
if(length % 2 != 0){
//从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值
return (double)list.get(length/2);
} else{
//从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值
return (double)(list.get(length/2-1) + list.get(length/2)) / 2;
}
}
}
(2)插入排序法
import java.util.*;
public class Solution {
private ArrayList<Integer> val = new ArrayList<Integer>();
public void Insert(Integer num) {
if(val.isEmpty()) {
//val中没有数据,直接加入
val.add(num);
} else {
//val中有数据,需要插入排序
int i = 0;
//遍历找到插入点
for(; i < val.size(); i++){
if(num <= val.get(i))
break;
}
//插入相应位置
val.add(i, num);
}
}
public Double GetMedian() {
int n = val.size();
//奇数个数字
if(n % 2 == 1)
//类型转换
return (double)val.get(n / 2);
//偶数个数字
else{
double a = val.get(n / 2);
double b = val.get(n / 2 - 1);
return (a + b) / 2;
}
}
}
(3)堆排序法
step 1:可以维护两个堆,分别是大顶堆min,用于存储较小的值,其中顶部最大;小顶堆max,用于存储较大的值,其中顶部最小,则中位数只会在两个堆的堆顶出现。
step 2:约定奇数个元素时取大顶堆的顶部值,偶数个元素时取两堆顶的平均值,则可以发现两个堆的数据长度要么是相等的,要么奇数时大顶堆会多一个。
step 3:每次输入的数据流先进入大顶堆排序,然后将小顶堆的最大值弹入大顶堆中,完成整个的排序。
step 4:但是因为大顶堆的数据不可能会比小顶堆少一个,因此需要再比较二者的长度,若是小顶堆长度小于大顶堆,需要从大顶堆中弹出最小值到大顶堆中进行平衡。
import java.util.*;
public class Solution {
//小顶堆,元素数值都比大顶堆大
private PriorityQueue<Integer> max = new PriorityQueue<>();
//大顶堆,元素数值较小
private PriorityQueue<Integer> min = new PriorityQueue<>((o1, o2)->o2.compareTo(o1));
public void Insert(Integer num) {
//先加入较小部分
min.offer(num);
//将较小部分的最大值取出,送入到较大部分
max.offer(min.poll());
//平衡两个堆的数量
if(min.size() < max.size())
min.offer(max.poll());
}
public Double GetMedian() {
//奇数个
if(min.size() > max.size())
return (double)min.peek();
else
//偶数个
return (double)(min.peek() + max.peek()) / 2;
}
}
表达式求值
import java.util.*;
public class Solution {
// 使用 map 维护一个运算符优先级(其中加减法优先级相同,乘法有着更高的优先级)
Map<Character, Integer> map = new HashMap<Character, Integer>(){{
put('-', 1);
put('+', 1);
put('*', 2);
}};
public int solve(String s) {
// 将所有的空格去掉
s = s.replaceAll(" ", "");
char[] cs = s.toCharArray();
int n = s.length();
// 存放所有的数字
Deque<Integer> nums = new ArrayDeque<>();
// 为了防止第一个数为负数,先往 nums 加个 0
nums.addLast(0);
// 存放所有「非数字以外」的操作
Deque<Character> ops = new ArrayDeque<>();
for (int i = 0; i < n; i++) {
char c = cs[i];
if (c == '(') {
ops.addLast(c);
} else if (c == ')') {
// 计算到最近一个左括号为止
while (!ops.isEmpty()) {
if (ops.peekLast() != '(') {
calc(nums, ops);
} else {
ops.pollLast();
break;
}
}
} else {
if (isNumber(c)) {
int u = 0;
int j = i;
// 将从 i 位置开始后面的连续数字整体取出,加入 nums
while (j < n && isNumber(cs[j])) u = u * 10 + (cs[j++] - '0');
nums.addLast(u);
i = j - 1;
} else {
if (i > 0 && (cs[i - 1] == '(' || cs[i - 1] == '+' || cs[i - 1] == '-')) {
nums.addLast(0);
}
// 有一个新操作要入栈时,先把栈内可以算的都算了
// 只有满足「栈内运算符」比「当前运算符」优先级高/同等,才进行运算
while (!ops.isEmpty() && ops.peekLast() != '(') {
char prev = ops.peekLast();
if (map.get(prev) >= map.get(c)) {
calc(nums, ops);
} else {
break;
}
}
ops.addLast(c);
}
}
}
// 将剩余的计算完
while (!ops.isEmpty() && ops.peekLast() != '(') calc(nums, ops);
return nums.peekLast();
}
// 计算逻辑:从 nums 中取出两个操作数,从 ops 中取出运算符,然后根据运算符进行计算即可
void calc(Deque<Integer> nums, Deque<Character> ops) {
if (nums.isEmpty() || nums.size() < 2) return;
if (ops.isEmpty()) return;
int b = nums.pollLast(), a = nums.pollLast();
char op = ops.pollLast();
int ans = 0;
if (op == '+') ans = a + b;
else if (op == '-') ans = a - b;
else if (op == '*') ans = a * b;
nums.addLast(ans);
}
boolean isNumber(char c) {
return Character.isDigit(c);
}
}
两数之和
(1)解法1:public int[] twoSum (int[] numbers, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int cur = 0, tmp; cur < numbers.length; cur++){
tmp = numbers[cur];
if (map.containsKey(target - tmp)){
return new int[] {map.get(target - tmp) + 1, cur + 1};
}
map.put(tmp, cur);
}
throw new RuntimeException("results not exits");
}
(2)解法2:
public int[] twoSum (int[] numbers, int target) {
HashMap<Integer, Integer> map = new HashMap<>();
int index1 = -1;
int index2 = -1;
for (int i = 0; i < numbers.length; i++) {
if (map.containsKey(target - numbers[i])) {
index1 = map.get(target - numbers[i]);
index2 = i + 1;
break;
} else {
map.put(numbers[i], i + 1);
}
}
return new int[]{index1, index2};
}
(3)解法3:
public int[] twoSum (int[] numbers, int target) {
Map<Integer, Integer> map = new HashMap<>();
for(int i = 0; i < numbers.length; i ++){
map.put(numbers[i], i);
}
for(int i = 0; i < numbers.length; i ++){
int num = target - numbers[i];
Integer numIndex = map.get(num);
if(numIndex != null && numIndex != i ){
return new int[]{i+1, numIndex+1};
}
}
return new int[]{-1,-1};
}
数组中出现次数超过一半的数字
public int MoreThanHalfNum_Solution(int [] array) {
//哈希表统计每个数字出现的次数
HashMap<Integer, Integer> mp = new HashMap<Integer, Integer>();
//遍历数组
for (int i = 0; i < array.length; i++) {
//统计频率
if (!mp.containsKey(array[i]))
mp.put(array[i], 1);
else
mp.put(array[i], mp.get(array[i]) + 1);
//一旦有个数大于长度一半的情况即可返回
if (mp.get(array[i]) > array.length / 2)
return array[i];
}
return 0;
}
数组中只出现一次的两个数字
public int[] FindNumsAppearOnce (int[] array) {
HashMap<Integer, Integer> mp = new HashMap<Integer, Integer>();
ArrayList<Integer> res = new ArrayList<Integer>();
//遍历数组
for(int i = 0; i < array.length; i++)
//统计每个数出现的频率
if(!mp.containsKey(array[i]))
mp.put(array[i], 1);
else
mp.put(array[i], mp.get(array[i]) + 1);
//再次遍历数组
for(int i = 0; i < array.length; i++)
//找到频率为1的两个数
if(mp.get(array[i]) == 1)
res.add(array[i]);
//整理次序
if(res.get(0) < res.get(1))
return new int[] {res.get(0), res.get(1)};
else
return new int[] {res.get(1), res.get(0)};
}
缺失的第一个正整数
public int minNumberDisappeared (int[] nums) {
int n = nums.length;
HashMap<Integer, Integer> mp = new HashMap<Integer, Integer>();
//哈希表记录数组中出现的每个数字
for(int i = 0; i < n; i++)
mp.put(nums[i], 1);
int res = 1;
//从1开始找到哈希表中第一个没有出现的正整数
while(mp.containsKey(res))
res++;
return res;
}
三数之和
先对数组排序,然后固定一个数字,再求两个数字之和
public ArrayList<ArrayList<Integer>> threeSum(int[] num) {
//先排序
Arrays.sort(num);
ArrayList<ArrayList<Integer>> res = new ArrayList<>();
int length = num.length;
for (int i = 0; i < length - 2; i++) {
//过滤掉重复的
if (i != 0 && num[i] == num[i - 1])
continue;
int left = i + 1;
int right = length - 1;
int target = -num[i];
//改为求两数之和
while (left < right) {
int midVale = num[left] + num[right];
if (midVale == target) {
res.add(new ArrayList<>(Arrays.asList(num[i], num[left], num[right])));
while (left < right && num[left] == num[left + 1])//过滤掉重复的
left++;
while (left < right && num[right] == num[right - 1])//过滤掉重复的
right--;
left++;
right--;
} else if (midVale < target)
left++;
else
right--;
}
}
return res;
}
没有重复项数字的全排列
public class Solution {
ArrayList<ArrayList<Integer>> resList = new ArrayList<ArrayList<Integer>>();
public ArrayList<ArrayList<Integer>> permute(int[] num) {
// 存一种排列
LinkedList<Integer> list = new LinkedList<>();
// 递归进行
backTrack(num, list);
return resList;
}
public void backTrack(int[] num, LinkedList<Integer> list) {
// 当list中的长度等于数组的长度,则证明此时已经找到一种排列了
if (list.size() == num.length) {
// add进返回结果集中
resList.add(new ArrayList<>(list));
return;
}
// 遍历num数组
for (int i = 0; i < num.length; i++) {
// 若当前位置中的数已经添加过了则跳过
if (list.contains(num[i]))
continue;
// 选择该数
list.add(num[i]);
// 继续寻找
backTrack(num, list);
// 撤销最后一个
list.removeLast();
}
}
}
有重复项数字的全排列
import java.util.*;
public class Solution {
public void recursion(ArrayList<ArrayList<Integer>> res, int[] num, ArrayList<Integer> temp, Boolean[] vis){
//临时数组满了加入输出
if(temp.size() == num.length){
res.add(new ArrayList<Integer>(temp));
return;
}
//遍历所有元素选取一个加入
for(int i = 0; i < num.length; i++){
//如果该元素已经被加入了则不需要再加入了
if(vis[i])
continue;
if(i > 0 && num[i - 1] == num[i] && !vis[i - 1])
//当前的元素num[i]与同一层的前一个元素num[i-1]相同且num[i-1]已经用过了
continue;
//标记为使用过
vis[i] = true;
//加入数组
temp.add(num[i]);
recursion(res, num, temp, vis);
//回溯
vis[i] = false;
temp.remove(temp.size() - 1);
}
}
public ArrayList<ArrayList<Integer>> permuteUnique(int[] num) {
//先按字典序排序
Arrays.sort(num);
Boolean[] vis = new Boolean[num.length];
Arrays.fill(vis, false);
ArrayList<ArrayList<Integer> > res = new ArrayList<ArrayList<Integer>>();
ArrayList<Integer> temp = new ArrayList<Integer>();
recursion(res, num, temp, vis);
return res;
}
}
岛屿数量
(1)DFS解决
public class Solution {
public int solve(char[][] grid) {
//边界条件判断
if (grid == null || grid.length == 0)
return 0;
//统计岛屿的个数
int count = 0;
//两个for循环遍历每一个格子
for (int i = 0; i < grid.length; i++)
for (int j = 0; j < grid[0].length; j++) {
//只有当前格子是1才开始计算
if (grid[i][j] == '1') {
//如果当前格子是1,岛屿的数量加1
count++;
//然后通过dfs把当前格子的上下左右4
//个位置为1的都要置为0,因为他们是连着
//一起的算一个岛屿,
dfs(grid, i, j);
}
}
//最后返回岛屿的数量
return count;
}
//这个方***把当前格子以及他邻近的为1的格子都会置为1
public void dfs(char[][] grid, int i, int j) {
//边界条件判断,不能越界
if (i < 0 || i >= grid.length || j < 0 || j >= grid[0].length ||
grid[i][j] == '0')
return;
//把当前格子置为0,然后再从他的上下左右4个方向继续遍历
grid[i][j] = '0';
