







准备工作
1. 三台虚拟机
| 主机名 | IP地址 |
|---|---|
| node1 | 192.168.10.101 |
| node2 | 192.168.10.102 |
| node3 | 192.168.10.103 |
2. 软件版本
| 软件名称 | 版本 |
|---|---|
| jdk | 1.8.0_65 |
| elasticsearch | 6.8.4 |
一、安装jdk
- 上传安装包到
/export/server目录下

- 解压压缩包
tar -zxvf jdk-8u65-linux-x64.tar.gz
- 删除安装包
rm -rf jdk-8u65-linux-x64.tar.gz
- 重命名文件夹
mv jdk1.8.0_65/ jdk
- 配置环境变量
vim /etc/profile
# 新增加的内容
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- 重载环境变量
source /etc/profile
二、安装ElasticSearch
- 将安装包上传到
/export/server目录下
- 解压压缩包
tar -zxvf elasticsearch-6.8.4.tar.gz
- 删除安装包
rm -rf elasticsearch-6.8.4.tar.gz
- 重命名文件夹
mv elasticsearch-6.8.4/ elasticsearch
- 创建普通用户
# 新增es用户
useradd es
# 为es用户设置密码
passwd es
# 如果错了,可以删除再加
# userdel -r es
- 修改配置文件
vim /export/server/elasticsearch/config/elasticsearch.yml
# 集群标识,同一个集群中的多个节点使用相同的标识
cluster.name: es-cluster
# 节点名称,每个节点的名称不能重复
# 其他机器修改为es-node2和es-node3
node.name: "es-node1"
# 数据存储目录
path.data: /export/server/elasticsearch/data
# 日志存储目录
path.logs: /export/server/elasticsearch/logs
# 节点绑定IP地址,并且该节点会被通知到集群中的其他节点,每个节点的地址不能重复
# 其他机器修改为192.168.10.102、192.168.10.103
network.host: 192.168.10.101
# 绑定鉴定的网络接口,监听传入的请求,可以设置为IP地址或者主机名
# 其他机器修改为192.168.10.102、192.168.10.103
network.bind_host: 192.168.10.101
# 发布地址,用于通知集群中的其他节点,和其他节点通讯,不设置的话默认可以自动设置,必须是一个存在的IP地址
# 其他机器修改为192.168.10.102、192.168.10.103
network.publish_host: 192.168.10.101
# 对外提供服务的http端口,默认为9200
http.port: 9200
# 集群中主节点的初始列表,当主节点启动时会使用这个列表进行非主节点的监测
discovery.zen.ping.unicast.hosts: ["192.168.10.101","192.168.10.102","192.168.10.103"]
# 下面这个参数控制的是,一个节点需要看到的具有master节点资格的最小数量,然后才能在集群中做操作,官方推荐值是(N/2)+1
# 其中N是具有master资格的节点的数量(我的情况是3,因此这个参数设置为2)
# 但是:对于只有2个节点的情况,设置为2就有些问题了,一个节点DOWN掉后,肯定连不上台服务器了,这点需要注意
discovery.zen.minimum_master_nodes: 2
# ES默认开启了内存地址锁定,为了避免内存交换提高性能,但是Centos6不支持SecComp功能,启动会报错,所以需要将其设置为false
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
- 修改limits.conf
vim /etc/security/limits.conf
# 在文件末尾中增加下面内容
# 用来保护系统的资源访问,和sysctl.conf很像,但是limits.conf是针对于用户,而sysctl.conf是针对于操作系统
# 每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536
- 修改
/etc/security/limits.d/20-nproc.conf
vim /etc/security/limits.d/20-nproc.conf
# 在文件末尾中增加下面内容
# 每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536
# 操作系统级别对每个用户创建的进程数的限制
* hard nproc 4096
# 注:* 代表Linux所有用户名称
- 修改内核参数
vim /etc/sysctl.conf
# 在文件中增加下面内容
# max_map_count文件包含限制一个进程可以拥有VMA(虚拟内存区域)的数量。虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。当进程达到了VMA上限但又只能释放少量的内存给其他的内核进程使用时,操作系统会抛出内存不足的的错误,默认值为65536
vm.max_map_count=655360
# 重新加载
sysctl -p
- 创建data和log目录
mkdir -p /export/server/elasticsearch/data
mkdir -p /export/server/elasticsearch/logs
- 修改jvm配置文件
vim /export/server/elasticsearch/config/jvm.options
# elasticsearch启动时jvm所分配的初始堆内存大小
-Xms512m
# elasticsearch启动之后允许jvm分配的最大堆内存大小,生产环境中可能需要调大
-Xmx512m
注意:如果内存足够大,可以不用修改,默认为1G
- 修改文件夹权限
# 文件夹所有者
chown -R es:es /export/server/elasticsearch
三、启动ElasticSearch
- 切换用户
# 三台服务器都执行
su es
- 启动服务
# 前台启动
bin/elasticsearch
# 后台启动
bin/elasticsearch -d
- 启动成功
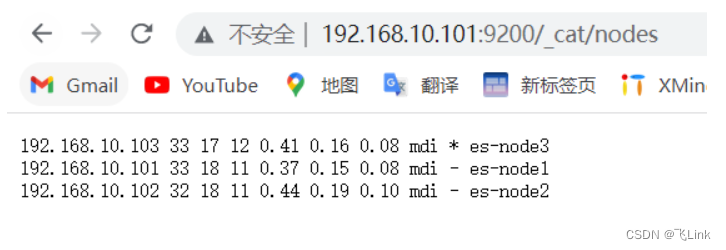
# 其他检测方式
ps -ef | grep elasticsearch
lsof -i:9200
- 测试
curl 192.168.10.101:9200
















 2406
2406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









