






在之前一篇推文一文串起从NLP到CV 预训练技术和范式演进中,由于篇幅有限,仅仅介绍了深度学习中的预训练技术发展,基本思路是顺着CV和NLP双线的预训练技术发展演进。
这里正式开启一个顺着这篇推文的倒叙精读系列。
Masked Autoencoders Are Scalable Vision Learners
正好mae的官方pytorch在两周前开源了
https://github.com/facebookresearch/mae
我们用倒叙的方式,从MAE往后看。开篇用一个非常夸张的实验效果demo图。这个效果实在是太夸张了,人都脑补不出来这样的马赛克程度。

摘要
MAE的方法非常简单,随机MASK住图片里的一些块,然后再去重构这些被MASK住的像素。这整个思想也来自 BERT 的带掩码的语言模型,但不一样的是这一个词(patches) 它就是一个 image 的一个块,然后它预测的是你这块里面的所有的像素。
全文有两个重要的创新点:跑得快+学得难
跑得快:非对称的自编码器架构(autoencoder),其编码器仅作用在可见的这些patch里面, 如果一个 patch 被它丢掉了,那么编码器就不会对它进行编码。这样图像encoder端的工作量就减少了,好处就是可以跑得很快。进一步地,解码器是一个比较轻量的解码器。一层transformer就够用。
学得难:预训练任务能够重构原始的像素级图片。并且,可以搞定75%的这些块全部遮住下的图像复原。这个事情是一个非平凡的,而且有意义的自监督的任务。如果你就简单遮住几块的话,那么就插一下值,你就可以出来了,这样整个模型可能学不到特别有意思的东西。但是你要是遮住高达75%的部分,苦一苦你的模型,说不定他会学到一些更好的一些表征
然后把这两个放在一起,跑得快+学得难,我们就可以让他做一些超越自己当前模型水平的水平的事情(老PUA了)
结果:用更小的数据来自监督预训练,超越了更多数据监督训练的ViT模型。他用来自于VIT这个论文的不加任何技巧的ViT-Huge的模型backbobe结构,
加上他的预训练方法,能够得到 87.8% 的ACC表现。
最后,强调一下迁移学习也很好。当然,预训练模型不迁移学习,那岂不预训练了一个寂寞。
结构
论文一般有两个图最重要,一个是第一页右上角的小图,第二个是第三页横跨双栏的大图。
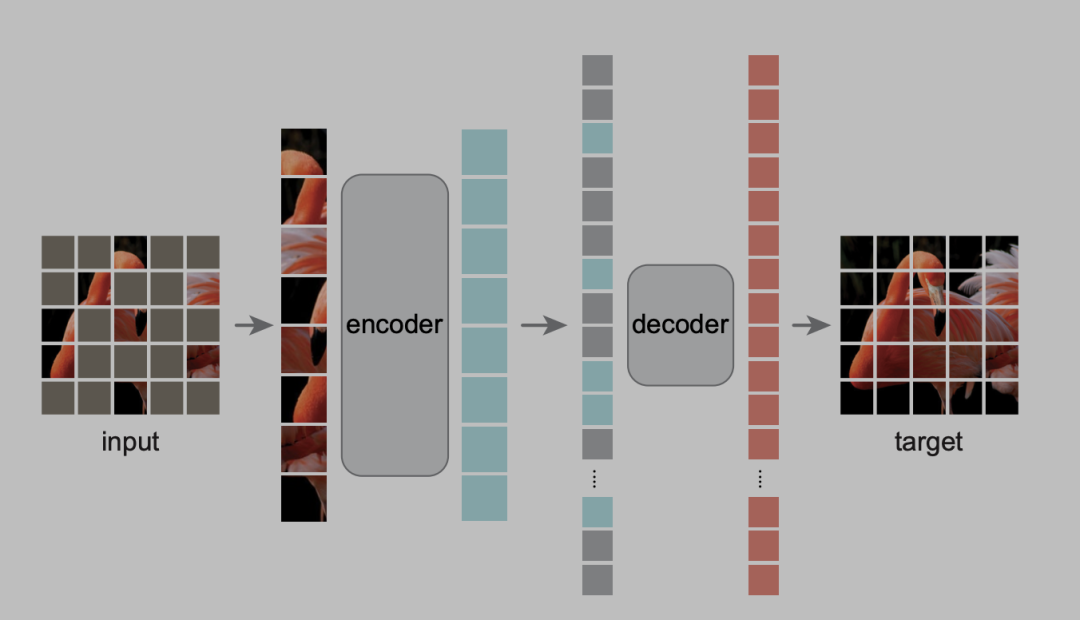
这是 MAE体的架构图,预训练阶段一共分为四个部分,MASK,encoder,decoder。
MASK
可以看到一张图片进来,首先把你切块切成一个一个的小块,按格子切下来。
其中要被MASK住的这一块就是涂成一个灰色,然后没有MASK住的地方直接拎出来,这个地方75%的地方被MASK住了。注意是随机采样,而不是什么中心采样,网格的采样,局部采样等方式,s这部分在实验里对比过。这里比较符合认知的解释是,可以防止引入类似中心归纳偏好等特定bias,随机是最公平的。
encoder
前面拎起来的像素块即unmask部分,放进一个 encoder 的里面,这里采用了ViT论文中的transformer backbone,得到每一个块它对应的这一些特征。
在这个地方它要把它拉长,把这些被MASK那些块,重新放回到原来的位置,把它拉成一条向量。在预训练的时候,MASK住的东西,其实啥也没有了,作者给了他一个可以学习的共享隐向量+Position embedding(!!!!这个地方比较难trick,推荐看一下代码实现)没有MASK住的,就是填上那 ViT 它出来的这些特征。组成一个长的隐层向量,输到一个解码器里面。
decoder
解码器会去尝试把里面的像素信息全部重构回来,得到最后的 target(目标的像素值)。要注意的是,解码的过程是没有加速度的,但是解码的模型一般都不大。我们知道编码的Transformer 这些模型计算量都特别大,如果有个几倍的加速,其实也是非常重要的一个事情。
下游任务
如果你想用这个模型来做一个下游任务呢,你就只需要它的编码器就行了,解码器是不需要的,你的图片进来你不需要对它做掩码
你直接切成这些格子块。然后过encoder它就会得到你所有那些块的一个特征的表示,这个就是你的图片的语义表征(representation)
实现细节
encoder
1.patch,图像切块, 图像在tensor中的表示为 (B,C,H,W) reshape 成 (B,N,PxPxC),其中B是Batch大小,N和P分别为 patch 数量 和 patch 大小。
N = H*W/P/P。
2.patch embedding, 1中的图片切块的嵌入表征,他是连续值经过一层全连接得到固定维度大小的值(dim),注意文本是one-hot形式,或者look up table的形式。
从1中的 (B,N,PxPxC) -> (B,N,dim)
3.position embedding,patch编码对应的embeding,这个和NLP中的词表查到的embedding是一样的。
4.部分编码,预训练阶段的Encoder从实现角度再复述一遍:图像切块-没有MASK的部分走patch embedding+position embedding
def forward_encoder(self, x, mask_ratio):
# embed patches
x = self.patch_embed(x)
# add pos embed w/o cls token
x = x + self.pos_embed[:, 1:, :]
# masking: length -> length * mask_ratio
x, mask, ids_restore = self.random_masking(x, mask_ratio)
# append cls token
cls_token = self.cls_token + self.pos_embed[:, :1, :]
cls_tokens = cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
# apply Transformer blocks
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x, mask, ids_restoredecoder
1.mask部分的对应的隐向量并不来自于encoder的推断,而是直接在这里进行凭空初始化的共享token向量+position embedding。
2.decoder不需要用encoder那么重的模型。你可以理解为Bert的decoder就是个MLP,这里可以用一个特别简单的一层transformer。虽然decoder在数量补齐了复杂度,因为模型简单,压力并不太大。
def forward_decoder(self, x, ids_restore):
# embed tokens
x = self.decoder_embed(x)
# append mask tokens to sequence
mask_tokens = self.mask_token.repeat(x.shape[0], ids_restore.shape[1] + 1 - x.shape[1], 1)
x_ = torch.cat([x[:, 1:, :], mask_tokens], dim=1) # no cls token
x_ = torch.gather(x_, dim=1, index=ids_restore.unsqueeze(-1).repeat(1, 1, x.shape[2])) # unshuffle
x = torch.cat([x[:, :1, :], x_], dim=1) # append cls token
# add pos embed
x = x + self.decoder_pos_embed
# apply Transformer blocks
for blk in self.decoder_blocks:
x = blk(x)
x = self.decoder_norm(x)
# predictor projection
x = self.decoder_pred(x)
# remove cls token
x = x[:, 1:, :]
return xloss
1.仅用MSE算mask path的像素差值。只算mask patch是因为实验结论,否则有大约0.5%的ACC下降。
2.归一化的像素值作为target比较好。实验结果
总结
预训练阶段:
1.图片切patch
2.patch做embedding (projection方式)
3.加上position embedding (lookup table方式)
4.mask打码(75%)
5.无码部分进encoder
6.有码部分做好可训练的共享语义向量+position embedding
7.按patch的原始顺序拼好mask和unmask的对应语义向量,送decoder
8.取decoder出来的,mask部分对应的像素值算mse loss。
实验部分
1.mask比例

