






什么是数据预处理
数据预处理的概念
指数据分析之前,对数据进行加工处理,使数据在后续的分析方法中更加的准确、有效。
数据预处理的种类
主要有:数据合并、数据清洗、数据转换。

数据合并:
将两个表格中的数据通过一定的逻辑合并到一起。
拼接合并的概念:
纵向拼接:指将两个列名相同的Datafrmae表格对象上下拼接到一起。
横向拼接:指将两个索引相同的Datafrmae表格对象左右拼接到一起。
拼接合并的现实方法:
pd.concat()函数
语法结构:pd.concat([表格对象1,表格对象2],axis=0或1)
axis默认为0,表示横向拼接,axis=1时表示纵向拼接
主键合并的概念:
基于两个表共有的主键(即某列数据)将两个表的数据根据主键相同原则进行拼接(匹配)。
同理于SQL语言中的join语句、Excel中的VLOOKUP函数。
主键合并的方式:
根据合并后显示数据的逻辑不同,将主键合并分为:左连接、右连接、内连接、外连接
左连接:结果只显示左表的主键所对应的数据
右连接:结果只显示右表的主键所对应的数据
内连接:结果只显示左表和右表共有的主键所对应的数据
外连接:结果显示左表和右表所有的主键所对应的数据
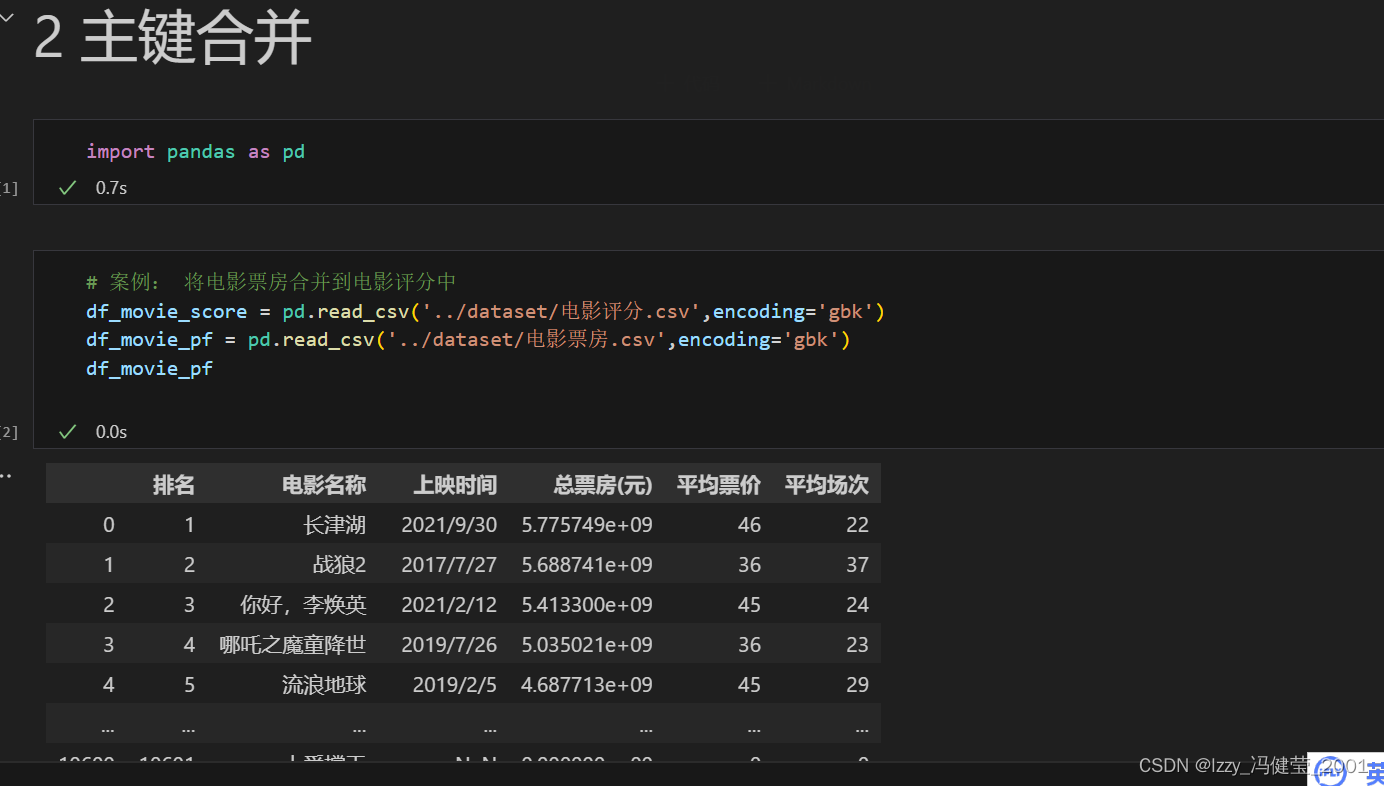
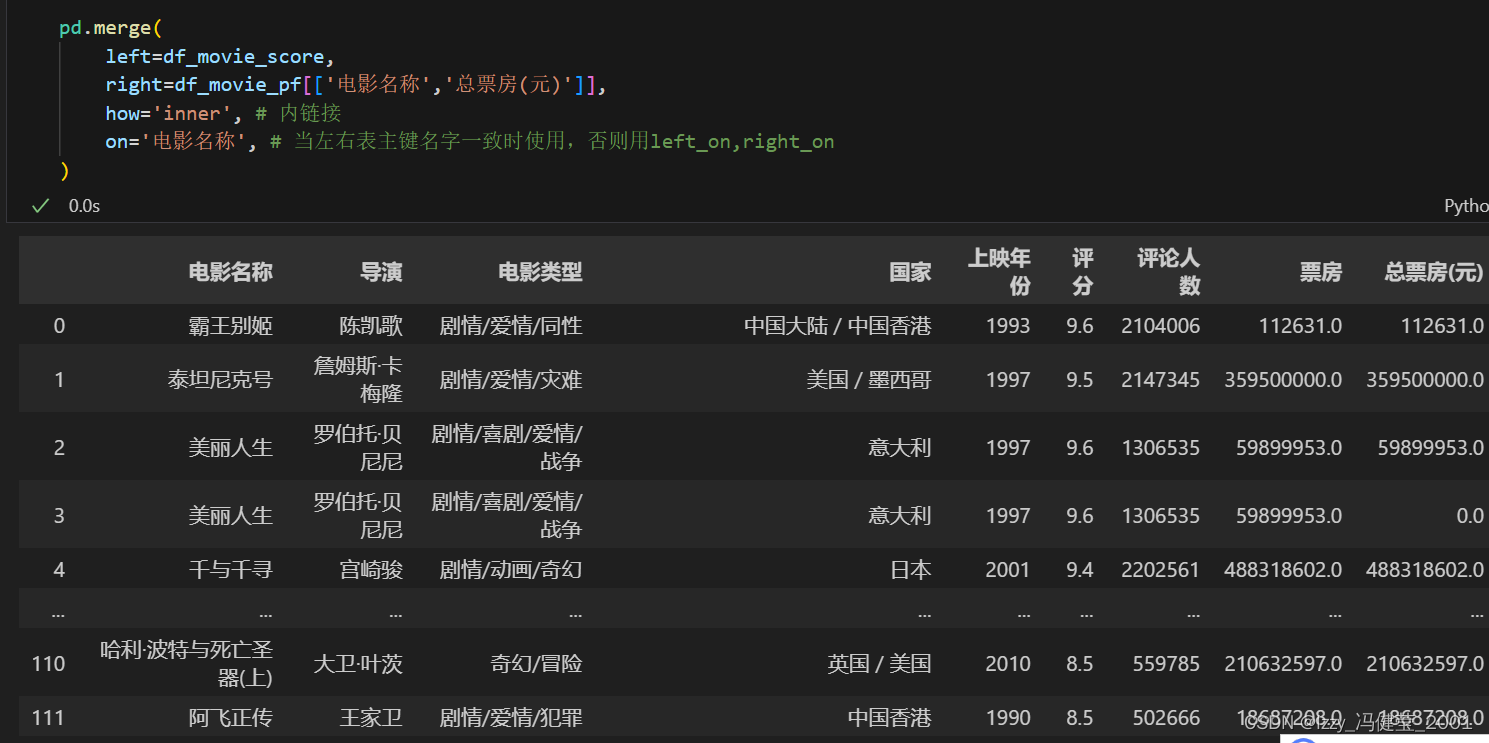
主键合并函数pd.merge()
各参数的含义
pd.merge(left,right,how='inner',on=None,left_on=None,right_on=None)
数据清洗:
去除重复值、处理缺失值、处理异常值。
去除重复值:
去重方法drop_duplicates()
去重的概念:删除某个序列或是表格中某个序列中的重复数据。
去重方法:DataFrame表格和Series序列对象内置方法drop_duplicates()
语法结构:表格/序列对象.drop_duplicates(subset=None ,keep='first', inplace=False)
| 参数 | 作用 |
| subset | 当去重对象是表格对象时使用,指定去重依据的字段 |
| keep | 指定去重后保留哪一行,first表示第一行,last表示最后一行 |
