






 夕小瑶科技说 原创
夕小瑶科技说 原创
作者 | 海野
OpenAI的Q* 项目,也就是后来在网上沸沸扬扬的Strawberry草莓,终于定档于秋季上线。
据The Information爆料,作为GPT-4的下一代,Strawberry很惊艳:
拥有极强的推理和数学能力;
减少了幻觉问题;
能够主动进行“思考”,解决复杂的问题(耗时较长)。
根据路透社的报道,早在七月份,OpenAI就已经向美国国家安全局展示过这个模型的技术。OpenAI内部也已经在使用这个新的模型。
而在八月初,Sam Altman发布了一些带草莓照片的推文,这种暗示不言而喻:昭告所有人,草莓模型要来了!

哎……它真来了吗?OpenAI卷起了草莓狂欢热,却没有带来对应的期货。互联网上逐渐出现一些质疑声,痛批OpenAI的无实物炒作。

与此同时,OpenAI的其他弊病也被披露出来:
已经预告了数个月的sora模型,迟迟没有上线;
searchGPT暂停开放测试;
GPT-4o的语音功能依然在waiting list,仅限少部分人使用。
以Claude为首的各家大模型,逐渐在不同方面超越了GPT-4o,而OpenAI并没有进行反击,也没有带来更强的新模型。
等等等等……
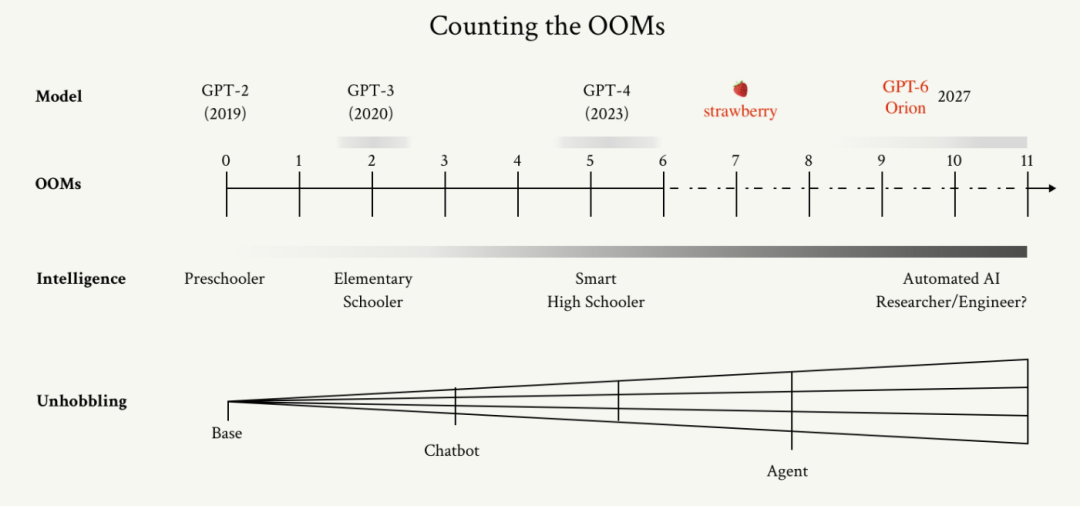
直至今日,OpenAI依然在巨大的舆论风波之中。终于,OpenAI带来了一个振奋人心的消息:Strawberry不是终点,我们开始用Strawberry训练新的模型Orion !
而关于Strawberry模型的问题,OpenAI也做出了回应
为什么迟迟没有上线?
一言概之就两个问题:安全和竞争。
关于安全问题,我们看OpenAI最近常发的文章就可以知晓:



OpenAI在安全方面做出了很多举措。由于发布安全问题推文的频率之高,OpenAI甚至被网友们戏称,应该改名为SafeAI。
但即便是这样的安全保障举措,依然没有讨得美国国家安全局的芳心。
此前,因为人工智能发展速度过快,安全和监管没有起到应有的效果,人工智能先驱Yoshua Bengio决定与人工智能教父Geoff Hinton一起,投入更多精力来倡导人工智能监管。

另外,美国国家安全局的另一个考量是,要防止其他国家使用strawberry模型合成数据,从而训练出更强大的模型。
出于各种安全考虑,Strawberry模型被禁止直接向公众提供服务。
所以,接下来在秋季公开的Strawberry,也是一个小型的蒸馏模型,削弱了推理能力,更主要的用于聊天。不过也能满足公众的个人使用需求。
根据预测,Strawberry聊天模型可能会在十月Devday的时间上线;也有可能会在十一月美国大选结束后上线。

Strawberry模型的完全体,则会在OpenAI的内部使用,用来生成高质量的合成数据,训练Orion模型——GPT-6。
而OpenAI选择这样举措的原因,就是竞争的问题了。
OpenAI,选择了更进一步封闭
OpenAI放弃了strawberry完全体(GPT-5)模型的发布,转而训练更先进的模型Orion,以确保自己能断崖式的碾压竞争对手。
OpenAI似乎忘记了自己的原始使命(开发开源技术造福人类),转而走向了闭源和盈利。而对于这项选择,我们也不难看出OpenAI的考量:
为什么在GPT-4上线后,各竞争对手以及开源模型,进步速度突飞猛进?因为GPT-4经常被用于合成数据,这些合成数据就会被用来训练其他家的模型。
要知道,优质的大模型往往建立在庞大的数据集的训练上,而现有的公开真实数据,早已被各家厂商用遍了。拉开差距的方法之一,就是使用人为创建的合成数据。创建合成数据使用的模型越先进,数据集越强大。

为了避免这种情况继续发生,为了保持领先地位,OpenAI只能选择闭境自守,用下一代模型训练下下代模型,从而实现遥遥领先。
如果OpenAI真的可以实现如此成效,那各大开源模型可能要狠狠地吃瘪了。这一场比赛很可能会演变成一次文明的游戏。
OpenAI的动向也透露出一个信号,也许不久后,这种超级AI会成为新的封闭的资源,对其进行掌握和控制,会成为下一轮科技竞赛的核心。

参考资料
[1]https://x.com/imxiaohu/status/1828258507197690201
往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)
















 6358
6358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