dfs(grid, i - 1, j);//上
dfs(grid, i + 1, j);//下
dfs(grid, i, j + 1);//左
dfs(grid, i, j - 1);//右
}
}
(2)BFS解决
public class Solution {
public int solve(char[][] grid) {
//边界条件判断
if (grid == null || grid.length == 0)
return 0;
//统计岛屿的个数
int count = 0;
//两个for循环遍历每一个格子
for (int i = 0; i < grid.length; i++)
for (int j = 0; j < grid[0].length; j++) {
//只有当前格子是1才开始计算
if (grid[i][j] == '1') {
//如果当前格子是1,岛屿的数量加1
count++;
//然后通过bfs把当前格子的上下左右4
//个位置为1的都要置为0,因为他们是连着
//一起的算一个岛屿,
bfs(grid, i, j);
}
}
return count;
}
private void bfs(char[][] grid, int x, int y) {
//把当前格子先置为0
grid[x][y] = '0';
int n = grid.length;
int m = grid[0].length;
//使用队列,存储的是格子坐标转化的值
Queue<Integer> queue = new LinkedList<>();
//我们知道平面坐标是两位数字,但队列中存储的是一位数字,
//所以这里是把两位数字转化为一位数字
int code = x * m + y;
//坐标转化的值存放到队列中
queue.add(code);
while (!queue.isEmpty()) {
//出队
code = queue.poll();
//在反转成坐标值(i,j)
int i = code / m;
int j = code % m;
if (i > 0 && grid[i - 1][j] == '1') {//上
//如果上边格子为1,把它置为0,然后加入到队列中
//下面同理
grid[i - 1][j] = '0';
queue.add((i - 1) * m + j);
}
if (i < n - 1 && grid[i + 1][j] == '1') {//下
grid[i + 1][j] = '0';
queue.add((i + 1) * m + j);
}
if (j > 0 && grid[i][j - 1] == '1') { //左
grid[i][j - 1] = '0';
queue.add(i * m + j - 1);
}
if (j < m - 1 && grid[i][j + 1] == '1') {//右
grid[i][j + 1] = '0';
queue.add(i * m + j + 1);
}
}
}
}
字符串的排列
import java.util.*;
public class Solution {
public ArrayList<String> Permutation(String str) {
ArrayList<String> result = new ArrayList<>();
if(str.length() == 0){
return result;
}
recur(str,"",result);
return result;
}
public void recur(String str,String cur,ArrayList<String> result){
if(str.length() == 0){
if(!result.contains(cur)){
result.add(cur);
}
}
for(int i = 0; i < str.length();i++){
recur(str.substring(0,i) + str.substring(i+1, str.length()), cur+str.charAt(i), result);
}
}
}
N皇后问题
import java.util.*;
public class Solution {
Set<Integer> column = new HashSet<Integer>(); //标记列不可用
Set<Integer> posSlant = new HashSet<Integer>();//标记正斜线不可用
Set<Integer> conSlant = new HashSet<Integer>();//标记反斜线不可用
int result = 0;
public int Nqueen (int n) {
compute(0, n);
return result;
}
private void compute(int i, int n) {
if (i == n) {
result++;
return;
}
for (int j = 0; j < n; j++) {
if (column.contains(j) ||
posSlant.contains(i - j) ||
conSlant.contains(i + j)) {
continue;
}
column.add(j); //列号j
posSlant.add(i - j);//行号i - 列号j 正斜线
conSlant.add(i + j);//行号i + 列号j 反斜线
compute(i + 1, n); //计算下一行
column.remove(j); //完成上一步递归计算后,清除
posSlant.remove(i - j);
conSlant.remove(i + j);
}
}
}
括号生成
import java.util.*;
public class Solution {
public void recursion(int left, int right, String temp, ArrayList<String> res,
int n) {
//左右括号都用完了,就加入结果
if (left == n && right == n) {
res.add(temp);
return;
}
//使用一次左括号
if (left < n) {
recursion(left + 1, right, temp + "(", res, n);
}
//使用右括号个数必须少于左括号
if (right < n && left > right) {
recursion(left, right + 1, temp + ")", res, n);
}
}
public ArrayList<String> generateParenthesis (int n) {
//记录结果
ArrayList<String> res = new ArrayList<String>();
//递归
recursion(0, 0, "", res, n);
return res;
}
}
矩阵最长递增路径
(1) DFS解决
import java.util.*;
public class Solution {
//记录四个方向
private int[][] dirs = new int[][] {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
private int n, m;
//深度优先搜索,返回最大单元格数
public int dfs(int[][] matrix, int[][] dp, int i, int j) {
if (dp[i][j] != 0)
return dp[i][j];
dp[i][j]++;
for (int k = 0; k < 4; k++) {
int nexti = i + dirs[k][0];
int nextj = j + dirs[k][1];
//判断条件
if (nexti >= 0 && nexti < n &&
nextj >= 0 && nextj < m &&
matrix[nexti][nextj] > matrix[i][j]) {
dp[i][j] = Math.max(dp[i][j], dfs(matrix, dp, nexti, nextj) + 1);
}
}
return dp[i][j];
}
public int solve (int[][] matrix) {
//矩阵不为空
if (matrix.length == 0 || matrix[0].length == 0)
return 0;
int res = 0;
n = matrix.length;
m = matrix[0].length;
//i,j处的单元格拥有的最长递增路径
int[][] dp = new int[m + 1][n + 1];
for (int i = 0; i < n; i++)
for (int j = 0; j < m; j++)
//更新最大值
res = Math.max(res, dfs(matrix, dp, i, j));
return res;
}
}
合并两个排序的链表
(1)迭代:
public class Solution {
public ListNode Merge(ListNode list1,ListNode list2) {
ListNode head = new ListNode(Integer.MIN_VALUE);
ListNode cur = head;
while (list1!=null && list2!=null) {
if (list1.val <list2.val) {
cur.next = list1;
cur = cur.next;
list1 = list1.next;
} else {
cur.next = list2;
cur = cur.next;
list2 = list2.next;
}
}
if (list1 == null) {
cur.next = list2;
} else {
cur.next = list1;
}
return head.next;
}
}
(2)递归:
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode Merge(ListNode list1,ListNode list2) {
if(list1 == null) return list2;
if(list2 == null) return list1;
if(list1.val > list2.val){
list2.next = Merge(list1,list2.next);
return list2;
}else{
list1.next = Merge(list1.next,list2);
return list1;
}
}
}
合并k个已排序的链表
import java.util.ArrayList;
public class Solution {
//两个链表合并函数
public ListNode Merge(ListNode list1, ListNode list2) {
//一个已经为空了,直接返回另一个
if(list1 == null)
return list2;
if(list2 == null)
return list1;
//加一个表头
ListNode head = new ListNode(0);
ListNode cur = head;
//两个链表都要不为空
while(list1 != null && list2 != null){
//取较小值的节点
if(list1.val <= list2.val){
cur.next = list1;
//只移动取值的指针
list1 = list1.next;
}else{
cur.next = list2;
//只移动取值的指针
list2 = list2.next;
}
//指针后移
cur = cur.next;
}
//哪个链表还有剩,直接连在后面
if(list1 != null)
cur.next = list1;
else
cur.next = list2;
//返回值去掉表头
return head.next;
}
//划分合并区间函数
ListNode divideMerge(ArrayList<ListNode> lists, int left, int right){
if(left > right) return null;
//中间一个的情况
if(left == right) return lists.get(left);
//从中间分成两段,再将合并好的两段合并
int mid = (left + right) / 2;
return Merge(divideMerge(lists, left, mid), divideMerge(lists, mid + 1, right));
}
public ListNode mergeKLists(ArrayList<ListNode> lists) {
//k个链表归并排序
return divideMerge(lists, 0, lists.size() - 1);
}
}
用两个栈实现队列
(1)解法1:
public class Solution {
Stack<Integer> stack1 = new Stack<Integer>();
Stack<Integer> stack2 = new Stack<Integer>();
public void push(int node) {
stack1.push(node);
}
public int pop() {
if(stack2.isEmpty()){
while(!stack1.isEmpty()){
stack2.push(stack1.pop());
}
}
return stack2.pop();
}
}
(2)解法2:
public class Solution {
Stack<Integer> stack1 = new Stack<Integer>();
Stack<Integer> stack2 = new Stack<Integer>();
public void push(int node) {
while(!stack2.isEmpty()) {
stack1.push(stack2.pop());
}
stack2.push(node);
while(!stack1.isEmpty()) {
stack2.push(stack1.pop());
}
}
public int pop() {
return stack2.pop();
}
}
包含min函数的栈
import java.util.Stack;
public class Solution {
//用于栈的push 与 pop
Stack<Integer> s1 = new Stack<Integer>();
//用于存储最小min
Stack<Integer> s2 = new Stack<Integer>();
public void push(int node) {
s1.push(node);
//空或者新元素较小,则入栈
if(s2.isEmpty() || s2.peek() > node)
s2.push(node);
else
//重复加入栈顶
s2.push(s2.peek());
}
public void pop() {
s1.pop();
s2.pop();
}
public int top() {
return s1.peek();
}
public int min() {
return s2.peek();
}
}
有效括号序列
public boolean isValid (String s) {
//辅助栈
Stack<Character> st = new Stack<Character>();
//遍历字符串
for(int i = 0; i < s.length(); i++){
//遇到左小括号
if(s.charAt(i) == '(')
//期待遇到右小括号
st.push(')');
//遇到左中括号
else if(s.charAt(i) == '[')
//期待遇到右中括号
st.push(']');
//遇到左打括号
else if(s.charAt(i) == '{')
//期待遇到右打括号
st.push('}');
//必须有左括号的情况下才能遇到右括号
else if(st.isEmpty() || st.pop() != s.charAt(i))
return false;
}
//栈中是否还有元素
return st.isEmpty();
}
滑动窗口的最大值
public ArrayList<Integer> maxInWindows(int [] num, int size) {
ArrayList<Integer> res = new ArrayList<Integer>();
//窗口大于数组长度的时候,返回空
if (size <= 0 || size > num.length) {
return res;
}
//数组后面要空出窗口大小,避免越界
for (int i = 0; i <= num.length - size; i++) {
//寻找每个窗口最大值
int max = 0;
for (int j = i; j < i + size; j++) {
if (num[j] > max)
max = num[j];
}
res.add(max);
}
return res;
}
斐波那契数列
(1)递归
public int Fibonacci(int n) {
if(n<=1){
return n;
}
return Fibonacci(n-1) + Fibonacci(n-2);
}
(2) 迭代
public int Fibonacci (int n) {
if (n == 0 || n == 1) {
return n;
}
int sum = 1;
int one = 0;
for(int i=2; i<=n; i++) {
sum = sum + one;
one = sum - one;
}
return sum;
}
跳台阶
对于本题,前提只有 一次 1阶或者2阶的跳法。
a.如果两种跳法,1阶或者2阶,那么假定第一次跳的是一阶,那么剩下的是n-1个台阶,跳法是f(n-1);
b.假定第一次跳的是2阶,那么剩下的是n-2个台阶,跳法是f(n-2)
c.由a\b假设可以得出总跳法为: f(n) = f(n-1) + f(n-2)
d.然后通过实际的情况可以得出:只有一阶的时候 f(1) = 1 ,只有两阶的时候可以有 f(2) = 2
e.可以发现最终得出的是一个斐波那契数列:
| 1, (n=1)
f(n) = | 2, (n=2)
| f(n-1)+f(n-2) ,(n>2,n为整数)
(1)递归
public class Solution {
public int jumpFloor(int target) {
if (target <= 0) {return -1;}
if (target == 1) { return 1;}
if (target ==2) { return 2;}
return jumpFloor(target-1)+jumpFloor(target-2);
}
}
(2)迭代解法1
public class Solution {
// 状态转移方程 dp(n) = dp(n-1) + dp(n-2)
// 初始值dp(0) = 1 , dp(1) = 1
// 验证 dp(2) = dp(1) + dp(0) = 2
public int jumpFloor(int target) {
if (target <= 1) return 1;
int[] dp = new int[target+1];
dp[0] = 1;
dp[1] = 1;
