







公众号:尤而小屋
编辑:Peter
作者:Peter
大家好,我是Peter~
mlxtend(machine learning extensions,机器学习扩展)是一个用于日常数据分析、机器学习建模的有用Python库。mlxtend可以用作模型的可解释性,包括统计评估、数据模式、图像提取等。
今天给大家介绍一个强大的机器学习建模扩展包:mlxtend的多种绘图,主要内容见思维导图:
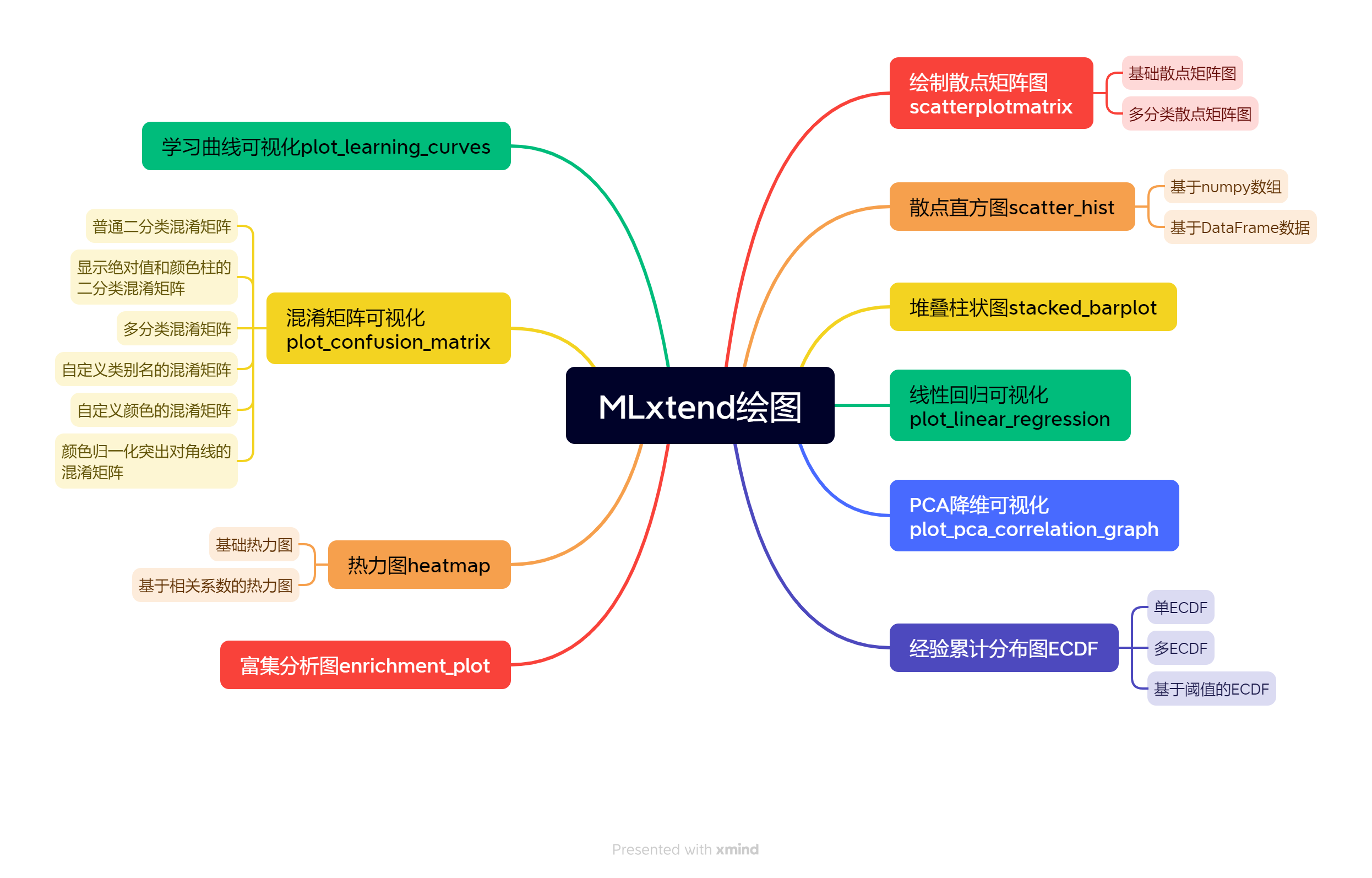
1 MLxtend特点
mlxtend是一个Python第三方库,用于支持机器学习和数据分析任务。其主要功能:
- 数据处理
- 数据:提供了数据集加载和预处理的功能,方便用户处理各种格式的数据集。
- 预处理:包括数据清洗、标准化、归一化等,确保数据质量,提高模型性能等
- 特征选择
- 基于特征重要性的方法:这种方法通过评估各个特征对模型预测能力的贡献度来选择特征。
- 递归特征消除:这是一种通过递归地考虑越来越小的特征子集来选择特征的方法。
- 基于特征子集搜索的方法:这种方法通过搜索最优特征子集来选择特征,通常使用启发式或优化技术来实现。
- 模型评估
- 分类器:提供了多种分类算法的实现,帮助用户进行分类任务的建模和评估。
- 聚类器:提供了多种聚类算法,用于无监督学习中的样本分组。
- 回归器:提供了回归分析的工具,用于预测连续值输出。
- 评估方法:提供了模型性能评估的方法,如交叉验证、得分指标等。
- 数据可视化
- 绘图:提供了丰富的绘图功能,帮助用户在数据探索和分析过程中可视化数据分布和模型结果。
- 图像:支持图像数据的处理和分析,扩展了机器学习在视觉领域的应用。
官方学习地址:https://rasbt.github.io/mlxtend/
2 导入库
In [1]:
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from matplotlib import cm
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
import itertools
from sklearn.linear_model import LogisticRegression # 逻辑回归分类
from sklearn.svm import SVC # SVC
