






看本文之前,可以先看一下之前的文章:计算机视觉"新"范式: Transformer
检测框架的本质:从检测框编码的输入角度考虑,有密集到稀疏,密集和稀疏三种框架。Mask R-CNN属于先通过密集预测得到稀疏的采样,然后进行稀疏预测的检测框架;RetinaNet(FCOS、CenterNet)等都属于直接密集预测得到结果的检测框架。在DETR工作之前,几乎所有的检测算法都可以归类到这两种类型中去。之前的G-CNN是直接通过稀疏的初始化采样级联回归得到结果,这算第三种检测框架,但是精度不太令人满意。从检测框编码的输出角度考虑,有one-to-many和one-to-one两种框架。one-to-many需要通过nms、maxpooling等后处理方式去重,而one-to-one通过学习的方式去重。所有的检测框架都可以通过3x2的排列组合得到。举几个例子,Mask R-CNN(密集到稀疏+one-to-many),FCOS(密集+one-to-many),DeFCN(密集+one-to-one),Deformable DETR two-stage版本(密集到稀疏+one-to-one)等等。
DETR属于稀疏+one-to-one的框架,DETR的成功主要归功于Transformer强大的建模能力,还有匈牙利匹配算法解决了如何通过学习的方式one-to-one的匹配检测框和目标框。
虽然DETR可以达到跟Mask R-CNN相当的精度,但是训练500个epoch、收敛速度慢,小目标精度低的问题都饱受诟病。后续一系列的工作都围绕着这几个问题展开,其中最精彩的要属Deformable DETR,也是如今检测的刷榜必备,Deformable DETR的贡献不单单只是将Deformable Conv推广到了Transformer上,更重要的是提供了很多训练好DETR检测框架的技巧,比如模仿Mask R-CNN框架的two-stage做法,如何将query embed拆分成content和reference points两部分组成,如何将DETR拓展到多尺度训练,还有通过look forward once进行boxes预测等技巧,在Deformable DETR之后,大家似乎找到了如何打开DETR框架的正确姿势。本文将通过DAB-DETR、DN-DETR、DINO和Mask DINO等四篇文章,串讲一下如何正确打开DETR的潘多拉魔盒。
