






编辑:Peter
作者:Peter
今天给大家介绍如何基于MLxtend扩展包绘制5种机器学习分类模型的决策边界。
自适应神经元二分类器Adative Linear Neuron Classifier
逻辑回归分类器LogisticRegression
多层感知机分类器MultillayerPerceptron
集成投票分类器EnsembleVoteClassifier
堆叠分类器StackingClassifier
导入库
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from matplotlib import cm
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
import itertools
from sklearn import datasets
from sklearn.linear_model import LogisticRegression # 逻辑回归分类
from sklearn.svm import SVC # SVC
from sklearn.ensemble import RandomForestClassifier # 随机森林分类
from mlxtend.classifier import Adaline, EnsembleVoteClassifier # 从mlxtend导入多个模型
from mlxtend.data import iris_data # 内置数据集
from mlxtend.plotting import plot_decision_regions # 绘制决策边界
import warnings
warnings.filterwarnings('ignore')自适应神经元分类器Adaline(Adaptive Linear Neuron Classifier)
X,y = iris_data()
X = X[:, [0,3]]
X = X[0:100]
y = y[0:100]X[:5]array([[5.1, 0.2],
[4.9, 0.2],
[4.7, 0.2],
[4.6, 0.2],
[5. , 0.2]])y[:10]array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])数据标准化过程:
X[:,0] = (X[:,0] - X[:,0].mean()) / X[:,0].std()
X[:,1] = (X[:,1] - X[:,1].mean()) / X[:,0].std()ada = Adaline(epochs=30, eta=0.01, minibatches=None, random_seed=1) # closed form
ada.fit(X,y)plot_decision_regions(X,y,clf=ada)
plt.title("Adaline-Closed form for Classifier")
plt.show()
ada = Adaline(epochs=30, eta=0.01, minibatches=1, random_seed=1,print_progress=3) # gradient descent
ada.fit(X,y)
plot_decision_regions(X,y,clf=ada)
plt.title("Adaline-Gradient Descent for Classifier")
plt.show()
plt.plot(range(len(ada.cost_)), ada.cost_)
plt.xlabel('Iterations')
plt.ylabel('Cost')Iteration: 30/30 | Cost 3.81 | Elapsed: 0:00:00 | ETA: 0:00:0000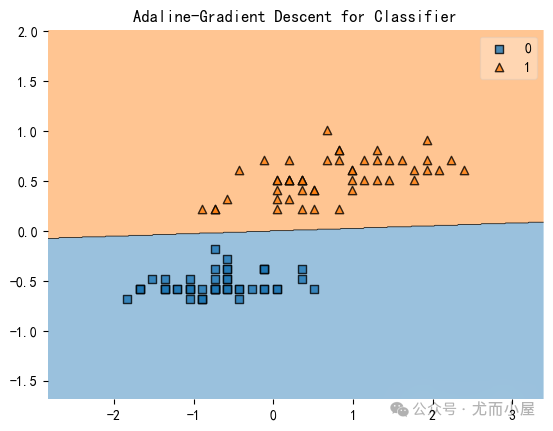
Text(0, 0.5, 'Cost')

ada = Adaline(epochs=15,
eta=0.02,
minibatches=len(y), # SGD learning
random_seed=1,
print_progress=3)
ada.fit(X,y)
plot_decision_regions(X,y,clf=ada)
plt.title("Adaline-Stochastic Gradient Descent for Classifier")
plt.show()
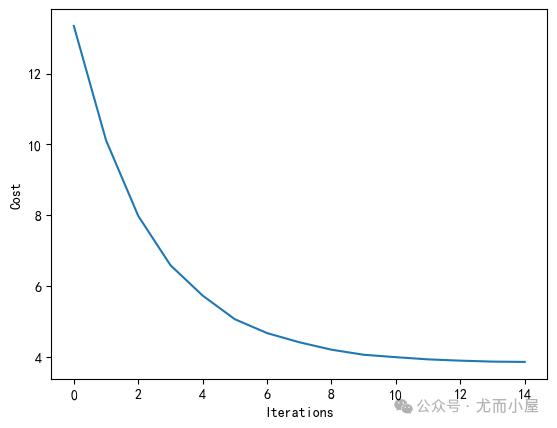
plt.plot(range(len(ada.cost_)), ada.cost_)
plt.xlabel('Iterations')
plt.ylabel('Cost')Iteration: 15/15 | Cost 3.85 | Elapsed: 0:00:00 | ETA: 0:00:0000
Text(0, 0.5, 'Cost')
逻辑回归LogisticRegression(二分类器)
https://rasbt.github.io/mlxtend/user_guide/classifier/LogisticRegression/
from mlxtend.data import iris_data
from mlxtend.plotting import plot_decision_regions
