







目录
vector大致框架
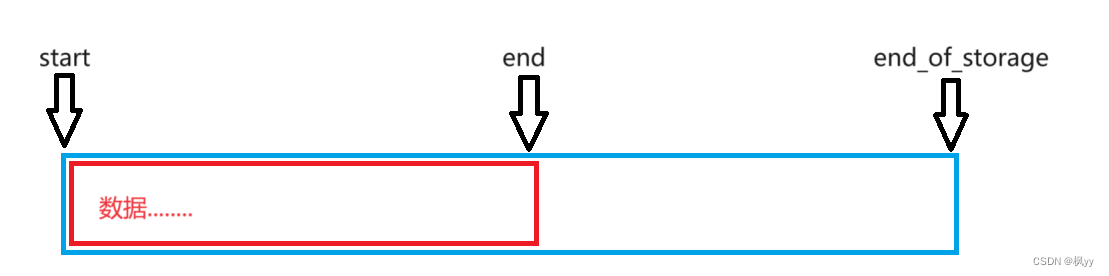
vector的内部的成员变量大概有三部分构成:
namespace bit
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
private:
iterator _start = nullptr; //记录头元素
iterator _finish = nullptr; //记录尾元素
iterator _end_of_storage = nullptr; //记录容量
};
这里成员变量的iterator可以理解为指针类型,但实际上并不是指针。具体框架就如上vector所示,这里不难发现,vector利用的是模板,意味着vector可以利用string等类型来搭建顺序表。
vector常见接口模拟实现
既然刚刚解释了iterator,那我们先模拟实现begin迭代器和end迭代器:
begin迭代器 & end迭代器
const_iterator begin() const
{
return _start;
}
const_iterator end() const
{
return _finish;
}
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}begin直接返回头元素地址,end直接返回尾元素地址。
capacity( ) & size( )
根据上文的三个成员变量,我们可以设计出以下的代码来反映vector的元素个数和容量大小。
size_t capacity()
{
return _end_of_storage - _start;
}
size_t size()
{
return _finish - _start;
}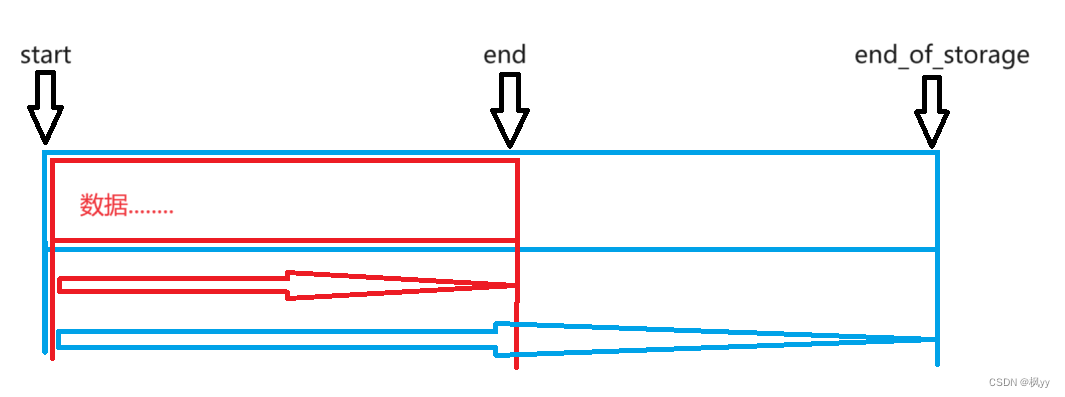
由图可知, end与start相减是元素个数,end of storage与start相减是容量大小。
思考:为什么两个指针相减可以算出元素个数?
