






首届“AI高考”落幕,21位大模型宝宝参加高考,及格率只有 33%!其中,OpenAI 的 GPT-4-Turbo、智谱AI 的 GLM-4-0520 和 GLM-4-Air 分别斩获COT 版本考试中前三甲。
自从2022 年底的ChatGPT呱呱落地,顺利破圈后,这两年大模型迎来全面的野蛮的发展。各个奶爸费尽心机,为自己娃儿争取更高质量的奶粉(数据)、给自己的娃儿雇佣了一堆具有全球视野的精专人才(大量的人才)、买了大量的GPU点读机(哪里不会怼哪里)、还引入的众多网友的无私调教、参加各类才艺表演比赛(MMLU、CMMLU 等)。
每个娃在他爹眼中就是全世界最亮的宝,那么经过素质教育后的娃即将引来第一届高考,那么谁才是大模型中的别人家的娃儿?谁家的娃儿最能打?谁家的娃儿又最坑爹?

考生情报
本次精选21位大模型宝宝参加高考,下面是考生情报
国际组




国内组






考试方法
考试目的:使用训练集中不可能出现的24年高考数学题,“管中窥豹”各大模型AI 宝宝的推理能力、稳定性以及对提示词的敏感程度,了解大模型AI的定价与哪些因素有关。
试卷来源:抽样自上海卷,北京卷,新课标1,新课标2,全国甲卷(理)共29道单项选择题。
考题处理:为降低 OCR 识别导致的误差,满足考试目地的要求,考题进行一下预处理。
1)使用gpt4o进行ocr转换为Latex格式文本,并进行人工校对
2)对每道题的选项ABCD进行倒序A->D,B->C,C->B,D->A构造镜像的29道逆序题
答题过程:正序和倒序题使用Vanila Prompt(简单直出)和CoT Prompt(经典step by step)调用模型答题,每题答2次。因此每个待测模型的总答题数为29x2x2x2=232次,待测21个模型,有些娃儿不听话,需要多问几遍...因此四舍五入...因此本次测试6000次。
记分规则:2次都答对得1分,对1次得0.5分,都不对得0分,满分29分推理
增量定义:△Reason:=CoT Prompt得分-Vanilla Prompt得分,反映模型因思维链推理额外获得的分数提升推理采样的超参数:temperature=0.2,frequency_.penalty=0
为了方便后续阅读,里面的分数还原成百分制,满分 100 分。
为调参与感,我们开通打榜通道,为您喜欢的 AI 模型投下宝贵一票讲人话版本:兄弟测试了接近6000次,熬了5个夜晚,一个周末,终于把不听话的娃儿都测完了。请各位看官不要忘记一键三连。
1. Vanila Prompt(简单直出) ,相当于模型利用一堆QKV和全连接层的参数在脑子里算,简单理解 = 心算。
2. CoT Prompt(经典step by step),将中间过程写在纸上边打草稿边算,相当于手算。

看看谁是你心目中的 Top1,待会一起看看是不是如你所想?
考生情报提前提出,https://langgptai.feishu.cn/wiki/HteYwsIMpimxO8kFqJ8cylqEnoe?table=blkxAzUVuUw1KjeT 由FishAI 维护,LangGPT 首发的大模型跑分数据库的提供早期情报,方便大家慎重投票。您的一票将维护您心中的最好的 AI

Y 轴出场费情况,越往上越贵,不要小看出场费,最贵的 Claude3 是最便宜的GLM-Flash 的 1000倍。
X轴是MMLU的测试情况,一般大模型他爹会主动公布的,不公布的大概率 Hmmm,当然还是有不少没有公布的,目前截取都是有公布成绩
是不是最贵一定最好呢
是不是分数最好一定最好呢
!!!猛按投票!一人一票,票完看成绩!
我们郑重承诺,本次测试绝不受投票影响,绝对不抽卡(因为要钱啊 QAQ)
首届AI高考分数排行(CoT Prompt)

GPT-4-Turbo 获得 COT 版本考试🥇!GPT-4o虽然官宣 MMLU 第一,但是在推理面前仍然惜败前辈 GPT-4-Turbo,作为7个月前发布的大模型,能打能抗!就是有点小贵。
GLM-4-0520与GLM-4-Air分别荣获COT 版本考试🥈与🥉,一门双豪杰 要注意的是 GLM-4-Air 是什么妖孽,仅仅 1 元钱,四舍五入不要钱!效果比肩 GPT-4-Turbo!!我甚至怀疑 GLM-4-Air背后藏着 GLM-4-0520!
Gemini 1.5 Pro依然水平在线,获得本次的第四名的好成绩,这种上不了前三的感觉,是您熟悉的谷歌的味道...
GPT-4o仅仅取得第五名,毕竟只要 50 元,现在的 OpenAI 已经是一个盈利公司了,估计开了阉割大法了吧。
Claude3 Opus就令人无语了,被国产大模型摁在地上打,最贵的大模型!业界皆有口碑,被众人踩在地上.仅仅斩获第八名。排在前面是为了本次考试紧急发布的 Deepseek-V2-Code(hoho,恰逢其会)以及阿里的 Qwen2,也同样恭喜这两位国内玩家,出色的完成比赛,得出亮眼的成绩。
当然告诉大家一个好消息,最糟糕的大模型 GPT-3.5-Pro,还是领先了人类 2 岁幼崽的智商...