for (int i = 2; i <= target; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[target];
}
}
(3)迭代解法2:
自底向上型循环求解,时间复杂度为 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HGnndKNE-1629356069694)(https://www.nowcoder.com/equation?tex=O(n)]&preview=true)
public class Solution {
public int JumpFloor(int target) {
// f[1] = 1, f[0] = 1 (f[0]是为了简便作答自己添加的)
int a = 1, b = 1;
for (int i = 2; i <= target; i++) {
// 求f[i] = f[i - 1] + f[i - 2]
a = a + b; // 这里求得的 f[i] 可以用于下次循环求 f[i+1]
// f[i - 1] = f[i] - f[i - 2]
b = a - b; // 这里求得的 f[i-1] 可以用于下次循环求 f[i+1]
}
return a;
}
}
自底向上求递推式的过程,该方法二原始的版本为:
public class Solution {
public int JumpFloor(int target) {
if (target <= 1) {
return 1;
}
// a 表示第 f[i-2] 项,b 表示第 f[i-1] 项
int a = 1, b = 1, c = 0;
for (int i = 2; i <= target; i++) {
c = a + b; // f[i] = f[i - 1] + f[i - 2];
// 为下一次循环求 f[i + 1] 做准备
a = b; // f[i - 2] = f[i - 1]
b = c; // f[i - 1] = f[i]
}
return c;
}
}
最小花费爬楼梯
public int minCostClimbingStairs (int[] cost) {
//dp[i]表示爬到第i阶楼梯需要的最小花费
int[] dp = new int[cost.length + 1];
for (int i = 2; i <= cost.length; i++)
//每次选取最小的方案
dp[i] = Math.min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]);
return dp[cost.length];
}
子数组的最大累加和问题
(1)动态规划
public int maxsumofSubarray (int[] arr) {
//1.dp状态设置: dp[i]就是以nums[i]为结尾的的连续子数组的最大和
int[] dp = new int[arr.length];
//2.初态设置:dp[0]必须包含nums[0] 所以:
dp[0] = arr[0];
int max = dp[0];
//3.转移方程:
//因为nums[i]无论如何都要包括 那么可以选择的余地就是dp[i-1]了
//dp[i-1]<0 那么不如只选nums[i]了 dp[i-1]>0 那就nums[i]带上dp[i-1]
for (int i = 1; i < arr.length; i++) {
dp[i] = dp[i-1]>0?dp[i-1]+arr[i]:arr[i];
//由于无论如何都要包括nums[i] 那么如果最后的nums[len-1]<0
//那么此时dp[len-1]肯定不是最大连续和 需要max筛选
max = Math.max(max,dp[i]);
}
return max;
}
(2)迭代
public int maxsumofSubarray (int[] arr) {
if(arr.length == 0) return 0;
int maxSum = 0;
int sum = 0;
for(int i = 0; i < arr.length; i++){
sum = sum + arr[i] > 0 ? sum + arr[i] : 0;
maxSum = maxSum > sum ? maxSum : sum;
}
return maxSum;
}
链表中的节点每k个一组翻转
(1)链表头插法import java.util.*;
public class Solution {
public ListNode reverseKGroup (ListNode head, int k) {
if(head==null||head.next==null||k==1) return head;
ListNode res = new ListNode(0);
res.next = head;
int length = 0;
ListNode pre = res,
cur = head,
temp = null;
while(head!=null){
length++;
head = head.next;
}
//分段使用头插法将链表反序
for(int i=0; i<length/k; i++){
//pre作为每一小段链表的头节点,负责衔接
for(int j=1; j<k; j++){
temp = cur.next;
cur.next = temp.next;
//相当于头插法,注意:
//temp.next = cur是错误的,temp需要连接的不是前一节点,而是子序列的头节点
temp.next = pre.next;
pre.next = temp;
}
//每个子序列反序完成后,pre,cur需要更新至下一子序列的头部
pre = cur;
cur = cur.next;
}
return res.next;
}
}
(2)迭代法
public ListNode reverseKGroup(ListNode head, int k) {
if (head == null || head.next == null){
return head;
}
//定义一个假的节点。
ListNode dummy=new ListNode(0);
//假节点的next指向head。
// dummy->1->2->3->4->5
dummy.next=head;
//初始化pre和end都指向dummy。pre指每次要翻转的链表的头结点的上一个节点。
//end指每次要翻转的链表的尾节点
ListNode pre=dummy;
ListNode end=dummy;
while(end.next!=null){
//循环k次,找到需要翻转的链表的结尾,这里每次循环要判断end是否等于空
//因为如果为空,end.next会报空指针异常。
//dummy->1->2->3->4->5 若k为2,循环2次,end指向2
for(int i=0;i<k&&end != null;i++){
end=end.next;
}
//如果end==null,即需要翻转的链表的节点数小于k,不执行翻转。
if(end==null){
break;
}
//先记录下end.next,方便后面链接链表
ListNode next=end.next;
//然后断开链表
end.next=null;
//记录下要翻转链表的头节点
ListNode start=pre.next;
//翻转链表,pre.next指向翻转后的链表。1->2 变成2->1。
//dummy->2->1
pre.next=reverse(start);
//翻转后头节点变到最后。通过.next把断开的链表重新链接。
start.next=next;
//将pre换成下次要翻转的链表的头结点的上一个节点。即start
pre=start;
//翻转结束,将end置为下次要翻转的链表的头结点的上一个节点。
//即start
end=start;
}
return dummy.next;
}
//链表翻转
// 例子: head: 1->2->3->4
public ListNode reverse(ListNode head) {
//单链表为空或只有一个节点,直接返回原单链表
if (head == null || head.next == null){
return head;
}
//前一个节点指针
ListNode preNode = null;
//当前节点指针
ListNode curNode = head;
//下一个节点指针
ListNode nextNode = null;
while (curNode != null){
nextNode = curNode.next;
//nextNode 指向下一个节点,保存当前节点后面的链表。
curNode.next=preNode;
//将当前节点next域指向前一个节点 null<-1<-2<-3<-4
preNode = curNode;
//preNode 指针向后移动。preNode指向当前节点。
curNode = nextNode;
//curNode指针向后移动。下一个节点变成当前节点
}
return preNode;
}
(3)递归
1、找到待翻转的k个节点(注意:若剩余数量小于 k 的话,则不需要反转,因此直接返回待翻转部分的头结点即可)。
2、对其进行翻转。并返回翻转后的头结点(注意:翻转为左闭又开区间,所以本作的尾结点其实就是下一作的头结点)。
3、对下一轮 k 个节点也进行翻转操作。
4、将上一轮翻转后的尾结点指向下一轮翻转后的头节点,即将每一轮翻转的k的节点连接起来。

写法1:
public ListNode reverseKGroup(ListNode head, int k) {
if (head == null || head.next == null) {
return head;
}
ListNode tail = head;
for (int i = 0; i < k; i++) {
//剩余数量小于k的话,则不需要反转。
if (tail == null) {
return head;
}
tail = tail.next;
}
// 反转前 k 个元素
ListNode newHead = reverse(head, tail);
//下一轮的开始的地方就是tail
head.next = reverseKGroup(tail, k);
return newHead;
}
/*
左闭又开区间
*/
private ListNode reverse(ListNode head, ListNode tail) {
ListNode pre = null;
ListNode next = null;
while (head != tail) {
next = head.next;
head.next = pre;
pre = head;
head = next;
}
return pre;
}
写法2:使用栈翻转
public class Solution {
public ListNode reverseKGroup (ListNode head, int k) {
// write code here
//使用一个栈来反转每段链表
Stack<ListNode> stack = new Stack<ListNode>();
ListNode cur = head;
for(int i = 0;i<k;i++){
if(cur == null){
//如果这段链表长度不够k,则直接返回这个链表
return head;
}
stack.push(cur);
cur = cur.next;
}
//根据栈中的节点构造链表,构造出来的是原来链表的反转
ListNode res = stack.pop();
ListNode temp = res;
while(!stack.isEmpty()){
temp.next = stack.pop();
temp = temp.next;
}
//反转后的链表的尾节点是递归返回的头节点
temp.next = reverseKGroup(cur,k);
return res;
}
}
反转字符串
(1)
public String solve (String str) {
char[] ans = str.toCharArray();
int len = str.length();
for(int i = 0 ; i < len ;i++){
ans[i] = str.charAt(len-1-i);
}
return new String(ans);
}
(2)
public String solve (String str) {
StringBuffer sb = new StringBuffer(str);
return sb.reverse().toString();
}
最长无重复子数组
(1)方法一:滑动窗口法
我们可以利用双指针模拟一个滑动窗口。初始化该窗口为(left, right]。所以left从-1开始。窗口不断往右扩大。因为我们要的是无重复子数组,因此,遇到有重复的数字,在窗口左侧进行缩小。
在每次滑动时,对窗口的大小进行比较,保留最大的长度。
import java.util.*;
public class Solution {
public int maxLength (int[] arr) {
if(arr.length < 2){
return arr.length;
}
HashMap<Integer, Integer> windows = new HashMap<>();
int res = 0;
//用双指针来模拟一个滑动窗口
int left = -1;
//窗口向右滑动
for(int right = 0; right < arr.length; right++){
//遇到重复数字
if(windows.containsKey(arr[right])){
//因为有可能遇到的重复数字的位置 比 left还要前
//所以不能把left置于该位置前一位, 而是比较哪个最大,目的还是为了缩小窗口
//确保窗口内全是不重复的数字
left = Math.max(left, windows.get(arr[right]));
}
//每次更新窗口大小
res = Math.max(res, right-left);
//将数字位置更新到windows中
windows.put(arr[right], right);
}
return res;
}
}
(2)方法二:双指针 + 回头遍历
定义双指针, right指针对数组进行遍历,left指针对arr[right]前的子数组进行遍历。当left小于0或者遇到重复数字时,终止left遍历。
定义res代表最长的长度,tmp代表当前字符拥有的子串长度。
每次更新tmp时,也得更新res。
import java.util.*;
public class Solution {
public int maxLength (int[] arr) {
// write code here
int res = 0, tmp = 0;
for(int right = 0; right < arr.length; right++){
int left = right -1;
//回头遍历
while(left >= 0 && arr[right] != arr[left]){
left --;
}
//若指针距离比上一个字符拥有的子串长度要大,就tmp+1 否则说明,遇到了重复数字,设置为新的指针距离,方便下一步res比较
tmp = tmp < right - left ? tmp + 1 : right - left;
//更新res指
res = Math.max(res, tmp);
}
return res;
}
}
判断链表中是否有环
(1)快慢指针解决
判断链表是否有环应该是老生常谈的一个话题了,最简单的一种方式就是快慢指针,慢指针针每次走一步,快指针每次走两步,如果相遇就说明有环,如果有一个为空说明没有环
public boolean hasCycle(ListNode head) {
if (head == null)
return false;
//快慢两个指针
ListNode slow = head;
ListNode fast = head;
while (fast != null && fast.next != null) {
//慢指针每次走一步
slow = slow.next;
//快指针每次走两步
fast = fast.next.next;
//如果相遇,说明有环,直接返回true
if (slow == fast)
return true;
}
//否则就是没环
return false;
}
写法2:
/**
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
/**
判断链表是否有环,用快慢指针
*/
public boolean hasCycle(ListNode head) {
ListNode fast = head, slow = head;
while(slow != null && fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
// 判断是否重合
if(slow == fast) {
return true;
}
}
return false;
}
}
(2)逐个删除
一个链表从头节点开始一个个删除,所谓删除就是让他的next指针指向他自己。如果没有环,从头结点一个个删除,最后肯定会删完。如果是环形的,那么有两种情况,一种是o型的,一种是6型的。
public boolean hasCycle(ListNode head) {
//如果head为空,或者他的next指向为空,直接返回false
if (head == null || head.next == null)
return false;
//如果出现head.next = head表示有环
if (head.next == head)
return true;
ListNode nextNode = head.next;
//当前节点的next指向他自己,相当于把它删除了
head.next = head;
//然后递归,查看下一个节点
return hasCycle(nextNode);
}
合并两个有序的数组
(1)插入排序
public class Solution {
public void merge(int A[], int m, int B[], int n) {
// 插入排序
int i=0;
int j=0;
while(i<m+n && j<n){
if(A[i]>B[j]){
// i以及i之后的往后移动
for(int cur=m+n-1;cur>i;cur--){
A[cur]=A[cur-1];
}
A[i]=B[j];
j++;
i++;
}else{i++;}
}
// 如果剩余的B大于A的最大值
for(int q=j;q<n;q++){
A[m+q]=B[q];
}
}
}
(2)归并排序
public class Solution {
public void merge(int A[], int m, int B[], int n) {
int[] result=new int[m+n];
int t=0;
int i=0,j=0;
while(i<m&&j<n){
if(A[i]<=B[j]){//两边有序数组相互比较得出小的元素依次存放
result[t++]=A[i++];
}else{
result[t++]=B[j++];
}
}
//将剩余元素依次存放在result数组中
while(i<m){//左边数组A如果还有剩余元素,全部存放在result数组中
result[t++]=A[i++];
}
while(j<n){//右边数组B如果还有剩余元素,全部存放在result数组中
result[t++]=B[j++];
}
