







在上一节中( https://juejin.cn/post/7261604498924273701 ),介绍了怎么对数据进行预处理和数据集的整合,接下来从本章开始进行数据集的探索和分析,初步了解数据集。
5.统计分析
了解一个数据集最好的方法是通过常用的统计分析方法来求出数据集的统计特征,包括数据集的大小,数值的特征,数据分布情况等等。
5.1 测试数据集
为了更好地说明问题,从本节开始引入测试数据集,以下是来自A和B两个班级5位学生的考试成绩单可以根据该成绩单进行分析。
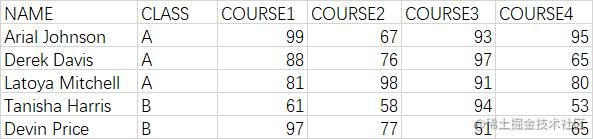
初始化数据集:
import pandas as pd
data = {
'NAME': ['Arial Johnson', 'Derek Davis', 'Latoya Mitchell', 'Tanisha Harris', 'Devin Price'],
'CLASS': ['A', 'A', 'A', 'B', 'B'],
'COURSE1': [99, 88, 81, 61, 97],
'COURSE2': [67, 76, 98, 58, 77],
'COURSE3': [93, 97, 91, 94, 51],
'COURSE4': [95, 65, 80, 53, 65]
}
df = pd.DataFrame(data)
5.2 描述性统计分析
对于一个数据集而言,其主要的统计特征有:
- 求和:数据集中所有元素的总和;
- 平均值:数据集中所有数据的总和除以数据个数;
- 中位数:将数据集从小到大排序后,位于中间的数值;
- 众数:数据集中出现次数最多的数值;
- 最大值:数据集中最大的数值;
- 最小值:数据集中最小的数值;
- 极差:最大值减去最小值的差;
- 标准差:数据集各数据与其平均值的差值平方的平均值的算术平方根,表示数据集的离散程度。
5.2.1 求和函数以及参数说明
# 求每个人的总得分
>>> df[['COURSE1', 'COURSE2', 'COURSE3', 'COURSE4']].sum(axis=1)
0 354
1 326
2 350
3 266
4 290
dtype: int64
# 求每个科目的总得分
>>> df[['COURSE1', 'COURSE2', 'COURSE3', 'COURSE4']].sum(axis=0)
COURSE1 426
COURSE2 376
COURSE3 426
COURSE4 358
dtype: int64
在数组操作中,有一个参数特别值得注意,那就是axis,其中axis=0表示按行操作,axis=1表示按列操作,axis取值不同,得出来的结果差别很大。一个 DataFrame 对象有两个轴,分别是 “axis=0" 和 “axis=1“ ,“axis=0” 代表“跨行”,“axis=1“代表“跨列。关于axis的理解可以参照:https://zhuanlan.zhihu.com/p/444973350

当数据的列数很多时,我们如果只想统计包含了数据的列,numeric_only参数可以解决问题,用了这个参数,就不需要单独指定含有数据的列了,使用起来更加便捷:
>>> df.sum(axis=0,numeric_only=True)
COURSE1 426
COURSE2 376
COURSE3 426
COURSE4 358
dtype: int64
>>> df.sum(axis=1,numeric_only=True)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3862
3862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









