






今天的讨论比较玄学,至于为什么用曹雪芹的诗当封面,看完文章明白啦。
目录
背景
玄学立论
娓娓道来
后话
背景
之前在知乎上回答了一个类似的问题,他们问为什么很多领域的比赛数据集上的GBDT效果那么好(比神经网络)。
回答这个问题前,先引入一个概念,目标的非线性。
非线性,应该是从原始输入到目标决策之间gap的刻画,用博大精深的中文语言为例:
比如垃圾话,就很直白,无非是问候几个人物,几个器官,几个行为。可以望文生义。
但是阴阳话,这个就非常难了。
感恩两字,你要看他真的感恩,还是在那里只能咸因。威武支持有希望了,你看他是不是在叼飞盘,这就很难。
这些都要看具体的场景,人物和环境,这就叫非线性。
人的解决问题,大概就是把一个复杂目标化简解决的能力,目的是降低问题的非线性,把一个问题去解决的过程。具体到数据挖掘上,应该是把特征表达出来的能力。
具体到问题,非线性比较高的场景有,序列建模,大规模离散ID建模,阴阳话识别,语音的特征表达。这些都是非线性非常高的场景,基本都超出了手动解决输入到目标之间gap的能力。
玄学立论
先用一个玄学的图来立论。
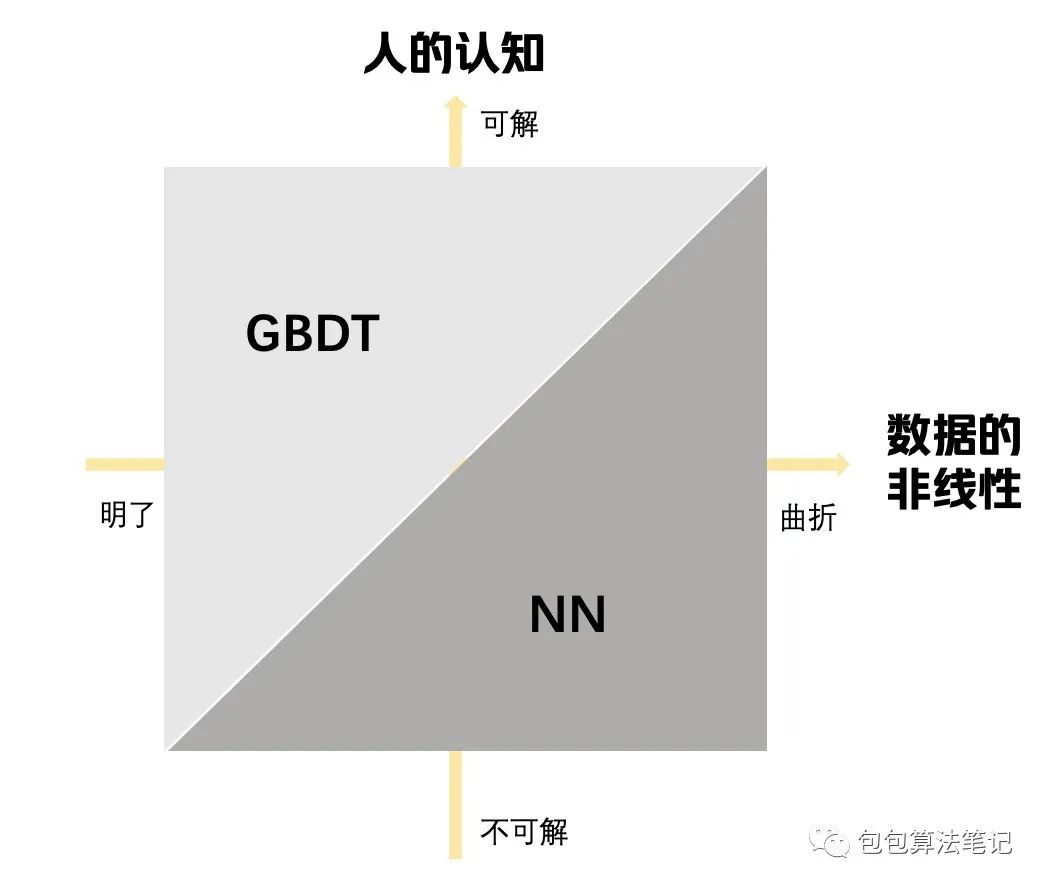
简而言之当你的认知超越问题的难度时候,可以通过一些方法把问题去复杂化,一般GBDT的效果会比NN好。
可这话真的太晦涩了。
我们回到之前的知乎上回答看看吧。
娓娓道来
先来几个问题作为引子吧,在回答为什么在实际的kaggle比赛中,GBDT效果非常好?
Q1.kaggle上的数据和赛题有什么特点?
Q2.GBDT和NN有什么特点?
