







nvshmem简介
介绍
nvshmem是nvidia基于openshmem标准实现的高性能通信库,特点如下:
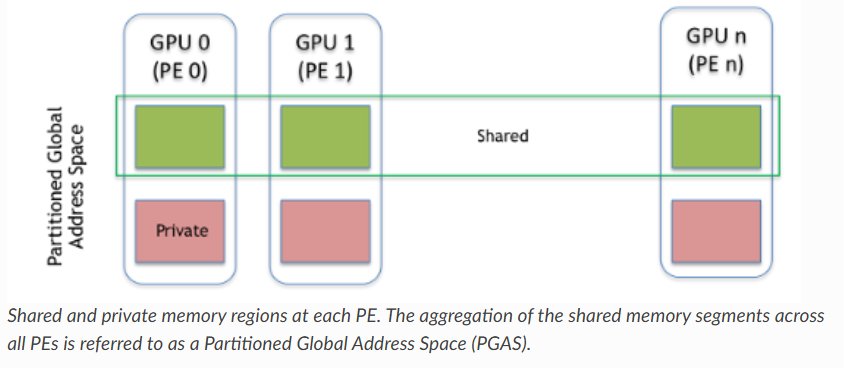
- 支持对称内存,所有GPU的虚拟地址一致,可通过指针直接访问
- 支持host-size和device-size api发起通信操作
集群中参与nvshmem操作的每个进程认为是一个PE(processing element),每个PE分配唯一ID。PE之间可通过对称内存进行通信和数据共享,对称内存通过nvshmem_malloc进行分配,使用其他api分配的内存都是私有的。
官方文档:https://docs.nvidia.com/nvshmem/api/introduction.html
transport
nvshmem支持p2p, ibrc, ibgda等transport,可在编译和运行时通过环境变量控制使能哪个transport。
p2p只能用于node内PE通信,ibrc/ibgda可用于node内和node间PE通信。
编译时
p2p没有编译选项控制,其他transport通过如下环境变量控制
NVSHMEM_IBRC_SUPPORT //默认使能
NVSHMEM_UCX_SUPPORT
NVSHMEM_LIBFABRIC_SUPPORT
NVSHMEM_IBDEVX_SUPPORT
NVSHMEM_IBGDA_SUPPORT
运行时
p2p通过NVSHMEM_DISABLE_P2P控制,ibgda通过NVSHMEM_IB_ENABLE_IBGDA控制,其他transport默认使能
NVSHMEM_DISABLE_P2P
NVSHMEM_IB_ENABLE_IBGDA
ibrc和ibgda的区别可参考:https://developer.nvidia.com/zh-cn/blog/improving-network-performance-of-hpc-systems-using-nvidia-magnum-io-nvshmem-and-gpudirect-async/
API
初始化 api
用来初始化相关资源,其中flag指定bootstrap模式,attributes指定额外信息,比如myrank和nranks
void nvshmem_init(void)
int nvshmemx_init_attr(unsigned int flags, nvshmemx_init_attr_t *attributes)
内存管理 api
用来分配对称内存,需所有PE同时调用
void *nvshmem_malloc(size_t size)
void nvshmem_free(void *ptr)
void *nvshmem_align(size_t alignment, size_t size)
单边操作 api
提供了host-size和device-size api,device-size api还区分thread/warp/block等使用多个的cuda core进行操作
//TYPENAME和TYPE为nvshem支持的数据类型,比如int,long等
//操作多个元素
void nvshmem_TYPENAME_put(TYPE *dest, const TYPE *source, size_t nelems, int pe)
void nvshmemx_TYPENAME_put_on_stream(TYPE *dest, const TYPE *source, size_t nelems, int pe, cudaStream_t stream)
__device__ void nvshmem_TYPENAME_put(TYPE *dest, const TYPE *source, size_t nelems, int pe)
__device__ void nvshmemx_TYPENAME_put_block(TYPE *dest, const TYPE *source, size_t nelems, int pe)
__device__ void nvshmemx_TYPENAME_put_warp(TYPE *dest, const TYPE *source, size_t nelems, int pe)
//操作单个元素
void nvshmem_TYPENAME_p(TYPE *dest, TYPE value, int pe)
__device__ void nvshmem_TYPENAME_p(TYPE *dest, TYPE value, int pe)
集合通信 api
nvshmem提供了reducescatter, allreduce, allgather, broadcat和all2all等集合通信api。
提供了host-size和device-size api,device-size api还区分thread/warp/block等使用多个的cuda core进行操作
int nvshmem_TYPENAME_alltoall(nvshmem_team_t team, TYPE *dest, const TYPE *source, size_t nelems)
int nvshmemx_TYPENAME_alltoall_on_stream(nvshmem_team_t team, TYPE *dest, const TYPE *source, size_t nelems, cudaStream_t stream)