for(int sum=0;sum<result.length;sum++){//最后通过遍历将result数组元素存放到A数组中
A[sum]=result[sum];
}
}
}
(3)双指针
/***
*整体类比ArrayList中add操作的数组移动
*比较后用System.arraycopy()函数
****/
public class Solution {
public void merge(int A[], int m, int B[], int n) {
int a = 0;
int b = 0;
while(b < n){
if(a >= m || B[b] <= A[a]){
System.arraycopy(A , a, A, a+1, m-a);
m++;
A[a++] = B[b++];
}else{
a++;
}
}
}
}
(4)使用集合
- 保证 A 数组有足够的空间存放 B 数组的元素, A 和 B 中初始的元素数目分别为 m 和 n,A的数组空间大小为 m+n
- A 数组在[0,m-1]的范围也是有序的
public void merge(int A[], int m, int B[], int n) {
for (int i = 0; i < n; i++) {
A[m + i] = B[i];
}
Arrays.sort(A);
}
判断是否为回文字符串
(1) 双指针
public boolean judge (String str) {
//首指针
int left = 0;
//尾指针
int right = str.length() - 1;
//首尾往中间靠
while(left < right){
//比较前后是否相同
if(str.charAt(left) != str.charAt(right))
return false;
left++;
right--;
}
return true;
}
(2)反转
public boolean judge (String str) {
StringBuffer temp = new StringBuffer(str);
//反转字符串
String s = temp.reverse().toString();
//比较字符串是否相等
if(s.equals(str))
return true;
return false;
}
合并区间
public ArrayList<Interval> merge(ArrayList<Interval> intervals) {
Collections.sort(intervals, (v1, v2) -> v1.start - v2.start);
ArrayList<Interval> result = new ArrayList<Interval>();
int index = -1;
for (Interval interval : intervals) {
if (index == - 1 || interval.start > result.get(index).end) {
// 区间 [a,b] [c,d] c 大于 b的话
result.add(interval);
index ++ ;
} else {
//如果 c 大于 b 那么就需要找一个最大的作为 右边的边界 因为数据start都从左到右排好序了
result.get(index).end = Math.max(interval.end, result.get(index).end);
}
}
return result;
}
最小覆盖子串
import java.util.*;
public class Solution {
//检查是否有小于0的
boolean check(int[] hash) {
for (int i = 0; i < hash.length; i++) {
if (hash[i] < 0)
return false;
}
return true;
};
public String minWindow (String S, String T) {
int cnt = S.length() + 1;
//记录目标字符串T的字符个数
int[] hash = new int[128];
for(int i = 0; i < T.length(); i++)
//初始化哈希表都为负数,找的时候再加为正
hash[T.charAt(i)] -= 1;
int slow = 0, fast = 0;
//记录左右区间
int left = -1, right = -1;
for(; fast < S.length(); fast++){
char c = S.charAt(fast);
//目标字符匹配+1
hash[c]++;
//没有小于0的说明都覆盖了,缩小窗口
while(check(hash)){
//取最优解
if(cnt > fast - slow + 1){
cnt = fast - slow + 1;
left = slow;
right = fast;
}
c = S.charAt(slow);
//缩小窗口的时候减1
hash[c]--;
//窗口缩小
slow++;
}
}
//找不到的情况
if(left == -1)
return "";
return S.substring(left, right + 1);
}
}
链表中环的入口结点
(1) 指针判断
思路:1.判断链表中有环 -> 2.得到环中节点的数目 -> 3.找到环中的入口节点
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public ListNode EntryNodeOfLoop(ListNode pHead)
{
if(pHead == null){
return null;
}
// 1.判断链表中有环
ListNode l=pHead,r=pHead;
boolean flag = false;
while(r != null && r.next!=null){
l=l.next;
r=r.next.next;
if(l==r){
flag=true;
break;
}
}
if(!flag){
return null;
}else{
// 2.得到环中节点的数目
int n=1;
r=r.next;
while(l!=r){
r=r.next;
n++;
}
// 3.找到环中的入口节点
l=r=pHead;
for(int i=0;i<n;i++){
r=r.next;
}
while(l!=r){
l=l.next;
r=r.next;
}
return l;
}
}
}
写法2:
public class Solution {
public ListNode EntryNodeOfLoop(ListNode pHead) {
if(pHead == null || pHead.next == null) {
return null;
}
ListNode slow = pHead;
ListNode fast = pHead;
while(fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
if(slow == fast) {
ListNode p = pHead;
while(p != slow) {
p = p.next;
slow = slow.next;
}
return p;
}
}
return null;
}
}
(2)使用集合
写法1:
public ListNode EntryNodeOfLoop(ListNode pHead) {
//方法一:利用Map
Map<ListNode,Integer> map = new HashMap();
ListNode node = pHead;
while (node != null){
map.put(node,map.getOrDefault(node,0) + 1);
if (map.get(node) > 1) return node;
//或:if (map.get(node) == 2) return node; //一个意思
node = node.next;
}
return null;
}
写法2:
public ListNode EntryNodeOfLoop(ListNode pHead) {
//方法二:利用Set
Set<ListNode> set = new HashSet();
while(pHead != null){
if(set.contains(pHead)) return pHead;
else set.add(pHead);
pHead = pHead.next;
}
return null;
}
括号序列
(1)压栈和取栈'(','[','{' 这三个就压栈
')',']','}' 这三个就取栈,取栈时判断一下是不是对应的括号,如果是就取栈成功,不是就不能取。
这样最后看栈是不是为空,不为空就说明顺序不正确
public boolean isValid (String s) {
//遇到括号匹配这样的题,首选使用栈来做
//每次遍历遇到'('、'['和'{'时,就将其对应的方括号')'、']'和'}'放入栈中
//然后遍历下一个,并与栈顶元素进行比较
//如果不同直接返回false;如果相同就将栈顶的反括号弹出,遍历结束都没有返回false就说明合法,返回true
Stack<Character> stack = new Stack<>();
char[] temp = s.toCharArray();
for (char c : temp){//遍历字符,如果遇到左括号,就把相应的右括号压入栈顶
if (c == '(') stack.push(')');
else if (c == '[') stack.push(']');
else if (c == '{') stack.push('}');
//else if (stack.isEmpty()) return false;//字符还没有遍历完就出现栈为空就返回false
//else if (stack.pop() != c) return false;//如果能到达这一步,就每次从栈顶pop出一个元素与当前元素c
//进行比较,如果不同就返回false
//也可以将上面两行代码合并:
else if (stack.isEmpty() || stack.pop() != c) return false;
}
return stack.isEmpty();//遍历结束如果栈为空就返回true,否则返回false
}
(2)字符替换
public boolean isValid (String s) {
boolean flag = true;
while(flag){
int len = s.length();
s=s.replace("()","");
s=s.replace("[]","");
s=s.replace("{}","");
if(len == s.length()){
flag=false;
}
}
return s.length() == 0;
}
链表中倒数最后k个结点
(1)快慢双指针
import java.util.*;
public class Solution {
public ListNode FindKthToTail (ListNode pHead, int k) {
int n = 0;
ListNode fast = pHead;
ListNode slow = pHead;
//快指针先行k步
for(int i = 0; i < k; i++){
if(fast != null)
fast = fast.next;
//达不到k步说明链表过短,没有倒数k
else
return slow = null;
}
//快慢指针同步,快指针先到底,慢指针指向倒数第k个
while(fast != null){
fast = fast.next;
slow = slow.next;
}
return slow;
}
}
(2) 先找长度再找最后k
import java.util.*;
public class Solution {
public ListNode FindKthToTail (ListNode pHead, int k) {
int n = 0;
ListNode p = pHead;
//遍历链表,统计链表长度
while(p != null){
n++;
p = p.next;
}
//长度过小,返回空链表
if(n < k)
return null;
p = pHead;
//遍历n-k次
for(int i = 0; i < n - k; i++)
p = p.next;
return p;
}
}
删除链表的倒数第n个节点
(1)先得到链表的长度,然后删除倒数第n个结点
public class Solution {
/**
*
* @param head ListNode类
* @param n int整型
* @return ListNode类
*/
public ListNode removeNthFromEnd (ListNode head, int n) {
ListNode cur = head;
if (head == null || head.next == null) return null;
List<ListNode> list = new ArrayList<>();
while (cur != null) {
list.add(cur);
cur = cur.next;
}
list.remove(list.size() - n);
ListNode resNode = list.get(0);
ListNode temp = resNode;
for (int i = 1; i < list.size(); i++) {
temp.next = list.get(i);
temp = temp.next;
}
temp.next = null;
return resNode;
}
}
(2)方法二:快慢指针
public ListNode removeNthFromEnd(ListNode head, int n) {
// write code here
if (head == null) {
return head;
}
ListNode left = head;
ListNode right = head;
//right指针先走n步
for (int i = 0; i < n; i++) {
right = right.next;
}
//此时right可能为null 把头节点删除
if (right == null) {
head = head.next;
return head;
}
//遍历,直至right.next为null,此时right就是链表的最后一个节点
while (right.next != null) {
left = left.next;
right = right.next;
}
//那么left.next就是需要删除的node
//target.next至少为right,所以不可能为null
//此时只需要把target节点删除即可
ListNode target = left.next;
left.next = target.next;
target.next = null;
return head;
}
字符串变形
import java.util.*;
public class Solution {
public String trans(String s, int n) {
if (n == 0) return s;
StringBuffer res = new StringBuffer();
for (int i = 0; i < n; i++) {
//大小写转换
if (s.charAt(i) <= 'Z' && s.charAt(i) >= 'A')
res.append((char)(s.charAt(i) - 'A' + 'a'));
else if (s.charAt(i) >= 'a' && s.charAt(i) <= 'z')
res.append((char)(s.charAt(i) - 'a' + 'A'));
else
//空格直接复制
res.append(s.charAt(i));
}
//翻转整个字符串
res = res.reverse();
for (int i = 0; i < n; i++) {
int j = i;
//以空格为界,二次翻转
while (j < n && res.charAt(j) != ' ')
j++;
String temp = res.substring(i, j);
StringBuffer buffer = new StringBuffer(temp);
temp = buffer.reverse().toString();
res.replace(i, j, temp);
i = j;
}
return res.toString();
}
}
最长公共前缀
public String longestCommonPrefix (String[] strs) {
// //纵向扫描
if (strs.length == 0 || strs == null) {
return "";
}
int rows = strs.length;
int cols = strs[0].length();
//开始扫描
for (int i = 0; i < cols; i++) {
char firstChar = strs[0].charAt(i);
for (int j = 1; j < rows; j++) {
if (strs[j].length() == i || strs[j].charAt(i) != firstChar) {
return strs[0].substring(0, i);
}
}
}
return strs[0];
}
验证IP地址
public class Solution {
public String solve(String IP) {
return validIPv4(IP) ? "IPv4" : (validIPv6(IP) ? "IPv6" : "Neither");
}
private boolean validIPv4(String IP) {
String[] strs = IP.split("\\.", -1);
if (strs.length != 4) {
return false;
}
for (String str : strs) {
if (str.length() > 1 && str.startsWith("0")) {
return false;
}
try {
int val = Integer.parseInt(str);
if (!(val >= 0 && val <= 255)) {
return false;
}
} catch (NumberFormatException numberFormatException) {
return false;
}
}
return true;
}
private boolean validIPv6(String IP) {
String[] strs = IP.split(":", -1);
if (strs.length != 8) {
return false;
}
for (String str : strs) {
if (str.length() > 4 || str.length() == 0) {
return false;
}
try {
int val = Integer.parseInt(str, 16);
} catch (NumberFormatException numberFormatException) {
return false;
}
}
return true;
}
}
大数加法
