






转载于 :量子位,王乃岩知乎虽然这文章没有提出新的方法,但是对于我们理解CNN是如何学习到一些appearance cue来处理需要几何模型的视觉问题大有裨益。
首先,我们知道单目相机是没有办法恢复出来绝对尺度的,但是如果我们有实际的场景先验,这个问题是可以部分被解决的,在自动驾驶的场景中体现最为明显。简化的原理如下图:
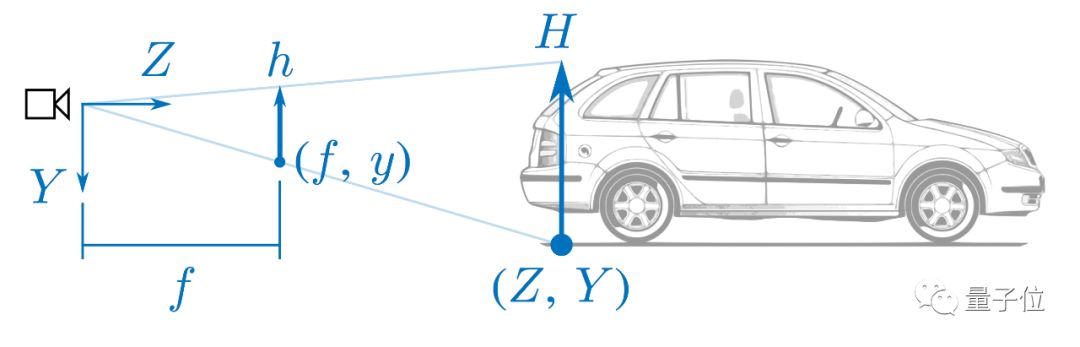
在上面这个图中,对实际场景做了一些简化。所有的大写字母代表的都是在3D世界中的实际坐标,小写字母代表的都是在相机成像平面上的像素坐标。f为相机的实际焦距,假设通过标定已知。
那么我们其实可以在图中找到两个和Z相关的相似三角形来恢复实际尺度:
第一个是h/H = f/Z,整理下可得到Z=Hf/h。
从上面公式可知,我们需要知道实际世界中的车宽(或车高),然后通过物体在图像中的像素高度即可换算出来实际物体的距离。直观上来理解,物体应该是近大远小的。
第二个是y/Y = f/Z,同理可得Z=Yf/y。
在这种方法中,我们需要知道的是相机距离地面的安装高度以及在图像中车轮与地面接触点的纵坐标。直观上理解,如果我们在一条平直的路上,那么离我们越近的物体它的纵坐标应该越靠图像下方,越远的物体越靠图像上方。
那这些CNN深度估计的方法是靠什么样的线索来估计的呢?文中第一部分便是研究这个问题。作者使用了一个假的车通过变换大小和位置贴在一张真实的图片中来验证各个猜想。