| inplace | 表示去重是否对在原始数据对象上进行 |
对Dataframe表格对象去重:
通过subset参数指定通过哪一列数据来去重。
df.drop_duplicates(subset=['姓名'])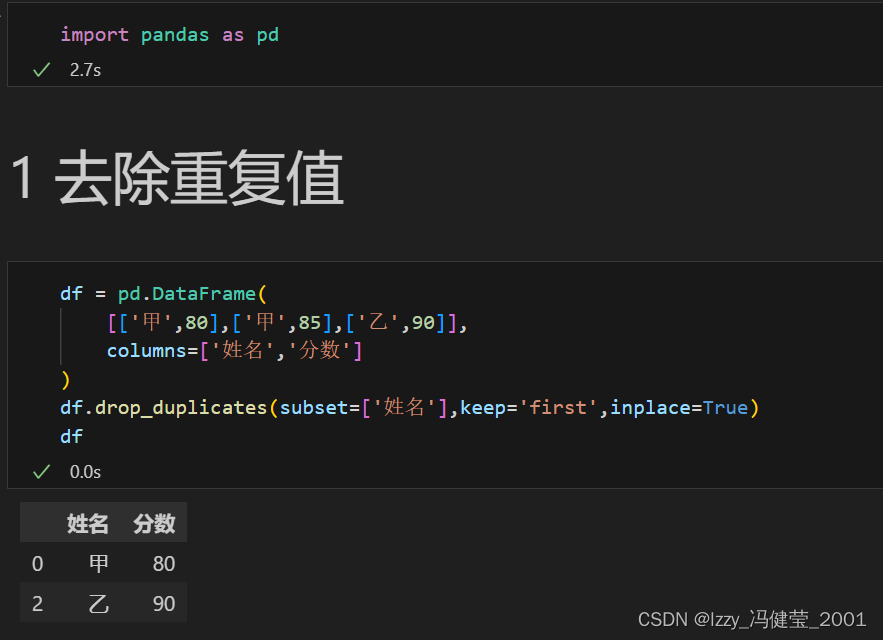
处理缺失值:
缺失值的定义:在现实的数据的产生场景中,由于人为原因或系统原因导致的数据缺失问题。
查看数据的缺失值:
表格对象.isnull()方法返回数据是否缺失的布尔值矩阵。
表格对象.isnull().sum()返回各列的缺失值数量。
df_user.isnull().sum()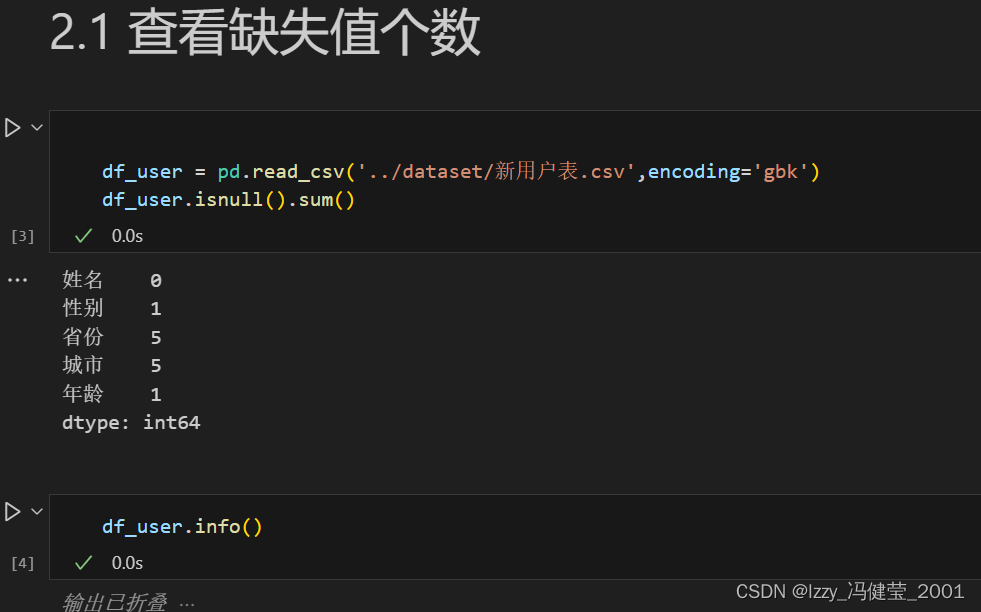
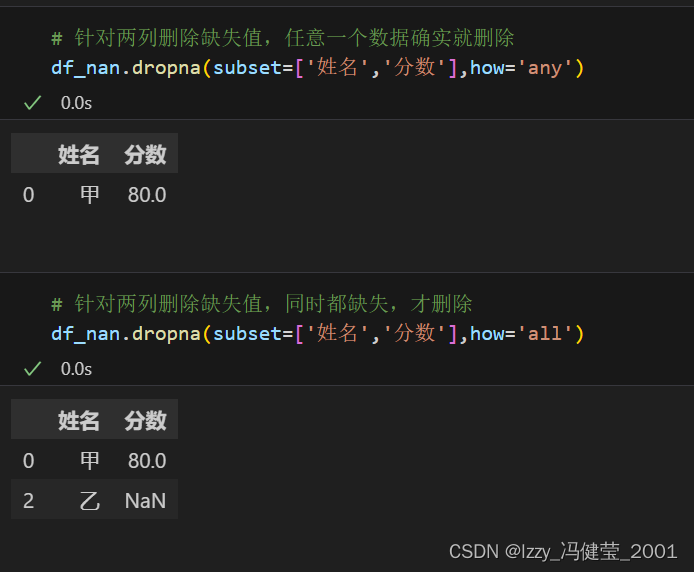
删除法处理缺失值:
删除法:删除某个缺失数据所在的行的所有数据。
语法结构:表格对象.dropna(axis=0,how='any',subset=None,inplace=False)
| 参数 | 作用 |