DAB-DETR
DAB-DETR将object query看成是content和reference points两个部分,其中reference points显示的表示成xywh四维向量,然后通过decoder预测xywh的残差对检测框迭代更新,另外还通过xywh向量引入位置注意力,帮助DETR加快收敛速度。


在DAB-DETR之前,有许多工作对如何设置reference points进行过深入的探索:Conditional DETR通过256维的可学习向量学习得到xy参考点,然后将位置信息引入transformer decoder中;Anchor DETR参考点看成是xy,然后通过学习的方式得到256维的向量,将位置信息引入transformer decoder中,并且通过逐级迭代得到检测框的xy;Defomable DETR则是通过256维可学习向量得到xywh参考anchor,通过逐级迭代得到检测框;DAB-DETR则更为彻底,吸百家之长,通过xywh学习256维的向量,将位置信息引入transformer decoder中,并且通过逐级迭代得到检测框。至此,reference points的使用方式逐渐明朗起来,显示的表示为xywh,然后学习成256维向量,引入位置信息,每层transformer decoder学习xywh的残差,逐级叠加得到最后的检测框。
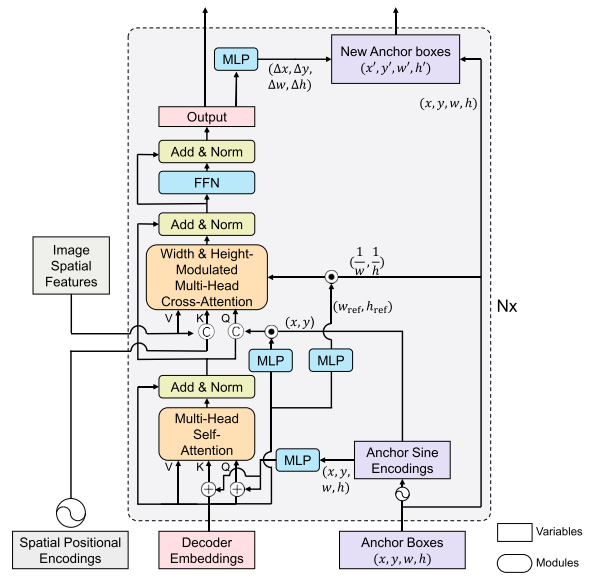
另外,DAB-DETR为了更充分的利用xywh这种更为显示的reference points表示方式,进一步的引入了Width & Height-Modulated Multi-Head Cross-Attention,其实简单来讲就是在cross-attention中引入位置xywh得到的位置注意力,这一点改进可以极大的加快decoder的收敛速度,因为原始的DETR相当于是在全图学习到位置注意力,DAB-DETR可以直接关注到关键位置,这也是Deformable DETR为啥能加快收敛的原因,本质就是更关键的稀疏位置采样可以加快decoder收敛速度。