(1)从尾部插入public String solve(String s, String t) {
StringBuilder stringBuilder = new StringBuilder();
int i = s.length() - 1, j = t.length() - 1, carry = 0;
while (i >= 0 || j >= 0 || carry != 0) {
int x = i < 0 ? 0 : s.charAt(i--) - '0';
int y = j < 0 ? 0 : t.charAt(j--) - '0';
int sum = x + y + carry;
stringBuilder.append(sum % 10);//添加到字符串尾部
carry = sum / 10;
}
return stringBuilder.reverse().toString();//对字符串反转
}
(2)从头部插入
public String solve(String s, String t) {
StringBuilder stringBuilder = new StringBuilder();
int carry = 0, i = s.length() - 1, j = t.length() - 1;
while (i >= 0 || j >= 0 || carry != 0) {
int x = i < 0 ? 0 : s.charAt(i--) - '0';
int y = j < 0 ? 0 : t.charAt(j--) - '0';
int sum = x + y + carry;
stringBuilder.insert(0, sum % 10);//插入到s字符串的第一个位置
carry = sum / 10;
}
return stringBuilder.toString();
}
(3) 使用栈来解决
public String solve(String s, String t) {
Stack<Integer> stack = new Stack<>();
StringBuilder stringBuilder = new StringBuilder();
int i = s.length() - 1, j = t.length() - 1, carry = 0;
while (i >= 0 || j >= 0 || carry != 0) {
carry += i >= 0 ? s.charAt(i--) - '0' : 0;
carry += j >= 0 ? t.charAt(j--) - '0' : 0;
stack.push(carry % 10);
carry = carry / 10;
}
while (!stack.isEmpty())
stringBuilder.append(stack.pop());
return stringBuilder.toString();
}
按之字形顺序打印二叉树
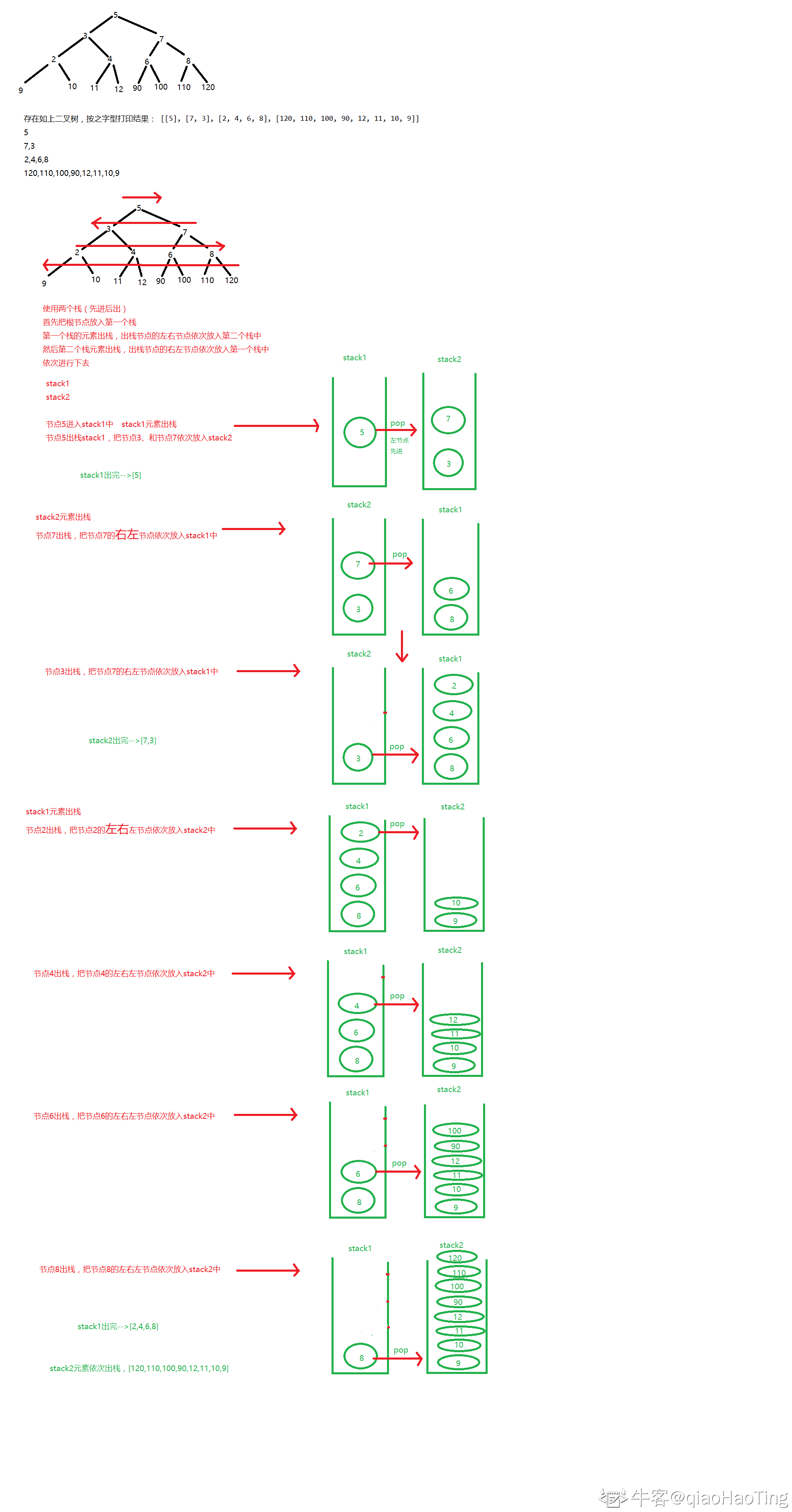
(1)队列+List
//解题思路:其实就是二叉树的层级遍历,不过是在遍历的时候,需要将偶数层的节点逆序。
//关键点:每次只处理上次在queue中剩余的节点,这是上一层的所有节点。
// 处理完后刚好将下一层的所有节点(包含null)又全部放了进去。
public ArrayList<ArrayList<Integer> > Print(TreeNode pRoot) {
ArrayList<ArrayList<Integer> > result=new ArrayList<>();
if(pRoot==null){
return result;
}
Queue<TreeNode> queue=new LinkedList<TreeNode>();
queue.offer(pRoot);
boolean reverse=false;
while(!queue.isEmpty()){
int size=queue.size();
ArrayList<Integer> list=new ArrayList<>();
for(int i=0;i<size;i++){
TreeNode node=queue.poll();
if(node==null){
continue;
}
if(!reverse){
list.add(node.val);
}else{
list.add(0,node.val);//每次加到0的位置,就自动逆序了
}
queue.offer(node.left);
queue.offer(node.right);
}
if(list.size()>0){
result.add(list);
}
reverse=!reverse;
}
return result;
}
写法2:
//方法2和方法1相比,代码区别仅仅是把stack相关删去,然后换成ArrayList头插法
//时间、空间都是 O(N)
public class Solution {
public ArrayList<ArrayList<Integer> > Print(TreeNode pRoot) {
ArrayList<ArrayList<Integer>> res = new ArrayList<ArrayList<Integer>>();
if(pRoot == null)return res;
ArrayList<TreeNode> queue = new ArrayList<TreeNode>();
queue.add(pRoot);
int layer = 1;
while(!queue.isEmpty()){
ArrayList<Integer> list = new ArrayList<Integer>();
int size = queue.size();
for(int i=0; i<=size-1; ++i){
TreeNode node = queue.get(0);
queue.remove(0);
if(layer % 2 == 1){
list.add(node.val);
}
else{
list.add(0,node.val);//头插法,逆序 //【代码简洁,但效率比Stack低】
}
if(node.left != null)queue.add(node.left);
if(node.right != null)queue.add(node.right);
}
res.add(list);
++layer;
}
return res;
}
}
(2)队列+栈
public class Solution {
public ArrayList<ArrayList<Integer> > Print(TreeNode pRoot) {
ArrayList<ArrayList<Integer>> res = new ArrayList<ArrayList<Integer>>();
if(pRoot == null)return res;
Stack<Integer> stack = new Stack<Integer>();//stack仅用于偶数层翻转val
ArrayList<TreeNode> queue = new ArrayList<TreeNode>();//queue是奇偶共用
queue.add(pRoot);
int layer = 1;//层数用layer (区别于深度depth = layer-1)
while(!queue.isEmpty()){
ArrayList<Integer> list = new ArrayList<Integer>();//新建行
int size = queue.size();//出本层前记录size,不然难以做到层数的切分 //提前写出来,因为size会变
for(int i=0; i<=size-1; ++i){
TreeNode node = queue.get(0);//一定要新建node副本,不然是引用会变
queue.remove(0);
if(layer % 2 == 1){
list.add(node.val);
} else{//偶数行,需要栈翻转
stack.push(node.val);
}
if(node.left != null)queue.add(node.left);
if(node.right != null)queue.add(node.right);
}
while(!stack.isEmpty()){
list.add(stack.pop());//偶数层一次性添加,奇数层一个个添加
}
res.add(list);
++layer;//本层结束,层数加一
}
return res;
}
}//时间、空间复杂度,都是树的规模 O(N)
二叉树的最大深度
(1) 递归
public int maxDepth(TreeNode root) {
if(root == null) return 0;
//返回子树深度+1
return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;
}
(2) BFS队列
public int maxDepth(TreeNode root) {
if (root == null)
return 0;
//创建一个队列
Deque<TreeNode> deque = new LinkedList<>();
deque.push(root);
int count = 0;
while (!deque.isEmpty()) {
//每一层的个数
int size = deque.size();
while (size-- > 0) {
TreeNode cur = deque.pop();
if (cur.left != null)
deque.addLast(cur.left);
if (cur.right != null)
deque.addLast(cur.right);
}
count++;
}
return count;
}
(3) DFS栈
public int maxDepth(TreeNode root) {
if (root == null)
return 0;
//stack记录的是节点,而level中的元素和stack中的元素
//是同时入栈同时出栈,并且level记录的是节点在第几层
Stack<TreeNode> stack = new Stack<>();
Stack<Integer> level = new Stack<>();
stack.push(root);
level.push(1);
int max = 0;
while (!stack.isEmpty()) {
//stack中的元素和level中的元素同时出栈
TreeNode node = stack.pop();
int temp = level.pop();
max = Math.max(temp, max);
if (node.left != null) {
//同时入栈
stack.push(node.left);
level.push(temp + 1);
}
if (node.right != null) {
//同时入栈
stack.push(node.right);
level.push(temp + 1);
}
}
return max;
}
二叉树中和为某一值的路径(一)
(1) 递归
public boolean hasPathSum (TreeNode root, int sum) {
//空节点找不到路径
if(root == null)
return false;
//叶子节点,且路径和为sum
if(root.left == null && root.right == null && sum - root.val == 0)
return true;
//递归进入子节点
return hasPathSum(root.left, sum - root.val) || hasPathSum(root.right, sum - root.val);
}
(2)DFS 栈
public boolean hasPathSum(TreeNode root, int sum) {
if (root == null)
return false;
Stack<TreeNode> stack = new Stack<>();
stack.push(root);//根节点入栈
while (!stack.isEmpty()) {
TreeNode cur = stack.pop();//出栈
//累加到叶子节点之后,结果等于sum,说明存在这样的一条路径
if (cur.left == null && cur.right == null && cur.val == sum) {
return true;
}
//右子节点累加,然后入栈
if (cur.right != null) {
cur.right.val = cur.val + cur.right.val;
stack.push(cur.right);
}
//左子节点累加,然后入栈
if (cur.left != null) {
cur.left.val = cur.val + cur.left.val;
stack.push(cur.left);
}
}
return false;
}
二叉搜索树与双向链表
(1) 递归
public class Solution {
//返回的第一个指针,即为最小值,先定为null
public TreeNode head = null;
//中序遍历当前值的上一位,初值为最小值,先定为null
public TreeNode pre = null;
public TreeNode Convert(TreeNode pRootOfTree) {
if(pRootOfTree == null)
//中序递归,叶子为空则返回
return null;
//首先递归到最左最小值
Convert(pRootOfTree.left);
//找到最小值,初始化head与pre
if(pre == null){
head = pRootOfTree;
pre = pRootOfTree;
} else {
//当前节点与上一节点建立连接,将pre设置为当前值
pre.right = pRootOfTree;
pRootOfTree.left = pre;
pre = pRootOfTree;
}
Convert(pRootOfTree.right);
return head;
}
}
(2) 使用栈
import java.util.*;
public class Solution {
public TreeNode Convert(TreeNode pRootOfTree) {
if (pRootOfTree == null)
return null;
//设置栈用于遍历
Stack<TreeNode> s = new Stack<TreeNode>();
TreeNode head = null;
TreeNode pre = null;
//确认第一个遍历到最左,即为首位
boolean isFirst = true;
while(pRootOfTree != null || !s.isEmpty()){
//直到没有左节点
while(pRootOfTree != null){
s.push(pRootOfTree);
pRootOfTree = pRootOfTree.left;
}
pRootOfTree = s.pop();
//最左元素即表头
if(isFirst){
head = pRootOfTree;
pre = head;
isFirst = false;
} else{
//当前节点与上一节点建立连接,将pre设置为当前值
pre.right = pRootOfTree;
pRootOfTree.left = pre;
pre = pRootOfTree;
}
pRootOfTree = pRootOfTree.right;
}
return head;
}
}
对称的二叉树
(1) 递归
public class Solution {
boolean recursion(TreeNode root1, TreeNode root2){
//可以两个都为空
if(root1 == null && root2 == null) return true;
//只有一个为空或者节点值不同,必定不对称
if(root1 == null || root2 == null || root1.val != root2.val) return false;
//每层对应的节点进入递归比较
return recursion(root1.left, root2.right) && recursion(root1.right, root2.left);
}
boolean isSymmetrical(TreeNode pRoot) {
return recursion(pRoot, pRoot);
}
}
(2)使用队列
import java.util.*;
public class Solution {
boolean isSymmetrical(TreeNode pRoot) {
//空树为对称的
if(pRoot == null)
return true;
//辅助队列用于从两边层次遍历
Queue<TreeNode> q1 = new LinkedList<TreeNode>();
Queue<TreeNode> q2 = new LinkedList<TreeNode>();
q1.offer(pRoot.left);
q2.offer(pRoot.right);
while(!q1.isEmpty() && !q2.isEmpty()){
//分别从左边和右边弹出节点
TreeNode left = q1.poll();
TreeNode right = q2.poll();
//都为空暂时对称
if(left == null && right == null)
continue;
//某一个为空或者数字不相等则不对称
if(left == null || right == null || left.val != right.val)
return false;
//从左往右加入队列
q1.offer(left.left);
q1.offer(left.right);
//从右往左加入队列
q2.offer(right.right);
q2.offer(right.left);
}
//都检验完都是对称的
return true;
}
}
合并二叉树
(1)递归
public TreeNode mergeTrees (TreeNode t1, TreeNode t2) {
//若只有一个节点返回另一个,两个都为null自然返回null
if (t1 == null) return t2;
if (t2 == null) return t1;
//根左右的方式递归
TreeNode head = new TreeNode(t1.val + t2.val);
head.left = mergeTrees(t1.left, t2.left);
head.right = mergeTrees(t1.right, t2.right);
return head;
}
(2)使用队列
import java.util.*;
public class Solution {
public TreeNode mergeTrees (TreeNode t1, TreeNode t2) {
//若只有一个节点返回另一个,两个都为null自然返回null
if (t1 == null) return t2;
if (t2 == null) return t1;
//合并根节点
TreeNode head = new TreeNode(t1.val + t2.val);
//连接后的树的层次遍历节点
Queue<TreeNode> q = new LinkedList<TreeNode>();
//分别存两棵树的层次遍历节点