| axis | 指定删除行或者列,默认为0,表示删除行 |
| how | 对表格对象多个字段的缺失值进行删除时使用。 'all'表示所有字段都缺失才删除。 |
| subset | 指定要删除的缺失值来自哪一(几)列 |
| inplace | 表示是否对原数据生效,默认为False |


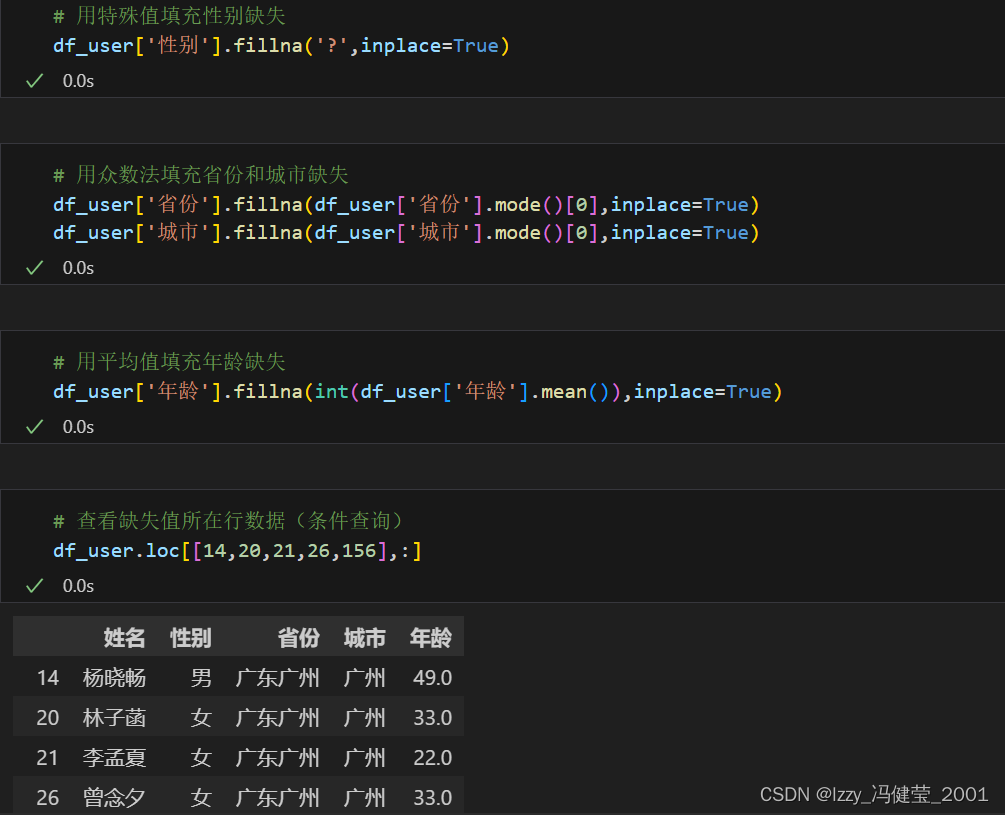
替换法处理缺失值:
替换法:使用某个数据去替换缺失值的处理方法,又叫填充法。
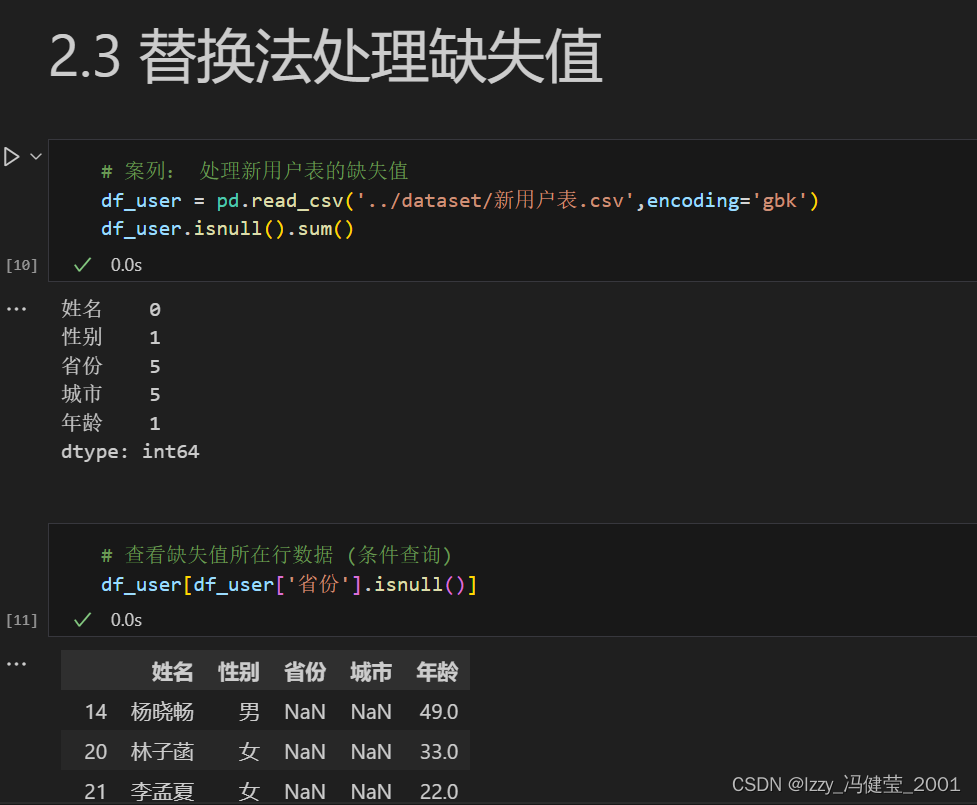
语法结构:序列对象.fillna(values=需要替换的值,inplace=False)
替换法又可以细分为:平均值法、众数法、特殊值法。
平均值法:一般对数值型序列使用。
众数法:一般对类别型序列使用。
特殊值法:一般在能够判断缺失数据和其他数据有不同特征时使用。
处理异常值:
异常值的概念:
从数学角度说,异常值是某一个序列中距离大部分数据较远,远到一定程度的数据。
从通俗角度说,异常值是能根据经验判断的不符合常理的数据。
异常值计算涉及的相关数学概念:
上四分位数(Q3) :序列中75%的数小于这个数。
下四分位数(Q1) :序列中25%的数小于这个数。
IQR: IQR = Q3 - Q1
正常值区间: [Q1 - 1.5 * IQR,Q3 + 1.5 * IQR]
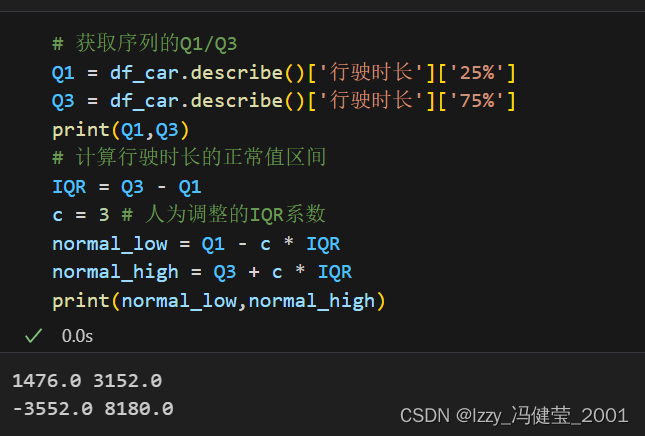
异常值:在正常值区间之外的数。
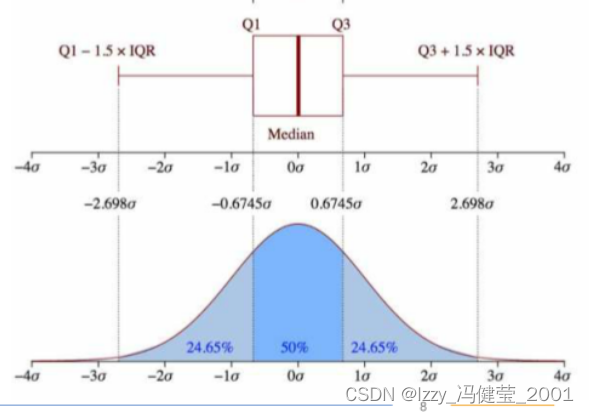
异常值的查找和处理流程:
常用的异常值处理方法有: 删除法, 替换法。
删除法:删除掉异常值数据所在的行。
替换法:用均值法、众数法来替换掉异常值。

数据转换:
数据结构转换:
对数据结构或数据类型进行转换,以便于后续的分析。
常见的数据结构转换方法
Pandas库中常用的数据结构转换方法有数据堆叠(stack)、数据拆堆(unstack)、数据融合(melt)、数据透视(pivot)
数据堆叠(stack):将一个表格对象的列名称转换为行索引,实现数据从矩阵排布到单列排布的堆叠。
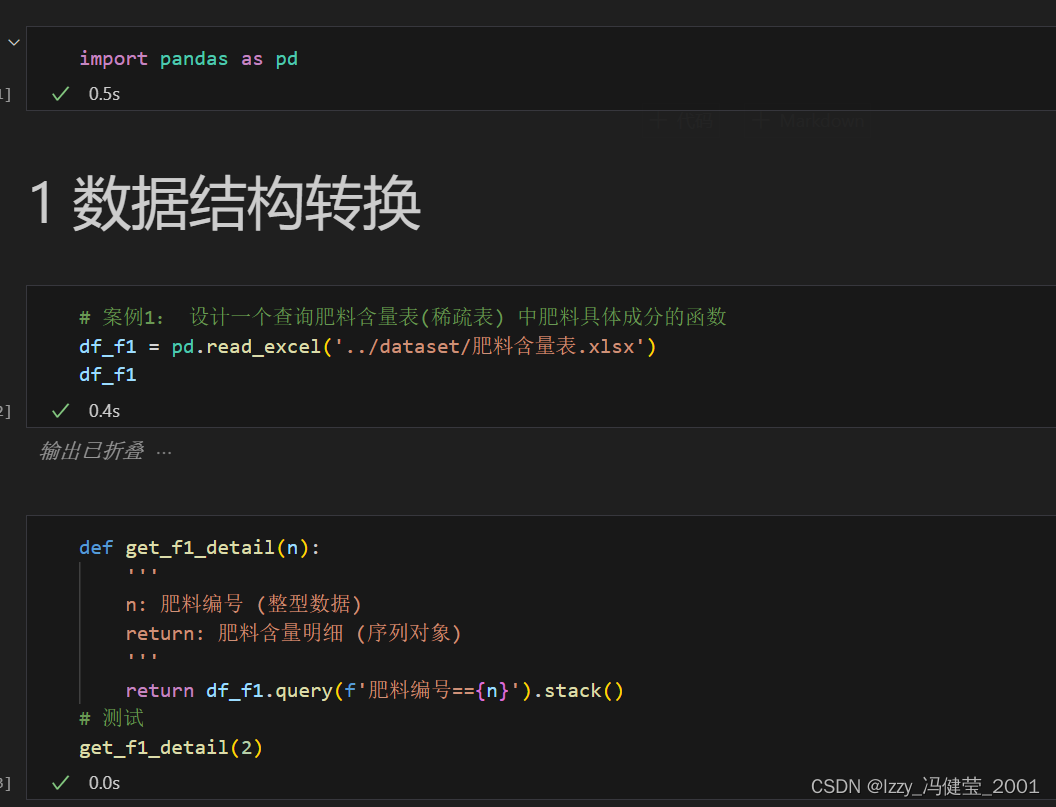
