







原文网址:MySQL原理--一条SQL查询语句的执行流程_IT利刃出鞘的博客-CSDN博客
简介
说明
本文介绍MySQL中一条SQL查询语句的执行流程。
此问题也是Java后端面试中常问的一个问题。
相关网址
MySQL--query cache,buffer pool,key buffer--含义与区别_IT利刃出鞘的博客-CSDN博客
流程概述
说明
MySQL 可以分为 Server 层和存储引擎层两部分。
- Server 层
- 包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核 心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等)。
- 所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
- 存储引擎层:
- 负责数据的存储和提取。
- 架构模式是插件式的,支持 InnoDB、 MyISAM、Memory 等多个存储引擎。现在常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
流程图
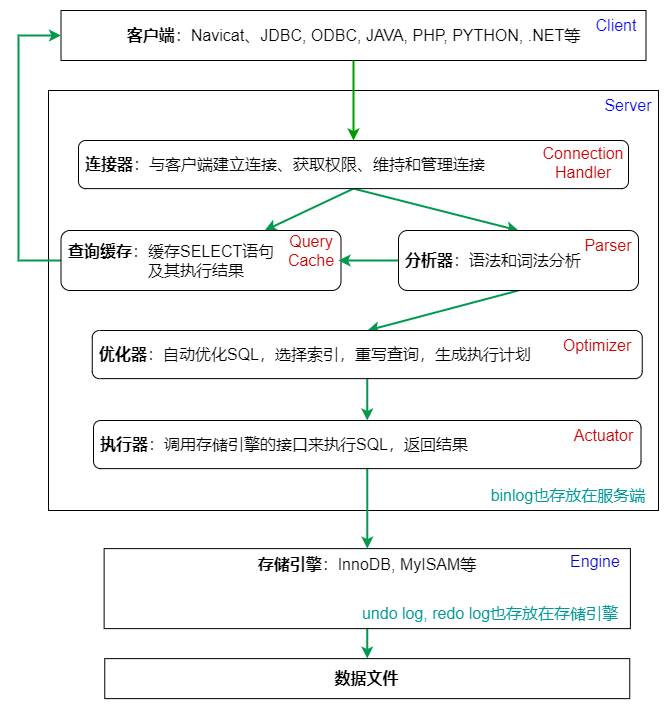
1. 连接器
连接器的作用:连接处理、授权认证、安全性。
上边只是部分内容,为便于维护,本文已迁移到此地址:MySQL一条SQL查询语句的执行流程 - 自学精灵
















 2047
2047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