DN-DETR
虽然DAB-DETR已经极大的加快了DETR的收敛速度,但是仍然不能和Mask R-CNN和RetinaNet等算法比较,常规的Mask R-CNN和RetinaNet算法,可以在12epoch(1x)训练时长下就达到相当好的精度水平,而DAB-DETR仍然需要训练50个epoch,尽管有了更好的reference points和更好的attention。DN-DETR通过实验发现,DETR的decoder收敛速度慢,还有一个重要的原因就是,匈牙利匹配算法导致one-to-one匹配检测框和目标框切换频繁。
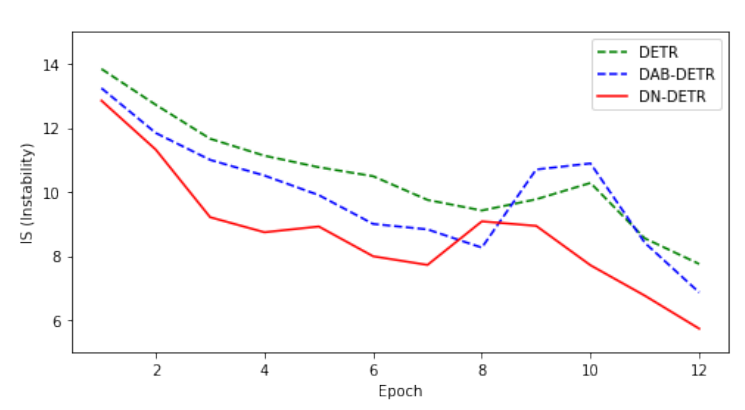
DN-DETR用IS指标表示匈牙利匹配算法的匹配稳定性,可以看到DN-DETR相比于DETR和DAB-DETR,匹配稳定性有显著的提升。
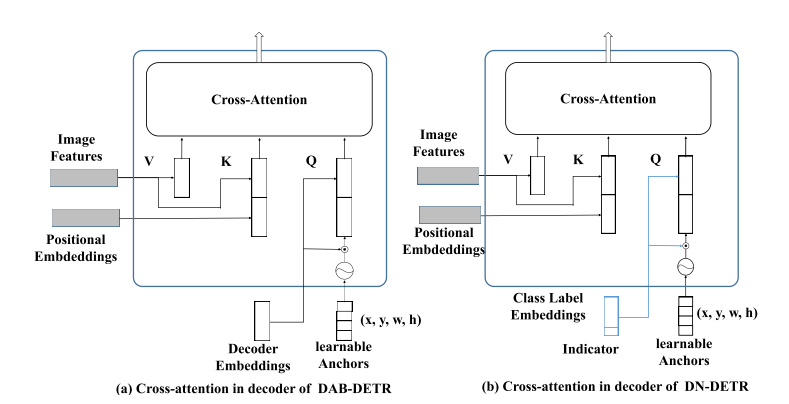
DN-DETR在DAB-DETR的基础上,引入了denoising part部分,具体来讲就是通过ground truth生成带有噪声的label和bbox,这一部分直接跳过匈牙利匹配,直接进行label和bbox的预测,另外在decoder的embeding中引入一个indicator位置来指示是否是带有噪声的label和bbox的预测部分。
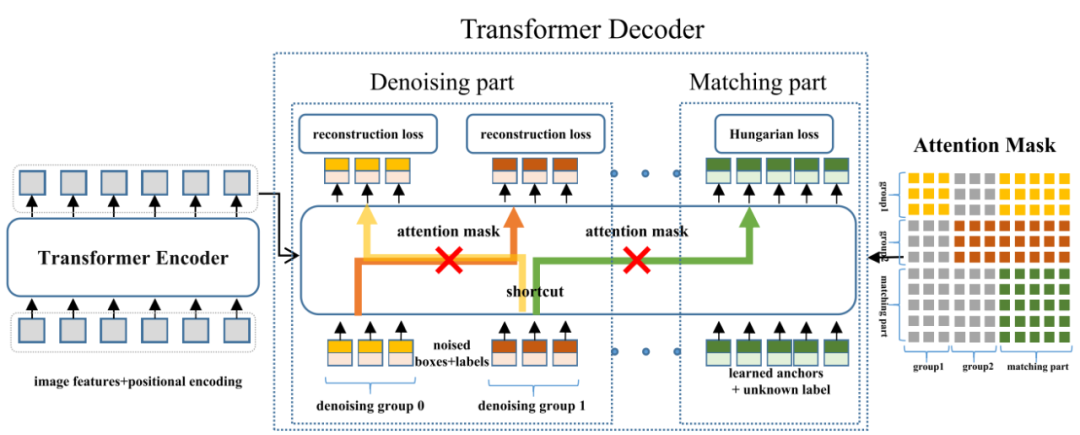
DN-DETR的整体框架如图所示,decoder的训练分成denoising part和matching part两个部分,reference points表示成xywh和label两个部分,其中matching part的xywh是可学习的4维向量,label是unknown的,训练目标通过匈牙利匹配算法one-to-one进行匹配;而denoising part的reference points表示成noised的boxes和labels,训练目标直接匹配(其中group表示不同目标分组)。另外为了避免denoising part部分泄露信息,DN-DETR在decoder的self-attention部分引入了一个attention mask,避免不同目标denoising的相互影响,也避免了denoising部分对matching部分的影响。