少了多了都不好。所以说恰当的压力才是前进的动力。直观理解就是太简单了学不到东西,太难了也学不会。
2.采样策略
随机采样效果最好,其他的方式多多少少泛化能力都差一点。

block的任务更难,扣掉一大块比例太大也学不好,对于模型来说太难了。扣掉50%差不多了,但是效果比随机还差一点。和上面个实验一样,刚刚好比较好。
3.decoder设计

用深层和更大decoder不太好。其实也可以理解,encoder出来的隐向量的信息已经够复杂了。第二点是苦一苦encoder,这样在下游任务他发挥的更好一点。要是用复杂的encoder,信息和建模能力,都隐藏在decoder恐怕就没有这么好的效果了。
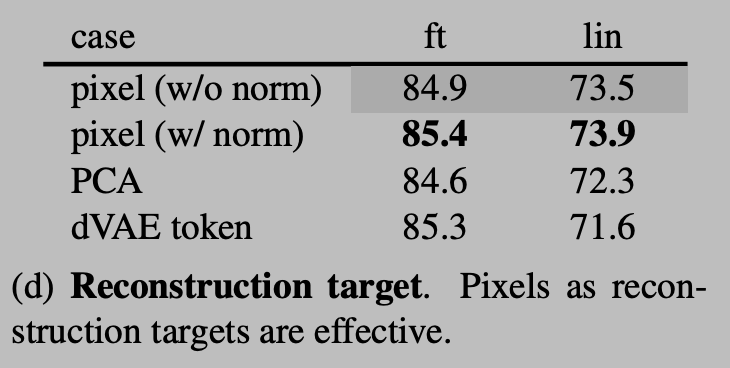
4.重建目标
作者和 BEiT 那种预测token的方式 以及 PCA 的方式。patch 做 PCA 并预测最大的因子,进行了比较。有无归一化也进行了比较。
5.数据增强
保持图片局部完整信息的随机缩放,比其他引入噪声的方式都要好。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









