







在上一节中(https://juejin.cn/post/7271942371636789300 ),我们结合具体的数据集,介绍了如何对单一数据集进行分析,包括了条件筛选方法和如何用自定义函数来操作数据集中的元素。在本章,将介绍多数据集的数据处理和分析方法,重点介绍如何做关联分析。
8.关联分析
8.1 数据集的合并
在数据的收集过程中,会遇到多个数据合并的情况。concat函数一般用于不同数据集之间的合并。
还是延续之前的成绩单数据,假设有A班和B班两个数据集:
>>> import pandas as pd
>>> class_a = pd.DataFrame(
{
'NAME': ['Arial Johnson', 'Derek Davis', 'Latoya Mitchell'],
'COURSE1': [99, 88, 81],
'COURSE2': [67, 76, 98],
'COURSE3': [93, 97, 91],
'COURSE4': [95, 65, 80]
})
>>> class_b = pd.DataFrame(
{
'NAME': ['Tanisha Harris', 'Devin Price'],
'COURSE1': [61, 97],
'COURSE2': [58, 77],
'COURSE3': [94, 51],
'COURSE4': [53, 65]
})
>>> class_a
NAME COURSE1 COURSE2 COURSE3 COURSE4
0 Arial Johnson 99 67 93 95
1 Derek Davis 88 76 97 65
2 Latoya Mitchell 81 98 91 80
>>> class_b
NAME COURSE1 COURSE2 COURSE3 COURSE4
0 Tanisha Harris 61 58 94 53
1 Devin Price 97 77 51 65
concat函数的用法:
# 单纯的合并,此时的索引仍然保留原始的索引:
>>> pd.concat([class_a, class_b], ignore_index=False)
NAME COURSE1 COURSE2 COURSE3 COURSE4
0 Arial Johnson 99 67 93 95
1 Derek Davis 88 76 97 65
2 Latoya Mitchell 81 98 91 80
0 Tanisha Harris 61 58 94 53
1 Devin Price 97 77 51 65
# 可以看到索引并没有变化
- ignore_index:忽略索引,默认False。如果为True,则不在连接轴上使用索引值。结果轴将被标记为0,…,n-1。这在使用对象时非常有用,其中连接轴没有有意义的索引信息。请注意,在其他轴上的索引值在连接时仍然被保持。
# 将ignore_index设置为True,可以重构索引
>>> pd.concat([class_a, class_b], ignore_index=True)
NAME COURSE1 COURSE2 COURSE3 COURSE4
0 Arial Johnson 99 67 93 95
1 Derek Davis 88 76 97 65
2 Latoya Mitchell 81 98 91 80
3 Tanisha Harris 61 58 94 53
4 Devin Price 97 77 51 65
- axis: 这个参数之前介绍过,要进行合并的轴,默认按行进行合并,当按列进行合并时,则会出现下面的效果,注意,对成绩单而言,这样的合并并没有实际意义。默认值为0。
>>> pd.concat([class_a, class_b], axis=1, ignore_index=True)
0 1 2 3 4 5 6 7 8 9
0 Arial Johnson 99 67 93 95 Tanisha Harris 61.0 58.0 94.0 53.0
1 Derek Davis 88 76 97 65 Devin Price 97.0 77.0 51.0 65.0
2 Latoya Mitchell 81 98 91 80 NaN NaN NaN NaN NaN
- keys : 序列,默认None。使用传递的键作为最外层构造层次索引。如果传递了多个级别,则应包含元组。
>>> pd.concat([class_a, class_b], keys=['A', 'B'])
NAME COURSE1 COURSE2 COURSE3 COURSE4
A 0 Arial Johnson 99 67 93 95
1 Derek Davis 88 76 97 65
2 Latoya Mitchell 81 98 91 80
B 0 Tanisha Harris 61 58 94 53
1 Devin Price 97 77 51 65
给现有的数据集添加一条数据,也可以用concat来实现,如在B班加入一个叫Michael Smith的同学。
>>> new_student = pd.Series(["Michael Smith", 72, 76, 85, 88], index=["NAME", "COURSE1", "COURSE2", "COURSE3", "COURSE4"])
>>> pd.concat([class_b, new_student.to_frame().T], ignore_index=True)
NAME COURSE1 COURSE2 COURSE3 COURSE4
0 Tanisha Harris 61 58 94 53
1 Devin Price 97 77 51 65
2 Michael Smith 72 76 85 88
8.2 数据集的连接
在使用跨数据集的分析时,需要找到它们之间的关联关系,就不得不需要用到数据集的连接。数据集的连接可以用merge函数来实现。
8.2.1 连接的类型——按方法划分
根据连接的方法,可以分为内连接、左连接、右连接和外连接和交叉连接,在做数据集的关联时,可以通过how参数来指定连接的方式。下表是Merge方法和SQL中的连接的比较:
| Merge method | SQL Join Name | Description |
|---|---|---|
left | LEFT OUTER JOIN | Use keys from left frame only |
right | RIGHT OUTER JOIN | Use keys from right frame only |