DN-DETR的denoising part部分设计的十分巧妙,从我对于检测算法的认知来讲,匈牙利匹配算法的虽然可以通过自适应的方式one-to-one匹配,但是也带来了额外的问题,一个是匹配会频繁切换,另一个就是训练样本不够的问题,Mask R-CNN和RetinaNet等检测框架,每个目标可以有多个正样本进行匹配训练,这可以极大的加快收敛速度,而denosing part部分某种程度上就是one-to-many的做法,每个目标可以有多个正样本进行训练,从这个角度看,matching part和denosing part两个部分相当于解耦了one-to-one和one-to-many两种匹配方式,one-to-many只用来加快训练速度,而one-to-one用来找出最佳的匹配结果。
DINO
DINO简单来讲,就是在DN-DETR的基础上,提出3个有效的提点加快收敛速度的技巧:contrastive denoising(CDN)、mixed query selection和look forward twice。
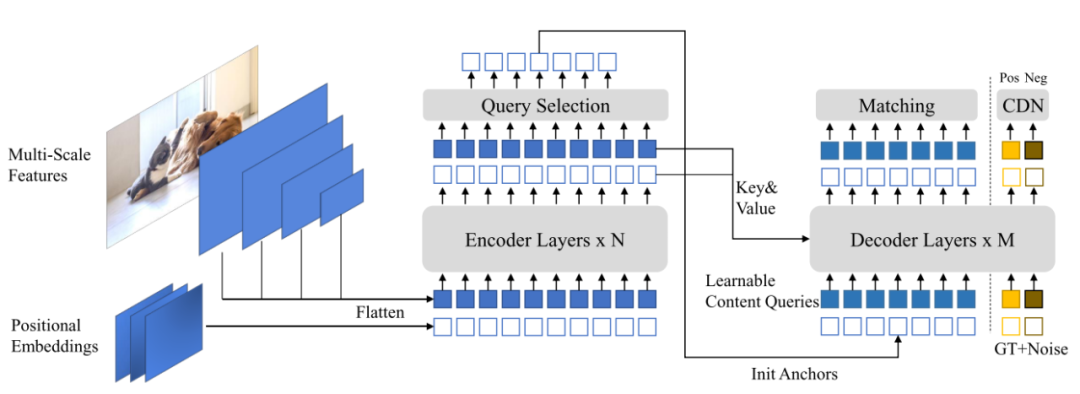
整体框架如图所示,transformer encoder出来的特征,通过query selection采样得到稀疏的init anchors,然后在DN-DETR的denoising part部分引入了CDN进行辅助训练。
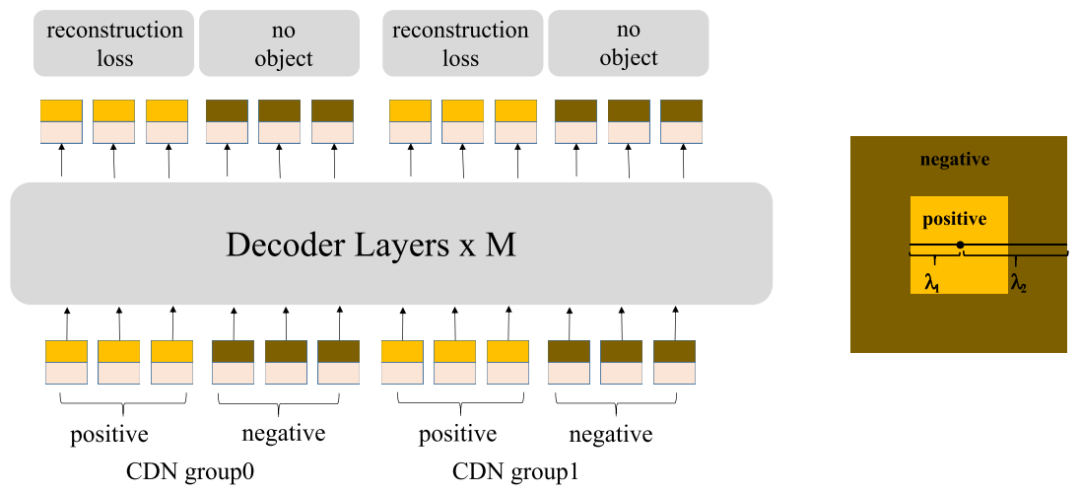
上图就是contrastive denoising的设计,这个设计同样非常巧妙,原始的denoising part虽然增加了每个目标的正样本数量,但是仍然存在没有负样本的问题,这样就会导致DETR的去重能力不够强,于是DINO为每个noised labels和boxes都设置了正负样本(比例为1:1),负样本的重建目标为no object。正负样本通过右图的两个参数控制,也就是小于参数1的为正样本,大于参数1小于参数2的为负样本,之所以这样子设计是因为noised boxes距离ground truth boxes很近一定是正样本,而距离很远的非常容易学习成负样本,距离不近不远的是难负样本,更有利于学习出去重的能力。这里的正负样本设计已经非常类似Mask R-CNN或者RetinaNet等经典的检测算法了。
