






背景
伪标签(Pseudo-Labeling)的定义来自于半监督学习,其核心思想是通过借助无标签的数据来提升有监督模型的性能。伪标签技术在许多场景中被验证了它的有效性,例如在kaggle竞赛Santander Customer Transaction Prediction中,冠军方案就使用了这项技术,并获得了25,000刀的奖金。
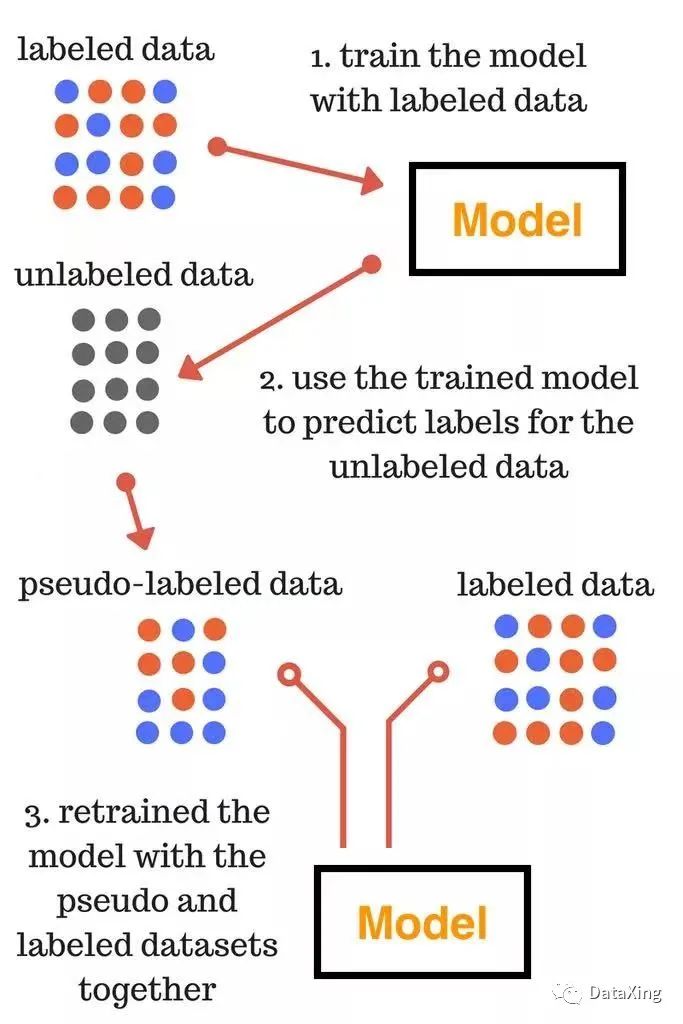
使用伪标签技术的基本步骤
1
使用有标签的数据训练模型;
2
使用第一步训练出来的模型对无标签数据进行预测;
3
从第2步预测结果中选择出置信度比较大的样本,使用预测结果作为他们的标签(伪标签),这部分样本就是伪标签数据集;
4
将伪标签数据集合并到训练集中,重新训练模型。
实际使用时,以上4步有可能多次迭代进行。
伪标签技术为什么能work? (个人想法)
1
伪标签技术常常用于数据量较小的场景,伪标签数据集增大了样本量,虽然有可能带来噪音,但是对于模型收敛是有帮助的;
2
伪标签的数据带来了额外的正确信息, 模型对于不同类别之间的分界更加明确了。
伪标签技术适用场景(个人经验)
1
训练集数据量较小;
2
数据难度较小(例如baseline模型auc就能达到0.9以上)。
✓
使用案例
我们的开源项目autox把自动生成伪标签数据集的函数进行了封装, 方便大家使用,使用简单的几行代码就能构造出伪标签数据集。
from autox.autox_competition.process_data import get_pseudo_label
id_ = 'id'
target = 'target'
used_cols = [col for col in test.columns if col not in [id_, target]]
pseudo_label_data = get_pseudo_label(train, test, id_ = id_, target = target, used_cols = used_cols)案例地址
https://www.kaggle.com/poteman/pseudolabeling-autox
开源项目地址
https://github.com/4paradigm/autox
参考资料
1.https://www.kaggle.com/c/santander-customer-transaction-prediction/discussion/89003
2.https://www.kaggle.com/cdeotte/pseudo-labeling-qda-0-969
3.https://towardsdatascience.com/pseudo-labeling-to-deal-with-small-datasets-what-why-how-fd6f903213af
往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑
AI基础下载机器学习交流qq群955171419,加入微信群请扫码:















 2112
2112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