outer | FULL OUTER JOIN | Use union of keys from both frames |
inner | INNER JOIN | Use intersection of keys from both frames |
cross | CROSS JOIN | Create the cartesian product of rows of both frames |
默认情况下,how=NA时,采用的是内连接(Inner Join)的方式。Pandas的官方文档对不同的连接方式做了详细地说明,以其提供的数据集为例,有一个直观的说明。
>>> left = pd.DataFrame(
{
"key1": ["K0", "K0", "K1", "K2"],
"key2": ["K0", "K1", "K0", "K1"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
>>> right = pd.DataFrame(
{
"key1": ["K0", "K1", "K1", "K2"],
"key2": ["K0", "K0", "K0", "K0"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
- 内连接-Inner Join
>>> result = pd.merge(left, right, how="left", on=["key1", "key2"])
# 等价于
>>> result = pd.merge(left, right, how="left", on=["key1", "key2"], how='inner')

这里值得额外说明的是,当数据集的左连接键和右连接键的名称不一致的时候,也是可以支持的,可以分别用left_on和right_on来指定左右数据集的连接键名称。上面的语句等价于:
result = pd.merge(left, right, how="left", left_on=["key1", "key2"], right_on=["key1", "key2"])
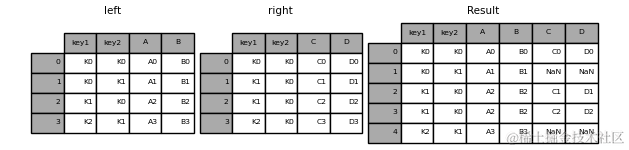
- 左连接-Left Join
注意NaN出现的位置。
>>> result = pd.merge(left, right, how="left", on=["key1", "key2"])
- 右连接-Right Join
>>> result = pd.merge(left, right, how="right", on=["key1", "key2"])

- 外连接-Outer Join
>>> result = pd.merge(left, right, how="outer", on=["key1", "key2"])
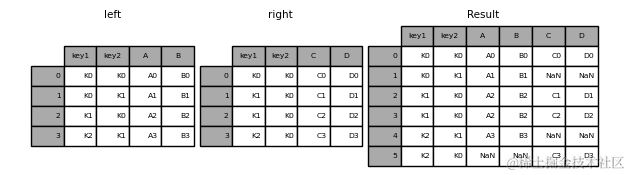
对于全连接,指定indicator参数可以创建一个新的列,来说明merge结果的类型,进而可以对全连接的数据做进一步筛选,indicator的值为新生成的列名。
| Observation Origin | _merge value |
|---|---|
Merge key only in 'left' frame | left_only |
Merge key only in 'right' frame | right_only |
| Merge key in both frames | both |
>>> pd.merge(left, right, how="outer", on=["key1", "key2"], indicator='merge_result')
key1 key2 A B C D merge_result
0 K0 K0 A0 B0 C0 D0 both
1 K0 K1 A1 B1 NaN NaN left_only
2 K1 K0 A2 B2 C1 D1 both
3 K1 K0 A2 B2 C2 D2 both
4 K2 K1 A3 B3 NaN NaN left_only
5 K2 K0 NaN NaN C3 D3 right_only
- 交叉连接-Cross Join
>>> result = pd.merge(left, right, how="cross")
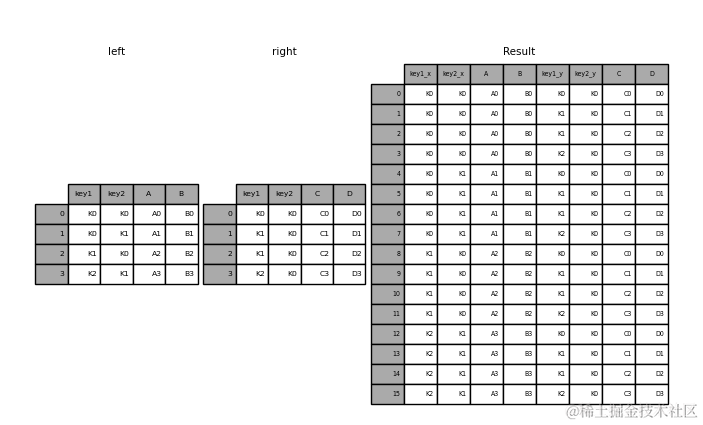
交叉连接也称笛卡尔积(Cartesian product)连接,在数学中,两个集合X和Y的笛卡尔积,又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员。
例如,如果集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a,0), (a,1), (a,2), (b,0), (b,1), (b,2)}。
8.2.2 连接的类型——按结果划分
根据连接的结果,可以划分为下面的几类:
- 一对一连接(one_to_one)
- 多对一连接(one_to_many)
- 一对多连接(many_to_one)
- 多对一连接(many_to_many)
想必在上一节的图片中,你也注意到了一些场景下,连接的结果集会发生膨胀。如果一个键组合在两个表中都出现多次,则结果表将具有关联数据的笛卡尔积。在一些极端情况下,做数据集的连接会因为数据的急剧膨胀导致内存溢出。因此在做表的关联之前,首先要了解关联键组合的唯一性,并做好相应的预处理。在具体实践中,比较常见的是关联键出现空值导致的笛卡尔积,这也再次验证了在正式的数据分析之前做好数据的预处理工作是非常有必要的。
如果在数据集的关联前不知道关联后的结果情况,可以使用validate参数自动检查合并键中是否存在意外的重复项。在执行合并操作之前,会检查键的唯一性,因此应该能够避免内存溢出。检查键的唯一性也是确保用户数据结构符合预期的好方法。
>>> left = pd.DataFrame({"A": [1, 2], "B": [1, 2]})
>>> right = pd.DataFrame({"A": [4, 5, 6], "B": [2, 2, 2]})
>>> pd.merge(left, right, on="B", how="outer", validate="one_to_one")
Traceback (most recent call last):