数据堆叠stack方法解析
数据堆叠:将一个表格对象的列名称转换为行索引,实现数据从矩阵排布到单列排布的堆叠。
数据堆叠语法:表格对象.stack(level=-1,dropna=True)
Level表示列名称转换为行索引后的索引层级,默认为-1,即最内层索引。
Dropna表示新数据中的缺失值是否删除。
注意:表格对象数据堆叠后返回一个序列对象。
type(df.stack())
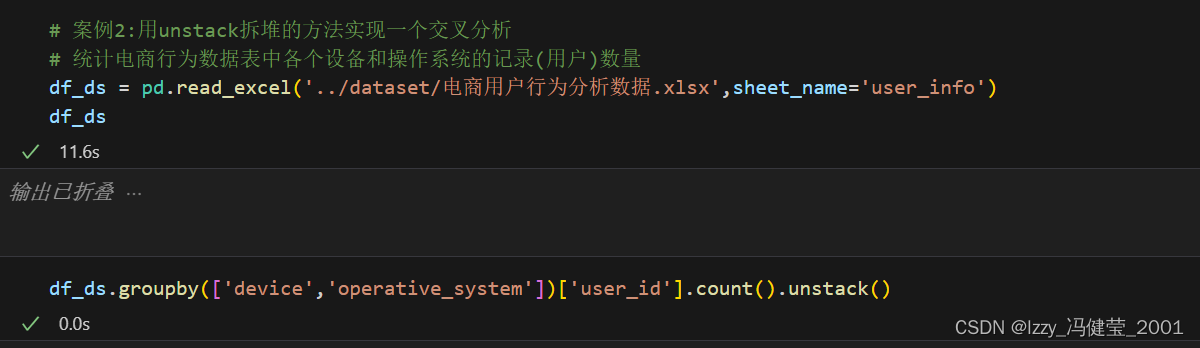
pandas.core.series.Series数据堆叠unstack方法解析
数据拆堆:将一个表格对象的列名称转换为行索引,实现数据从矩阵排布到单列排布的转换。
数据拆堆语法:多层索引序列对象.unstack(level=-1,fill_value=None)
Level表示要将哪个索引层级的行索引转换为列索引,默认为-1,即最内层索引
fill_value表示用于填充缺失值的值,默认为空值
注意:表格对象也可以使用数据拆堆unstack方法,行索引转为列索引后,只有一行数据的表格对象退化为一个序列对象。