Q3.为什么你很少看见Kaggle上用SVM LR立大功?
Q4.怎么根据数据特点进行模型选型?
Q5.近三年,有哪些非CV和NLP,Speech的比赛上印证了NN和GBDT的江湖地位之争
一句话来回答,本质上还是由数据和模型决定的。
再来说一下为什么kaggle里给你一种GBDT满天飞的感觉。
来到Q1kaggle上的数据和赛题有什么特点?
跟现在研究生入学,大部分用深度学习怼图片文本不一样,以前kaggle赛题,尤其是2019年前,有很大比例是工业界的表格数据。比如各种实际的预测预估任务,CTR,信用评分,销量预测等。他们有如下几个特点。
1.工业界的数据脏。异常点,缺失值,历史遗留问题造成的数据痕迹等等。
2.工业界的数据可解释性很强,每一列有真实的业务含义。
在以上背景下,再来到Q2.GBDT和NN有什么特点?
我们理一下树模型天然的优点
1.天然的鲁棒性,能自动从异常点,缺失值学到信息。不需要归一化。直接上手一把梭哈。
2.树可以半自动化地完成一些特征非线性表达的工作,而且基于贪心切分+采样等抗过拟合手段,能比较好的挖掘数据的非线性。
3.树的可解释性很好,能生产特征重要性,帮助你理解数据,改善特征工程。一个经典的套路是思考topN特征背后的逻辑,并围绕他们进行特征工程。
我们理一下NN模型的优点:
1.全自动化的特征工程和登峰造极的非线性表达能力,在数据表征范式统一,语义含义统一的稠密数据上(典型文本图像)上,NN一个打十个。另外,典型的像ID序列这种,人很难做出花来。也就是Bag of words或者借用embedding表达一下,还有一半是NN的功劳。
2.NN模型容量极大,在数据量的加持上,放大了1的优势。
给你们整个表吧
| 优势 | 劣势 | |
|---|---|---|
| GBDT | 1.鲁棒,异常点,缺失值都是可以学习的信息 2.适中的非线性能力,在一定范围内是优势3.可解释性很好,可以帮你优化特征工程 | 1.非线性表达能力有限,很难在文本图像上有用。 2.数据量带来的边际增益不大,容易触及天花板。 |
| NN | 1.全自动化的特征工程 2.模型容量大,可以利用数据量的优势 | 1.异常值敏感,依赖手动处理 2.不可解释,改进迭代的过程有点像蒙特卡洛,措施和结果的路径太远。3.过强的非线性中隐含过拟合和噪音。 |
但是看起来LGB的优点在其他模型也有,那么Q3为什么不是SVM和LR?
1.这两种模型获取非线性的方式太粗暴了,有种大炮打蚊子的感觉。依靠kernel强行把VC维提高,带来的噪声特别多,有用信息很少,并且kernal是有先验的,很容易被人设的参数带跑偏。这在实际业务数据中是非常致命的。
2.理论上LR+完美的特征工程可以很强,但是太难了,又不是人人都是特征工程大师。早期凤巢亿级特征跑LR效果特别好逐渐成为传说。
说了那么多,那么我们到Q4.怎么根据数据特点进行模型选型?
前面讲了很多了,大概可以从这4方面来的。A.数据量大小 B.数据到预测目标的非线性C.单列数据可解释性D.特征工程天花板高低
XGB/LGB/CTB在最后两个上很有优势。NN在前两个方面很有优势。
Q5.近三年,有哪些非CV和NLP,Speech的比赛上印证了NN和GBDT的江湖地位之争
NN胜出的比赛
第一个
Google Brain - Ventilator Pressure Prediction
这个比赛是医学数据,表结构。干的事情是根据呼吸机的呼吸阀百分比来预测压力。
Transfoermer+特征工程在排行榜上单模型可以杀到金牌。
示例代码:
TensorFlow Transformer - [0.112]
第二个
Riiid Answer Correctness Prediction
这个题目是根据学生历史学习情况,预测做题表现。
Transfoermer+特征工程胜出。
示例代码:
Riiid LGBM bagging2 + SAKT =0.781
GBDT完胜的比赛。
这部分就比较多了,不详细介绍了。
IEEE-CIS Fraud Detection | Kaggle
Elo Merchant Category Recommendation
Home Credit Default Risk
后话
好风凭借力,送我上青云。
力,就是人的主观能动性。
风,是模型本身的潜力。
风好不好,要看具体的问题。主观能动性的力量很强,但也是有天花板的。
在合适的问题上,选择合适的模型,发挥你的主观能动性。
这大概也是大部分问题的解决方式吧。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载黄海广老师《机器学习课程》视频课黄海广老师《机器学习课程》711页完整版课件本站qq群955171419,加入微信群请扫码:
















 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