答案:指针相减的结果:例如两个整型指针的地址相差8个字节,但是相减的结果为2,是因为两个指针相减操作会对其结果除以该指针所代表的数据类型的字节数,此处整型数据类型有4个字节,所以指针相减结果为2.
reserve
void reserve(size_t n)
{
if (n > capacity())
{
size_t oldsize = size();
T* tmp = new T[n];
if (_start)
{
memcpy(tmp, _start, sizeof(T) * size());
delete[] _start;
}
_start = tmp;
_finish = _start + oldsize;
_end_of_storage = _start + n;
}
}思考一下,为什么reserve的空间大于容量大小要开辟空间?如下图所示:
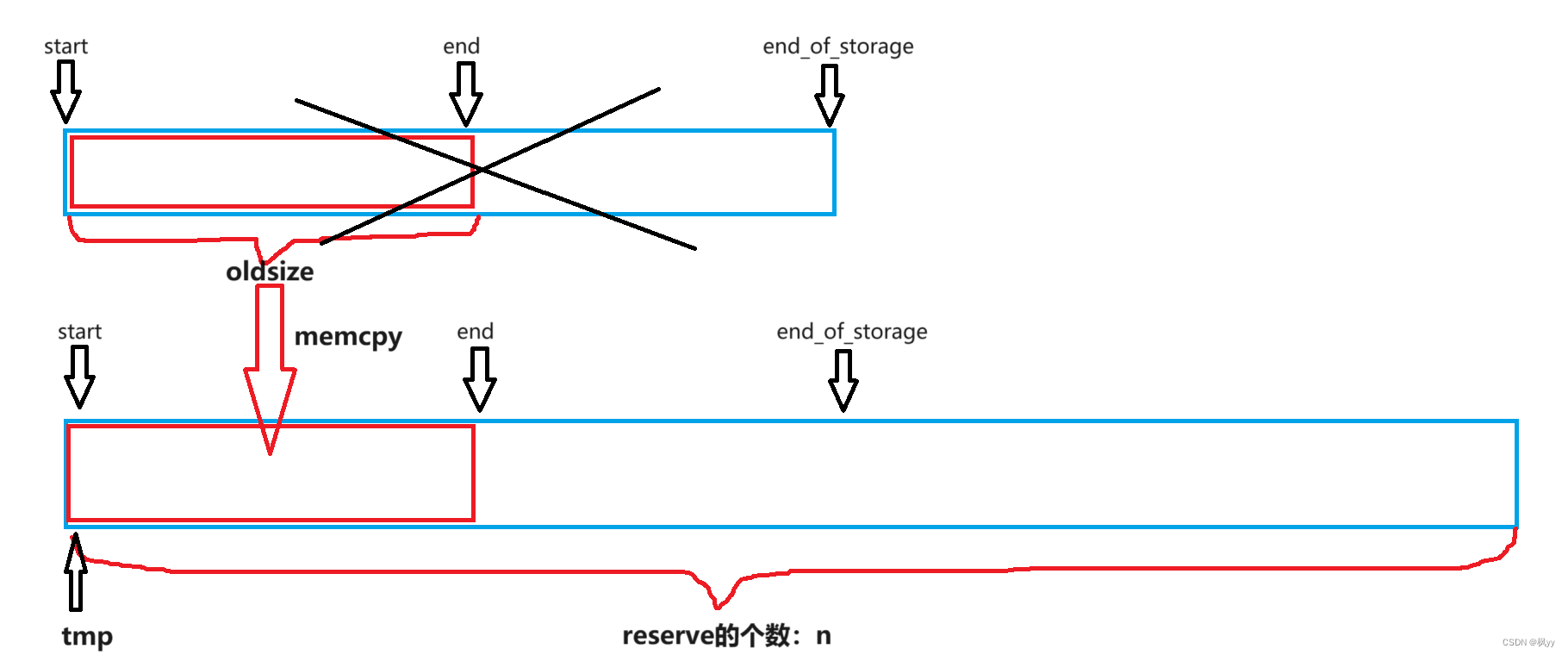
如果我们直接在原空间扩容,需要计算多扩容的个数,并且无法控制扩容的位置是否连续,对此应对这个问题,我们通过另外开辟一个n大小的空间进行memcpy。
operator[ ]
T& operator[](size_t i)
{
assert(i < size());
return _start[i];
}assert保证了不会越界访问,否则会断言。
push_back( ) & pop_back( )
void push_back(const T& x)
{
if (_finish == _end_of_storage)
{
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
}
*_finish = x;
++_finish;
}