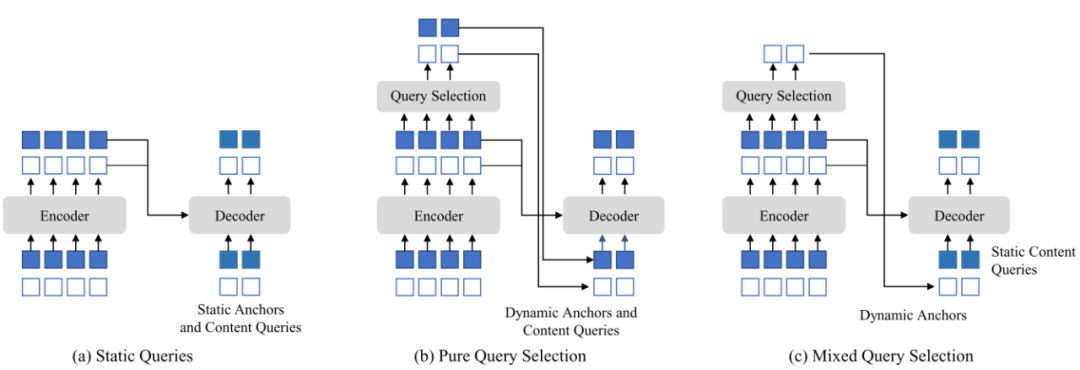
图(a)是原始DETR的query做法,anchor和content queries都是静态的;图(b)是Deformable DETR的two-stage版本,从transformer encoder的输出中学习出最重要的query采样点来初始化decoder的anchor和content queries;图(c)是DINO提出的mixed query selection,也就是decoder的初始化anchor从transformer encoder的输出中取,而content queries保持静态。之所以这么修改,是为了避免encoder输出的query采样点误导decoder的学习。
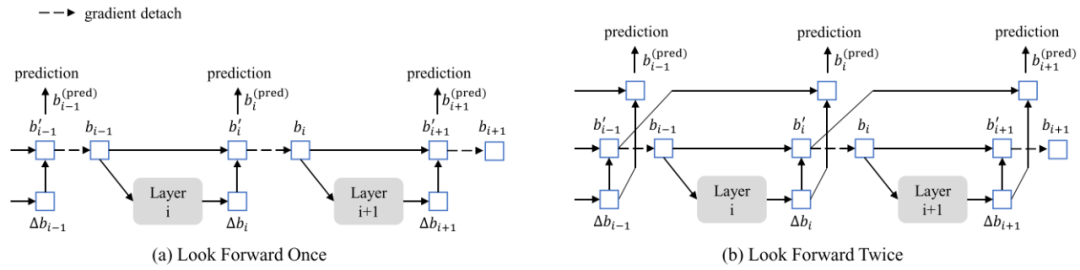
上图的虚箭头表示gradient detach。图(a)是Deformable DETR预测boxes的技巧,因为layer i的参数更新只是由当前层的预测boxes决定的,所以简称为Look Forward Once。图(b)是DINO提出来的Look Forward Twice,意思就是当前层的预测boxes同时由layer i和layer i-1两层参数更新来决定。
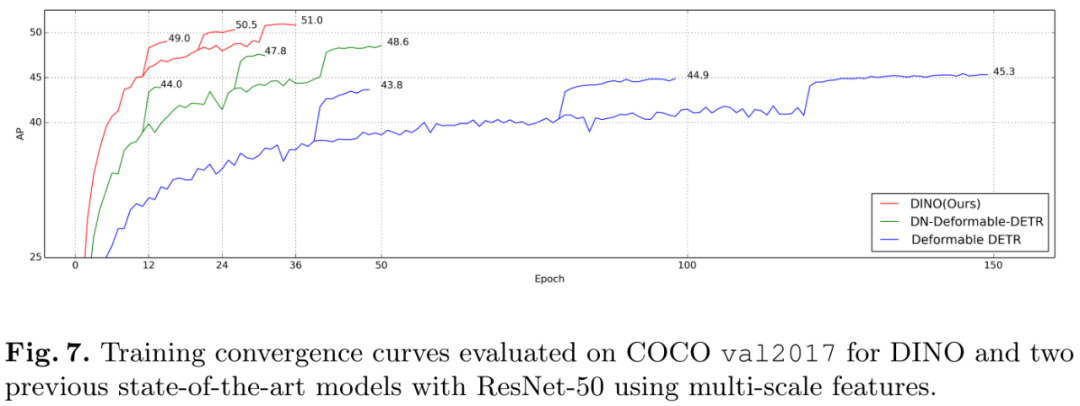
通过以上3个技巧的改进,极大加快了DINO的收敛速度,DINO-R50在36个epoch下可以达到51mAP。
Mask DINO
Mask DINO在DINO的基础上,将DINO拓展到了Instance Segmentation、Semantic Segmentation和Panoptic Segmentation任务上。
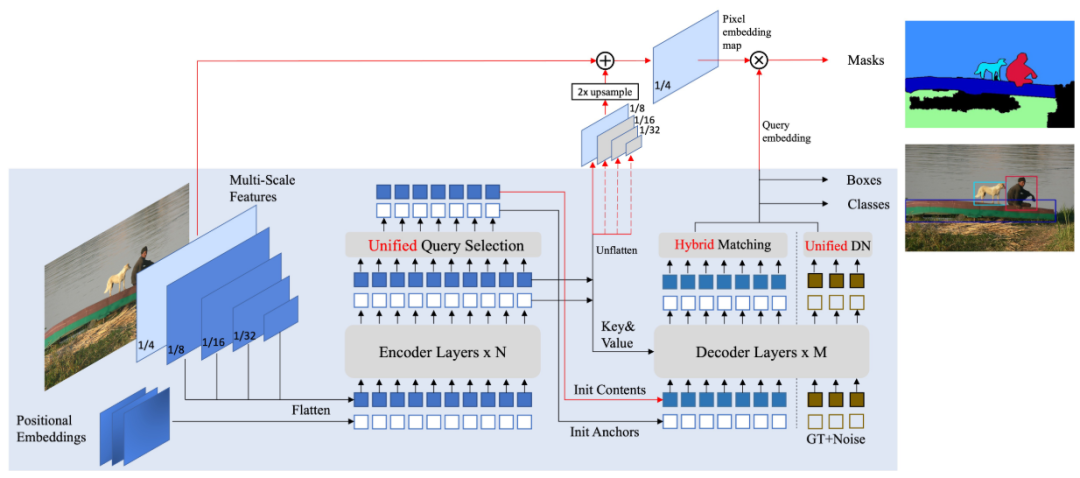
Mask DINO整体框架如图所示,类似MaskFormer的做法,将分割任务统一成mask classification任务,引入一个mask prediction branch,通过query embedding来对高分辨率的pixel embedding map进行点乘,得到最终的mask预测结果。其中pixel embedding map通过1/4的feature map和transformer encoder后的1/8、1/16和1/32的feature map融合得到。相比于DINO,Mask DINO将mixed query selection改回了pury query selection。另外,query selection、matching和DN部分都针对mask预测部分做了适应性的细节修改。

从上表中可以看出,Mask DINO几乎把所有能提升的部分都做了一遍改进,DINO和Mask DINO屠榜了Object Detection、Instance Segmentation、Semantic Segmentation和Panoptic Segmentation等主流视觉任务,成功帮助DETR正名,原来不是DETR不够强,而是打开的方式不对。
Reference
[1] DAB-DETR: DYNAMIC ANCHOR BOXES ARE BETTER QUERIES FOR DETR
[2] DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
[3] DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
[4] Mask DINO: Towards A Unified Transformer-based Framework for Object Detection and Segmentation

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码(读博请说明)















 937
937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