首届AI高考分数排行(Vanilla Prompt)
首届AI高考分数排行(Vanilla)
“心算,12当作5”
排名
参考大模型
分数
1
Gemini-1.5-flash
49.1
2
Baichuan3-turbo
48.3
3
Baichuan4
47.4
4
Yi-lagre
47.4
5
Qwen-2-70B
46.6
6
Yi-lagre-turbo
44.8
7
Gemini-1.5-pro
44.0
8
DeepSeek-v2-code
40.5
9
Claude3-Haiku
40.5
10
Moonshot-v1-8k
38.8
11
Claude3-Sonnet
38.8
12
GPT-4-turbo
37.1
13
GPT-4o
37.1
14
GLM-4-Air
36.2
15
Claude3-Opus
36.2
16
Qwen-2-57b-A14b
36.2
17
GLM-4-flash
36.2
18
DeepSeek-v2-chat
35.3
19
Llama-3-70b
32.8
20
GLM-4-0520
31.0
21
人类 2 岁幼崽
25
22
GPT-3.5-turbo
17.2
心算组的成绩就让人嘘嘘了,排名第一竟然是 Gemini 1.5 Flash,作为 3 元钱的高性价比(美刀购买力),这咋第一的.
排在第二Baichuan3-turbo..也是一个次级模型...整体毫无规律可言。
模型升级不能提升这个心算能力。
大模型没有超纲,不做推理思考就能猜到答案,如果到了这个阶段,世界究竟是什么光景呢
GPT-3.5-Turbo 稳稳倒一,也算是时代的眼泪了?
感觉越强能力的在心算组的分数越低...