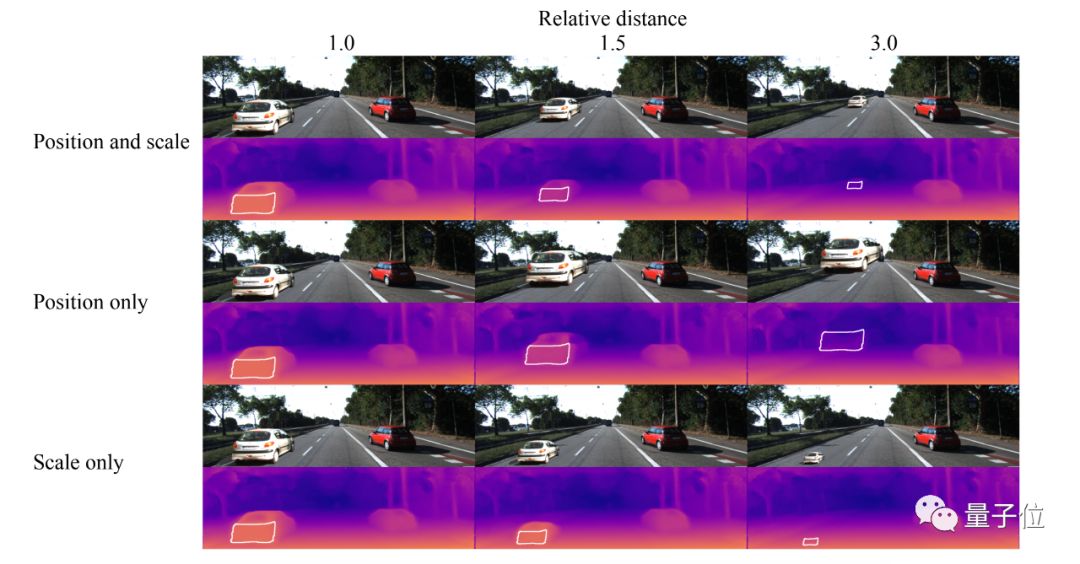
第一行中,是按照正常的逻辑同时变换高度和大小,可见整体的预测是符合常理的。
在第二行中,贴图的时候只变化垂直方向上的位置,物体的大小没有进行缩放,可见随着放置纵坐标的变化物体的距离也有相应的变化。
但是在第三行中,保持物体的纵坐标不变,只是缩放大小,整个神经网络的输出其实相当一致,并没有剧烈变化。(都注意预测中白框内的结果即可,也就是车尾的距离)下面是一个定量的结果:
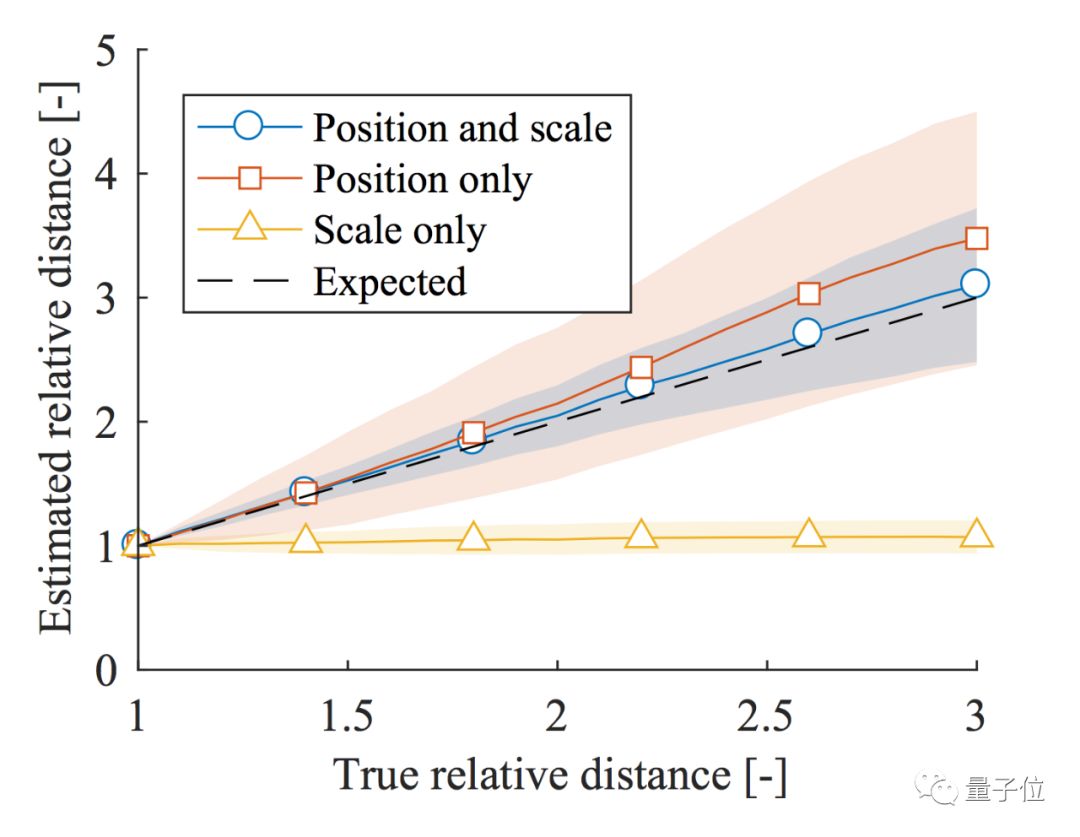
可见,scale only完全丧失了预测的能力,但是剩下的两种方式趋势仍然正确。
所以,本文的第一个结论便是,CNN其实是通过物体在图像中的纵坐标而不是物体的长宽来对物体测距的。
这个结论说实话还挺反直觉的,文末谈了一些我个人的想法。
在第二部分中,作者探究了camera pose对于CNN深度估计算法的影响。理论上讲,一个鲁棒的算法应该对于camera pose的变化具有不变性。但是实际上并非如此。作者分别对pitch和roll角的扰动进行了分析。