__device__ int nvshmem_TYPENAME_alltoall(nvshmem_team_t team, TYPE *dest, const TYPE *source, size_t nelems)
__device__ int nvshmemx_TYPENAME_alltoall_block(nvshmem_team_t team, TYPE *dest, const TYPE *source, size_t nelems)
__device__ int nvshmemx_TYPENAME_alltoall_warp(nvshmem_team_t team, TYPE *dest, const TYPE *source, size_t nelems)
host-size api集合通信也支持调用nccl api,比如all2all调用nccl的send/recv实现
template <typename TYPE>
int nvshmemi_alltoall_on_stream(nvshmem_team_t team, TYPE *dest, const TYPE *source, size_t nelems,
cudaStream_t stream) {
#ifdef NVSHMEM_USE_NCCL
nvshmemi_team_t *teami = nvshmemi_team_pool[team];
int team_n_pes = nvshmem_team_n_pes(team);
if (nvshmemi_use_nccl && nvshmemi_get_nccl_dt<TYPE>() != ncclNumTypes &&
((nccl_version >= 2700 && team_n_pes <= 4096 /* NCCL limit for Group API */) ||
(nccl_version >= 2800 && team_n_pes <= 32768 /* NCCL limit for Group API */))) {
size_t rank_offset = nelems * sizeof(TYPE);
NCCL_CHECK(nccl_ftable.GroupStart());
for (int pe = 0; pe < team_n_pes; pe++) {
NCCL_CHECK(nccl_ftable.Send(((char *)source) + pe * rank_offset, nelems,
nvshmemi_get_nccl_dt<TYPE>(), pe,
(ncclComm_t)teami->nccl_comm, stream));
NCCL_CHECK(nccl_ftable.Recv(((char *)dest) + pe * rank_offset, nelems,
nvshmemi_get_nccl_dt<TYPE>(), pe,
(ncclComm_t)teami->nccl_comm, stream));
}
NCCL_CHECK(nccl_ftable.GroupEnd());
} else
#endif /* NVSHMEM_USE_NCCL */
{
nvshmemi_call_alltoall_on_stream_kernel<TYPE>(team, dest, source, nelems, stream);
}
return 0;
}
nvshmem例子
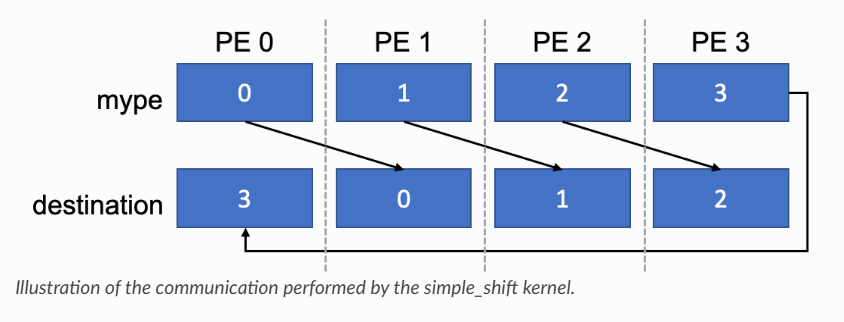
通过此例子熟悉nvshmem用法,功能为每个PE将自己的id发送到相邻的下一个PE
#include <stdio.h>
#include <cuda.h>
#include <nvshmem.h>
#include <nvshmemx.h>
__global__ void simple_shift(int *destination) {
int mype = nvshmem_my_pe();
int npes = nvshmem_n_pes();
int peer = (mype + 1) % npes;
nvshmem_int_p(destination, mype, peer);
}
int main(void) {
int mype_node, msg;
cudaStream_t stream;
nvshmem_init();
mype_node = nvshmem_team_my_pe(NVSHMEMX_TEAM_NODE);
cudaSetDevice(mype_node);
cudaStreamCreate(&stream);
int *destination = (int *) nvshmem_malloc(sizeof(int));
simple_shift<<<1, 1, 0, stream>>>(destination);
nvshmemx_barrier_all_on_stream(stream);
cudaMemcpyAsync(&msg, destination, sizeof(int), cudaMemcpyDeviceToHost, stream);
cudaStreamSynchronize(stream);