Prompt 对 AI 大模型性能提升
本次考试再一次强有力的证明,Prompt 提示词在 AI 产业中的重要作用,无论是心力为先、还是推理致胜,都只是玩家 Prompt中的几个字符。
Gartner在 Hype Cycle of AI中着重强调 Prompt engineering,提示词工程化技术,它是如此的准确的描述到:
Prompt engineering提示工程是一门为GenAI模型提供文本或图像形式的输入,以指定和限制模型可产生的响应集的学科。输入的提示集能产生预期的结果,而无需更新模型的实际权重(如微调所做的那样)。
在考试中,我们两个 Prompt 非常简单,仅仅因为多了一句"Step by Step"就将近 100% 的性能提升。
这是因为大型语言模型(LLMs)对输入中的细微差别和微小变化极为敏感,每个模型都有自己的敏感度级别,而提示工程学就是通过反复测试和评估来发现敏感度。
实际上从技术而言,表面原因是模型在训练阶段加入了思维链数据,进一步使模型在推理时将问题展开,从而在被约束了的概率空间内进行搜索,究其本质还是用有效计算换智能(更长的输出路径消耗了更多的计算)
使用好 Prompt,将有助于提高AI的性能,减少幻觉的产生,提高输出质量;更重要的是在业务验证的时候提供高效的落地实践方案,它允许企业在 "按原样 "消费与追求更昂贵、更耗时的微调方法之间取得平衡。
一个成熟的 AI 应用、场景,势必要使用更加系统化,更准确的 Prompt 工程技术,使得AI 在原有的大模型能力上能够更好的工作。
聪明的 AI 训练专家已经有各类专业的评估工具,比如本次考试使用的“陆游博士玩转万亿 token 的提示词编排和评估工具PSAK(PSAK,Prompt Swiss Army Knife)”