from mlxtend.classifier import LogisticRegression
import matplotlib.pyplot as plt
# 生成数据
X, y = iris_data()
X = X[:, [0, 3]]
X = X[0:100]
y = y[0:100]
# 数据标准化
X[:,0] = (X[:,0] - X[:,0].mean()) / X[:,0].std()
X[:,1] = (X[:,1] - X[:,1].mean()) / X[:,1].std()
lr = LogisticRegression(
eta=0.1,
l2_lambda=0.0,
epochs=100,
minibatches=1, # 梯度下降 (GD) 默认是1
#minibatches=5, # SGD with Minibatches
#minibatches=len(y), # 随机梯度下降(SGD)
random_seed=1,
print_progress=3)
lr.fit(X, y)
plot_decision_regions(X, y, clf=lr)
plt.title('Logistic Regression - Gradient Descent')
plt.show()
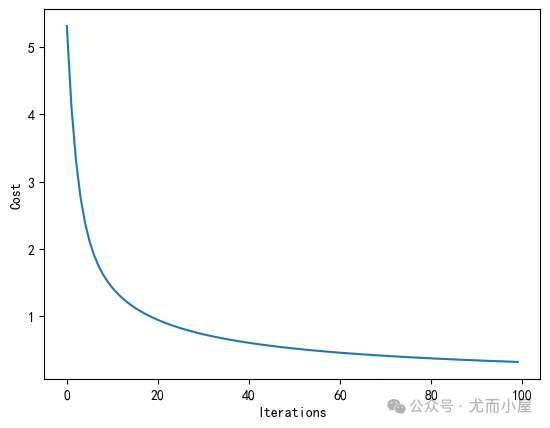
plt.plot(range(len(lr.cost_)), lr.cost_)
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.show()Iteration: 100/100 | Cost 0.32 | Elapsed: 0:00:00 | ETA: 0:00:00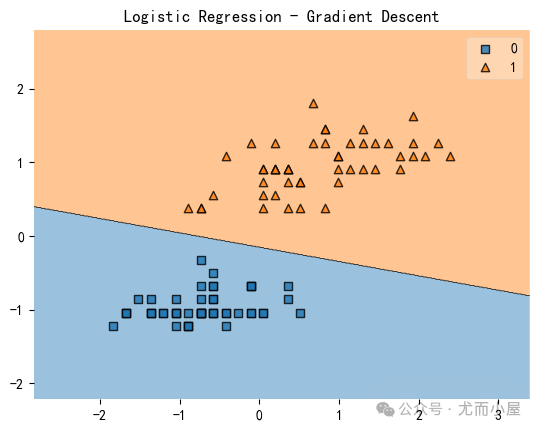
模型预测的最终类别及对应概率:
lr.predict(X)[:3]array([0, 0, 0])lr.predict_proba(X)[-3:]array([0.99997968, 0.99339873, 0.99992707])多层感知机分类器MultilayerPerceptron-MLP
MLP模型:https://rasbt.github.io/mlxtend/user_guide/classifier/MultiLayerPerceptron/
感知机模型:https://rasbt.github.io/mlxtend/user_guide/classifier/Perceptron/
from mlxtend.classifier import MultiLayerPerceptron as MLP
# from mlxtend.classifier import Perceptron 也可以使用感知机基于MLP的iris数据分类
from mlxtend.data import iris_data
X, y = iris_data()
X = X[:, [0, 3]]
# 数据标准化
X_std = (X - X.mean(axis=0)) / X.std(axis=0)建立MLP模型:
mlp = MLP( # 或者Perceptron模型
hidden_layers=[50],
l1=0.0,
l2=0.0,
epochs=150,
eta=0.05,
momentum=0.1,
decrease_const=0.0,
minibatches=1, # Gradient Descent
#minibatches=len(y), # Stochastic Gradient Descent
random_seed=1,
print_progress=3
)
mlp.fit(X_std, y)Iteration: 150/150 | Cost 0.06 | Elapsed: 0:00:00 | ETA: 0:00:000
<mlxtend.classifier.multilayerperceptron.MultiLayerPerceptron at 0x2565add0c90>绘制分类模型决策边界:
from mlxtend.plotting import plot_decision_regions
import matplotlib.pyplot as plt
fig = plot_decision_regions(X=X_std, y=y, clf=mlp, legend=2)
plt.title('Multi-Layer-Perceptron w. 50 hidden layer (logistic sigmoid)')
plt.show()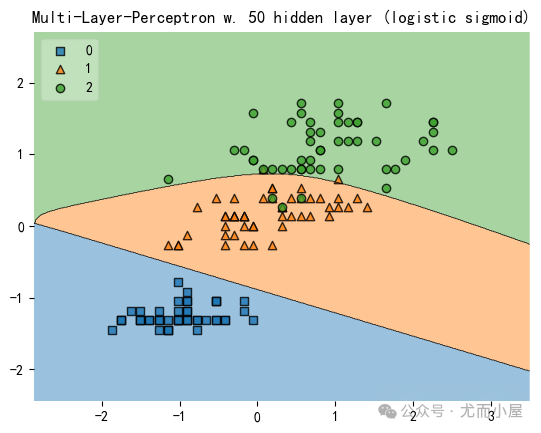
绘制模型损失变化趋势:
import matplotlib.pyplot as plt
plt.plot(range(len(mlp.cost_)), mlp.cost_)
plt.ylabel('Cost')
plt.xlabel('Epochs')
plt.show()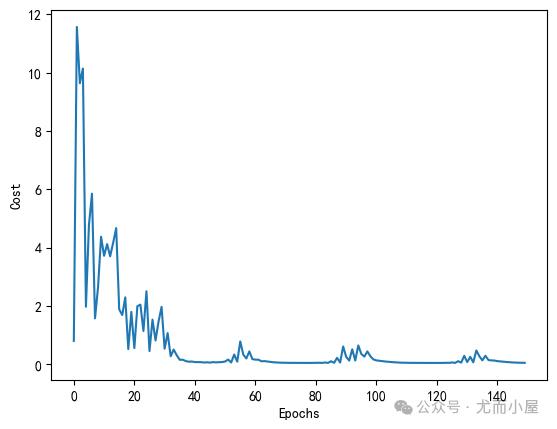
print('Accuracy: %.2f%%' % (100 * mlp.score(X_std, y)))
Accuracy: 96.67%10% MINIST Subset数据集分类
