






公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter~
本文介绍的是通过11种方法来对比Pandas中DataFrame两列的求和
direct_add
for_iloc
iloc_sum
iat
apply(指定字段)
apply(针对整个DataFrame)
numpy_array
iterrows
zip
assign
sum
文末送书,文末送书,文末送书!

数据模拟
为了效果明显,模拟了一份5万条的数据,4个字段:
import pandas as pd
import numpy as np
data = pd.DataFrame({
"A":np.random.uniform(1,1000,50000),
"B":np.random.uniform(1,1000,50000),
"C":np.random.uniform(1,1000,50000),
"D":np.random.uniform(1,1000,50000)
})
data
11种函数
下面是通过11种不同的函数来实现A、C两列的数据相加求和E列
方法1:直接相加
把df的两列直接相加
In [3]:
def fun1(df):
df["E"] = df["A"] + df["C"]方法2:for+iloc定位
for语句 + iloc方法的遍历循环
In [4]:
def fun2(df):
for i in range(len(df)):
df["E"] = df.iloc[i,0] + df.iloc[i, 2] # iloc[i,0]定位A列的数据方法3:iloc + sum
iloc方法针对全部行指定列的求和:
0:第一列A
2:第三列C
In [5]:
def fun3(df):
df["E"] = df.iloc[:,[0,2]].sum(axis=1) # axis=1表示在列上操作方法3:iat定位
for语句 + iat定位,类比于for + iloc
In [6]:
def fun4(df):
for i in range(len(df)):
df["E"] = df.iat[i,0] + df.iat[i, 2]apply函数(只读两列)
apply方法 ,仅仅取出AC两列
In [7]:
def fun5(df):
df["E"] = df[["A","C"]].apply(lambda x: x["A"] + x["C"], axis=1)apply函数(全部df)
针对前部的DataFrame使用apply方法
In [8]:
def fun6(df):
df["E"] = df.apply(lambda x: x["A"] + x["C"], axis=1)numpy数组
使用numpy数组解决
In [9]:
def fun7(df):
df["E"] = df["A"].values + df["C"].valuesiterrows迭代
iterrows()迭代每行的数据
In [10]:
def fun8(df):
for _, rows in df.iterrows():
rows["E"] = rows["A"] + rows["C"]zip函数
通过zip函数现将AC两列的数据进行压缩
In [11]:
def fun9(df):
df["E"] = [i+j for i,j in zip(df["A"], df["C"])]assign函数
通过派生函数assign生成新的字段E
In [12]:
def fun10(df):
df.assign(E = df["A"] + df["C"])sum函数
在指定的A、C两列上使用sum函数
In [13]:
def fun11(df):
df["E"] = df[["A","C"]].sum(axis=1)结果
调用11种函数,比较它们的速度:


统计每种方法下的均值,并整理成相同的us:
| 方法 | 结果 | 统一(us) |
|---|---|---|
| 直接相加 | 626us | 626 |
| for + iloc | 9.61s | 9610000 |
| iloc + sum | 1.42ms | 1420 |
| iat | 9.2s | 9200000 |
| apply(只取指定列) | 666ms | 666000 |
| apply(全部列) | 697ms | 697000 |
| numpy | 216us | 216 |
| iterrows | 3.29s | 3290000 |
| zip | 17.9ms | 17900 |
| assign | 888us | 888 |
| sum(axis=1) | 1.33ms | 1330 |
result = pd.DataFrame({"methods":["direct_add","for_iloc","iloc_sum","iat","apply_part","apply_all",
"numpy_arry","iterrows","zip","assign","sum"],
"time":[626,9610000,1420,9200000,666000,697000,216,3290000,17900,888,1330]})
result进行降序后的可视化:
result.sort_values("time",ascending=False,inplace=True)
import plotly_express as px
fig = px.bar(result, x="methods", y="time", color="time")
fig.show()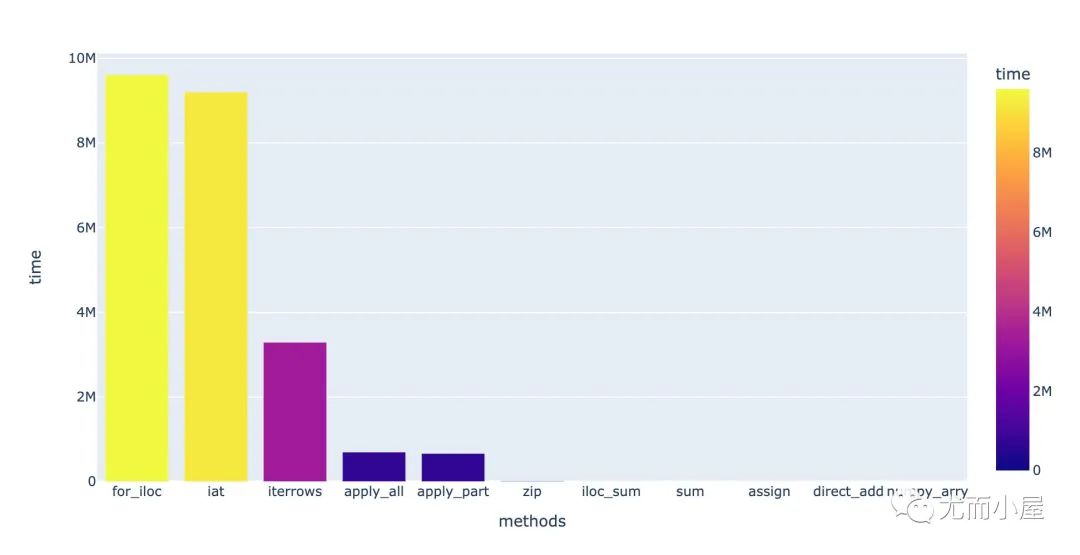
从结果中能够看到:
for循环是最耗时的,使用numpy数组最省时间,相差4万多倍;主要是因为Numpy数组使用的向量化操作
sum函数(指定轴axis=1)对效果的提升很明显
总结:循环能省则省,尽可能用Pandas或者numpy的内置函数来解决。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码















 3819
3819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