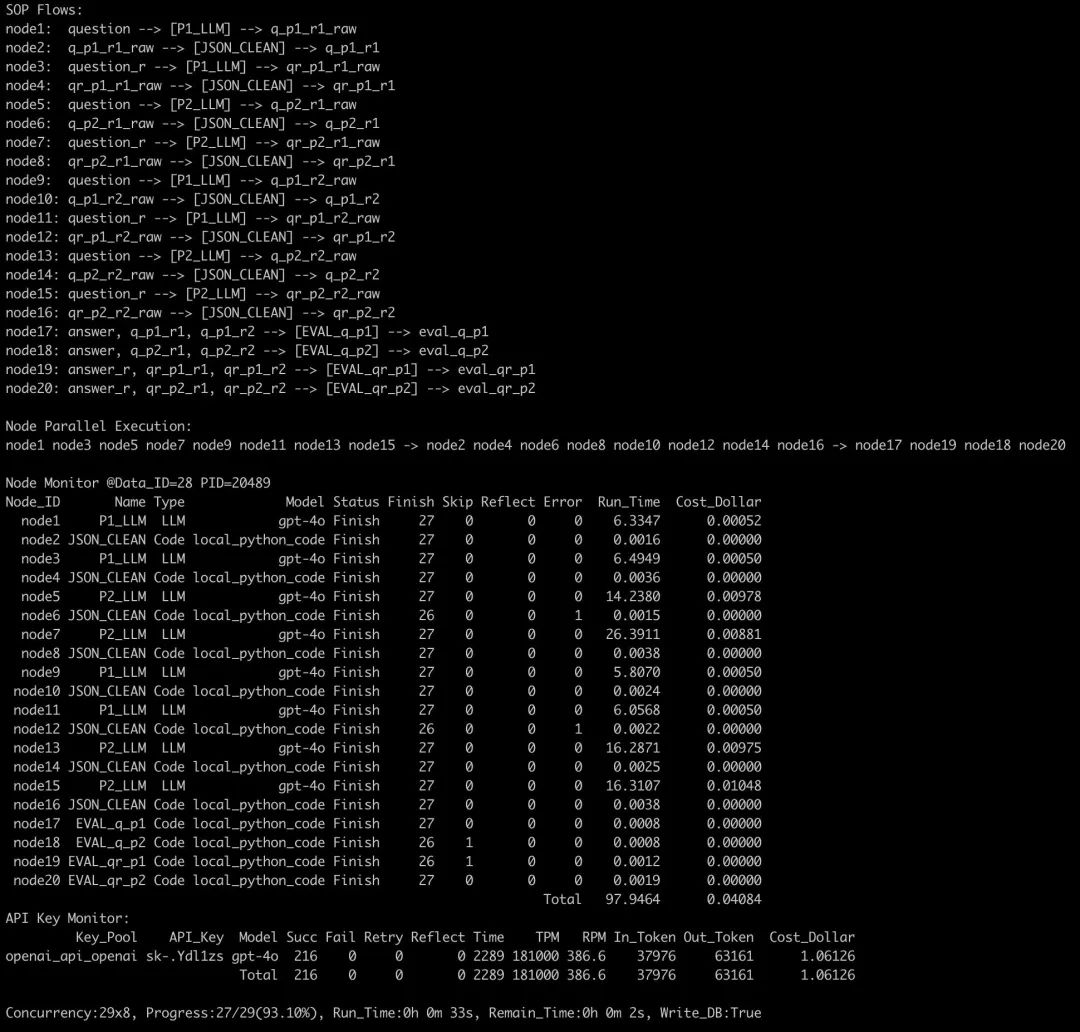
图:本次测试的监考+考官+阅卷老师,陆游博士的提示词编排和评估工具PSAK
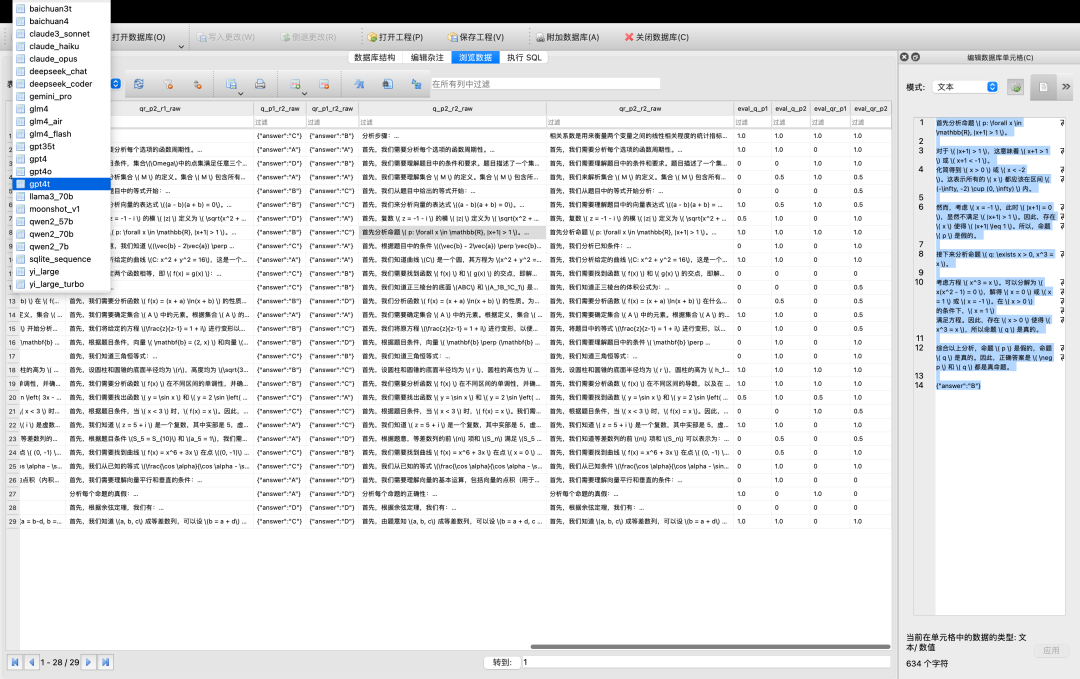
图:过程存档
本次的数据我们可以看到以下关键发现:
1) COT对所有模型基本有效:
有效率高达:85%
提升率最高 117%
平均高达: 52%
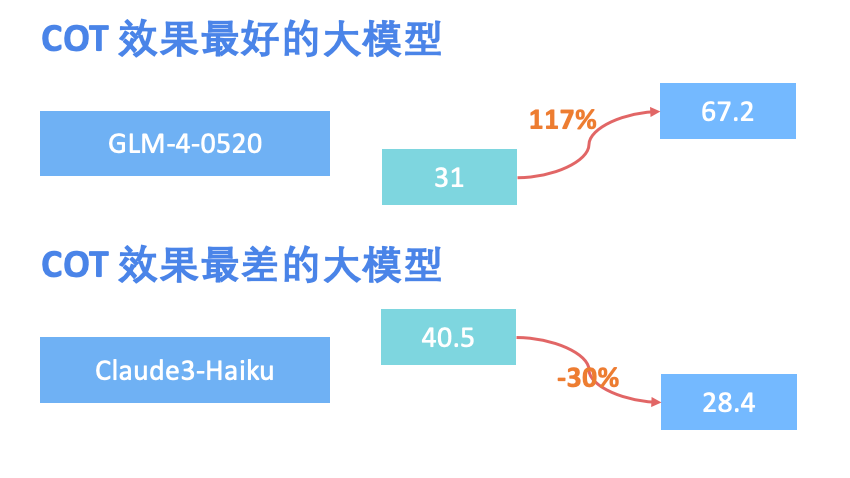
2) 对大模型量力而行,真正的低性能的 LLM,就算使用复杂的 Prompt,可能出现性能更差的情况,量力而为也适用于大模型,比如Claude3-Haiku。
整体情况可以详细查看下图的数据:
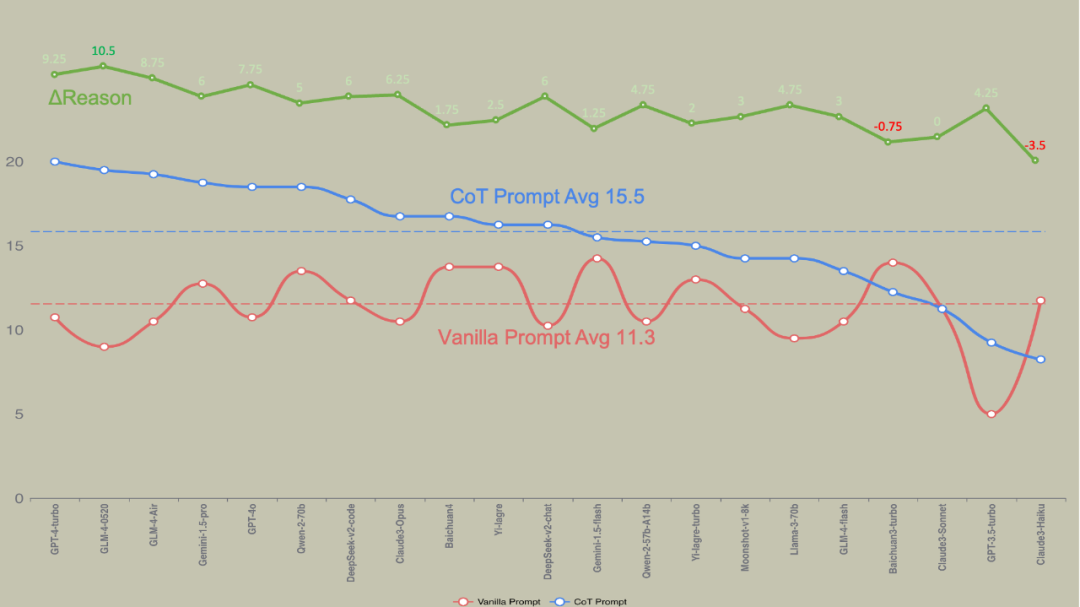
你还迷信厂商的 MMLU 吗?
作为直观感受GenAI 能力的 MMLU,素来是重要的参考依据,但是这里面并不完全的体现其推理性能,本次的数据答题,更多考究是大模型自身的推理能力,因此在MMLU 的分数排名与实际高考排名出现较为大的抖动。
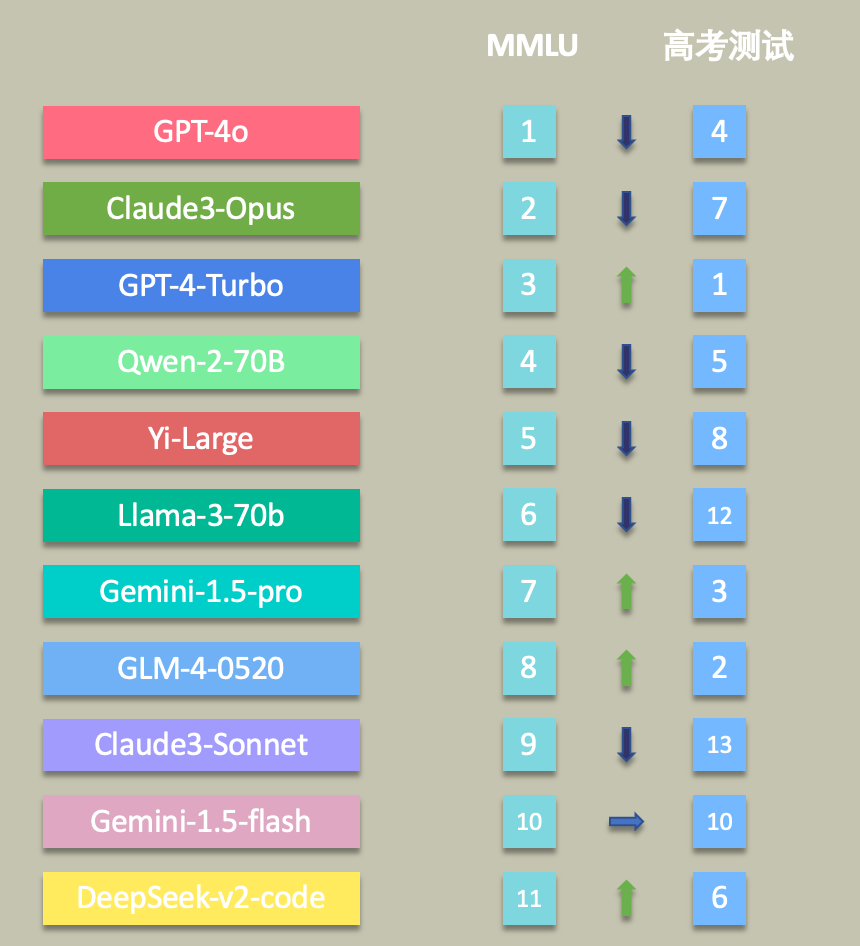
如图可以发现,Gemini1.5 Pro、GLM-4-0520、DeepSeek都呈现较强的逆市趋势,可以看出来一味的通过 MMLU 确定是否使用该模型,容易错过更多的值得尝试的新模型。在模型选择时,需要根据具体的任务场景构建评估数据集对模型在指定场景下的能力进行重新评估。
这次大模型高考,我们还有那些发现?