from mlxtend.data import mnist_data
from mlxtend.preprocessing import shuffle_arrays_unison
X, y = mnist_data()
X, y = shuffle_arrays_unison((X, y), random_seed=1) # 打乱数据
X_train, y_train = X[:500], y[:500] # 取出前10%的数据
X_test, y_test = X[500:], y[500:]1、显示某个具体的图片:
import matplotlib.pyplot as plt
def plot_digit(X,y,idx):
img = X[idx].reshape(28,28)
plt.imshow(img, cmap="Greys", interpolation="nearest")
plt.title("True Label: %d" % y[idx])
plt.show()
plot_digit(X,y,2800)
2、数据标准化
from mlxtend.preprocessing import standardize# 训练集归一化;返回参数params
X_train_std, params = standardize(X_train, columns=range(X_train.shape[1]),return_params=True)用训练集返回的参数对测试集进行归一化:
X_test_std = standardize(X_test, columns=range(X_test.shape[1]), params=params)3、建立MLP模型
mlp = MLP(
hidden_layers=[150],
l2=0.00,
l1=0.0,
epochs=100,
eta=0.005,
momentum=0.0,
decrease_const=0.0,
minibatches=100,
random_seed=1,
print_progress=3
)
mlp.fit(X_train_std, y_train)Iteration: 100/100 | Cost 0.01 | Elapsed: 0:00:13 | ETA: 0:00:00
<mlxtend.classifier.multilayerperceptron.MultiLayerPerceptron at 0x2565ae37c90>4、模型损失可视化
import matplotlib.pyplot as plt
plt.plot(range(len(mlp.cost_)), mlp.cost_)
plt.ylabel('Cost')
plt.xlabel('Epochs')
plt.show()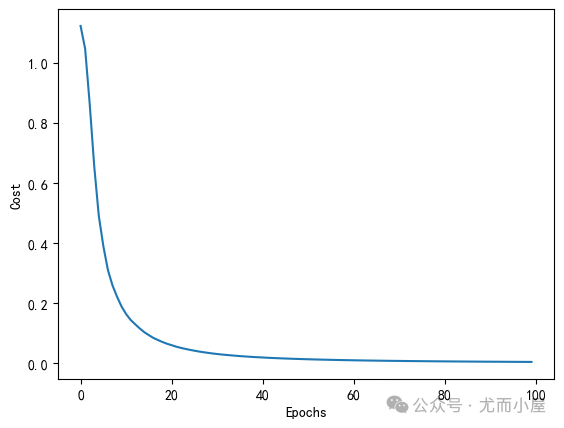
5、模型准确率评估
print('Train Accuracy: %.2f%%' % (100 * mlp.score(X_train_std, y_train)))
print('Test Accuracy: %.2f%%' % (100 * mlp.score(X_test_std, y_test)))
Train Accuracy: 100.00%
Test Accuracy: 84.62%集成投票分类器EnsembleVoteClassifier(多分类投票表决)
使用不同分类模型解决分类预测
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
import numpy as npfrom sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target1、建立不同的分类模型:
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()labels = ["LR","RandomForest","Naive Bayes"]
for clf, label in zip([clf1, clf2, clf3], labels):
scores = model_selection.cross_val_score(clf,X,y,cv=5,scoring="accuracy")
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))Accuracy: 0.95 (+/- 0.04) [LR]
Accuracy: 0.94 (+/- 0.04) [RandomForest]
Accuracy: 0.91 (+/- 0.04) [Naive Bayes]2、创建集成投票表决分类器模型实例:
from mlxtend.classifier import EnsembleVoteClassifier # 集成投票表决分类器
eclf = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3], weights=[1,1,1])# 基于集成模型的预测
labels = ["LR","RandomForest","Naive Bayes","EnsembleVote"]
for clf, label in zip([clf1, clf2, clf3, eclf], labels):