数据类型转换:
数据类型的概念
数据类型转换指通过数据处理方法将数字型数据和类别型数据之间进行相互转换。
在计算机编程领域中,基础的数据类型包括数字型(整型、浮点型)、字符型等。
在数学学术领域中,变量类型可以分为连续型变量和离散型变量。
而在数据分析领域中,则一般叫做数字型(value)数据和类别型(category)数据。
数字型数据的特点是:由数字构成,取值的可能性是无限多的
类别型数据的特点是:一般由字符构成,取值的可能性是有限的
类别型数据转数字型数据的方法一哑变量处理
在数据挖掘技术中,数学算法需要接收数字信息,但是数据中的信息有时候是一些字符型的类别型数据(如:性别、等级),有必要将类别型数据转换成数字型数据。
同时还要保留类别型数据中蕴含的信息。
生成的数字数据又叫做“哑变量”。(新生成的数字型数据的列数由原序列中的非空数据取值种类数决定。)
哑变量实现的函数解析
语法:
get_dummies(data,prefix,prefix_sep='_',columns)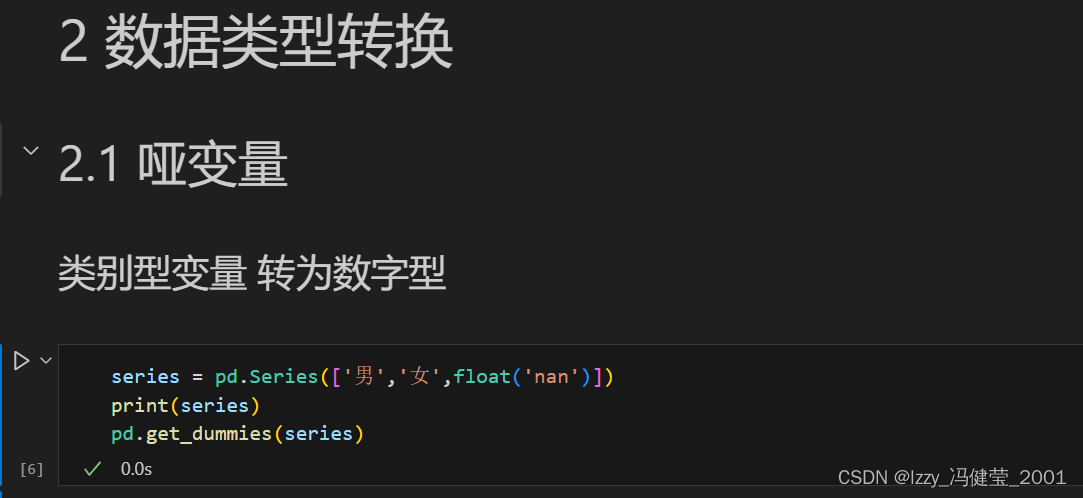