便宜有好货,懂得赶紧来(1元都不到,你还想咋样系列)
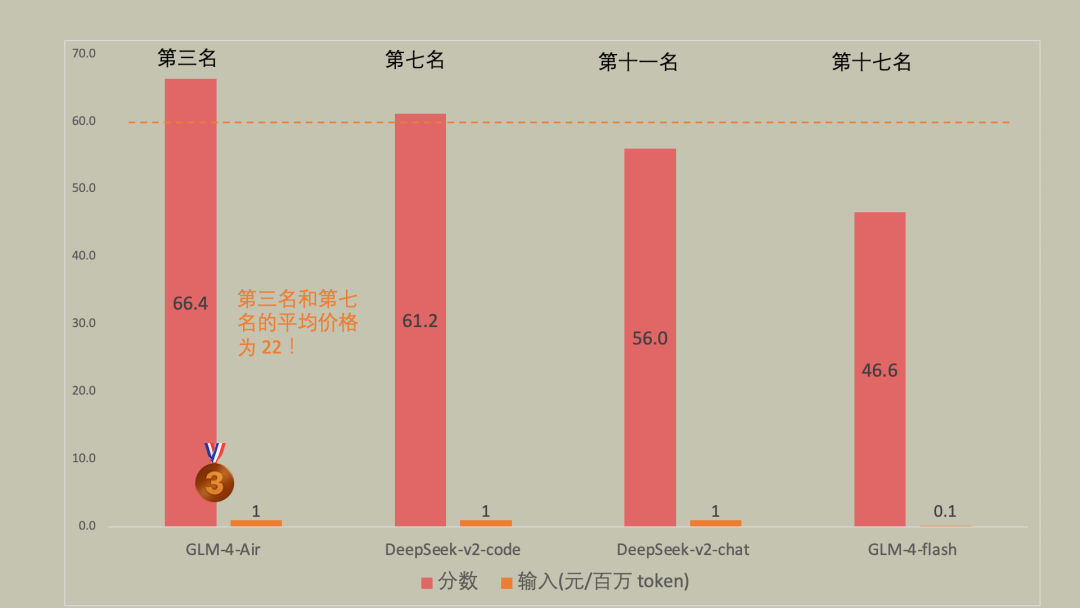 1 元不到大模型,Top3、Top7 任你挑,哪里不会问哪里!如图所示从第三名到第七名之间的 API 平均售价是 22 元,足足有 22 倍!
1 元不到大模型,Top3、Top7 任你挑,哪里不会问哪里!如图所示从第三名到第七名之间的 API 平均售价是 22 元,足足有 22 倍!
便宜有好货,懂得赶紧挑(1-5 元区)
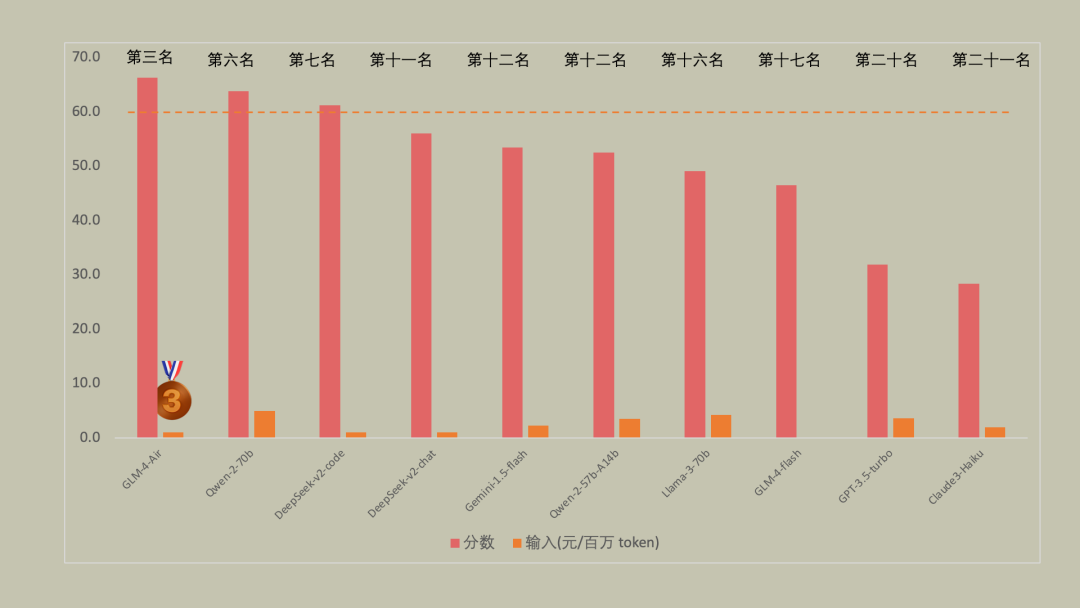
选择最长的那些就可以了,比如 GLM-4-Air、Qwen-2-70B、DeepSeek2-Code
意料之外之自己看数据吧
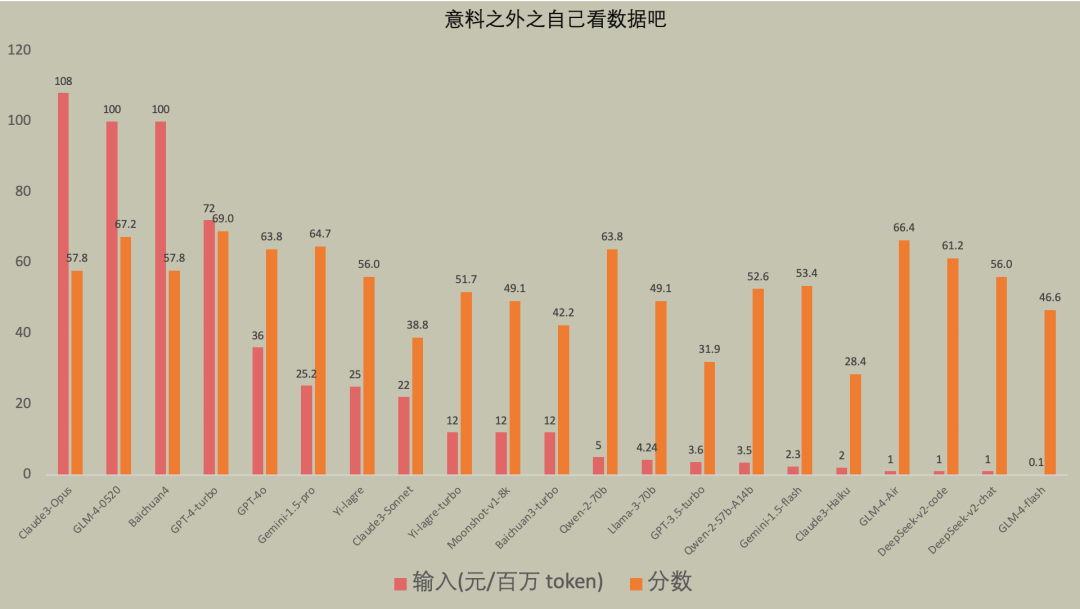
不敢多说了,我怕怕
巅峰对决到底谁最强?
智谱Open-Day,中国四小龙巅峰对决(面壁智能给端用的,不算哈)
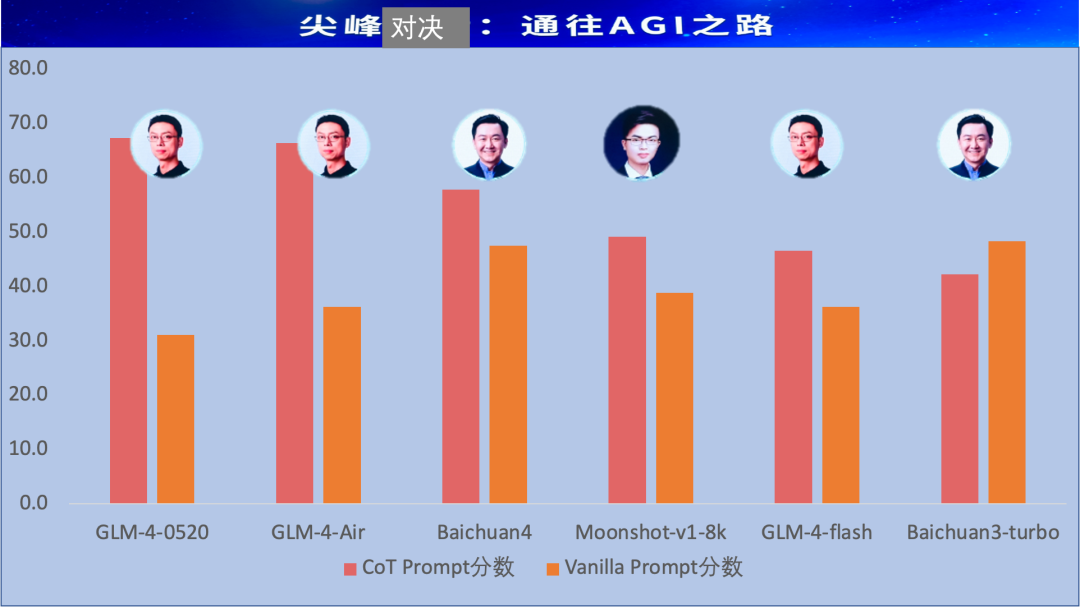
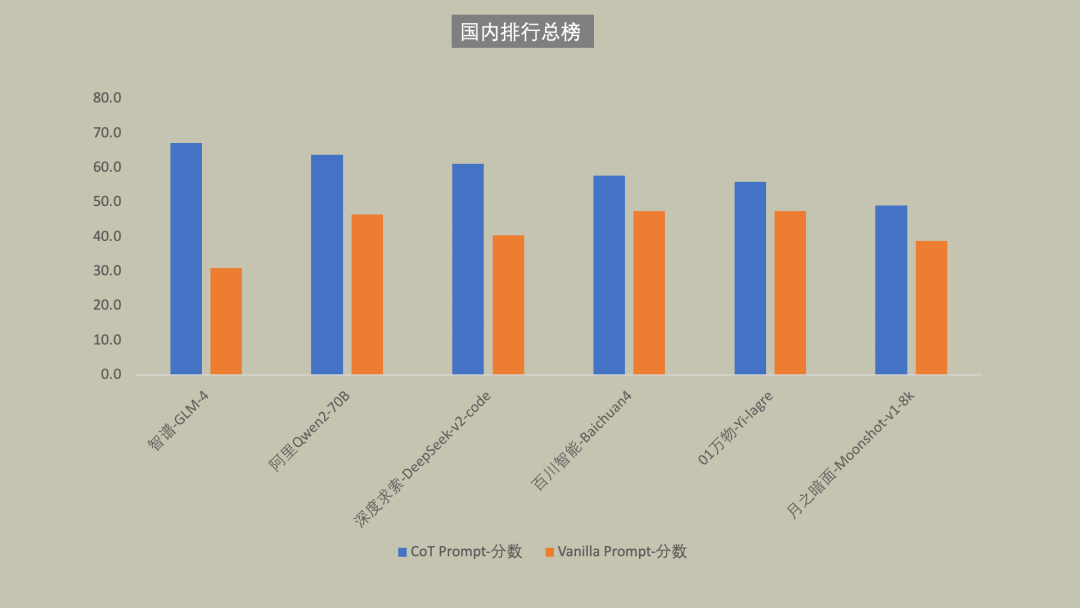
国内大模型总榜
最后两张图,代表本次测试最终结果
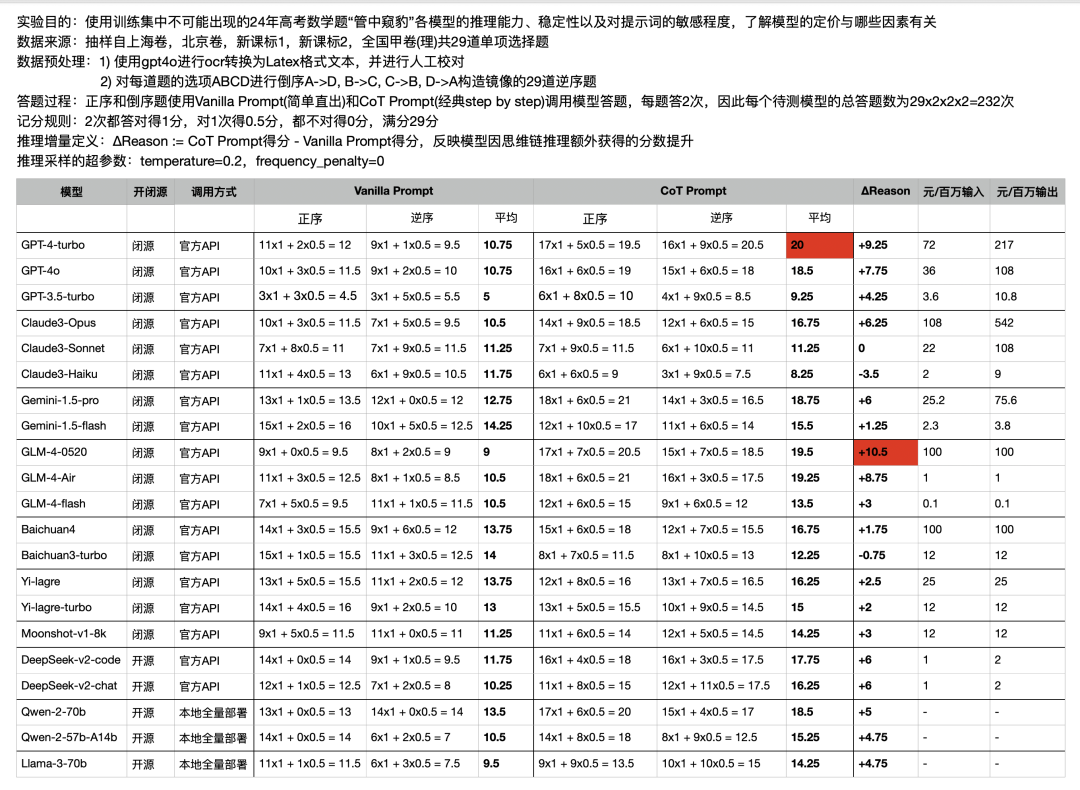
图:测试结果记录