scores = model_selection.cross_val_score(clf,X,y,cv=5,scoring="accuracy")
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))Accuracy: 0.95 (+/- 0.04) [LR]
Accuracy: 0.94 (+/- 0.04) [RandomForest]
Accuracy: 0.91 (+/- 0.04) [Naive Bayes]
Accuracy: 0.95 (+/- 0.04) [EnsembleVote]3、绘制决策边界:
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_decision_regions
import matplotlib.gridspec as gridspec
import itertoolsgs = gridspec.GridSpec(2,2)
fig = plt.figure(figsize=(10,8))
labels = ["LR","RandomForest","Naive Bayes","EnsembleVote"]
for clf, lab, grd in zip([clf1, clf2, clf3, eclf],
labels,
itertools.product([0,1], repeat=2)):
clf.fit(X,y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf)
plt.title(lab)
使用不同分类模型预测网格搜索GridSearch
# 导入数据
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data, iris.target# 创建不同的模型
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
eclf = EnsembleVoteClassifier(clfs=[clf1,clf1, clf2, clf3], voting='soft') # 同一个模型多次出现# 实施网格搜索
from sklearn.model_selection import GridSearchCV
# 参数组合
params = {"logisticregression-1__C":[1.0, 100.0], # 参数组合使用自然数递增方式
"logisticregression-2__C":[1.0, 100.0],
"randomforestclassifier__n_estimators": [20,200]}
grid = GridSearchCV(estimator=eclf, param_grid=params, cv=5)
grid.fit(X,y)cv_keys = ("mean_test_score", "std_test_score", "params")
for r, _ in enumerate(grid.cv_results_["mean_test_score"]):
print("%0.3f +/- %0.2f %r"
%(grid.cv_results_[cv_keys[0]][r],
grid.cv_results_[cv_keys[1]][r] / 2.0,
grid.cv_results_[cv_keys[2]][r]))0.953 +/- 0.01 {'logisticregression-1__C': 1.0, 'logisticregression-2__C': 1.0, 'randomforestclassifier__n_estimators': 20}
0.960 +/- 0.01 {'logisticregression-1__C': 1.0, 'logisticregression-2__C': 1.0, 'randomforestclassifier__n_estimators': 200}
0.960 +/- 0.01 {'logisticregression-1__C': 1.0, 'logisticregression-2__C': 100.0, 'randomforestclassifier__n_estimators': 20}
0.960 +/- 0.01 {'logisticregression-1__C': 1.0, 'logisticregression-2__C': 100.0, 'randomforestclassifier__n_estimators': 200}
0.960 +/- 0.01 {'logisticregression-1__C': 100.0, 'logisticregression-2__C': 1.0, 'randomforestclassifier__n_estimators': 20}
0.960 +/- 0.01 {'logisticregression-1__C': 100.0, 'logisticregression-2__C': 1.0, 'randomforestclassifier__n_estimators': 200}
0.960 +/- 0.01 {'logisticregression-1__C': 100.0, 'logisticregression-2__C': 100.0, 'randomforestclassifier__n_estimators': 20}