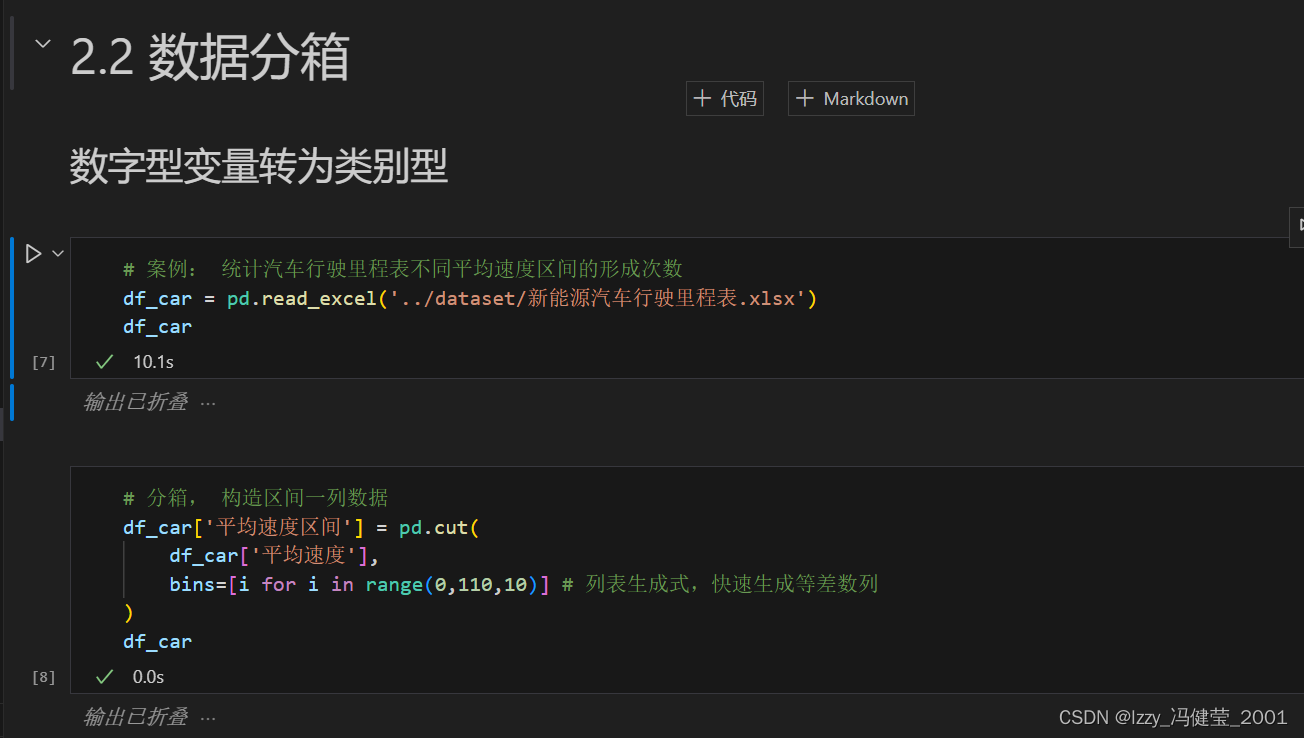
数据分箱的概念
对于数字型数据可以通过将其划分到不同的区间(分箱)来减少数据的取值可能个数。
这样处理降低了数据的复杂度,同时也保留了数据的大部分信息。
新生成的数据是类别型数据,在python中是字符串str和区间Interval等类型的数据。

区间的概念
“区间”指的是数字的范围。一般用括号和数字表示一个区间。
(a,b]表示一个区间,不包括a,但是包括b。数字1不属于(1,2),但1属于[1,2)。
Pandas中有一个Interval类可以生成“区间”对象
# 区间对象
interval = pd.Interval(0,100)
print(interval)
print(50 in interval)数据分箱函数pd.cut()解析
pd.cut(data=None,bins=None,labels=None)














 1854
1854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