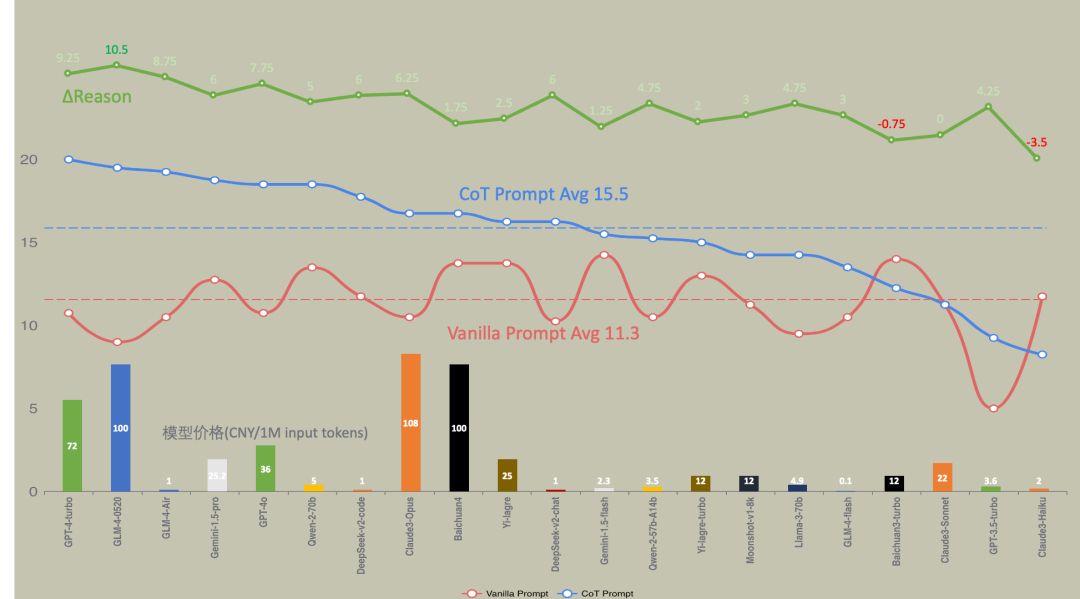
图:模型测试全景图
陆游博士的结论
目前大模型能力已经达到独立做高考数学题的水准,使用未精调的CoT Prompt,旗舰模型可以做对约70%的单选题
国产旗舰模型在这个测试场景下已经非常接近国外旗舰模型
模型升级后并不能一致性的提高Vanilla Prompt和CoT Prompt的得分
模型升级其实是模型上限的提升,而这上限需要Prompt去激发,否则会发生贵1000倍的模型比不上便宜1000倍模型的极端情况
同厂商发布的不同模型的定价不仅与CoT Prompt得分而且与ΔReason高度正相关,ΔReason越高的模型说明模型靠推理获得的泛化能力越强
Vanilla Prompt得分甚至与模型定价(能力)有负相关的倾向
正序题和逆序题答对数的方差越大说明模型对输入的敏感程度越高
得0.5分的情况越多说明模型decode输出的空间越发散
所有的评测都难免存在片面性,这个测试也不例外。(请大家不要再留言区打架,嗷本公众号还没有留言功能)
Flag:(25年将实现多模态+agent全自动评测,今年还是有不少手工,25年还要加上交卷时间(执行时间),消耗卡路里(token总费用)等硬指标。)
其他数据留给有兴趣的小伙伴自行挖掘把,比如哪个大模型回答的 1 最多、有没有什么规律等等,那么咱们25年高考再见吧~