printf("%d: received message %d\n", nvshmem_my_pe(), msg);
nvshmem_free(destination);
nvshmem_finalize();
return 0;
}
//执行结果
mpirun --mca btl_tcp_if_include eth0 --allow-run-as-root --prefix /root/host/openmpi-4.1.3/build/ --hostfile /root/hostfile -x NVSHMEM_BOOTSTRAP=MPI -x NVSHMEM_IB_GID_INDEX=3 -x LD_LIBRARY_PATH=/root/deepep/nvshmem_src/install/lib:/root/host/openmpi-4.1.3/build/lib:/root/deepep/gdrcopy-2.4.4/build/lib -x NVSHMEM_ENABLE_NIC_PE_MAPPING=1 -x NVSHMEM_HCA_LIST=^mlx5_3:1,mlx5_4 /root/deepep/nvshmem_src/install/bin/examples/ring-bcast
1: received message 0
5: received message 4
4: received message 3
2: received message 1
7: received message 6
0: received message 7
3: received message 2
6: received message 5
nvshmem处理流程
nvshmem初始化
a. bootstrap初始化
nvshmem支持MPI, PMI, SHMEM和UID等多种bootstrap模式,可通过nvshmemx_init_attr的参数flag或者环境变量NVSHMEM_BOOTSTRAP指定,bootstrap提供了allgather,alltoall等接口在集群中传递信息
b. memory初始化
使用cuda vmm机制实现内存管理,初始化只是申请虚拟地址,后续申请内存时再分配物理内存,并映射到对应的虚拟地址,可参考:https://developer.nvidia.com/blog/introducing-low-level-gpu-virtual-memory-management/
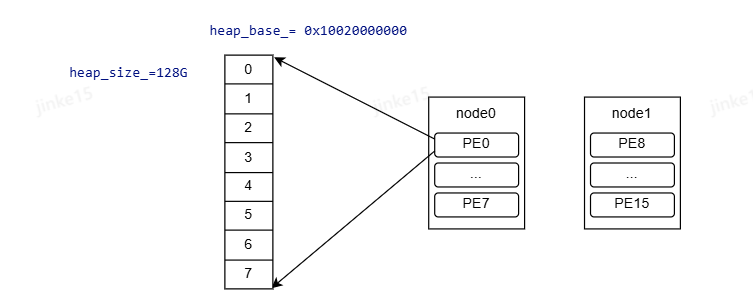
每个PE申请虚拟地址起始值为heap_base_,大小为heap_size_*p2p_npes,即包含node内所有PE,每个PE对应的虚拟地址大小为heap_size_(128G)。
不管同node还是跨node,每个PE的虚拟地址都是相同的。
nvshmem_malloc申请内存时将不同PE的物理内存映射到PE对应的虚拟地址,实现对其他PE内存的访问
c. transport初始化
以ibrc和ibgda为例,transport初始化主要是rdma qp的建立。
对ibrc来说,一个网卡建立的qp个数为: n_pes * qp_count,其中n_pes为集群PE个数,qp_count为网卡和每个peer建立的qp个数,代码中为固定值2,一个qp给proxy使用,一个qp给host-size api使用
对ibgda来说,一个网卡建立的qp个数为: n_pes * num_rc_eps_per_pe,其中num_rc_eps_per_pe可通过环境变量NVSHMEM_IBGDA_NUM_RC_PER_PE指定
nvshmem_malloc
分配内存主要流程如下:
- 分配PINNED物理内存,将物理内存映射到本PE对应的虚拟地址
- 获取物理内存句柄,通过bootstrap传播给其他PE,其他PE导入此句柄,实现同node对本PE内存访问
- 通过ibv_reg_mr将虚拟地址注册到网卡,获取对应的lkey和rkey,将虚拟地址和key通过bootstrap传播给其他PE,实现跨node其他PE对本PE内存访问
比如调用nvshmem_malloc分配100M内存
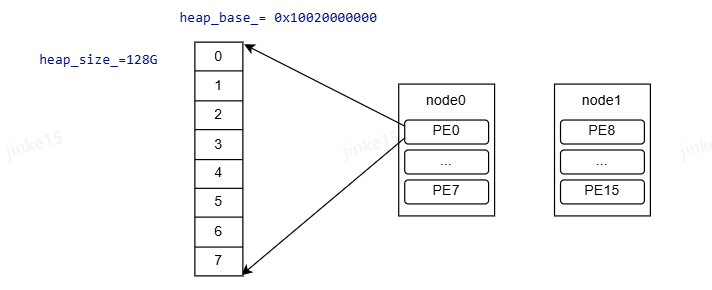
PE0访问PE7内存的地址为:0x10020000000+128G*7=0x1e020000000
PE0访问PE8内存的地址为:0x10020000000
PE0访问PE15内存的地址为: 0x10020000000
nvshmem_int_p
a. 主机侧发起
- 如果peer在本node,则调用cudaMemcpyAsync实现
- 如果peer在其他node,则由主机cpu调用ibv_post_send通知网卡进行数据发送(使用第一个qp)
b. 设备侧发起
- 如果peer在本node,则调用cude kernel实现内存拷贝
- 如果peer不在本node,还要分两种情况 使能igbda,由cuda core调用ibgda_post_send通知网卡进行数据发送未使能igbda,由cuda core通知proxy线程,proxy线程调用ibv_post_send通知网卡进行数据发送(使用第二个qp)
nvshmem在deepep中的使用