0.960 +/- 0.01 {'logisticregression-1__C': 100.0, 'logisticregression-2__C': 100.0, 'randomforestclassifier__n_estimators': 200}grid.best_params_ # 最佳参数组合
{'logisticregression-1__C': 1.0,
'logisticregression-2__C': 1.0,
'randomforestclassifier__n_estimators': 200}不同特征子集训练多数投票分类器
# 生成数据
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data[:, :], iris.targetfrom sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import EnsembleVoteClassifier
from sklearn.pipeline import Pipeline
from mlxtend.feature_selection import SequentialFeatureSelector # 序惯特征选择clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()创建特征选择的管道:
sfs1 = SequentialFeatureSelector(
clf1,
k_features=4,
forward=True,
floating=False,
scoring="accuracy",
verbose=0,
cv=0
)clf1_pipe = Pipeline([
("sfs", sfs1),
("logreg", clf1)
])创建集成投票表决分类器模型:
eclf = EnsembleVoteClassifier(clfs=[clf1_pipe, clf2, clf3],voting="soft")创建参数组合:
params = {
'pipeline__sfs__k_features': [1, 2, 3],
'pipeline__logreg__C': [1.0, 100.0],
'randomforestclassifier__n_estimators': [20, 200]
}grid = GridSearchCV(estimator=eclf, param_grid=params, cv=5)
grid.fit(X,y)cv_keys = ('mean_test_score', 'std_test_score', 'params')
for r, _ in enumerate(grid.cv_results_['mean_test_score']):
print("%0.3f +/- %0.2f %r"
% (grid.cv_results_[cv_keys[0]][r],
grid.cv_results_[cv_keys[1]][r] / 2.0,
grid.cv_results_[cv_keys[2]][r]))0.947 +/- 0.02 {'pipeline__logreg__C': 1.0, 'pipeline__sfs__k_features': 1, 'randomforestclassifier__n_estimators': 20}
0.947 +/- 0.02 {'pipeline__logreg__C': 1.0, 'pipeline__sfs__k_features': 1, 'randomforestclassifier__n_estimators': 200}
0.947 +/- 0.02 {'pipeline__logreg__C': 1.0, 'pipeline__sfs__k_features': 2, 'randomforestclassifier__n_estimators': 20}
0.960 +/- 0.01 {'pipeline__logreg__C': 1.0, 'pipeline__sfs__k_features': 2, 'randomforestclassifier__n_estimators': 200}
0.953 +/- 0.01 {'pipeline__logreg__C': 1.0, 'pipeline__sfs__k_features': 3, 'randomforestclassifier__n_estimators': 20}
0.960 +/- 0.01 {'pipeline__logreg__C': 1.0, 'pipeline__sfs__k_features': 3, 'randomforestclassifier__n_estimators': 200}
0.953 +/- 0.01 {'pipeline__logreg__C': 100.0, 'pipeline__sfs__k_features': 1, 'randomforestclassifier__n_estimators': 20}
0.953 +/- 0.01 {'pipeline__logreg__C': 100.0, 'pipeline__sfs__k_features': 1, 'randomforestclassifier__n_estimators': 200}