附录
Prompt参考
1) Vanilla Prompt

2)COT Prompt
Q&A
Q:为什么本次考试只考单选择题?
A:因为数据预处理和阅卷(填空题各种等价答案、主观题的发散答案)需要投入人力,PSAK虽然已经实现了大部分的自动化操作,但整个流程实操下来还是需要人力介入,例如需要对OCR的Latex格式的题目和答案进行人工校对,以及测试能力不足的模型时需要对不遵从输出格式的答案进行人工阅卷等。由于整个测试只有一个人利用课余时间完成,所以采用了更简单的选择题(不选多选题是因为单选题可以和随机答对数有个直观比较),但作为横向对比各模型的推理能力已足够。或许等25年高考题时,用彼时进化到Agently版本的PSAK结合GPT5可以做到全流程自动化。
Q:为什么选择采用简单经典的Prompt?
A:因为本次测试的主要目的不在于探索提示词实现的答题能力上限,而是测试模型本身在不进行外部工具支持的情况下的推理能力。实际上如果要追求上限,需要对每个模型进行Prompt特调且进行拆分workflow引入fc和reflection,工作量巨大且影响评测的公平性
Q:测试总共花了多少钱?
A:一千多人民币买API key,五百多人民币租卡
Q:测试过程遇到的麻烦事有哪些?