Queue<TreeNode> q1 = new LinkedList<TreeNode>();
Queue<TreeNode> q2 = new LinkedList<TreeNode>();
q.offer(head);
q1.offer(t1);
q2.offer(t2);
while (!q1.isEmpty() && !q2.isEmpty()) {
TreeNode node = q.poll();
TreeNode node1 = q1.poll();
TreeNode node2 = q2.poll();
TreeNode left1 = node1.left;
TreeNode left2 = node2.left;
TreeNode right1 = node1.right;
TreeNode right2 = node2.right;
if(left1 != null || left2 != null){
//两个左节点都存在
if(left1 != null && left2 != null){
TreeNode left = new TreeNode(left1.val + left2.val);
node.left = left;
//新节点入队列
q.offer(left);
q1.offer(left1);
q2.offer(left2);
//只连接一个节点
}else if(left1 != null)
node.left = left1;
else
node.left = left2;
}
if(right1 != null || right2 != null){
//两个右节点都存在
if(right1 != null && right2 != null) {
TreeNode right = new TreeNode(right1.val + right2.val);
node.right = right;
//新节点入队列
q.offer(right);
q1.offer(right1);
q2.offer(right2);
//只连接一个节点
}else if(right1 != null)
node.right = right1;
else
node.right = right2;
}
}
return head;
}
}
二叉树的镜像
(1) 递归
public TreeNode Mirror(TreeNode root) {
if (root == null) return null;
TreeNode left = Mirror(root.left);
TreeNode right = Mirror(root.right);
root.left = right;
root.right = left;
return root;
}
(2)使用栈DFS
public TreeNode Mirror(TreeNode root) {
//如果为空直接返回
if (root == null)
return null;
//栈
Stack<TreeNode> stack = new Stack<>();
//根节点压栈
stack.push(root);
//如果栈不为空就继续循环
while (!stack.empty()) {
//出栈
TreeNode node = stack.pop();
//子节点交换
TreeNode temp = node.left;
node.left = node.right;
node.right = temp;
//左子节点不为空入栈
if (node.left != null)
stack.push(node.left);
//右子节点不为空入栈
if (node.right != null)
stack.push(node.right);
}
return root;
}
(3)使用队列BFS
public TreeNode Mirror(TreeNode root) {
//如果为空直接返回
if (root == null) return null;
//队列
final Queue<TreeNode> queue = new LinkedList<>();
//首先把根节点加入到队列中
queue.add(root);
while (!queue.isEmpty()) {
//poll方法相当于移除队列头部的元素
TreeNode node = queue.poll();
//交换node节点的两个子节点
TreeNode left = node.left;
node.left = node.right;
node.right = left;
//如果当前节点的左子树不为空,就把左子树
//节点加入到队列中
if (node.left != null) {
queue.add(node.left);
}
//如果当前节点的右子树不为空,就把右子树
//节点加入到队列中
if (node.right != null) {
queue.add(node.right);
}
}
return root;
}
判断是不是二叉搜索树
(1) 递归
import java.util.*;
public class Solution {
int pre = Integer.MIN_VALUE;
//中序遍历
public boolean isValidBST (TreeNode root) {
if (root == null) return true;
//先进入左子树
if(!isValidBST(root.left)) return false;
if(root.val < pre) return false;
//更新最值
pre = root.val;
//再进入右子树
return isValidBST(root.right);
}
}
(2)使用栈
import java.util.*;
public class Solution {
public boolean isValidBST(TreeNode root){
//设置栈用于遍历
Stack<TreeNode> s = new Stack<TreeNode>();
TreeNode head = root;
//记录中序遍历的数组
ArrayList<Integer> list = new ArrayList<Integer>();
while(head != null || !s.isEmpty()){
//直到没有左节点
while(head != null){
s.push(head);
head = head.left;
}
head = s.pop();
//访问节点
list.add(head.val);
//进入右边
head = head.right;
}
//遍历中序结果
for(int i = 1; i < list.size(); i++){
//一旦有降序,则不是搜索树
if(list.get(i - 1) > list.get(i))
return false;
}
return true;
}
}
判断是不是完全二叉树
(1) 递归DFS
完全二叉树有下面公式,如果某个节点索引是i,那么他的左右子节点为(索引从1开始)
left=2∗i
right=2∗i+1
public class Solution {
int ans = 0;
int dfs(TreeNode root, int idx){
if(root == null) return 0;
ans = Math.max(ans, idx);
//遍历左右子树
return 1 + dfs(root.left, idx * 2) + dfs(root.right, idx * 2 + 1);
}
public boolean isCompleteTree (TreeNode root) {
// dfs判断节点的序号是否等于编号
return dfs(root, 1) == ans;
}
}
(2)使用队列
public boolean isCompleteTree (TreeNode root) {
if(root == null) return true;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
boolean left = true;
while(!queue.isEmpty()){
TreeNode nowNode = queue.poll();
//说明当前节点是空节点
if(nowNode == null){
left = false;
} else {
// 遇到空节点直接返回false
if(left == false)
return false;
queue.offer(nowNode.left);
queue.offer(nowNode.right);
}
}
return true;
}
判断是不是平衡二叉树
(1) 递归
public class Solution {
public boolean IsBalanced_Solution(TreeNode root) {
if (root == null) return true;
//判断左子树和右子树是否符合规则,且深度不能超过2
return IsBalanced_Solution(root.left) &&
IsBalanced_Solution(root.right) &&
Math.abs(deep(root.left) - deep(root.right)) < 2;
}
//判断二叉树深度
public int deep(TreeNode root) {
if (root == null) return 0;
return Math.max(deep(root.left), deep(root.right)) + 1;
}
}
(2)回溯法
public class Solution {
public boolean IsBalanced_Solution(TreeNode root) {
if (deep(root) == -1) return false;
return true;
}
public int deep(TreeNode node) {
if (node == null) return 0;
int left = deep(node.left);
if (left == -1 ) return -1;
int right = deep(node.right);
if (right == -1 ) return -1;
//两个子节点深度之差小于一
if ((left - right) > 1 || (right - left) > 1) {
return -1;
}
//父节点需要向自己的父节点报告自己的深度
return (left > right ? left : right) + 1;
}
}
二叉搜索树的最近公共祖先
(1)非递归,利用二叉搜索树的特点:左子树<根节点<右子树
若p,q都比当前结点的值小,说明最近公共祖先结点在当前结点的左子树上,继续检查左子> 树;
若p,q都比当前结点的值大,说明最近公共祖先结点在当前结点的右子树上,继续检查右子树;
若p,q中一个比当前结点的值大,另一个比当前结点的值小,则当前结点为最近公共祖先结点
public int lowestCommonAncestor (TreeNode root, int p, int q) {
TreeNode curr=root;
while(true) {
if(p<curr.val && q<curr.val) curr=curr.left;
else if(p>curr.val && q>curr.val) curr=curr.right;
else return curr.val;
}
}
(2) 递归
public int lowestCommonAncestor (TreeNode root, int p, int q) {
if (root == null) return -1;
if (p < root.val && q < root.val)
return lowestCommonAncestor(root.left, p, q);
else if (p > root.val && q > root.val)
return lowestCommonAncestor(root.right, p, q);
else
return root.val;
}
(3) 搜索路径
public class Solution {
//求得根节点到目标节点的路径
public ArrayList<Integer> getPath(TreeNode root, int target) {
ArrayList<Integer> path = new ArrayList<Integer>();
TreeNode node = root;
//节点值都不同,可以直接用值比较
while(node.val != target){
path.add(node.val);
//小的在左子树
if(target < node.val)
node = node.left;
//大的在右子树
else
node = node.right;
}
path.add(node.val);
return path;
}
public int lowestCommonAncestor (TreeNode root, int p, int q) {
//求根节点到两个节点的路径
ArrayList<Integer> path_p = getPath(root, p);
ArrayList<Integer> path_q = getPath(root, q);
int res = 0;
//比较两个路径,找到第一个不同的点
for(int i = 0; i < path_p.size() && i < path_q.size(); i++){
int x = path_p.get(i);
int y = path_q.get(i);
//最后一个相同的节点就是最近公共祖先
if(x == y)
res = path_p.get(i);
else
break;
}
return res;
}
}
序列化二叉树
import java.util.*;
public class Solution {
//序列的下标
public int index = 0;
//处理序列化的功能函数(递归)
private void SerializeFunction(TreeNode root, StringBuilder str){
//如果节点为空,表示左子节点或右子节点为空,用#表示
if(root == null){
str.append('#');
return;
}
//根节点
str.append(root.val).append('!');
//左子树
SerializeFunction(root.left, str);
//右子树
SerializeFunction(root.right, str);
}
public String Serialize(TreeNode root) {
//处理空树
if(root == null)
return "#";
StringBuilder res = new StringBuilder();
SerializeFunction(root, res);
//把str转换成char
return res.toString();
}
//处理反序列化的功能函数(递归)
private TreeNode DeserializeFunction(String str){
//到达叶节点时,构建完毕,返回继续构建父节点
//空节点
if(str.charAt(index) == '#'){
index++;
return null;
}
//数字转换
int val = 0;
//遇到分隔符或者结尾
while(str.charAt(index) != '!' && index != str.length()){
val = val * 10 + ((str.charAt(index)) - '0');
index++;
}
TreeNode root = new TreeNode(val);
//序列到底了,构建完成
if(index == str.length())
return root;
else
index++;
//反序列化与序列化一致,都是前序
root.left = DeserializeFunction(str);
root.right = DeserializeFunction(str);
return root;
}
public TreeNode Deserialize(String str) {
//空序列对应空树
if(str == "#")
return null;
TreeNode res = DeserializeFunction(str);
return res;
}
}
重建二叉树
(1) 递归
public TreeNode reConstructBinaryTree(int[] pre, int[] in) {
if (pre.length == 0 || in.length == 0) {
return null;
}
TreeNode root = new TreeNode(pre[0]);
// 在中序中找到前序的根
for (int i = 0; i < in.length; i++) {
if (in[i] == pre[0]) {
// 左子树,注意 copyOfRange 函数,左闭右开
root.left = reConstructBinaryTree(Arrays.copyOfRange(pre, 1, i + 1), Arrays.copyOfRange(in, 0, i));
// 右子树,注意 copyOfRange 函数,左闭右开
root.right = reConstructBinaryTree(Arrays.copyOfRange(pre, i + 1, pre.length), Arrays.copyOfRange(in, i + 1, in.length));
break;
}
}
return root;
}
(2) 使用栈
import java.util.*;
public class Solution {
public TreeNode reConstructBinaryTree(int [] pre,int [] vin) {
int n = pre.length;
int m = vin.length;
//每个遍历都不能为0
if(n == 0 || m == 0)
return null;
Stack<TreeNode> s = new Stack<TreeNode>();
//首先建立前序第一个即根节点
TreeNode root = new TreeNode(pre[0]);
TreeNode cur = root;
for(int i = 1, j = 0; i < n; i++){
//要么旁边这个是它的左节点
if(cur.val != vin[j]){
cur.left = new TreeNode(pre[i]);
s.push(cur);
//要么旁边这个是它的右节点,或者祖先的右节点
cur = cur.left;
}else{
j++;
//弹出到符合的祖先
while(!s.isEmpty() && s.peek().val == vin[j]){
cur = s.pop();
j++;
}
//添加右节点
cur.right = new TreeNode(pre[i]);
cur = cur.right;
}
}
return root;
}
}
输出二叉树的右视图
(1)递归建树+辅助Map
public class Solution {
private HashMap<Integer, Integer> ans = new HashMap<>();
private HashMap<Integer, Integer> map = new HashMap<>();