File "C:\Python36\lib\code.py", line 91, in runcode
exec(code, self.locals)
File "<input>", line 1, in <module>
File "C:\Python36\lib\site-packages\pandas\core\reshape\merge.py", line 86, in merge
validate=validate,
File "C:\Python36\lib\site-packages\pandas\core\reshape\merge.py", line 637, in __init__
self._validate(validate)
File "C:\Python36\lib\site-packages\pandas\core\reshape\merge.py", line 1259, in _validate
"Merge keys are not unique in right dataset; "
pandas.errors.MergeError: Merge keys are not unique in right dataset; not a one-to-one merge
在上面的示例中,连接的结果未满足one_to_one的预期,因此会出现报错,将validate改成one_to_many,则可以正常输出:
>>> pd.merge(left, right, on="B", how="outer", validate="one_to_many")
A_x B A_y
0 1 1 NaN
1 2 2 4.0
2 2 2 5.0
3 2 2 6.0
validate参数可以有效保证数据集关联的有效性,合理的应用此参数,是提高数据分析效率的好办法。validate可指定的检查方法:
“one_to_one” or “1:1”: checks if merge keys are unique in both left and right datasets.
“one_to_many” or “1:m”: checks if merge keys are unique in left dataset.
“many_to_one” or “m:1”: checks if merge keys are unique in right dataset.
“many_to_many” or “m:m”: allowed, but does not result in checks.
8.2.3 按索引连接
在8.2.1中介绍的merge函数可用于按列进行连接的情况,而如果想按照DataFrame的索引进行连接,则可以考虑用join方法。
>>> left = pd.DataFrame(
{"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]}, index=["K0", "K1", "K2"]
)
>>> right = pd.DataFrame(
{"C": ["C0", "C2", "C3"], "D": ["D0", "D2", "D3"]}, index=["K0", "K2", "K3"]
)
# 默认为left join
>>> result = left.join(right)
>>> result
A B C D
K0 A0 B0 C0 D0
K1 A1 B1 NaN NaN
K2 A2 B2 C2 D2
>>> result = left.join(right, how='left')
>>> result
A B C D
K0 A0 B0 C0 D0
K1 A1 B1 NaN NaN
K2 A2 B2 C2 D2
>>> result = left.join(right, how='right')
>>> result
A B C D
K0 A0 B0 C0 D0
K2 A2 B2 C2 D2
K3 NaN NaN C3 D3
>>> result = left.join(right, how='inner')
>>> result
A B C D
K0 A0 B0 C0 D0
K2 A2 B2 C2 D2
>>> result = left.join(right, how='outer')
>>> result
A B C D
K0 A0 B0 C0 D0
K1 A1 B1 NaN NaN
K2 A2 B2 C2 D2
K3 NaN NaN C3 D3
关于join的其他参数,使用方法和原理与merge类似,在此不做赘述。
8.3 数据集的对比
在做两个数据集的对比时,一方面可以用上一节介绍的连接方法,提取两个数据集中不一样的地方。同时,也提供了一个compare方法,对两个数据集做比较。值得注意的是,compare方法是在V1.1.0版本之后才添加的,若无法找到该函数,可以升级pandas版本。
创建两个数据集:
>>> import numpy as np
>>> df = pd.DataFrame(
{
"col1": ["a", "a", "b", "b", "a"],
"col2": [1.0, 2.0, 3.0, np.nan, 5.0],
"col3": [1.0, 2.0, 3.0, 4.0, 5.0],
},
columns=["col1", "col2", "col3"],
)
>>> df2 = df.copy()
>>> df2.loc[0, "col1"] = "c"
>>> df2.loc[2, "col3"] = 4.0
>>> df
col1 col2 col3
0 a 1.0 1.0
1 a 2.0 2.0
2 b 3.0 3.0
3 b NaN 4.0
4 a 5.0 5.0
>>> df2
col1 col2 col3
0 c 1.0 1.0
1 a 2.0 2.0
2 b 3.0 4.0
3 b NaN 4.0
4 a 5.0 5.0
对比两个数据集的不同:
>>> df.compare(df2)
col1 col3
self other self other
0 a c NaN NaN
2 NaN NaN 3.0 4.0
>>> df.compare(df2, align_axis=0)
col1 col3
0 self a NaN
other c NaN
2 self NaN 3.0
other NaN 4.0














 8068
8068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