A:免费或者低充值个人账号给的并发数和RPM太低,需要弄很多API key利用PSAK组池子拉高整体并发数,单每个账号多个key的RPM是一起统计的,所以经常需要五六个手机号注册多个号拿key。另外在API调用上,很多厂商虽然说是兼容openai但实际在一些参数细节上兼容做的并不好(例如json_object输出格式,temperature和frequency_penalty取值范围等细节)。最后一些不听话(指令遵循能力差)的模型的输出需要人工去做阅读理解,这部分也会花费不少时间
Q:测试过程中最大的发现是什么?
A:模型升级其实是模型上限的提升,而这上限需要Prompt去激发,否则会发生贵1000倍的模型比不上便宜1000倍模型的极端情况
致谢 & 创作者
1、感谢LangGPT Prompt 诗人群的陆游博士倾力测试,并授权数据与我进行二次创作。
2、感谢 LangGPT 社区、特别是Prompt 诗人群的小伙伴的无私分享。快点加入 LangGPT Prompt 社区。
创作者:
陆游:办公室摸一摸就有卡,群里说一说就有算力,几个亿 Token 随便跑,不怕费用高,就怕 TPM少,低低调调风险意识特别高。
三郎:FishAI 公众号主理者,算是一个有趣的人 :)Linux.do、Deepseek、谷歌 Gemini 自带吹。
THE END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