首先对于pitch而言,作者可以通过robust fitting的办法通过预测出的深度图来得到地平线的位置,这个算法就不再详述。然后作者通过center crop的方式来模拟相机pitch角度的变化,第一点,可以看到CNN预测出的深度图是能够部分反映出地平线位置的变化的,但是和理想状况仍有差距。第二点,基于前面分析出CNN其实是通过物体接地点的纵坐标来计算深度的,所以毫不意外,在这样center crop的setting下,深度完全随着crop的位置而变化,但实际上场景并没有变化。
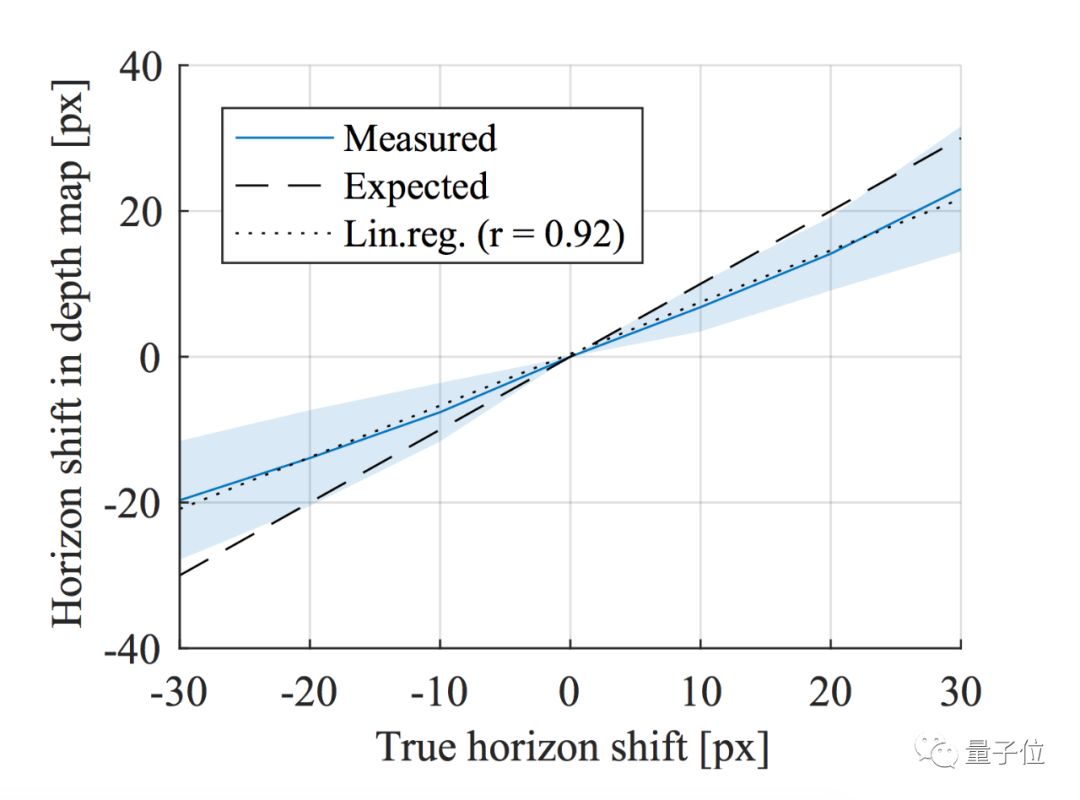
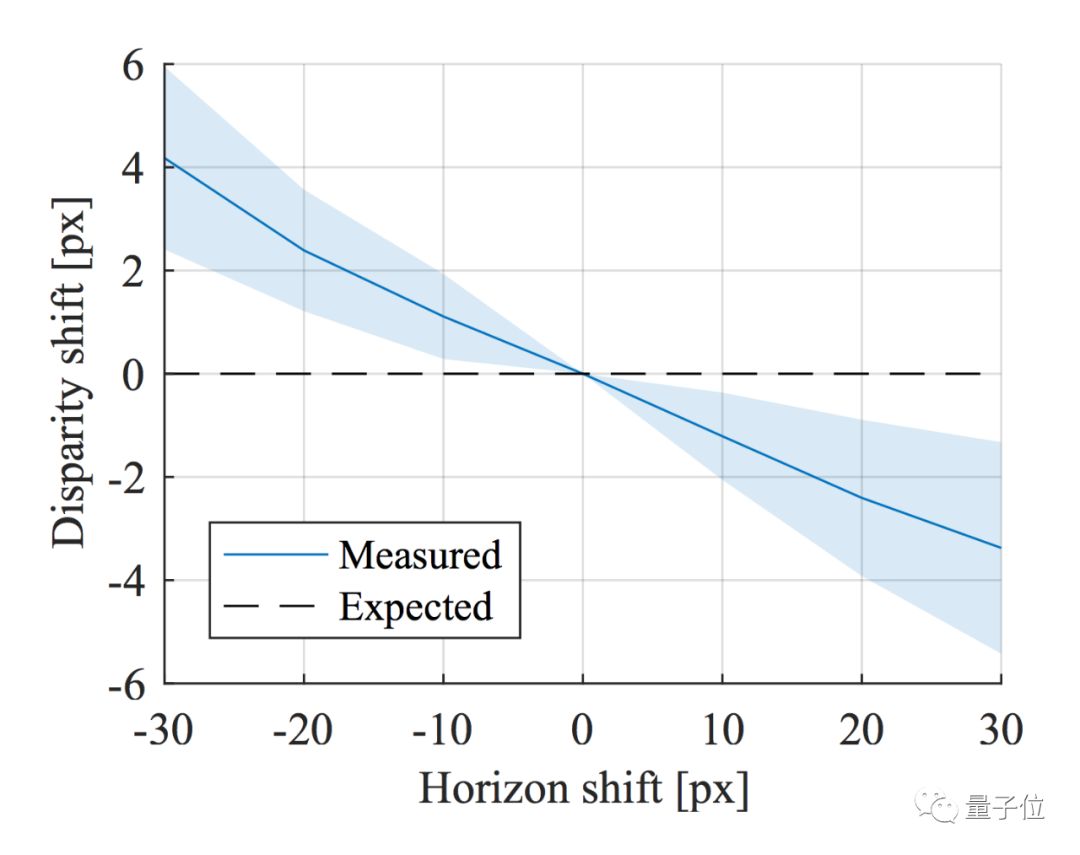
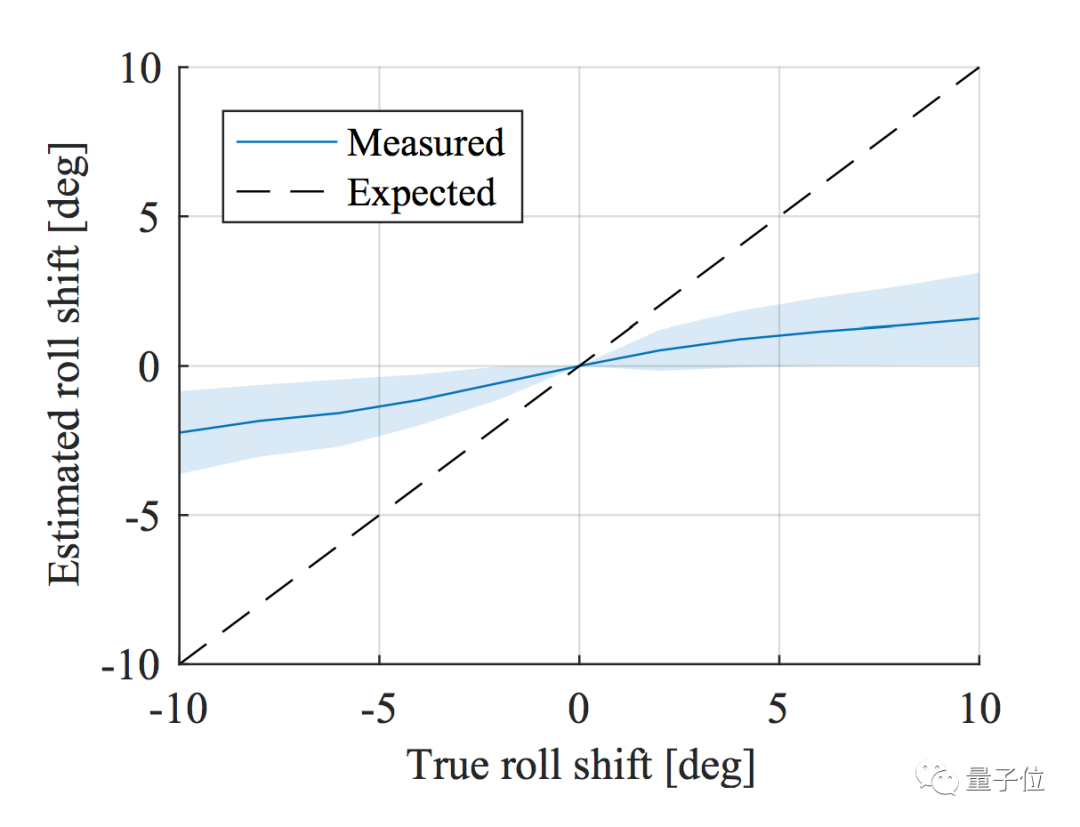
对于roll角也可以类似地做敏感度分析,最终结论是,CNN预测出深度图的roll角确实和GT有一定相关性,但是相对于pitch来说弱了很多。
第三部分,也是最有意思的部分,就是去验证CNN对于颜色和材质的不变性。


可以看到,去掉颜色保留灰度,或者用一个假的颜色预测结果都还算合理。但是如果使用类平均的颜色或者是指定颜色,整个预测结果会受到非常大的影响。
这其实表明,虽然不需要显式地model语义信息,但是纹理对于深度预测仍然非常关键。
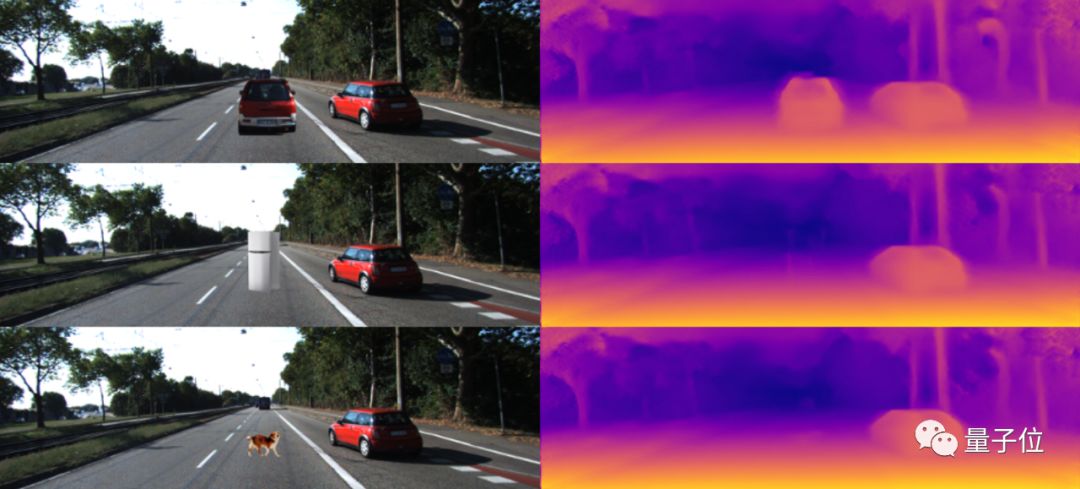