void pop_back()
{
assert(size() > 0);
--_finish;
}pop_back很好理解,尾删只需要把只需要将指向尾元素的指针往前移一位即可。
push_back就稍微麻烦,需要考虑扩容,如果不够需要另外开辟大小为原容量两倍的空间来拷贝原顺序表,并将需要尾插的元素放在finish指向的空间。
sort
另外介绍algorithm头文件中一个算法函数:排序。
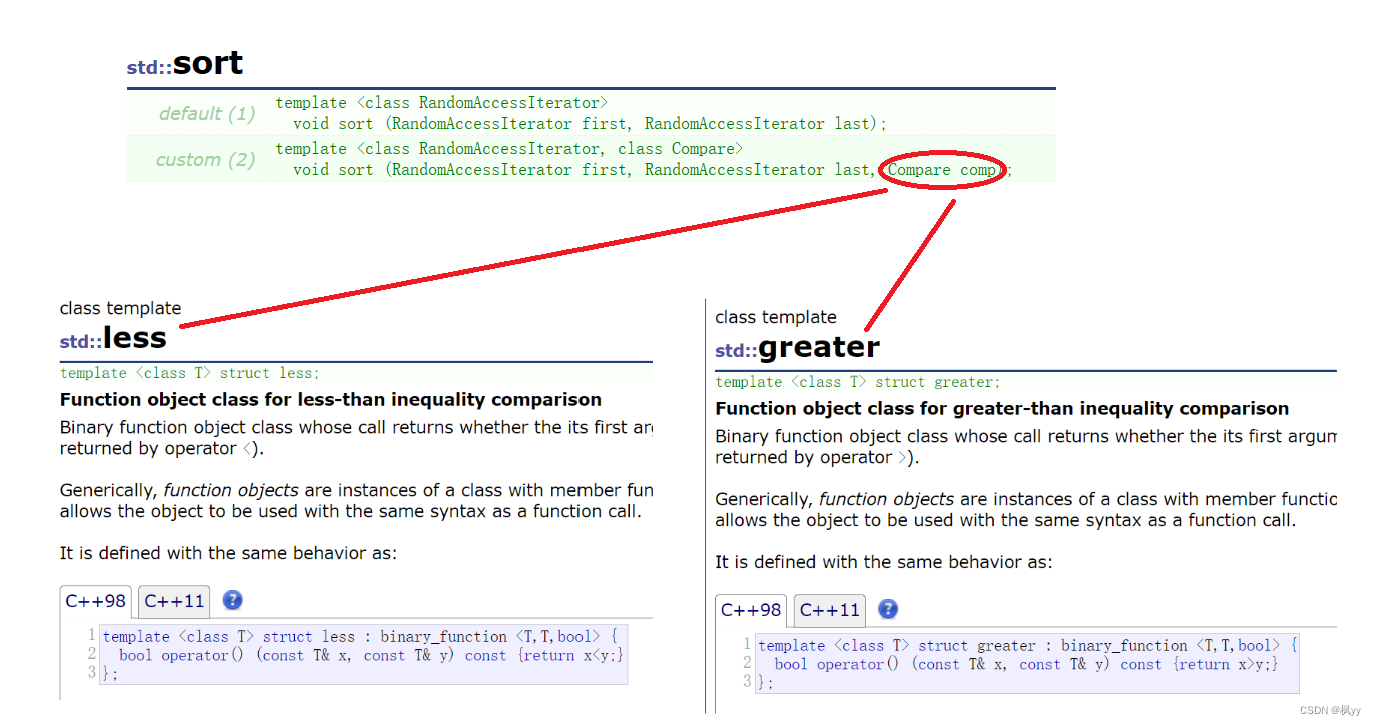
具体使用方法如下代码所示:
void test_vector()
{
vector<int> v1;
v1.push_back(10);
v1.push_back(2);
v1.push_back(30);
v1.push_back(4);
v1.push_back(44);
v1.push_back(4);
v1.push_back(40);
v1.push_back(4);
//sort(v1.begin()+1, v1.end()-1); //除首尾元素的排序
//sort(v1.begin(), v1.begin() + v1.size() / 2); //只排序一半元素
// 默认是升序
// 此处为降序
sort(v1.begin(), v1.end(), greater<int>());
for (const auto& e : v1)
{
cout << e << " ";
}
cout << endl;
}
int main()
{
test_vector();
return 0;
}














 1093
1093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