0.960 +/- 0.01 {'pipeline__logreg__C': 100.0, 'pipeline__sfs__k_features': 2, 'randomforestclassifier__n_estimators': 20}
0.960 +/- 0.01 {'pipeline__logreg__C': 100.0, 'pipeline__sfs__k_features': 2, 'randomforestclassifier__n_estimators': 200}
0.960 +/- 0.01 {'pipeline__logreg__C': 100.0, 'pipeline__sfs__k_features': 3, 'randomforestclassifier__n_estimators': 20}
0.960 +/- 0.01 {'pipeline__logreg__C': 100.0, 'pipeline__sfs__k_features': 3, 'randomforestclassifier__n_estimators': 200}最佳参数组合:
grid.best_params_{'pipeline__logreg__C': 1.0,
'pipeline__sfs__k_features': 2,
'randomforestclassifier__n_estimators': 200}使用最佳的参数组合再次进行预测:
eclf = eclf.set_params(**grid.best_params_) # 解析参数组合
eclf.fit(X, y).predict(X[[1, 51, 149]])
array([0, 1, 2])使用预训练模型
# 生成数据
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data[:, :], iris.target
# 不同分类模型
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
import numpy as np
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
for clf in (clf1, clf2, clf3):
clf.fit(X, y)from mlxtend.classifier import EnsembleVoteClassifier
import copy
eclf = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3], weights=[1,1,1], fit_base_estimators=False)
labels = ['Logistic Regression', 'Random Forest', 'Naive Bayes', 'Ensemble']
eclf.fit(X, y)
print('accuracy:', np.mean(y == eclf.predict(X)))
accuracy: 0.98不同特征子集上的集成分类器使用
from sklearn.pipeline import make_pipeline
from mlxtend.feature_selection import ColumnSelector # 特征选择
pipe1 = make_pipeline(ColumnSelector(cols=(0,2)))
pipe2 = make_pipeline(ColumnSelector(cols=(0,1,3)))
eclf = EnsembleVoteClassifier(clfs=[pipe1, pipe2])
eclf.fit(X,y)堆叠分类器StackingClassifier
https://rasbt.github.io/mlxtend/user_guide/classifier/StackingClassifier/
Simple Stacked Classification
import numpy as np
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
import warnings
warnings.simplefilter('ignore')1、导入数据
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.targetclf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()2、建立Stacking模型,使用LogisticRegression作为基模型:
sclf = StackingClassifier(
classifiers=[clf1, clf2, clf3],
use_probas=True,
average_probas=False, # 是否使用概率作为Meta-Features
meta_classifier=lr # 元模型
)3、模型训练
for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN', 'Random Forest', 'Naive Bayes','StackingClassifier']):
