







#-*- coding:utf-8 -*-
# doc2pdf.py: python script to convert doc to pdf with bookmarks!
# Requires Office 2007 SP2
# Requires python for win32 extension
import sys, os
from win32com.client import Dispatch, constants, gencache
def doc2pdf(input, output):
w = Dispatch("Word.Application")
try:
doc = w.Documents.Open(input, ReadOnly = 1)
doc.ExportAsFixedFormat(output, constants.wdExportFormatPDF,\
Item = constants.wdExportDocumentWithMarkup, CreateBookmarks = constants.wdExportCreateHeadingBookmarks)
return 0
except:
return 1
finally:
w.Quit(constants.wdDoNotSaveChanges)
# Generate all the support we can.
def GenerateSupport():
# enable python COM support for Word 2007
# this is generated by: makepy.py -i "Microsoft Word 12.0 Object Library"
gencache.EnsureModule('{00020905-0000-0000-C000-000000000046}', 0, 8, 4)
def main():
print(len(sys.argv))
if (len(sys.argv) == 2):
input = sys.argv[1]
output = os.path.splitext(input)[0]+'.pdf'
elif (len(sys.argv) == 3):
input = sys.argv[1]
output = sys.argv[2]
else:
input = u'C:\\Users\\Administrator\\Desktop\stu\\testDocToPdf\\test.docx'#word文档的名称
output = u'C:\\Users\\Administrator\\Desktop\stu\\testDocToPdf\\test.pdf'#pdf文档的名称
if (not os.path.isabs(input)):
input = os.path.abspath(input)
if (not os.path.isabs(output)):
output = os.path.abspath(output)
try:
GenerateSupport()
rc = doc2pdf(input, output)
return rc
except:
return -1
if __name__=='__main__':
print("Hello python!")
rc = main()
if rc:
sys.exit(rc)
sys.exit(0)转换成功!
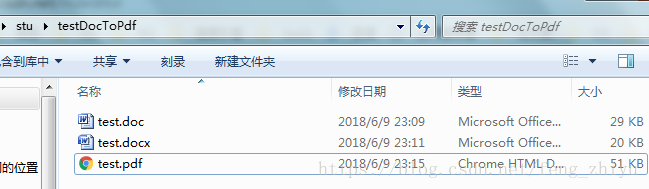
如图:
参考:
https://blog.csdn.net/qq_16645423/article/details/79468122















 3196
3196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