from sklearn.ensemble import RandomForestClassifier # 随机森林分类
from mlxtend.classifier import EnsembleVoteClassifier # 从mlxtend导入集成投票表决分类算法
from mlxtend.data import iris_data # 内置数据集
from mlxtend.plotting import plot_decision_regions # 绘制决策边界
import warnings
warnings.filterwarnings('ignore')
3 绘制散点矩阵图scatterplotmatrix
scatterplotmatrix(
X, # 待绘图的数据
fig_axes=None, # (fig,axes)的元组
names=None, # 名称
figsize=(8, 8), # 图形大小
alpha=1.0 # 透明度
)
返回值是fig_axes:(fig, axes)的元组;fig对象+axes对象,fig,axes=plt.subplots(…)
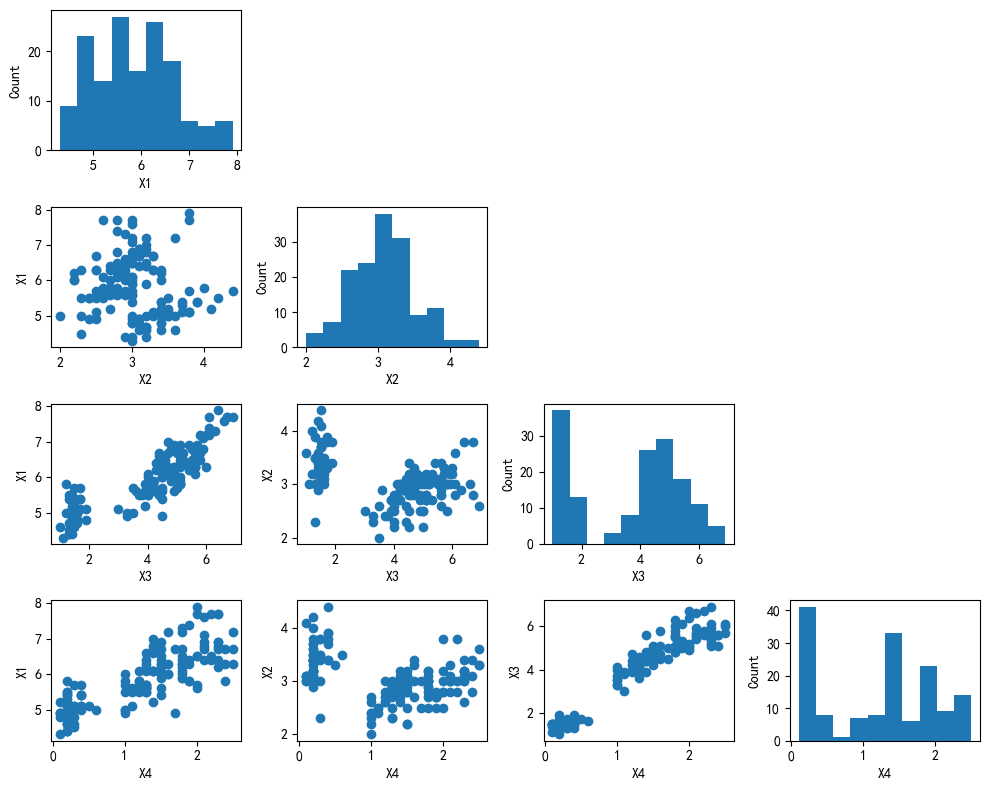
3.1 基础散点矩阵图
In [2]:
import matplotlib.pyplot as plt
from mlxtend.data import iris_data
from mlxtend.plotting import scatterplotmatrix # 散点矩阵图
X, y = iris_data()
y
Out[2]:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
In [3]:
scatterplotmatrix(X, figsize=(10, 8))
plt.tight_layout()
plt.show()
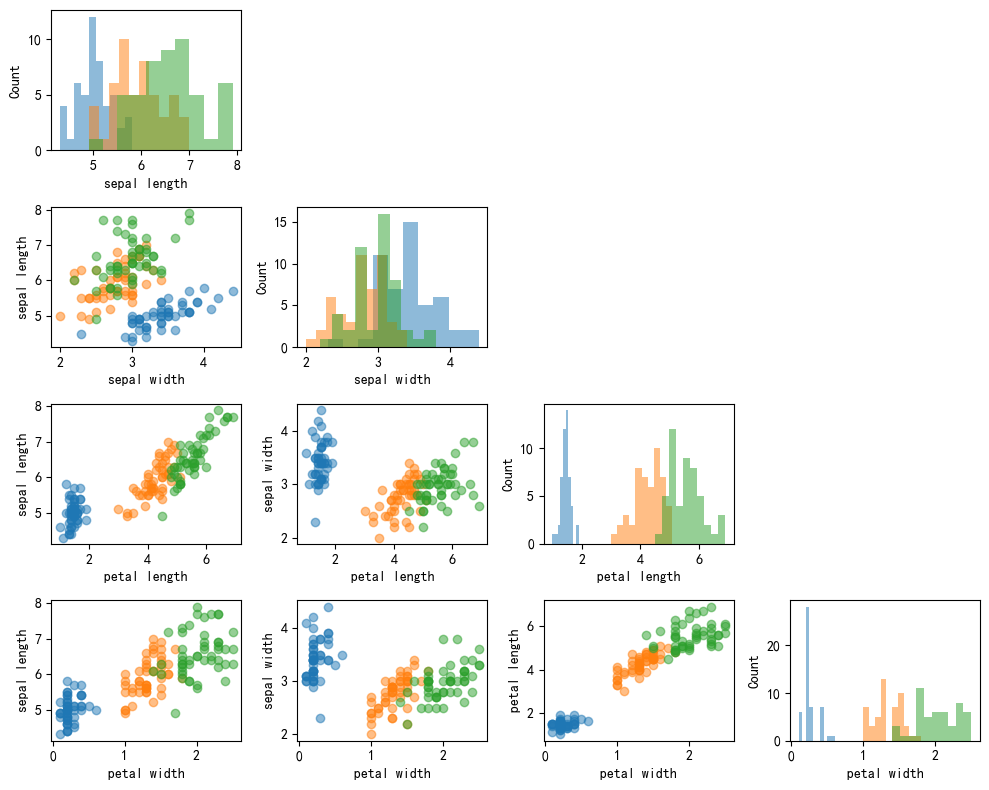
3.2 多分类散点矩阵图
In [4]:
names = ['sepal length', 'sepal width','petal length', 'petal width']
fig, axes = scatterplotmatrix(X[y==0], figsize=(10, 8), alpha=0.5) # y=0的数据
