







 超级会员免费看
超级会员免费看
1. 内存同步域
1.1. 内存栅栏干扰
部分CUDA应用程序可能因内存栅栏/刷新操作需等待超出CUDA内存一致性模型要求范围的内存事务,从而导致性能下降。
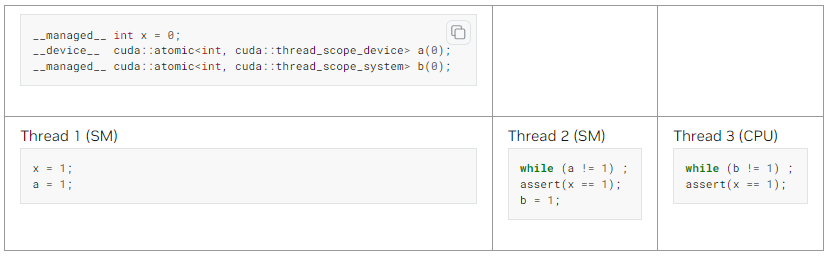
以观察上述示例。根据CUDA内存一致性模型的保证,断言条件必然成立,这意味着线程1对变量x的写入必须在线程2对b的写入之前,对线程3可见。
通过原子变量a的release-acquire操作所提供的内存序仅能确保x对线程2可见(因其作用域限于设备内部),而无法保证对线程3的可见性。因此,原子变量b通过系统级作用域(system-scope)的release-acquire内存序,不仅需要确保线程2自身的写入对线程3可见,还必须保证那些已对线程2可见的其他线程写入也能被线程3观测到——这一特性被称为"累积性(cumulativity)"。由于GPU在执行时无法区分哪些写入在源码层面已被严格同步、哪些仅因时序巧合而可见,它必须采取保守策略,广泛捕获所有执行中的内存操作。
这种机制有时会导致干扰现象:由于GPU需要等待一些在源码层面本无需等待的内存操作,使得栅栏/刷新操作的执行时间可能超出必要时长。
需特别说明的是,内存栅栏既可能显式地表现为代码中的原子操作或内在函数(如示例所示),也可能隐式地作用于任务边界处,用于实现"同步于(synchronizes-with)"关系。
典型场景是:当一个内核正在本地GPU内存执行计算时,另一个并行内核

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