private int j = 0;
public int[] solve (int[] xianxu, int[] zhongxu) {
//将xianxu节点的值映射到相应的中序节点的下标。
for (int i = 0; i < zhongxu.length; i++) {
map.put(zhongxu[i], i);
}
//开始构建二叉树。
build(xianxu, zhongxu, 0, xianxu.length - 1, 0);
//创建放回答案的数组
int[] temp = new int[ans.size()];
//将值传入数组。
for (int i = 0; i < ans.size(); i++) {
temp[i] = ans.get(i);
}
return temp;
}
public void build(int[] xianxu, int[] zhongxu, int left, int right, int i) {
if (left > right) {
return;
}
int index = map.get(xianxu[j++]);
//构建左子树
build(xianxu, zhongxu, left, index - 1, i + 1);
//构建右子树
build(xianxu, zhongxu, index + 1, right, i + 1);
//存储第i层的最右边的那个节点。
ans.put(i, zhongxu[index]);
}
}
(2) 递归建树+DFS深度优先搜索
import java.util.*;
public class Solution {
//建树函数
//四个int参数分别是前序最左节点下标,前序最右节点下标
//中序最左节点下标,中序最右节点坐标
public TreeNode buildTree(int[] xianxu, int l1, int r1, int[] zhongxu, int l2, int r2){
if(l1 > r1 || l2 > r2)
return null;
//构建节点
TreeNode root = new TreeNode(xianxu[l1]);
//用来保存根节点在中序遍历列表的下标
int rootIndex = 0;
//寻找根节点
for(int i = l2; i <= r2; i++){
if(zhongxu[i] == xianxu[l1]){
rootIndex = i;
break;
}
}
//左子树大小
int leftsize = rootIndex - l2;
//右子树大小
int rightsize = r2 - rootIndex;
//递归构建左子树和右子树
root.left = buildTree(xianxu, l1 + 1, l1 + leftsize, zhongxu, l2 , l2 + leftsize - 1);
root.right = buildTree(xianxu, r1 - rightsize + 1, r1, zhongxu, rootIndex + 1, r2);
return root;
}
//深度优先搜索函数
public ArrayList<Integer> rightSideView(TreeNode root) {
//右边最深处的值
Map<Integer, Integer> mp = new HashMap<Integer, Integer>();
//记录最大深度
int max_depth = -1;
//维护深度访问节点
Stack<TreeNode> nodes = new Stack<TreeNode>();
//维护dfs时的深度
Stack<Integer> depths = new Stack<Integer>();
nodes.push(root);
depths.push(0);
while(!nodes.isEmpty()){
TreeNode node = nodes.pop();
int depth = depths.pop();
if(node != null){
//维护二叉树的最大深度
max_depth = Math.max(max_depth, depth);
//如果不存在对应深度的节点我们才插入
if(mp.get(depth) == null)
mp.put(depth, node.val);
nodes.push(node.left);
nodes.push(node.right);
depths.push(depth + 1);
depths.push(depth + 1);
}
}
ArrayList<Integer> res = new ArrayList<Integer>();
//结果加入链表
for(int i = 0; i <= max_depth; i++)
res.add(mp.get(i));
return res;
}
public int[] solve (int[] xianxu, int[] zhongxu) {
//空节点
if(xianxu.length == 0)
return new int[0];
//建树
TreeNode root = buildTree(xianxu, 0, xianxu.length - 1, zhongxu, 0, zhongxu.length - 1);
//获取右视图输出
ArrayList<Integer> temp = rightSideView(root);
//转化为数组
int[] res = new int[temp.size()];
for(int i = 0; i < temp.size(); i++)
res[i] = temp.get(i);
return res;
}
}
最长公共子串
(1) 解法1
public String LCS (String str1, String str2) {
String result=new String();
for(int i=0;i<str1.length();i++){
int k=i;
int count=0;
for(int j=0; k<str1.length() && j<str2.length() ;j++){
if(str2.charAt(j)==str1.charAt(k)){
count++;
k++;
}else{
j=j-count;
k=i;
count=0;
}
if(count>result.length()){
result=str1.substring(i,k);
}
}
}
return result;
}
(2)解法2
public String LCS (String str1, String str2) {
int start = 0;
int end = 1;
StringBuilder s = new StringBuilder();
//注意是要加一,因substring函数是不包含上界
while (end < str1.length()+1) {
if (str2.contains(str1.substring(start, end))) {
if (s.length() < (end - start)) {
s.delete(0, s.length());
s.append(str1, start, end);
}
end++;
} else {
start++;
}
}
if (s.length() == 0) {
return "";
}
return s.toString();
}
(3)动态规划
public String LCS(String str1, String str2) {
int maxLenth = 0;//记录最长公共子串的长度
//记录最长公共子串最后一个元素在字符串str1中的位置
int maxLastIndex = 0;
int[] dp = new int[str2.length() + 1];
for (int i = 0; i < str1.length(); i++) {
//注意这里是倒序
for (int j = str2.length() - 1; j >= 0; j--) {
//递推公式,两个字符相等的情况
if (str1.charAt(i) == str2.charAt(j)) {
dp[j + 1] = dp[j] + 1;
//如果遇到了更长的子串,要更新,记录最长子串的长度,
//以及最长子串最后一个元素的位置
if (dp[j + 1] > maxLenth) {
maxLenth = dp[j + 1];
maxLastIndex = i;
}
} else {
//递推公式,两个字符不相等的情况
dp[j + 1] = 0;
}
}
}
//最字符串进行截取,substring(a,b)中a和b分别表示截取的开始和结束位置
return str1.substring(maxLastIndex - maxLenth + 1, maxLastIndex + 1);
}
不同路径的数目(一)
(1)递归
public int uniquePaths (int m, int n) {
//矩阵只要有一条边为1,路径数就只有一种了
if(m == 1 || n == 1)
return 1;
//两个分支
return uniquePaths(m - 1, n) + uniquePaths(m, n - 1);
}
(2) 动态规划
public int uniquePaths (int m, int n) {
//dp[i][j]表示大小为i*j的矩阵的路径数量
int[][] dp = new int[m + 1][n + 1];
for(int i = 1; i <= m; i++){
for(int j = 1; j <= n; j++){
//只有1行的时候,只有一种路径
if(i == 1){
dp[i][j] = 1;
continue;
}
//只有1列的时候,只有一种路径
if(j == 1){
dp[i][j] = 1;
continue;
}
//路径数等于左方格子的路径数加上上方格子的路径数
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m][n];
}
两个链表的第一个公共结点
思路:遍历两遍这两个链表,如果有重复的节点,那么一定能够使遍历的指针相等。
(1)遍历
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
if(pHead1 == null || pHead2 == null)return null;
ListNode p1 = pHead1;
ListNode p2 = pHead2;
while(p1!=p2){
p1 = p1.next;
p2 = p2.next;
if(p1 != p2){
if(p1 == null)p1 = pHead2;
if(p2 == null)p2 = pHead1;
}
}
return p1;
}
(2)集合Set
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
HashSet<ListNode> set=new HashSet<>();
while(pHead1!=null){
set.add(pHead1);
pHead1=pHead1.next;
}
while(pHead2!=null){
if(set.contains(pHead2))
return pHead2;
pHead2=pHead2.next;
}
return null;
}
链表相加(二)
import java.util.*;
public class Solution {
//反转链表
public ListNode ReverseList(ListNode pHead) {
if(pHead == null)
return null;
ListNode cur = pHead;
ListNode pre = null;
while(cur != null){
//断开链表,要记录后续一个
ListNode temp = cur.next;
//当前的next指向前一个
cur.next = pre;
//前一个更新为当前
pre = cur;
//当前更新为刚刚记录的后一个
cur = temp;
}
return pre;
}
public ListNode addInList (ListNode head1, ListNode head2) {
//任意一个链表为空,返回另一个
if(head1 == null)
return head2;
if(head2 == null)
return head1;
//反转两个链表
head1 = ReverseList(head1);
head2 = ReverseList(head2);
//添加表头
ListNode res = new ListNode(-1);
ListNode head = res;
//进位符号
int carry = 0;
//只要某个链表还有或者进位还有
while(head1 != null || head2 != null || carry != 0){
//链表不为空则取其值
int val1 = head1 == null ? 0 : head1.val;
int val2 = head2 == null ? 0 : head2.val;
//相加
int temp = val1 + val2 + carry;
//获取进位
carry = temp / 10;
temp %= 10;
//添加元素
head.next = new ListNode(temp);
head = head.next;
//移动下一个
if(head1 != null)
head1 = head1.next;
if(head2 != null)
head2 = head2.next;
}
//结果反转回来
return ReverseList(res.next);
}
}
单链表的排序
import java.util.*;
public class Solution {
//合并两段有序链表
ListNode merge(ListNode pHead1, ListNode pHead2) {
//一个已经为空了,直接返回另一个
if(pHead1 == null)
return pHead2;
if(pHead2 == null)
return pHead1;
//加一个表头
ListNode head = new ListNode(0);
ListNode cur = head;
//两个链表都要不为空
while(pHead1 != null && pHead2 != null){
//取较小值的节点
if(pHead1.val <= pHead2.val){
cur.next = pHead1;
//只移动取值的指针
pHead1 = pHead1.next;
}else{
cur.next = pHead2;
//只移动取值的指针
pHead2 = pHead2.next;
}
//指针后移
cur = cur.next;
}
//哪个链表还有剩,直接连在后面
if(pHead1 != null)
cur.next = pHead1;
else
cur.next = pHead2;
//返回值去掉表头
return head.next;
}
public ListNode sortInList (ListNode head) {
//链表为空或者只有一个元素,直接就是有序的
if(head == null || head.next == null)
return head;
ListNode left = head;
ListNode mid = head.next;
ListNode right = head.next.next;
//右边的指针到达末尾时,中间的指针指向该段链表的中间
while(right != null && right.next != null){
left = left.next;
mid = mid.next;
right = right.next.next;
}
//左边指针指向左段的左右一个节点,从这里断开
left.next = null;
//分成两段排序,合并排好序的两段
return merge(sortInList(head), sortInList(mid));
}
}
判断一个链表是否为回文结构
(1) 使用栈
public boolean isPail(ListNode head) {
ListNode temp = head;
Stack<Integer> stack = new Stack();
//把链表节点的值存放到栈中
while (temp != null) {
stack.push(temp.val);
temp = temp.next;
}
//然后再出栈
while (head != null) {
if (head.val != stack.pop()) {
return false;
}
head = head.next;
}
return true;
}
(2)后半部分反转
public boolean isPail(ListNode head) {
ListNode fast = head, slow = head;
//通过快慢指针找到中点
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
}
//如果fast不为空,说明链表的长度是奇数个
if (fast != null) {
slow = slow.next;
}
//反转后半部分链表
slow = reverse(slow);
fast = head;
while (slow != null) {
//然后比较,判断节点值是否相等
if (fast.val != slow.val)
return false;
fast = fast.next;
slow = slow.next;
}
return true;
}
//反转链表
public ListNode reverse(ListNode head) {
ListNode prev = null;
while (head != null) {
ListNode next = head.next;
head.next = prev;
prev = head;
head = next;
}
return prev;
}
链表的奇偶重排
public ListNode oddEvenList(ListNode head) {
//如果链表为空,不用重排
if(head == null)
return head;
//even开头指向第二个节点,可能为空
ListNode even = head.next;
//odd开头指向第一个节点
ListNode odd = head;
//指向even开头
ListNode evenhead = even;
while(even != null && even.next != null){
//odd连接even的后一个,即奇数位
odd.next = even.next;
//odd进入后一个奇数位
odd = odd.next;
//even连接后一个奇数的后一位,即偶数位
even.next = odd.next;
//even进入后一个偶数位
even = even.next;
}
//even整体接在odd后面
odd.next = evenhead;
return head;
}
删除有序链表中重复的元素-I
public ListNode deleteDuplicates (ListNode head) {
//空链表
if(head == null) return null;
//遍历指针
ListNode cur = head;
//指针当前和下一位不为空
while(cur != null && cur.next != null){