fig, axes = scatterplotmatrix(X[y==1], fig_axes=(fig, axes), alpha=0.5) # y=0的数据
fig, axes = scatterplotmatrix(X[y==2], fig_axes=(fig, axes), alpha=0.5, names=names)
plt.tight_layout()
plt.show()
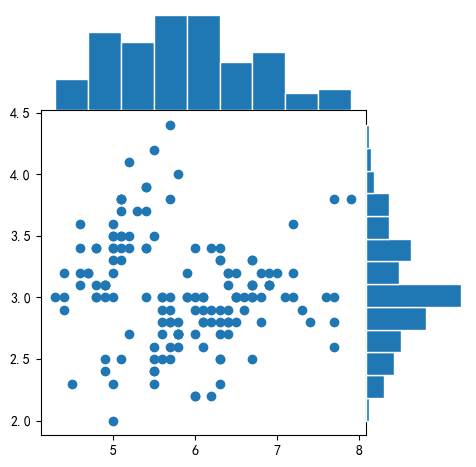
4 散点直方图scatter_hist
In [5]:
from mlxtend.data import iris_data
from mlxtend.plotting import scatter_hist
import pandas as pd
4.1 基于numpy数组的散点直方图
In [6]:
X,y = iris_data()
X[:3] # numpy数组形式
Out[6]:
array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2]])
In [7]:
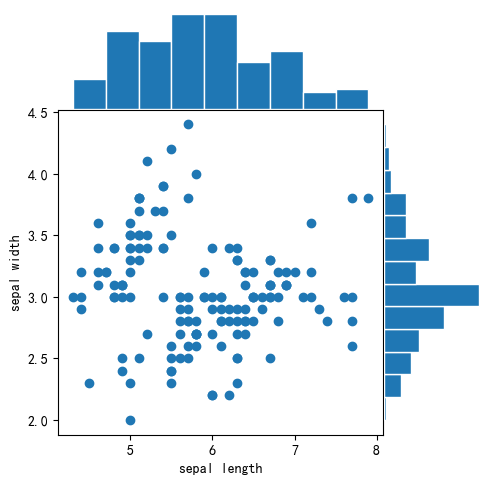
fig = scatter_hist(X[:,0], X[:,1]) # 传入两列数据
plt.show()
4.2 基于DataFrame数据的散点直方图
In [8]:
df = pd.DataFrame(X) # 生成DataFrame数据
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width']
df.head()
Out[8]:
| sepal length | sepal width | petal length | petal width | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
In [9]:
from mlxtend.plotting import scatter_hist
fig = scatter_hist(df["sepal length"], df["sepal width"])
plt.show()
5 堆叠柱状图stacked_barplot
In [10]:
import 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