文中也进行了其他诸多实验去验证CNN对于未知物体以及轮廓的敏感性,这里就不再展开。只举一个我觉得很有趣的例子。如果我们在图上加入一些训练集中没有出现过的未知物体,不出意外,模型是完全无法感知到它们的存在。但是如果我们在这些物体下面加入一些阴影,那么模型突然就可以找出整个的物体。
从这个小小的实验中,我们可以管窥CNN究竟是通过什么样的信息来识别物体,以及CNN是多么喜欢去找数据中的“捷径”来fit数据的。

说了这么多,这个文章也有几点我觉得可以继续深挖下去,包括:
1.在室内场景,如NYU Depth这样的数据集中,没有这样大面积的ground plane,CNN是如何估计出深度的?
2.在第一个分析实验中,既然CNN是通过车轮地面接触点的纵坐标来测距的,那么这个信息又是从哪里来的?网络结构基本是一个FCN,具有translation invariant的特点,那么理应不包括坐标信息。那是padding泄露了位置信息?还是通过车道线或者是其他的一些cue泄露了这个信息,这也是很有意思的一点。直观上来讲,物体的scale是CNN更容易捕捉的信息,但实际上并没有,这也就说明其实有一些CNN更直接可以利用的cue我们没有发现到。
3.既然CNN对于crop和rotation很敏感,那如果我们训练的时候使用了random crop和random rotation这样的data augmentation,那么CNN依赖的深度线索是否会有变化?
总结一下,现有基于CNN做深度估计的算法本质上还都是通过overfit场景中的某种信息来进行深度估计,整体来说这些方法其实并没有考虑到任何几何的限制,所以在不同场景下的泛化能力也比较弱。
如何能结合geometry方法和learning方法的优势是一个老生常谈的话题。
一方面这个问题可以被拆分成两部分,一部分通过几何的办法来完成不同位置相对深度的估计,另一部分通过一些场景先验或者数据驱动的办法来预测出绝对尺度,然后再融合这两者得到一个可靠鲁棒的深度估计。
另一方面,也许可以通过预测一些不变的物理量再结合上几何信息来得到最终的深度信息,例如某些特定车型的尺寸,车道线等信息。这个领域中仍然有大量open的问题有待解决。
论文传送门
How do neural networks see depth in single images?
作者:Tom van Dijk, Guido de Croon
Proceedings of the IEEE International Conference on Computer Vision. 2019.
https://arxiv.org/abs/1905.07005

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)















 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