# 模型训练与评估
scores = model_selection.cross_val_score(clf, X, y, cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))Accuracy: 0.91 (+/- 0.01) [KNN]
Accuracy: 0.95 (+/- 0.01) [Random Forest]
Accuracy: 0.91 (+/- 0.02) [Naive Bayes]
Accuracy: nan (+/- nan) [StackingClassifier]4、绘制决策边界
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_decision_regions
import matplotlib.gridspec as gridspec
import itertools
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10,8))
for clf, lab, grd in zip([clf1, clf2, clf3, sclf],
['KNN','Random Forest','Naive Bayes','StackingClassifier'],
itertools.product([0, 1], repeat=2)):
clf.fit(X, y) # 模型训练
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf)
plt.title(lab)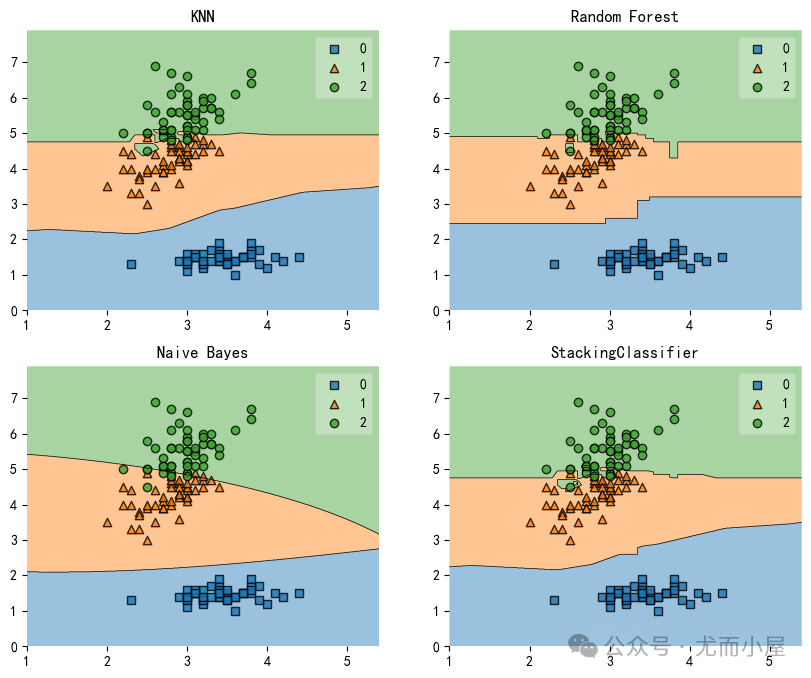
Stacked Classifier&GridSearch
将堆叠分类器和网格搜索结合起来:
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from mlxtend.classifier import StackingClassifier1、创建模型
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression() # meta模型# 堆叠分类器
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3], meta_classifier=lr)2、参数的网格搜索
params = {
'kneighborsclassifier__n_neighbors': [1, 5],
'randomforestclassifier__n_estimators': [10, 50],
'meta_classifier__C': [0.1, 10.0]
}3、模型训练
grid = GridSearchCV(estimator=sclf,param_grid=params,cv=5,refit=True)
grid.fit(X, y)4、获取参数组合及得分:
cv_keys = ('mean_test_score', 'std_test_score', 'params')
for r, _ in enumerate(grid.cv_results_['mean_test_score']):
print("%0.3f +/- %0.2f %r"
% (grid.cv_results_[cv_keys[0]][r],
grid.cv_results_[cv_keys[1]][r] / 2.0,
grid.cv_results_[cv_keys[2]][r]))
print('Best parameters: %s' % grid.best_params_)
print('Accuracy: %.2f' % grid.best_score_)0.933 +/- 0.03 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 10}
0.947 +/- 0.02 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 50}
0.927 +/- 0.03 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 10}
0.947 +/- 0.02 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 50}
0.947 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 10}
0.947 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 50}
0.933 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 10}
0.940 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 50}
Best parameters: {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 50}
Accuracy: 0.95
往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)
















 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