deepep提供了高效的all2all通信,但并未直接使用nvshmem中的集合通信all2all api,而是使用nvshmem的ibrc和ibgda transport实现node间rank的通信,使用cuda ipc实现node内rank的通信。
deepep使用nvshmemx_init_attr进行nvshmem的初始化,通过flag指定bootstrap模式为UID,通过attr指定root_unique_id,rank和num_ranks等信息。
root_unique_id为root rank的ip和端口组合,通过pytorch的dist.all_gather_object传播给其他rank,其他rank通过root_unique_id和root rank交互,从而获取集群所有rank的连接方式。
nvshmemx_uniqueid_t root_unique_id;
nvshmemx_init_attr_t attr;
std::memcpy(&root_unique_id, root_unique_id_val.data(), sizeof(nvshmemx_uniqueid_t));
nvshmemx_set_attr_uniqueid_args(rank, num_ranks, &root_unique_id, &attr);
nvshmemx_init_attr(NVSHMEMX_INIT_WITH_UNIQUEID, &attr);
编译环境变量
CUDA_HOME=/path/to/cuda \
GDRCOPY_HOME=/path/to/gdrcopy \
NVSHMEM_SHMEM_SUPPORT=0 \
NVSHMEM_UCX_SUPPORT=0 \
NVSHMEM_USE_NCCL=0 \
NVSHMEM_MPI_SUPPORT=0 \
NVSHMEM_IBGDA_SUPPORT=1 \
NVSHMEM_PMIX_SUPPORT=0 \
NVSHMEM_TIMEOUT_DEVICE_POLLING=0 \
NVSHMEM_USE_GDRCOPY=1 \
cmake -S . -B build/ -DCMAKE_INSTALL_PREFIX=/path/to/your/dir/to/install
高带宽kernel
node间同号rank通过nvshmem ibrc通信,node内rank使用cuda ipc通信。
node0上8个rank都需要获取unique_id,并传播给同号rank。
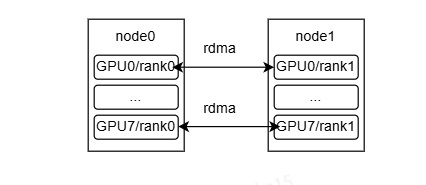
通信时node内通过同号rank发送,到了同号rank后再通过nvlink转发到目的rank。
低延时kernel
node间和node内rank通信均使用nvshmem ibgda,即使node内rank通信也不用p2p transport,减少rdma到nvlink报文的转发带来的延迟
os.environ['NVSHMEM_DISABLE_P2P'] = '1'
os.environ['NVSHMEM_IB_ENABLE_IBGDA'] = '1'
os.environ['NVSHMEM_IBGDA_NIC_HANDLER'] = 'gpu'
os.environ['NVSHMEM_IBGDA_NUM_RC_PER_PE'] = f'{num_qps_per_rank}'
# Make sure QP depth is always larger than the number of on-flight WRs, so that we can skip WQ slot check
os.environ['NVSHMEM_QP_DEPTH'] = '1024'
# NOTES: NVSHMEM initialization requires at least 256 MiB
os.environ['NVSHMEM_CUMEM_GRANULARITY'] = f'{2 ** 29}'
只有rank 0获取unique_id,并传播给所有rank。
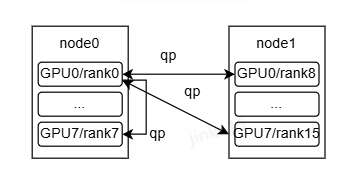
每个网卡创建的qp数量为: num_rc_eps_per_pe * n_pes,num_rc_eps_per_pe为本rank专家个数。
在两机16卡的情况下,假设专家个数288(256路由专家+32冗余专家),则每个卡上专家个数为18,即num_rc_eps_per_pe为18,网卡创建的qp数量为288。
通信时通过同号qp发给其他所有rank。
Support NVLink protocol for intranode low-latency kernels (conflict with hook-based overlapping)
低延时模式同主机gpu通信为什么不用nvlink?nvlink会占用SM,而使用rdma可由网卡自动完成数据传输,不占用sm,可做到计算和通信overlap
Enable IBGDA for the low latency mode, which refers to “no package forwarding between NVLink and RDMA”
低延时模式跨主机gpu通信为什么不用nvlink?需要先转到同号卡,同号卡再转给目的卡,增加了延迟


















 45
45

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