//如果当前与下一位相等则忽略下一位
if(cur.val == cur.next.val) {
cur.next = cur.next.next;
} else {
cur = cur.next;
}
}
return head;
}
删除有序链表中重复的元素-II
public ListNode deleteDuplicates(ListNode head) {
//空链表
if(head == null) return null;
ListNode res = new ListNode(0);
//在链表前加一个表头
res.next = head;
ListNode cur = res;
while(cur.next != null && cur.next.next != null){
//遇到相邻两个节点值相同
if(cur.next.val == cur.next.next.val){
int temp = cur.next.val;
//将所有相同的都跳过
while (cur.next != null && cur.next.val == temp)
cur.next = cur.next.next;
} else {
cur = cur.next;
}
}
//返回时去掉表头
return res.next;
}
连续子数组的最大和
public int FindGreatestSumOfSubArray(int[] array) {
int sum = 0;
int max = array[0];
for(int i=0;i<array.length;i++){
// 优化动态规划,确定sum的最大值
sum = Math.max(sum + array[i], array[i]);
// 每次比较,保存出现的最大值
max = Math.max(max, sum);
}
return max;
}
在二叉树中找到两个节点的最近公共祖先
(1)递归:
public class Solution {
public int lowestCommonAncestor(TreeNode root, int o1, int o2) {
return helper(root, o1, o2).val;
}
public TreeNode helper(TreeNode root, int o1, int o2) {
if (root == null || root.val == o1 || root.val == o2)
return root;
TreeNode left = helper(root.left, o1, o2);
TreeNode right = helper(root.right, o1, o2);
//如果left为空,说明这两个节点在root结点的右子树上,我们只需要返回右子树查找的结果即可
if (left == null) return right;
//同上
if (right == null) return left;
//如果left和right都不为空,说明这两个节点一个在root的左子树上一个在root的右子树上,
//我们只需要返回cur结点即可。
return root;
}
}
(2)使用队列:
public int lowestCommonAncestor(TreeNode root, int o1, int o2) {
//记录遍历到的每个节点的父节点。
Map<Integer, Integer> parent = new HashMap<>();
Queue<TreeNode> queue = new LinkedList<>();
parent.put(root.val, Integer.MIN_VALUE);
queue.add(root);
//直到两个节点都找到为止。
while (!parent.containsKey(o1) || !parent.containsKey(o2)) {
//队列是一边进一边出,这里poll方法是出队,
TreeNode node = queue.poll();
if (node.left != null) {
//左子节点不为空,记录下他的父节点
parent.put(node.left.val, node.val);
//左子节点不为空,把它加入到队列中
queue.add(node.left);
}
//右节点同上
if (node.right != null) {
parent.put(node.right.val, node.val);
queue.add(node.right);
}
}
Set<Integer> ancestors = new HashSet<>();
//记录下o1和他的祖先节点,从o1节点开始一直到根节点。
while (parent.containsKey(o1)) {
ancestors.add(o1);
o1 = parent.get(o1);
}
//查看o1和他的祖先节点是否包含o2节点,如果不包含再看是否包含o2的父节点……
while (!ancestors.contains(o2))
o2 = parent.get(o2);
return o2;
}
最长回文子串
public class Solution {
public int getLongestPalindrome (String A) {
return getLongestPalindrome(A, A.length());
}
public int getLongestPalindrome(String A, int n) {
if (n < 2) return A.length();
int maxLen = 1; //maxLen表示最长回文串的长度
boolean[][] dp = new boolean[n][n];
for (int right = 1; right < n; right++) {
for (int left = 0; left <= right; left++) {
//如果两种字符不相同,肯定不能构成回文子串
if (A.charAt(left) != A.charAt(right))
continue;
//下面是s.charAt(left)和s.charAt(right)两个
//字符相同情况下的判断
//如果只有一个字符,肯定是回文子串
if (right == left) {
dp[left][right] = true;
} else if (right - left <= 2) {
//类似于"aa"和"aba",也是回文子串
dp[left][right] = true;
} else {
//类似于"a******a",要判断他是否是回文子串,只需要
//判断"******"是否是回文子串即可
dp[left][right] = dp[left + 1][right - 1];
}
//如果字符串从left到right是回文子串,只需要保存最长的即可
if (dp[left][right] && right - left + 1 > maxLen) {
maxLen = right - left + 1;
}
}
}
//最长的回文子串
return maxLen;
}
}
数字字符串转化成IP地址
public ArrayList<String> restoreIpAddresses (String s) {
ArrayList<String> res = new ArrayList<String>();
int n = s.length();
//遍历IP的点可能的位置(第一个点)
for (int i = 1; i < 4 && i < n - 2; i++) {
//第二个点的位置
for (int j = i + 1; j < i + 4 && j < n - 1; j++) {
//第三个点的位置
for (int k = j + 1; k < j + 4 && k < n; k++) {
//最后一段剩余数字不能超过3
if (n - k >= 4)
continue;
//从点的位置分段截取
String a = s.substring(0, i);
String b = s.substring(i, j);
String c = s.substring(j, k);
String d = s.substring(k);
//IP每个数字不大于255
if (Integer.parseInt(a) > 255 ||
Integer.parseInt(b) > 255 ||
Integer.parseInt(c) > 255 ||
Integer.parseInt(d) > 255)
continue;
//排除前导0的情况
if ((a.length() != 1 && a.charAt(0) == '0') ||
(b.length() != 1 && b.charAt(0) == '0') ||
(c.length() != 1 && c.charAt(0) == '0') ||
(d.length() != 1 && d.charAt(0) == '0'))
continue;
//组装IP地址
String temp = a + "." + b + "." + c + "." + d;
res.add(temp);
}
}
}
return res;
}
编辑距离(一)
public int editDistance (String str1, String str2) {
int n1 = str1.length();
int n2 = str2.length();
//dp[i][j]表示到str1[i]和str2[j]为止的子串需要的编辑距离
int[][] dp = new int[n1 + 1][n2 + 1];
//初始化边界
for (int i = 1; i <= n1; i++)
dp[i][0] = dp[i - 1][0] + 1;
for (int i = 1; i <= n2; i++)
dp[0][i] = dp[0][i - 1] + 1;
//遍历第一个字符串的每个位置
for (int i = 1; i <= n1; i++) {
//对应第二个字符串每个位置
for (int j = 1; j <= n2; j++) {
//若是字符相同,此处不用编辑
if (str1.charAt(i - 1) == str2.charAt(j - 1))
//直接等于二者前一个的距离
dp[i][j] = dp[i - 1][j - 1];
else
//选取最小的距离加上此处编辑距离1
dp[i][j] = Math.min(dp[i - 1][j - 1], Math.min(dp[i - 1][j], dp[i][j - 1])) + 1;
}
}
return dp[n1][n2];
}
正则表达式匹配
import java.util.*;
public class Solution {
public boolean match (String str, String pattern) {
int n1 = str.length();
int n2 = pattern.length();
//dp[i][j]表示str前i个字符和pattern前j个字符是否匹配
boolean[][] dp = new boolean[n1 + 1][n2 + 1];
//遍历str每个长度
for(int i = 0; i <= n1; i++){
//遍历pattern每个长度
for(int j = 0; j <= n2; j++){
//空正则的情况
if(j == 0){
dp[i][j] = (i == 0 ? true : false);
//非空的情况下 星号、点号、字符
}else{
if(pattern.charAt(j - 1) != '*'){
//当前字符不为*,用.去匹配或者字符直接相同
if(i > 0 && (str.charAt(i - 1) == pattern.charAt(j - 1) || pattern.charAt(j - 1) == '.')){
dp[i][j] = dp[i - 1][j - 1];
}
}else{
//碰到*
if(j >= 2){
dp[i][j] |= dp[i][j - 2];
}
//若是前一位为.或者前一位可以与这个数字匹配
if(i >= 1 && j >= 2 && (str.charAt(i - 1) == pattern.charAt(j - 2) || pattern.charAt(j - 2) == '.')){
dp[i][j] |= dp[i - 1][j];
}
}
}
}
}
return dp[n1][n2];
}
}
最长的括号子串
import java.util.*;
public class Solution {
public int longestValidParentheses (String s) {
int res = 0;
//记录上一次连续括号结束的位置
int start = -1;
Stack<Integer> st = new Stack<Integer>();
for(int i = 0; i < s.length(); i++){
//左括号入栈
if(s.charAt(i) == '(')
st.push(i);
//右括号
else{
//如果右括号时栈为空,不合法,设置为结束位置
if(st.isEmpty())
start = i;
else{
//弹出左括号
st.pop();
//栈中还有左括号,说明右括号不够,减去栈顶位置就是长度
if(!st.empty())
res = Math.max(res, i - st.peek());
//栈中没有括号,说明左右括号行号,减去上一次结束的位置就是长度
else
res = Math.max(res, i - start);
}
}
}
return res;
}
}
打家劫舍(一)
public int rob (int[] nums) {
//dp[i]表示长度为i的数组,最多能偷取多少钱
int[] dp = new int[nums.length + 1];
//长度为1只能偷第一家
dp[1] = nums[0];
for (int i = 2; i <= nums.length; i++)
//对于每家可以选择偷或者不偷
dp[i] = Math.max(dp[i - 1], nums[i - 1] + dp[i - 2]);
return dp[nums.length];
}
打家劫舍(二)
import java.util.*;
public class Solution {
public int rob (int[] nums) {
//dp[i]表示长度为i的数组,最多能偷取多少钱
int[] dp = new int[nums.length + 1];
//选择偷了第一家
dp[1] = nums[0];
//最后一家不能偷
for(int i = 2; i < nums.length; i++)
//对于每家可以选择偷或者不偷
dp[i] = Math.max(dp[i - 1], nums[i - 1] + dp[i - 2]);
int res = dp[nums.length - 1];
//清除dp数组,第二次循环
Arrays.fill(dp, 0);
//不偷第一家
dp[1] = 0;
//可以偷最后一家
for(int i = 2; i <= nums.length; i++)
//对于每家可以选择偷或者不偷
dp[i] = Math.max(dp[i - 1], nums[i - 1] + dp[i - 2]);
//选择最大值
return Math.max(res, dp[nums.length]);
}
}
最长上升子序列(一)
public int LIS (int[] arr) {
int n = arr.length;
//特殊请款判断
if (n == 0) return 0;
//dp[i]表示以下标i结尾的最长上升子序列长度
int[] dp = new int[n];
for (int i = 0; i < n; i++) {
//初始化为1
dp[i] = 1;
for (int j = 0; j < i; j++) {
if (arr[i] > arr[j]) {
//只要前面某个数小于当前数,则要么长度在之前基础上加1,要么保持不变,取较大者
dp[i] = Math.max(dp[i], dp[j] + 1);
}
}
}
//返回所有可能中的最大值
return Arrays.stream(dp).max().getAsInt();
}
最长上升子序列(三)
public int[] LIS (int[] arr) {
int len = 1, n = arr.length;
if (n == 0) return new int[0];
int[] d = new int[n + 1];
int[] w = new int[n];
d[len] = arr[0];
w[0] = len;
for (int i = 1; i < n; ++i) {
if (arr[i] > d[len]) {
d[++len] = arr[i];
w[i] = len;
} else {
int l = 1, r = len, pos = 0;
while (l <= r) {
int mid = (l + r) >> 1;
if (d[mid] < arr[i]) {
pos = mid;
l = mid + 1;
} else {
r = mid - 1;
}
}
d[pos + 1] = arr[i];
w[i] = pos + 1;
}
}
int[] res = new int[len];
for (int i = n - 1, j = len; j > 0; --i) {
if (w[i] == j) {
res[--j] = arr[i];
}
}
return res;
}
盛水最多的容器
public int maxArea (int[] height) {
//排除不能形成容器的情况
if(height.length < 2)
return 0;
int res = 0;
//双指针左右界
int left = 0;
int right = height.length - 1;
//共同遍历完所有的数组
while(left < right){
//计算区域水容量
int capacity = Math.min(height[left], height[right]) * (right - left);
//维护最大值
res = Math.max(res, capacity);
//优先舍弃较短的边
if(height[left] < height[right])
left++;
else
right--;
}
return res;
}
接雨水问题
public long maxWater (int[] arr) {
//排除空数组
if(arr.length == 0) return 0;
long res = 0;
//左右双指针
int left = 0;
int right = arr.length - 1;
//中间区域的边界高度
int maxL = 0;
int maxR = 0;
//直到左右指针相遇
while(left < right){
//每次维护往中间的最大边界
maxL = Math.max(maxL, arr[left]);
maxR = Math.max(maxR, arr[right]);
//较短的边界确定该格子的水量
if(maxR > maxL)
res += maxL - arr[left++];
else
res += maxR - arr[right--];
}
return res;
}
















 4873
4873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











